1,多进程并发
在一个应用程序中使用并发的第一种方法,是将应用程序分为多个、独立的、单线程的进程,它们运行在同一时刻,就像你可以同时进行网页浏览和文字处理。这些独立的进程可以通过所有的常规的进程间通信渠道互相传递消讯息(信号、套接字、文件、管道等等),如图1.3所示。有一个缺点是这种进程之间的通信通常设置复杂,或是速度较慢,或两者兼备,因为操作系统通常在进程间提供了大量的保护,以避免一个进程不小心修改了属于另一个进程的数据。另一个缺点是运行多个进程所需的固有的开销:启动进程需要时间,操作系统必须投入内部资源来管理进程,等等。
当然,也并不全是缺点:操作系统在线程间提供的附加保护操作和更高级别的通信机制,意味着可以比线程更容易地编写安全的并发代码。

(一对并发运行的线程之间的通信)
2, 多线程并发
线程很像轻量级的进程:每个线程相互独立运行,且每个线程可以运行不同的指令序列。但进程中的所有线程都共享相同的地址空间,并且从所有线程中访问到大部分数据——全局变量仍然是全局的,指针、对象的引用或数据可以在线程之间传递。虽然通常可以在进程之间共享内存,但这难以建立并且通常难以管理,因为同一数据的内存地址在不同的进程中也不尽相同。
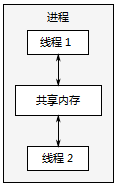
(同一进程中一对并发运行的线程之间的通信)
PKPKPKPKPKPKPKPKPKPKPKPK
共享的地址空间,以及缺少线程间的数据保护,使得使用多线程相关的开销远小于使用多个进程,
other:
一个线程可以处理用户界面,另一个处理DVD回放。它们之间会有交互,例如用户点击暂停,但现在这些交互直接与眼前的任务有关。
独立的线程常被用于运行必须在后台连续运行的任务,例如在桌面搜索程序中监视文件系统的变化。以这种方式使用线程一般会使每个线程的逻辑更加简单,因为它们之间的交互可以被限制为清晰可辨的点,而不是到处散播不同任务的逻辑。在这种情况下,线程的数量与CPU可用内核的数量无关,因为对线程的划分是基于概念上的设计而不是试图增加吞吐量。
对于一个可用地址空间限制为4GB的扁平架构的32位进程来说,这尤其是个问题:如果每个线程都有一个1MB的堆栈(对于很多系统来说是典型的),那么4096个线程将会用尽所有地址空间,不再为代码、静态数据或者堆数据留有空间。虽然64位(或者更大)的系统不存在这种直接的地址空间限制,它们仍然只具备有限的资源:如果你运行太多的线程,最终会导致问题。
如果客户端/服务器应用程序的服务器端为每一个链接启动一个独立的线程,对于少量的链接是可以正常工作的,但当同样的技术用于需要处理大量链接的高需求服务器时,就会因为启动太多线程而迅速耗尽系统资源。在这种场景下,谨慎地使用线程池可以提供优化的性能(参见第9章)。
最后,运行越多的线程,操作系统就需要做越多的上下文切换。每个上下文切换都需要耗费本可以花在有价值工作上的时间,所以在某些时候,增加一个额外的线程实际上会降低而不是提高应用程序的整体性能。为此,如果你试图得到系统的最佳性能,考虑可用的硬件并发(或缺乏之)并调整运行线程的数量是必需的。
C++标准库也被扩展了,包含了用于管理线程(参见第2章)、保护共享数据(参见第3章)、线程间同步操作(参见第4章)以及低级原子操作(参见第5章)的各个类
并发意味着多个执行实体(比方说上面例子中的人)可能需要竞争资源(咖啡机),因此就不可避免带来竞争和同步的问题;而并行则是不同的执行实体拥有各自的资源,相互之间可能互不干扰。
2222222222222222222222222222222222222222222222222222222222222
所谓同步(synchronization)就是指一个线程访问数据时,其它线程不得对同一个数据进行访问,即同一时刻只能有一个线程访问该数据,当这一线程访问结束时其它线程才能对这它进行访问。同步最常见的方式就是使用锁(Lock),也称为线程锁。锁是一种非强制机制,每一个线程在访问数据或资源之前,首先试图获取(Acquire)锁,并在访问结束之后释放(Release)锁。在锁被占用时试图获取锁,线程会进入等待状态,直到锁被释放再次变为可用。
二元信号量(Binary Semaphore)是一种最简单的锁,它有两种状态:占用和非占用。它适合只能被唯一一个线程独占访问的资源。当二元信号量处于非占用状态时,第一个试图获取该二元信号量锁的线程会获得该锁,并将二元信号量锁置为占用状态,之后其它试图获取该二元信号量的线程会进入等待状态,直到该锁被释放。
互斥锁的实现
互斥锁是实现线程同步的一种机制,只要在临界区前后对资源加锁就能阻塞其他进程的访问。
#include <iostream>
#include <pthread.h>
using namespace std;
#define NUM_THREADS 5
int sum = 0;
pthread_mutex_t sum_mutex;
void* say_hello( void* args )
{
cout << "hello in thread " << *(( int * )args) << endl;
pthread_mutex_lock( &sum_mutex );
cout << "before sum is " << sum << " in thread " << *( ( int* )args ) << endl;
sum += *( ( int* )args );
cout << "after sum is " << sum << " in thread " << *( ( int* )args ) << endl;
pthread_mutex_unlock( &sum_mutex );
pthread_exit( 0 );
}
int main()
{
pthread_t tids[NUM_THREADS];
int indexes[NUM_THREADS];
pthread_attr_t attr;
pthread_attr_init( &attr );
pthread_attr_setdetachstate( &attr, PTHREAD_CREATE_JOINABLE );
pthread_mutex_init( &sum_mutex, NULL );
for( int i = 0; i < NUM_THREADS; ++i )
{
indexes[i] = i;
int ret = pthread_create( &tids[i], &attr, say_hello, ( void* )&( indexes[i] ) );
if( ret != 0 )
{
cout << "pthread_create error:error_code=" << ret << endl;
}
}
pthread_attr_destroy( &attr );
void *status;
for( int i = 0; i < NUM_THREADS; ++i )
{
int ret = pthread_join( tids[i], &status );
if( ret != 0 )
{
cout << "pthread_join error:error_code=" << ret << endl;
}
}
cout << "finally sum is " << sum << endl;
pthread_mutex_destroy( &sum_mutex );
}
测试结果:
hello in thread hello in thread 1hello in thread 3
0
hello in thread 2
before sum is 0 in thread 1
hello in thread 4
after sum is 1 in thread 1
before sum is 1 in thread 3
after sum is 4 in thread 3
before sum is 4 in thread 4
after sum is 8 in thread 4
before sum is 8 in thread 0
after sum is 8 in thread 0
before sum is 8 in thread 2
after sum is 10 in thread 2
finally sum is 10
可知,sum的访问和修改顺序是正常的,这就达到了多线程的目的了,但是线程的运行顺序是混乱的,混乱就是正常?
信号量是线程同步的另一种实现机制,信号量的操作有signal和wait,本例子采用条件信号变量
pthread_cond_t tasks_cond;
信号量的实现也要给予锁机制。
#include <iostream>
#include <pthread.h>
#include <stdio.h>
using namespace std;
#define BOUNDARY 5
int tasks = 10;
pthread_mutex_t tasks_mutex;
pthread_cond_t tasks_cond;
void* say_hello2( void* args )
{
pthread_t pid = pthread_self();
cout << "[" << pid << "] hello in thread " << *( ( int* )args ) << endl;
bool is_signaled = false;
while(1)
{
pthread_mutex_lock( &tasks_mutex );
if( tasks > BOUNDARY )
{
cout << "[" << pid << "] take task: " << tasks << " in thread " << *( (int*)args ) << endl;
--tasks;
}
else if( !is_signaled )
{
cout << "[" << pid << "] pthread_cond_signal in thread " << *( ( int* )args ) << endl;
pthread_cond_signal( &tasks_cond );
is_signaled = true;
}
pthread_mutex_unlock( &tasks_mutex );
if( tasks == 0 )
break;
}
}
void* say_hello1( void* args )
{
pthread_t pid = pthread_self();
cout << "[" << pid << "] hello in thread " << *( ( int* )args ) << endl;
while(1)
{
pthread_mutex_lock( &tasks_mutex );
if( tasks > BOUNDARY )
{
cout << "[" << pid << "] pthread_cond_signal in thread " << *( ( int* )args ) << endl;
pthread_cond_wait( &tasks_cond, &tasks_mutex );
}
else
{
cout << "[" << pid << "] take task: " << tasks << " in thread " << *( (int*)args ) << endl;
--tasks;
}
pthread_mutex_unlock( &tasks_mutex );
if( tasks == 0 )
break;
}
}
int main()
{
pthread_attr_t attr;
pthread_attr_init( &attr );
pthread_attr_setdetachstate( &attr, PTHREAD_CREATE_JOINABLE );
pthread_cond_init( &tasks_cond, NULL );
pthread_mutex_init( &tasks_mutex, NULL );
pthread_t tid1, tid2;
int index1 = 1;
int ret = pthread_create( &tid1, &attr, say_hello1, ( void* )&index1 );
if( ret != 0 )
{
cout << "pthread_create error:error_code=" << ret << endl;
}
int index2 = 2;
ret = pthread_create( &tid2, &attr, say_hello2, ( void* )&index2 );
if( ret != 0 )
{
cout << "pthread_create error:error_code=" << ret << endl;
}
pthread_join( tid1, NULL );
pthread_join( tid2, NULL );
pthread_attr_destroy( &attr );
pthread_mutex_destroy( &tasks_mutex );
pthread_cond_destroy( &tasks_cond );
}
测试结果:
先在线程2中执行say_hello2,再跳转到线程1中执行say_hello1,直到tasks减到0为止。
[2] hello in thread 1
[2] pthread_cond_signal in thread 1
[3] hello in thread 2
[3] take task: 10 in thread 2
[3] take task: 9 in thread 2
[3] take task: 8 in thread 2
[3] take task: 7 in thread 2
[3] take task: 6 in thread 2
[3] pthread_cond_signal in thread 2
[2] take task: 5 in thread 1
[2] take task: 4 in thread 1
[2] take task: 3 in thread 1
[2] take task: 2 in thread 1
[2] take task: 1 in thread 1
信号量与普通整型变量的区别:
①信号量(semaphore)是非负整型变量,除了初始化之外,它只能通过两个标准原子操作:wait(semap) , signal(semap) ; 来进行访问;
②操作也被成为PV原语(P来源于Dutch proberen"测试",V来源于Dutch verhogen"增加"),而普通整型变量则可以在任何语句块中被访问;
信号量与互斥锁之间的区别:
1. 互斥量用于线程的互斥,信号线用于线程的同步。
这是互斥量和信号量的根本区别,也就是互斥和同步之间的区别。
互斥:是指某一资源同时只允许一个访问者对其进行访问,具有唯一性和排它性。但互斥无法限制访问者对资源的访问顺序,即访问是无序的。
同步:是指在互斥的基础上(大多数情况),通过其它机制实现访问者对资源的有序访问。在大多数情况下,同步已经实现了互斥,特别是所有写入资源的情况必定是互斥的。少数情况是指可以允许多个访问者同时访问资源
2. 互斥量值只能为0/1,信号量值可以为非负整数。
也就是说,一个互斥量只能用于一个资源的互斥访问,它不能实现多个资源的多线程互斥问题。信号量可以实现多个同类资源的多线程互斥和同步。当信号量为单值信号量是,也可以完成一个资源的互斥访问。
3. 互斥量的加锁和解锁必须由同一线程分别对应使用,信号量可以由一个线程释放,另一个线程得到。
信号量
信号量(Semaphore),有时被称为信号灯,是在多线程环境下使用的一种设施, 它负责协调各个线程, 以保证它们能够正确、合理的使用公共资源。
信号量可以分为几类:
² 二进制信号量(binary semaphore):只允许信号量取0或1值,其同时只能被一个线程获取。
² 整型信号量(integer semaphore):信号量取值是整数,它可以被多个线程同时获得,直到信号量的值变为0。
² 记录型信号量(record semaphore):每个信号量s除一个整数值value(计数)外,还有一个等待队列List,其中是阻塞在该信号量的各个线程的标识。当信号量被释放一个,值被加一后,系统自动从等待队列中唤醒一个等待中的线程,让其获得信号量,同时信号量再减一。
信号量通过一个计数器控制对共享资源的访问,信号量的值是一个非负整数,所有通过它的线程都会将该整数减一。如果计数器大于0,则访问被允许,计数器减1;如果为0,则访问被禁止,所有试图通过它的线程都将处于等待状态。
计数器计算的结果是允许访问共享资源的通行证。因此,为了访问共享资源,线程必须从信号量得到通行证, 如果该信号量的计数大于0,则此线程获得一个通行证,这将导致信号量的计数递减,否则,此线程将阻塞直到获得一个通行证为止。当此线程不再需要访问共享资源时,它释放该通行证,这导致信号量的计数递增,如果另一个线程等待通行证,则那个线程将在那时获得通行证。
Semaphore可以被抽象为五个操作:
- 创建 Create
- 等待 Wait:
线程等待信号量,如果值大于0,则获得,值减一;如果只等于0,则一直线程进入睡眠状态,知道信号量值大于0或者超时。
-释放 Post
执行释放信号量,则值加一;如果此时有正在等待的线程,则唤醒该线程。
-试图等待 TryWait
如果调用TryWait,线程并不真正的去获得信号量,还是检查信号量是否能够被获得,如果信号量值大于0,则TryWait返回成功;否则返回失败。
-销毁 Destroy
信号量,是可以用来保护两个或多个关键代码段,这些关键代码段不能并发调用。在进入一个关键代码段之前,线程必须获取一个信号量。如果关键代码段中没有任何线程,那么线程会立即进入该框图中的那个部分。一旦该关键代码段完成了,那么该线程必须释放信号量。其它想进入该关键代码段的线程必须等待直到第一个线程释放信号量。为了完成这个过程,需要创建一个信号量,然后将Acquire Semaphore VI以及Release Semaphore VI分别放置在每个关键代码段的首末端。确认这些信号量VI引用的是初始创建的信号量。 动作\系统
Win32
POSIX
创建
CreateSemaphore
sem_init
等待
WaitForSingleObject
sem _wait
释放
ReleaseMutex
sem _post
试图等待
WaitForSingleObject
sem _trywait
销毁
CloseHandle
sem_destroy
互斥量(Mutex)
互斥量表现互斥现象的数据结构,也被当作二元信号灯。一个互斥基本上是一个多任务敏感的二元信号,它能用作同步多任务的行为,它常用作保护从中断来的临界段代码并且在共享同步使用的资源。
Mutex本质上说就是一把锁,提供对资源的独占访问,所以Mutex主要的作用是用于互斥。Mutex对象的值,只有0和1两个值。这两个值也分别代表了Mutex的两种状态。值为0, 表示锁定状态,当前对象被锁定,用户进程/线程如果试图Lock临界资源,则进入排队等待;值为1,表示空闲状态,当前对象为空闲,用户进程/线程可以Lock临界资源,之后Mutex值减1变为0。
Mutex可以被抽象为四个操作:
- 创建 Create
- 加锁 Lock
- 解锁 Unlock
- 销毁 Destroy
Mutex被创建时可以有初始值,表示Mutex被创建后,是锁定状态还是空闲状态。在同一个线程中,为了防止死锁,系统不允许连续两次对Mutex加锁(系统一般会在第二次调用立刻返回)。也就是说,加锁和解锁这两个对应的操作,需要在同一个线程中完成。
不同操作系统中提供的Mutex函数: 动作\系统
Win32
Linyx
Solaris
创建
CreateMutex
pthread_mutex_init
mutex_init
加锁
WaitForSingleObject
pthread_mutex_lock
mutex_lock
解锁
ReleaseMutex
pthread_mutex_unlock
mutex_unlock
销毁
CloseHandle
pthread_mutex_destroy
mutex_destroy
#include "stdio.h"
int main()
{
char s[100],c;
int i,num,word;
while(1)
{
printf("请输入一行英文:");
gets(s);
num=0,word=0;
for(i=0;(c=s[i])!='\0';i++)
{
if(c==' ')
word=0;//这个语句就是按顺序执行,如果满足第一个if的
//判断则执行对应的语句,而忽略后面的else if和else,如果第一个判断不符合,
//则判断elseif,如果满足则执行相应的语句。
else if(word==0)
{
word=1;
num++;
}
}
printf("%d\n",num);
}
return 0;
}
--------------------------------------------------------------------------
while{
if{}
else if{}
}
只要第一个条件成立 就不会考虑别的问题
-------------------------------------------------------------------------
互斥量和信号量
互斥量是多线程里面 对共享资源加锁
信号量是发送信号
-------------------------------------------------------------------------------
使线程同步
在程序中使用多线程时,一般很少有多个线程能在其生命期内进行完全独立的操作。更多的情况是一些线程进行某些处理操作,而其他的线程必须对其处理结果进行了解。正常情况下对这种处理结果的了解应当在其处理任务完成后进行。
如果不采取适当的措施,其他线程往往会在线程处理任务结束前就去访问处理结果,这就很有可能得到有关处理结果的错误了解。例如,多个线程同时访问同一个全局变量,如果都是读取操作,则不会出现问题。如果一个线程负责改变此变量的值,而其他线程负责同时读取变量内容,则不能保证读取到的数据是经过写线程修改后的。
为了确保读线程读取到的是经过修改的变量,就必须在向变量写入数据时禁止其他线程对其的任何访问,直至赋值过程结束后再解除对其他线程的访问限制。象这种保证线程能了解其他线程任务处理结束后的处理结果而采取的保护措施即为线程同步。
线程同步是一个非常大的话题,包括方方面面的内容。从大的方面讲,线程的同步可分用户模式的线程同步和内核对象的线程同步两大类。用户模式中线程的同步方法主要有原子访问和临界区等方法。其特点是同步速度特别快,适合于对线程运行速度有严格要求的场合。
内核对象的线程同步则主要由事件、等待定时器、信号量以及信号灯等内核对象构成。由于这种同步机制使用了内核对象,使用时必须将线程从用户模式切换到内核模式,而这种转换一般要耗费近千个CPU周期,因此同步速度较慢,但在适用性上却要远优于用户模式的线程同步方式。
临界区
临界区(Critical Section)是一段独占对某些共享资源访问的代码,在任意时刻只允许一个线程对共享资源进行访问。如果有多个线程试图同时访问临界区,那么在有一个线程进入后其他所有试图访问此临界区的线程将被挂起,并一直持续到进入临界区的线程离开。临界区在被释放后,其他线程可以继续抢占,并以此达到用原子方式操作共享资源的目的。
临界区在使用时以CRITICAL_SECTION结构对象保护共享资源,并分别用EnterCriticalSection()和LeaveCriticalSection()函数去标识和释放一个临界区。所用到的CRITICAL_SECTION结构对象必须经过InitializeCriticalSection()的初始化后才能使用,而且必须确保所有线程中的任何试图访问此共享资源的代码都处在此临界区的保护之下。否则临界区将不会起到应有的作用,共享资源依然有被破坏的可能。
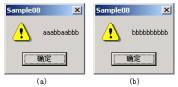
图1 使用临界区保持线程同步
下面通过一段代码展示了临界区在保护多线程访问的共享资源中的作用。通过两个线程来分别对全局变量g_cArray[10]进行写入操作,用临界区结构对象g_cs来保持线程的同步,并在开启线程前对其进行初始化。为了使实验效果更加明显,体现出临界区的作用,在线程函数对共享资源g_cArray[10]的写入时,以Sleep()函数延迟1毫秒,使其他线程同其抢占CPU的可能性增大。如果不使用临界区对其进行保护,则共享资源数据将被破坏(参见图1(a)所示计算结果),而使用临界区对线程保持同步后则可以得到正确的结果(参见图1(b)所示计算结果)。代码实现清单附下:
// 临界区结构对象
CRITICAL_SECTION g_cs;
// 共享资源
char g_cArray[10];
UINT ThreadProc10(LPVOID pParam)
{
// 进入临界区
EnterCriticalSection(&g_cs);
// 对共享资源进行写入操作
for (int i = 0; i < 10; i++)
{
g_cArray[i] = 'a';
Sleep(1);
}
// 离开临界区
LeaveCriticalSection(&g_cs);
return 0;
}
UINT ThreadProc11(LPVOID pParam)
{
// 进入临界区
EnterCriticalSection(&g_cs);
// 对共享资源进行写入操作
for (int i = 0; i < 10; i++)
{
g_cArray[10 - i - 1] = 'b';
Sleep(1);
}
// 离开临界区
LeaveCriticalSection(&g_cs);
return 0;
}
……
void CSample08View::OnCriticalSection()
{
// 初始化临界区
InitializeCriticalSection(&g_cs);
// 启动线程
AfxBeginThread(ThreadProc10, NULL);
AfxBeginThread(ThreadProc11, NULL);
// 等待计算完毕
Sleep(300);
// 报告计算结果
CString sResult = CString(g_cArray);
AfxMessageBox(sResult);
} |
在使用临界区时,一般不允许其运行时间过长,只要进入临界区的线程还没有离开,其他所有试图进入此临界区的线程都会被挂起而进入到等待状态,并会在一定程度上影响。程序的运行性能。尤其需要注意的是不要将等待用户输入或是其他一些外界干预的操作包含到临界区。如果进入了临界区却一直没有释放,同样也会引起其他线程的长时间等待。换句话说,在执行了EnterCriticalSection()语句进入临界区后无论发生什么,必须确保与之匹配的LeaveCriticalSection()都能够被执行到。可以通过添加结构化异常处理代码来确保LeaveCriticalSection()语句的执行。虽然临界区同步速度很快,但却只能用来同步本进程内的线程,而不可用来同步多个进程中的线程。
MFC为临界区提供有一个CCriticalSection类,使用该类进行线程同步处理是非常简单的,只需在线程函数中用CCriticalSection类成员函数Lock()和UnLock()标定出被保护代码片段即可。对于上述代码,可通过CCriticalSection类将其改写如下:
// MFC临界区类对象
CCriticalSection g_clsCriticalSection;
// 共享资源
char g_cArray[10];
UINT ThreadProc20(LPVOID pParam)
{
// 进入临界区
g_clsCriticalSection.Lock();
// 对共享资源进行写入操作
for (int i = 0; i < 10; i++)
{
g_cArray[i] = 'a';
Sleep(1);
}
// 离开临界区
g_clsCriticalSection.Unlock();
return 0;
}
UINT ThreadProc21(LPVOID pParam)
{
// 进入临界区
g_clsCriticalSection.Lock();
// 对共享资源进行写入操作
for (int i = 0; i < 10; i++)
{
g_cArray[10 - i - 1] = 'b';
Sleep(1);
}
// 离开临界区
g_clsCriticalSection.Unlock();
return 0;
}
……
void CSample08View::OnCriticalSectionMfc()
{
// 启动线程
AfxBeginThread(ThreadProc20, NULL);
AfxBeginThread(ThreadProc21, NULL);
// 等待计算完毕
Sleep(300);
// 报告计算结果
CString sResult = CString(g_cArray);
AfxMessageBox(sResult);
} |
管理事件内核对象
在前面讲述线程通信时曾使用过事件内核对象来进行线程间的通信,除此之外,事件内核对象也可以通过通知操作的方式来保持线程的同步。对于前面那段使用临界区保持线程同步的代码可用事件对象的线程同步方法改写如下:
// 事件句柄
HANDLE hEvent = NULL;
// 共享资源
char g_cArray[10];
……
UINT ThreadProc12(LPVOID pParam)
{
// 等待事件置位
WaitForSingleObject(hEvent, INFINITE);
// 对共享资源进行写入操作
for (int i = 0; i < 10; i++)
{
g_cArray[i] = 'a';
Sleep(1);
}
// 处理完成后即将事件对象置位
SetEvent(hEvent);
return 0;
}
UINT ThreadProc13(LPVOID pParam)
{
// 等待事件置位
WaitForSingleObject(hEvent, INFINITE);
// 对共享资源进行写入操作
for (int i = 0; i < 10; i++)
{
g_cArray[10 - i - 1] = 'b';
Sleep(1);
}
// 处理完成后即将事件对象置位
SetEvent(hEvent);
return 0;
}
……
void CSample08View::OnEvent()
{
// 创建事件
hEvent = CreateEvent(NULL, FALSE, FALSE, NULL);
// 事件置位
SetEvent(hEvent);
// 启动线程
AfxBeginThread(ThreadProc12, NULL);
AfxBeginThread(ThreadProc13, NULL);
// 等待计算完毕
Sleep(300);
// 报告计算结果
CString sResult = CString(g_cArray);
AfxMessageBox(sResult);
} |
在创建线程前,首先创建一个可以自动复位的事件内核对象hEvent,而线程函数则通过WaitForSingleObject()等待函数无限等待hEvent的置位,只有在事件置位时WaitForSingleObject()才会返回,被保护的代码将得以执行。对于以自动复位方式创建的事件对象,在其置位后一被WaitForSingleObject()等待到就会立即复位,也就是说在执行ThreadProc12()中的受保护代码时,事件对象已经是复位状态的,这时即使有ThreadProc13()对CPU的抢占,也会由于WaitForSingleObject()没有hEvent的置位而不能继续执行,也就没有可能破坏受保护的共享资源。在ThreadProc12()中的处理完成后可以通过SetEvent()对hEvent的置位而允许ThreadProc13()对共享资源g_cArray的处理。这里SetEvent()所起的作用可以看作是对某项特定任务完成的通知。
使用临界区只能同步同一进程中的线程,而使用事件内核对象则可以对进程外的线程进行同步,其前提是得到对此事件对象的访问权。可以通过OpenEvent()函数获取得到,其函数原型为:

HANDLE OpenEvent(
DWORD dwDesiredAccess, // 访问标志
BOOL bInheritHandle, // 继承标志
LPCTSTR lpName // 指向事件对象名的指针
); |
如果事件对象已创建(在创建事件时需要指定事件名),函数将返回指定事件的句柄。对于那些在创建事件时没有指定事件名的事件内核对象,可以通过使用内核对象的继承性或是调用DuplicateHandle()函数来调用CreateEvent()以获得对指定事件对象的访问权。在获取到访问权后所进行的同步操作与在同一个进程中所进行的线程同步操作是一样的。
如果需要在一个线程中等待多个事件,则用WaitForMultipleObjects()来等待。WaitForMultipleObjects()与WaitForSingleObject()类似,同时监视位于句柄数组中的所有句柄。这些被监视对象的句柄享有平等的优先权,任何一个句柄都不可能比其他句柄具有更高的优先权。WaitForMultipleObjects()的函数原型为:
DWORD WaitForMultipleObjects(
DWORD nCount, // 等待句柄数
CONST HANDLE *lpHandles, // 句柄数组首地址
BOOL fWaitAll, // 等待标志
DWORD dwMilliseconds // 等待时间间隔
); |
参数nCount指定了要等待的内核对象的数目,存放这些内核对象的数组由lpHandles来指向。fWaitAll对指定的这nCount个内核对象的两种等待方式进行了指定,为TRUE时当所有对象都被通知时函数才会返回,为FALSE则只要其中任何一个得到通知就可以返回。dwMilliseconds在饫锏淖饔糜朐赪aitForSingleObject()中的作用是完全一致的。如果等待超时,函数将返回WAIT_TIMEOUT。如果返回WAIT_OBJECT_0到WAIT_OBJECT_0+nCount-1中的某个值,则说明所有指定对象的状态均为已通知状态(当fWaitAll为TRUE时)或是用以减去WAIT_OBJECT_0而得到发生通知的对象的索引(当fWaitAll为FALSE时)。如果返回值在WAIT_ABANDONED_0与WAIT_ABANDONED_0+nCount-1之间,则表示所有指定对象的状态均为已通知,且其中至少有一个对象是被丢弃的互斥对象(当fWaitAll为TRUE时),或是用以减去WAIT_OBJECT_0表示一个等待正常结束的互斥对象的索引(当fWaitAll为FALSE时)。 下面给出的代码主要展示了对WaitForMultipleObjects()函数的使用。通过对两个事件内核对象的等待来控制线程任务的执行与中途退出:
// 存放事件句柄的数组
HANDLE hEvents[2];
UINT ThreadProc14(LPVOID pParam)
{
// 等待开启事件
DWORD dwRet1 = WaitForMultipleObjects(2, hEvents, FALSE, INFINITE);
// 如果开启事件到达则线程开始执行任务
if (dwRet1 == WAIT_OBJECT_0)
{
AfxMessageBox("线程开始工作!");
while (true)
{
for (int i = 0; i < 10000; i++);
// 在任务处理过程中等待结束事件
DWORD dwRet2 = WaitForMultipleObjects(2, hEvents, FALSE, 0);
// 如果结束事件置位则立即终止任务的执行
if (dwRet2 == WAIT_OBJECT_0 + 1)
break;
}
}
AfxMessageBox("线程退出!");
return 0;
}
……
void CSample08View::OnStartEvent()
{
// 创建线程
for (int i = 0; i < 2; i++)
hEvents[i] = CreateEvent(NULL, FALSE, FALSE, NULL);
// 开启线程
AfxBeginThread(ThreadProc14, NULL);
// 设置事件0(开启事件)
SetEvent(hEvents[0]);
}
void CSample08View::OnEndevent()
{
// 设置事件1(结束事件)
SetEvent(hEvents[1]);
} |
MFC为事件相关处理也提供了一个CEvent类,共包含有除构造函数外的4个成员函数PulseEvent()、ResetEvent()、SetEvent()和UnLock()。在功能上分别相当与Win32 API的PulseEvent()、ResetEvent()、SetEvent()和CloseHandle()等函数。而构造函数则履行了原CreateEvent()函数创建事件对象的职责,其函数原型为:
| CEvent(BOOL bInitiallyOwn = FALSE, BOOL bManualReset = FALSE, LPCTSTR lpszName = NULL, LPSECURITY_ATTRIBUTES lpsaAttribute = NULL ); |
按照此缺省设置将创建一个自动复位、初始状态为复位状态的没有名字的事件对象。封装后的CEvent类使用起来更加方便,图2即展示了CEvent类对A、B两线程的同步过程:
图2 CEvent类对线程的同步过程示意
B线程在执行到CEvent类成员函数Lock()时将会发生阻塞,而A线程此时则可以在没有B线程干扰的情况下对共享资源进行处理,并在处理完成后通过成员函数SetEvent()向B发出事件,使其被释放,得以对A先前已处理完毕的共享资源进行操作。可见,使用CEvent类对线程的同步方法与通过API函数进行线程同步的处理方法是基本一致的。前面的API处理代码可用CEvent类将其改写为:
| // MFC事件类对象
CEvent g_clsEvent;
UINT ThreadProc22(LPVOID pParam)
{
// 对共享资源进行写入操作
for (int i = 0; i < 10; i++)
{
g_cArray[i] = 'a';
Sleep(1);
}
// 事件置位
g_clsEvent.SetEvent();
return 0;
}
UINT ThreadProc23(LPVOID pParam)
{
// 等待事件
g_clsEvent.Lock();
// 对共享资源进行写入操作
for (int i = 0; i < 10; i++)
{
g_cArray[10 - i - 1] = 'b';
Sleep(1);
}
return 0;
}
……
void CSample08View::OnEventMfc()
{
// 启动线程
AfxBeginThread(ThreadProc22, NULL);
AfxBeginThread(ThreadProc23, NULL);
// 等待计算完毕
Sleep(300);
// 报告计算结果
CString sResult = CString(g_cArray);
AfxMessageBox(sResult);
}
|
信号量内核对象
信号量(Semaphore)内核对象对线程的同步方式与前面几种方法不同,它允许多个线程在同一时刻访问同一资源,但是需要限制在同一时刻访问此资源的最大线程数目。在用CreateSemaphore()创建信号量时即要同时指出允许的最大资源计数和当前可用资源计数。一般是将当前可用资源计数设置为最大资源计数,每增加一个线程对共享资源的访问,当前可用资源计数就会减1,只要当前可用资源计数是大于0的,就可以发出信号量信号。但是当前可用计数减小到0时则说明当前占用资源的线程数已经达到了所允许的最大数目,不能在允许其他线程的进入,此时的信号量信号将无法发出。线程在处理完共享资源后,应在离开的同时通过ReleaseSemaphore()函数将当前可用资源计数加1。在任何时候当前可用资源计数决不可能大于最大资源计数。
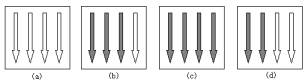
图3 使用信号量对象控制资源
下面结合图例3来演示信号量对象对资源的控制。在图3中,以箭头和白色箭头表示共享资源所允许的最大资源计数和当前可用资源计数。初始如图(a)所示,最大资源计数和当前可用资源计数均为4,此后每增加一个对资源进行访问的线程(用黑色箭头表示)当前资源计数就会相应减1,图(b)即表示的在3个线程对共享资源进行访问时的状态。当进入线程数达到4个时,将如图(c)所示,此时已达到最大资源计数,而当前可用资源计数也已减到0,其他线程无法对共享资源进行访问。在当前占有资源的线程处理完毕而退出后,将会释放出空间,图(d)已有两个线程退出对资源的占有,当前可用计数为2,可以再允许2个线程进入到对资源的处理。可以看出,信号量是通过计数来对线程访问资源进行控制的,而实际上信号量确实也被称作Dijkstra计数器。
使用信号量内核对象进行线程同步主要会用到CreateSemaphore()、OpenSemaphore()、ReleaseSemaphore()、WaitForSingleObject()和WaitForMultipleObjects()等函数。其中,CreateSemaphore()用来创建一个信号量内核对象,其函数原型为:
HANDLE CreateSemaphore(
LPSECURITY_ATTRIBUTES lpSemaphoreAttributes, // 安全属性指针
LONG lInitialCount, // 初始计数
LONG lMaximumCount, // 最大计数
LPCTSTR lpName // 对象名指针
); |
参数lMaximumCount是一个有符号32位值,定义了允许的最大资源计数,最大取值不能超过4294967295。lpName参数可以为创建的信号量定义一个名字,由于其创建的是一个内核对象,因此在其他进程中可以通过该名字而得到此信号量。OpenSemaphore()函数即可用来根据信号量名打开在其他进程中创建的信号量,函数原型如下:
HANDLE OpenSemaphore(
DWORD dwDesiredAccess, // 访问标志
BOOL bInheritHandle, // 继承标志
LPCTSTR lpName // 信号量名
); |
在线程离开对共享资源的处理时,必须通过ReleaseSemaphore()来增加当前可用资源计数。否则将会出现当前正在处理共享资源的实际线程数并没有达到要限制的数值,而其他线程却因为当前可用资源计数为0而仍无法进入的情况。ReleaseSemaphore()的函数原型为:
BOOL ReleaseSemaphore(
HANDLE hSemaphore, // 信号量句柄
LONG lReleaseCount, // 计数递增数量
LPLONG lpPreviousCount // 先前计数
); |
该函数将lReleaseCount中的值添加给信号量的当前资源计数,一般将lReleaseCount设置为1,如果需要也可以设置其他的值。WaitForSingleObject()和WaitForMultipleObjects()主要用在试图进入共享资源的线程函数入口处,主要用来判断信号量的当前可用资源计数是否允许本线程的进入。只有在当前可用资源计数值大于0时,被监视的信号量内核对象才会得到通知。
信号量的使用特点使其更适用于对Socket(套接字)程序中线程的同步。例如,网络上的HTTP服务器要对同一时间内访问同一页面的用户数加以限制,这时可以为没一个用户对服务器的页面请求设置一个线程,而页面则是待保护的共享资源,通过使用信号量对线程的同步作用可以确保在任一时刻无论有多少用户对某一页面进行访问,只有不大于设定的最大用户数目的线程能够进行访问,而其他的访问企图则被挂起,只有在有用户退出对此页面的访问后才有可能进入。下面给出的示例代码即展示了类似的处理过程:
// 信号量对象句柄
HANDLE hSemaphore;
UINT ThreadProc15(LPVOID pParam)
{
// 试图进入信号量关口
WaitForSingleObject(hSemaphore, INFINITE);
// 线程任务处理
AfxMessageBox("线程一正在执行!");
// 释放信号量计数
ReleaseSemaphore(hSemaphore, 1, NULL);
return 0;
}
UINT ThreadProc16(LPVOID pParam)
{
// 试图进入信号量关口
WaitForSingleObject(hSemaphore, INFINITE);
// 线程任务处理
AfxMessageBox("线程二正在执行!");
// 释放信号量计数
ReleaseSemaphore(hSemaphore, 1, NULL);
return 0;
}
UINT ThreadProc17(LPVOID pParam)
{
// 试图进入信号量关口
WaitForSingleObject(hSemaphore, INFINITE);
// 线程任务处理
AfxMessageBox("线程三正在执行!");
// 释放信号量计数
ReleaseSemaphore(hSemaphore, 1, NULL);
return 0;
}
……
void CSample08View::OnSemaphore()
{
// 创建信号量对象
hSemaphore = CreateSemaphore(NULL, 2, 2, NULL);
// 开启线程
AfxBeginThread(ThreadProc15, NULL);
AfxBeginThread(ThreadProc16, NULL);
AfxBeginThread(ThreadProc17, NULL);
} |
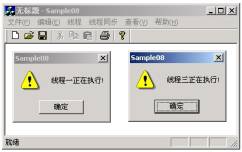
图4 开始进入的两个线程
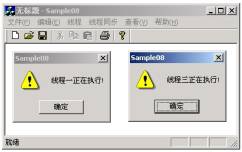
图5 线程二退出后线程三才得以进入
上述代码在开启线程前首先创建了一个初始计数和最大资源计数均为2的信号量对象hSemaphore。即在同一时刻只允许2个线程进入由hSemaphore保护的共享资源。随后开启的三个线程均试图访问此共享资源,在前两个线程试图访问共享资源时,由于hSemaphore的当前可用资源计数分别为2和1,此时的hSemaphore是可以得到通知的,也就是说位于线程入口处的WaitForSingleObject()将立即返回,而在前两个线程进入到保护区域后,hSemaphore的当前资源计数减少到0,hSemaphore将不再得到通知,WaitForSingleObject()将线程挂起。直到此前进入到保护区的线程退出后才能得以进入。图4和图5为上述代脉的运行结果。从实验结果可以看出,信号量始终保持了同一时刻不超过2个线程的进入。
在MFC中,通过CSemaphore类对信号量作了表述。该类只具有一个构造函数,可以构造一个信号量对象,并对初始资源计数、最大资源计数、对象名和安全属性等进行初始化,其原型如下:
| CSemaphore( LONG lInitialCount = 1, LONG lMaxCount = 1, LPCTSTR pstrName = NULL, LPSECURITY_ATTRIBUTES lpsaAttributes = NULL ); |
在构造了CSemaphore类对象后,任何一个访问受保护共享资源的线程都必须通过CSemaphore从父类CSyncObject类继承得到的Lock()和UnLock()成员函数来访问或释放CSemaphore对象。与前面介绍的几种通过MFC类保持线程同步的方法类似,通过CSemaphore类也可以将前面的线程同步代码进行改写,这两种使用信号量的线程同步方法无论是在实现原理上还是从实现结果上都是完全一致的。下面给出经MFC改写后的信号量线程同步代码:
// MFC信号量类对象
CSemaphore g_clsSemaphore(2, 2);
UINT ThreadProc24(LPVOID pParam)
{
// 试图进入信号量关口
g_clsSemaphore.Lock();
// 线程任务处理
AfxMessageBox("线程一正在执行!");
// 释放信号量计数
g_clsSemaphore.Unlock();
return 0;
}
UINT ThreadProc25(LPVOID pParam)
{
// 试图进入信号量关口
g_clsSemaphore.Lock();
// 线程任务处理
AfxMessageBox("线程二正在执行!");
// 释放信号量计数
g_clsSemaphore.Unlock();
return 0;
}
UINT ThreadProc26(LPVOID pParam)
{
// 试图进入信号量关口
g_clsSemaphore.Lock();
// 线程任务处理
AfxMessageBox("线程三正在执行!");
// 释放信号量计数
g_clsSemaphore.Unlock();
return 0;
}
……
void CSample08View::OnSemaphoreMfc()
{
// 开启线程
AfxBeginThread(ThreadProc24, NULL);
AfxBeginThread(ThreadProc25, NULL);
AfxBeginThread(ThreadProc26, NULL);
} |
互斥内核对象
互斥(Mutex)是一种用途非常广泛的内核对象。能够保证多个线程对同一共享资源的互斥访问。同临界区有些类似,只有拥有互斥对象的线程才具有访问资源的权限,由于互斥对象只有一个,因此就决定了任何情况下此共享资源都不会同时被多个线程所访问。当前占据资源的线程在任务处理完后应将拥有的互斥对象交出,以便其他线程在获得后得以访问资源。与其他几种内核对象不同,互斥对象在操作系统中拥有特殊代码,并由操作系统来管理,操作系统甚至还允许其进行一些其他内核对象所不能进行的非常规操作。为便于理解,可参照图6给出的互斥内核对象的工作模型:
图6 使用互斥内核对象对共享资源的保护
图(a)中的箭头为要访问资源(矩形框)的线程,但只有第二个线程拥有互斥对象(黑点)并得以进入到共享资源,而其他线程则会被排斥在外(如图(b)所示)。当此线程处理完共享资源并准备离开此区域时将把其所拥有的互斥对象交出(如图(c)所示),其他任何一个试图访问此资源的线程都有机会得到此互斥对象。
以互斥内核对象来保持线程同步可能用到的函数主要有CreateMutex()、OpenMutex()、ReleaseMutex()、WaitForSingleObject()和WaitForMultipleObjects()等。在使用互斥对象前,首先要通过CreateMutex()或OpenMutex()创建或打开一个互斥对象。CreateMutex()函数原型为:
HANDLE CreateMutex(
LPSECURITY_ATTRIBUTES lpMutexAttributes, // 安全属性指针
BOOL bInitialOwner, // 初始拥有者
LPCTSTR lpName // 互斥对象名
); |
参数bInitialOwner主要用来控制互斥对象的初始状态。一般多将其设置为FALSE,以表明互斥对象在创建时并没有为任何线程所占有。如果在创建互斥对象时指定了对象名,那么可以在本进程其他地方或是在其他进程通过OpenMutex()函数得到此互斥对象的句柄。OpenMutex()函数原型为:
HANDLE OpenMutex(
DWORD dwDesiredAccess, // 访问标志
BOOL bInheritHandle, // 继承标志
LPCTSTR lpName // 互斥对象名
); |
当目前对资源具有访问权的线程不再需要访问此资源而要离开时,必须通过ReleaseMutex()函数来释放其拥有的互斥对象,其函数原型为:
| BOOL ReleaseMutex(HANDLE hMutex); |
其唯一的参数hMutex为待释放的互斥对象句柄。至于WaitForSingleObject()和WaitForMultipleObjects()等待函数在互斥对象保持线程同步中所起的作用与在其他内核对象中的作用是基本一致的,也是等待互斥内核对象的通知。但是这里需要特别指出的是:在互斥对象通知引起调用等待函数返回时,等待函数的返回值不再是通常的WAIT_OBJECT_0(对于WaitForSingleObject()函数)或是在WAIT_OBJECT_0到WAIT_OBJECT_0+nCount-1之间的一个值(对于WaitForMultipleObjects()函数),而是将返回一个WAIT_ABANDONED_0(对于WaitForSingleObject()函数)或是在WAIT_ABANDONED_0到WAIT_ABANDONED_0+nCount-1之间的一个值(对于WaitForMultipleObjects()函数)。以此来表明线程正在等待的互斥对象由另外一个线程所拥有,而此线程却在使用完共享资源前就已经终止。除此之外,使用互斥对象的方法在等待线程的可调度性上同使用其他几种内核对象的方法也有所不同,其他内核对象在没有得到通知时,受调用等待函数的作用,线程将会挂起,同时失去可调度性,而使用互斥的方法却可以在等待的同时仍具有可调度性,这也正是互斥对象所能完成的非常规操作之一。
在编写程序时,互斥对象多用在对那些为多个线程所访问的内存块的保护上,可以确保任何线程在处理此内存块时都对其拥有可靠的独占访问权。下面给出的示例代码即通过互斥内核对象hMutex对共享内存快g_cArray[]进行线程的独占访问保护。下面给出实现代码清单:
// 互斥对象
HANDLE hMutex = NULL;
char g_cArray[10];
UINT ThreadProc18(LPVOID pParam)
{
// 等待互斥对象通知
WaitForSingleObject(hMutex, INFINITE);
// 对共享资源进行写入操作
for (int i = 0; i < 10; i++)
{
g_cArray[i] = 'a';
Sleep(1);
}
// 释放互斥对象
ReleaseMutex(hMutex);
return 0;
}
UINT ThreadProc19(LPVOID pParam)
{
// 等待互斥对象通知
WaitForSingleObject(hMutex, INFINITE);
// 对共享资源进行写入操作
for (int i = 0; i < 10; i++)
{
g_cArray[10 - i - 1] = 'b';
Sleep(1);
}
// 释放互斥对象
ReleaseMutex(hMutex);
return 0;
}
……
void CSample08View::OnMutex()
{
// 创建互斥对象
hMutex = CreateMutex(NULL, FALSE, NULL);
// 启动线程
AfxBeginThread(ThreadProc18, NULL);
AfxBeginThread(ThreadProc19, NULL);
// 等待计算完毕
Sleep(300);
// 报告计算结果
CString sResult = CString(g_cArray);
AfxMessageBox(sResult);
} |
互斥对象在MFC中通过CMutex类进行表述。使用CMutex类的方法非常简单,在构造CMutex类对象的同时可以指明待查询的互斥对象的名字,在构造函数返回后即可访问此互斥变量。CMutex类也是只含有构造函数这唯一的成员函数,当完成对互斥对象保护资源的访问后,可通过调用从父类CSyncObject继承的UnLock()函数完成对互斥对象的释放。CMutex类构造函数原型为:
| CMutex( BOOL bInitiallyOwn = FALSE, LPCTSTR lpszName = NULL, LPSECURITY_ATTRIBUTES lpsaAttribute = NULL ); |
该类的适用范围和实现原理与API方式创建的互斥内核对象是完全类似的,但要简洁的多,下面给出就是对前面的示例代码经CMutex类改写后的程序实现清单:
// MFC互斥类对象
CMutex g_clsMutex(FALSE, NULL);
UINT ThreadProc27(LPVOID pParam)
{
// 等待互斥对象通知
g_clsMutex.Lock();
// 对共享资源进行写入操作
for (int i = 0; i < 10; i++)
{
g_cArray[i] = 'a';
Sleep(1);
}
// 释放互斥对象
g_clsMutex.Unlock();
return 0;
}
UINT ThreadProc28(LPVOID pParam)
{
// 等待互斥对象通知
g_clsMutex.Lock();
// 对共享资源进行写入操作
for (int i = 0; i < 10; i++)
{
g_cArray[10 - i - 1] = 'b';
Sleep(1);
}
// 释放互斥对象
g_clsMutex.Unlock();
return 0;
}
……
void CSample08View::OnMutexMfc()
{
// 启动线程
AfxBeginThread(ThreadProc27, NULL);
AfxBeginThread(ThreadProc28, NULL);
// 等待计算完毕
Sleep(300);
// 报告计算结果
CString sResult = CString(g_cArray);
AfxMessageBox(sResult);
} |
小结
线程的使用使程序处理更够更加灵活,而这种灵活同样也会带来各种不确定性的可能。尤其是在多个线程对同一公共变量进行访问时。虽然未使用线程同步的程序代码在逻辑上或许没有什么问题,但为了确保程序的正确、可靠运行,必须在适当的场合采取线程同步措施。
产生死锁的四个必要条件:
(1) 互斥条件:一个资源每次只能被一个进程使用。
(2) 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
(3) 不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
(4) 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
产生死锁的四个必要条件:
(1) 互斥条件:一个资源每次只能被一个进程使用。
(2) 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
(3) 不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
(4) 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
二 锁的分类
锁的类别有两种分法:
1. 从数据库系统的角度来看:分为独占锁(即排它锁),共享锁和更新锁
MS-SQL Server 使用以下资源锁模式。
锁模式 描述
共享 (S) :读锁,用于不更改或不更新数据的操作(只读操作),如 SELECT 语句。
更新 (U) :(介于共享和排它锁之间),可以让其他程序在不加锁的条件下读,但本程序可以随时更改。
读取表时使用更新锁,而不使用共享锁,并将锁一直保留到语句或事务的结束。UPDLOCK 的优点是允许您读取数据(不阻塞其它事务)并在以后更新数据,同时确保自从上次读取数据后数据没有被更改。当我们用UPDLOCK来读取记录时可以对取到的记录加上更新锁,从而加上锁的记录在其它的线程中是不能更改的只能等本线程的事务结束后才能更改,我如下示例:
BEGIN TRANSACTION --开始一个事务
SELECT Qty
FROM myTable WITH (UPDLOCK)
WHERE Id in (1,2,3)
UPDATE myTable SET Qty = Qty - A.Qty
FROM myTable AS A
INNER JOIN @_Table AS B ON A.ID = B.ID
COMMIT TRANSACTION --提交事务
这样在更新时其它的线程或事务在这些语句执行完成前是不能更改ID是1,2,3的记录的.其它的都可以修改和读,1,2,3的只能读,要是修改的话只能等这些语句完成后才能操作.从而保证的数据的修改正确.
排它 (X):写锁。 用于数据修改操作,例如 INSERT、UPDATE 或 DELETE。确保不会同时同一资源进行多重更新。
意向锁 用于建立锁的层次结构。意向锁的类型为:意向共享 (IS)、意向排它 (IX) 以及与意向排它共享 (SIX)。
架构锁 在执行依赖于表架构的操作时使用。架构锁的类型为:架构修改 (Sch-M) 和架构稳定性 (Sch-S)。
大容量更新 (BU) 向表中大容量复制数据并指定了 TABLOCK 提示时使用。
共享锁
共享 (S) 锁允许并发事务读取 (SELECT) 一个资源。资源上存在共享 (S) 锁时,任何其它事务都不能修改数据。一旦已经读取数据,便立即释放资源上的共享 (S) 锁,除非将事务隔离级别设置为可重复读或更高级别,或者在事务生存周期内用锁定提示保留共享 (S) 锁。
更新锁
更新 (U) 锁可以防止通常形式的死锁。一般更新模式由一个事务组成,此事务读取记录,获取资源(页或行)的共享 (S) 锁,然后修改行,此操作要求锁转换为排它 (X) 锁。如果两个事务获得了资源上的共享模式锁,然后试图同时更新数据,则一个事务尝试将锁转换为排它 (X) 锁。共享模式到排它锁的转换必须等待一段时间,因为一个事务的排它锁与其它事务的共享模式锁不兼容;发生锁等待。第二个事务试图获取排它 (X) 锁以进行更新。由于两个事务都要转换为排它 (X) 锁,并且每个事务都等待另一个事务释放共享模式锁,因此发生死锁。
若要避免这种潜在的死锁问题,请使用更新 (U) 锁。一次只有一个事务可以获得资源的更新 (U) 锁。如果事务修改资源,则更新 (U) 锁转换为排它 (X) 锁。否则,锁转换为共享锁。
排它锁
排它 (X) 锁可以防止并发事务对资源进行访问。其它事务不能读取或修改排它 (X) 锁锁定的数据。
意向锁
意向锁表示 SQL Server 需要在层次结构中的某些底层资源上获取共享 (S) 锁或排它 (X) 锁。例如,放置在表级的共享意向锁表示事务打算在表中的页或行上放置共享 (S) 锁。在表级设置意向锁可防止另一个事务随后在包含那一页的表上获取排它 (X) 锁。意向锁可以提高性能,因为 SQL Server 仅在表级检查意向锁来确定事务是否可以安全地获取该表上的锁。而无须检查表中的每行或每页上的锁以确定事务是否可以锁定整个表。
意向锁包括意向共享 (IS)、意向排它 (IX) 以及与意向排它共享 (SIX)。
死锁原理
根据操作系统中的定义:死锁是指在一组进程中的各个进程均占有不会释放的资源,但因互相申请被其他进程所站用不会释放的资源而处于的一种永久等待状态。
死锁的四个必要条件:
互斥条件(Mutual exclusion):资源不能被共享,只能由一个进程使用。
请求与保持条件(Hold and wait):已经得到资源的进程可以再次申请新的资源。
非剥夺条件(No pre-emption):已经分配的资源不能从相应的进程中被强制地剥夺。
循环等待条件(Circular wait):系统中若干进程组成环路,该环路中每个进程都在等待相邻进程正占用的资源。
对应到SQL Server中,当在两个或多个任务中,如果每个任务锁定了其他任务试图锁定的资源,此时会造成这些任务永久阻塞,从而出现死锁;这些资源可能是:单行(RID,堆中的单行)、索引中的键(KEY,行锁)、页(PAG,8KB)、区结构(EXT,连续的8页)、堆或B树(HOBT) 、表(TAB,包括数据和索引)、文件(File,数据库文件)、应用程序专用资源(APP)、元数据(METADATA)、分配单元(Allocation_Unit)、整个数据库(DB)。一个死锁示例如下图所示:
说明:T1、T2表示两个任务;R1和R2表示两个资源;由资源指向任务的箭头(如R1->T1,R2->T2)表示该资源被改任务所持有;由任务指向资源的箭头(如T1->S2,T2->S1)表示该任务正在请求对应目标资源;
其满足上面死锁的四个必要条件:
(1).互斥:资源S1和S2不能被共享,同一时间只能由一个任务使用;
(2).请求与保持条件:T1持有S1的同时,请求S2;T2持有S2的同时请求S1;
(3).非剥夺条件:T1无法从T2上剥夺S2,T2也无法从T1上剥夺S1;
(4).循环等待条件:上图中的箭头构成环路,存在循环等待。
2. 死锁排查
(1). 使用SQL Server的系统存储过程sp_who和sp_lock,可以查看当前数据库中的锁情况;进而根据objectID(@objID)(SQL Server 2005)/object_name(@objID)(Sql Server 2000)可以查看哪个资源被锁,用dbcc ld(@blk),可以查看最后一条发生给SQL Server的Sql语句;
CREATE Table #Who(spid int,
ecid int,
status nvarchar(50),
loginname nvarchar(50),
hostname nvarchar(50),
blk int,
dbname nvarchar(50),
cmd nvarchar(50),
request_ID int);
CREATE Table #Lock(spid int,
dpid int,
objid int,
indld int,
[Type] nvarchar(20),
Resource nvarchar(50),
Mode nvarchar(10),
Status nvarchar(10)
);
INSERT INTO #Who
EXEC sp_who active --看哪个引起的阻塞,blk
INSERT INTO #Lock
EXEC sp_lock --看锁住了那个资源id,objid
DECLARE @DBName nvarchar(20);
SET @DBName='NameOfDataBase'
SELECT #Who.* FROM #Who WHERE dbname=@DBName
SELECT #Lock.* FROM #Lock
JOIN #Who
ON #Who.spid=#Lock.spid
AND dbname=@DBName;
--最后发送到SQL Server的语句
DECLARE crsr Cursor FOR
SELECT blk FROM #Who WHERE dbname=@DBName AND blk<>0;
DECLARE @blk int;
open crsr;
FETCH NEXT FROM crsr INTO @blk;
WHILE (@@FETCH_STATUS = 0)
BEGIN;
dbcc inputbuffer(@blk);
FETCH NEXT FROM crsr INTO @blk;
END;
close crsr;
DEALLOCATE crsr;
--锁定的资源
SELECT #Who.spid,hostname,objid,[type],mode,object_name(objid) as objName FROM #Lock
JOIN #Who
ON #Who.spid=#Lock.spid
AND dbname=@DBName
WHERE objid<>0;
DROP Table #Who;
DROP Table #Lock;
(2). 使用 SQL ServerProfiler 分析死锁: 将 Deadlock graph 事件类添加到跟踪。此事件类使用死锁涉及到的进程和对象的 XML 数据填充跟踪中的 TextData 数据列。SQL Server 事件探查器 可以将 XML 文档提取到死锁 XML (.xdl) 文件中,以后可在 SQL Server Management Studio 中查看该文件。
3. 避免死锁
上面1中列出了死锁的四个必要条件,我们只要想办法破其中的任意一个或多个条件,就可以避免死锁发生,一般有以下几种方法(FROM Sql Server 2005联机丛书):
(1).按同一顺序访问对象。(注:避免出现循环)
(2).避免事务中的用户交互。(注:减少持有资源的时间,较少锁竞争)
(3).保持事务简短并处于一个批处理中。(注:同(2),减少持有资源的时间)
(4).使用较低的隔离级别。(注:使用较低的隔离级别(例如已提交读)比使用较高的隔离级别(例如可序列化)持有共享锁的时间更短,减少锁竞争)
(5).使用基于行版本控制的隔离级别:2005中支持快照事务隔离和指定READ_COMMITTED隔离级别的事务使用行版本控制,可以将读与写操作之间发生的死锁几率降至最低:
SETALLOW_SNAPSHOT_ISOLATION ON --事务可以指定 SNAPSHOT 事务隔离级别;
SET READ_COMMITTED_SNAPSHOT ON --指定 READ_COMMITTED 隔离级别的事务将使用行版本控制而不是锁定。默认情况下(没有开启此选项,没有加with nolock提示),SELECT语句会对请求的资源加S锁(共享锁);而开启了此选项后,SELECT不会对请求的资源加S锁。
注意:设置 READ_COMMITTED_SNAPSHOT 选项时,数据库中只允许存在执行 ALTER DATABASE 命令的连接。在 ALTER DATABASE 完成之前,数据库中决不能有其他打开的连接。数据库不必一定要处于单用户模式中。
(6).使用绑定连接。(注:绑定会话有利于在同一台服务器上的多个会话之间协调操作。绑定会话允许一个或多个会话共享相同的事务和锁(但每个回话保留其自己的事务隔离级别),并可以使用同一数据,而不会有锁冲突。可以从同一个应用程序内的多个会话中创建绑定会话,也可以从包含不同会话的多个应用程序中创建绑定会话。在一个会话中开启事务(begin tran)后,调用exec sp_getbindtoken @Token out;来取得Token,然后传入另一个会话并执行EXEC sp_bindsession @Token来进行绑定(最后的示例中演示了绑定连接)。
4. 死锁处理方法:
(1). 根据2中提供的sql,查看那个spid处于wait状态,然后用kill spid来干掉(即破坏死锁的第四个必要条件:循环等待);当然这只是一种临时解决方案,我们总不能在遇到死锁就在用户的生产环境上排查死锁、Kill sp,我们应该考虑如何去避免死锁。
(2). 使用SET LOCK_TIMEOUT timeout_period(单位为毫秒)来设定锁请求超时。默认情况下,数据库没有超时期限(timeout_period值为-1,可以用SELECT@@LOCK_TIMEOUT来查看该值,即无限期等待)。当请求锁超过timeout_period时,将返回错误。timeout_period值为0时表示根本不等待,一遇到锁就返回消息。设置锁请求超时,破环了死锁的第二个必要条件(请求与保持条件)。
服务器: 消息 1222,级别 16,状态 50,行 1
已超过了锁请求超时时段。
(3). SQL Server内部有一个锁监视器线程执行死锁检查,锁监视器对特定线程启动死锁搜索时,会标识线程正在等待的资源;然后查找特定资源的所有者,并递归地继续执行对那些线程的死锁搜索,直到找到一个构成死锁条件的循环。检测到死锁后,数据库引擎 选择运行回滚开销最小的事务的会话作为死锁牺牲品,返回1205 错误,回滚死锁牺牲品的事务并释放该事务持有的所有锁,使其他线程的事务可以请求资源并继续运行。
5. 两个死锁示例及解决方法
5.1 SQL死锁
(1). 测试用的基础数据:
CREATE TABLE Lock1(C1 int default(0));
CREATE TABLE Lock2(C1 int default(0));
INSERT INTO Lock1 VALUES(1);
INSERT INTO Lock2 VALUES(1);
(2). 开两个查询窗口,分别执行下面两段sql
--Query 1
Begin Tran
Update Lock1 Set C1=C1+1;
WaitFor Delay '00:01:00';
SELECT * FROM Lock2
Rollback Tran;
--Query 2
Begin Tran
Update Lock2 Set C1=C1+1;
WaitFor Delay '00:01:00';
SELECT * FROM Lock1
Rollback Tran;
上面的SQL中有一句WaitFor Delay '00:01:00',用于等待1分钟,以方便查看锁的情况。
(3). 查看锁情况
在执行上面的WaitFor语句期间,执行第二节中提供的语句来查看锁信息:
Query1中,持有Lock1中第一行(表中只有一行数据)的行排他锁(RID:X),并持有该行所在页的意向更新锁(PAG:IX)、该表的意向更新锁(TAB:IX);Query2中,持有Lock2中第一行(表中只有一行数据)的行排他锁(RID:X),并持有该行所在页的意向更新锁(PAG:IX)、该表的意向更新锁(TAB:IX);
执行完Waitfor,Query1查询Lock2,请求在资源上加S锁,但该行已经被Query2加上了X锁;Query2查询Lock1,请求在资源上加S锁,但该行已经被Query1加上了X锁;于是两个查询持有资源并互不相让,构成死锁。
(4). 解决办法
a). SQL Server自动选择一条SQL作死锁牺牲品:运行完上面的两个查询后,我们会发现有一条SQL能正常执行完毕,而另一个SQL则报如下错误:
服务器: 消息 1205,级别 13,状态 50,行 1
事务(进程 ID xx)与另一个进程已被死锁在 lock 资源上,且该事务已被选作死锁牺牲品。请重新运行该事务。
这就是上面第四节中介绍的锁监视器干活了。
b). 按同一顺序访问对象:颠倒任意一条SQL中的Update与SELECT语句的顺序。例如修改第二条SQL成如下:
--Query2
Begin Tran
SELECT * FROM Lock1--在Lock1上申请S锁
WaitFor Delay '00:01:00';
Update Lock2 Set C1=C1+1;--Lock2:RID:X
Rollback Tran;
当然这样修改也是有代价的,这会导致第一条SQL执行完毕之前,第二条SQL一直处于阻塞状态。单独执行Query1或Query2需要约1分钟,但如果开始执行Query1时,马上同时执行Query2,则Query2需要2分钟才能执行完;这种按顺序请求资源从一定程度上降低了并发性。
c). SELECT语句加With(NoLock)提示:默认情况下SELECT语句会对查询到的资源加S锁(共享锁),S锁与X锁(排他锁)不兼容;但加上With(NoLock)后,SELECT不对查询到的资源加锁(或者加Sch-S锁,Sch-S锁可以与任何锁兼容);从而可以是这两条SQL可以并发地访问同一资源。当然,此方法适合解决读与写并发死锁的情况,但加With(NoLock)可能会导致脏读。
SELECT * FROM Lock2 WITH(NOLock)
SELECT * FROM Lock1 WITH(NOLock)
d). 使用较低的隔离级别。SQL Server 2000支持四种事务处理隔离级别(TIL),分别为:READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ、SERIALIZABLE;SQL Server 2005中增加了SNAPSHOT TIL。默认情况下,SQL Server使用READ COMMITTED TIL,我们可以在上面的两条SQL前都加上一句SET TRANSACTION ISOLATION LEVEL READUNCOMMITTED,来降低TIL以避免死锁;事实上,运行在READ UNCOMMITTED TIL的事务,其中的SELECT语句不对结果资源加锁或加Sch-S锁,而不会加S锁;但还有一点需要注意的是:READ UNCOMMITTED TIL允许脏读,虽然加上了降低TIL的语句后,上面两条SQL在执行过程中不会报错,但执行结果是一个返回1,一个返回2,即读到了脏数据,也许这并不是我们所期望的。
e). 在SQL前加SET LOCK_TIMEOUT timeout_period,当请求锁超过设定的timeout_period时间后,就会终止当前SQL的执行,牺牲自己,成全别人。
f). 使用基于行版本控制的隔离级别(SQL Server2005支持):开启下面的选项后,SELECT不会对请求的资源加S锁,不加锁或者加Sch-S锁,从而将读与写操作之间发生的死锁几率降至最低;而且不会发生脏读。啊
SET ALLOW_SNAPSHOT_ISOLATION ON
SET READ_COMMITTED_SNAPSHOT ON
g). 使用绑定连接(使用方法见下一个示例。)
5.2 程序死锁(SQL阻塞)
看一个例子:一个典型的数据库操作事务死锁分析,按照我自己的理解,我觉得这应该算是C#程序中出现死锁,而不是数据库中的死锁;下面的代码模拟了该文中对数据库的操作过程:
//略去的无关的code
SqlConnection conn = new SqlConnection(connectionString);
conn.Open();
SqlTransaction tran = conn.BeginTransaction();
string sql1 = "Update Lock1 SET C1=C1+1";
string sql2 = "SELECT * FROM Lock1";
ExecuteNonQuery(tran, sql1); //使用事务:事务中Lock了Table
ExecuteNonQuery(null, sql2); //新开一个connection来读取Table
public static void ExecuteNonQuery(SqlTransaction tran, string sql)
{
SqlCommand cmd = new SqlCommand(sql);
if (tran != null)
{
cmd.Connection = tran.Connection;
cmd.Transaction = tran;
cmd.ExecuteNonQuery();
}
else
{
using (SqlConnection conn = new SqlConnection(connectionString))
{
conn.Open();
cmd.Connection = conn;
cmd.ExecuteNonQuery();
}
}
}
执行到ExecuteNonQuery(null, sql2)时抛出SQL执行超时的异常,下图从数据库的角度来看该问题:
代码从上往下执行,会话1持有了表Lock1的X锁,且事务没有结束,回话1就一直持有X锁不释放;而会话2执行select操作,请求在表Lock1上加S锁,但S锁与X锁是不兼容的,所以回话2的被阻塞等待,不在等待中,就在等待中获得资源,就在等待中超时。。。从中我们可以看到,里面并没有出现死锁,而只是SELECT操作被阻塞了。也正因为不是数据库死锁,所以SQL Server的锁监视器无法检测到死锁。
我们再从C#程序的角度来看该问题:
C#程序持有了表Lock1上的X锁,同时开了另一个SqlConnection还想在该表上请求一把S锁,图中已经构成了环路;太贪心了,结果自己把自己给锁死了。。。
虽然这不是一个数据库死锁,但却是因为数据库资源而导致的死锁,上例中提到的解决死锁的方法在这里也基本适用,主要是避免读操作被阻塞,解决方法如下:
a).把SELECT放在Update语句前:SELECT不在事务中,且执行完毕会释放S锁;
b). 把SELECT也放加入到事务中:ExecuteNonQuery(tran, sql2);
c). SELECT加With(NOLock)提示:可能产生脏读;
d). 降低事务隔离级别:SELECT语句前加SET TRANSACTION ISOLATION LEVEL READUNCOMMITTED;同上,可能产生脏读;
e). 使用基于行版本控制的隔离级别(同上例)。
g). 使用绑定连接:取得事务所在会话的token,然后传入新开的connection中;执行EXEC sp_bindsession @Token后绑定了连接,最后执行exec sp_bindsession null;来取消绑定;最后需要注意的四点是:
(1). 使用了绑定连接的多个connection共享同一个事务和相同的锁,但各自保留自己的事务隔离级别;
(2). 如果在sql3字符串的“exec sp_bindsession null”换成“commit tran”或者“rollback tran”,则会提交整个事务,最后一行C#代码tran.Commit()就可以不用执行了(执行会报错,因为事务已经结束了-,-)。
(3). 开启事务(begintran)后,才可以调用execsp_getbindtoken @Token out来取得Token;如果不想再新开的connection中结束掉原有的事务,则在这个connection close之前,必须执行“exec sp_bindsession null”来取消绑定连接,或者在新开的connectoin close之前先结束掉事务(commit/tran)。
(4). (Sql server 2005 联机丛书)后续版本的Microsoft SQL Server 将删除该功能。请避免在新的开发工作中使用该功能,并着手修改当前还在使用该功能的应用程序。 请改用多个活动结果集 (MARS) 或分布式事务。
tran = connection.BeginTransaction();
string sql1 = "Update Lock1 SET C1=C1+1";
ExecuteNonQuery(tran, sql1); //使用事务:事务中Lock了测试表Lock1
string sql2 = @"DECLARE @Token varchar(255);
exec sp_getbindtoken @Token out;
SELECT @Token;";
string token = ExecuteScalar(tran, sql2).ToString();
string sql3 = "EXEC sp_bindsession @Token;Update Lock1 SET C1=C1+1;exec sp_bindsession null;";
SqlParameter parameter = new SqlParameter("@Token", SqlDbType.VarChar);
parameter.Value = token;
ExecuteNonQuery(null, sql3, parameter); //新开一个connection来操作测试表Lock1
tran.Commit();
HAHAHAHHAHAHAHHAHAHAHAHAHAHAHAHAHAHAHAHAHAHAHAHAHAH一篇非常棒的文章
注:本文发表于《程序员》2011年第8期并行编程专栏,略有删改。
在并行程序中,锁的使用会主要会引发两类难题:一类是诸如死锁、活锁等引起的多线程Bug;另一类是由锁竞争引起的性能瓶颈。本文将介绍并行编程中因为锁引发的这两类难题及其解决方案。
1. 用锁来防止数据竞跑
在进行并行编程时,我们常常需要使用锁来保护共享变量,以防止多个线程同时对该变量进行更新时产生数据竞跑(Data Race)。所谓数据竞跑,是指当两个(或多个)线程同时对某个共享变量进行操作,且这些操作中至少有一个是写操作时所造成的程序错误。例1中的两个线程可能同时执行“counter++”从而产生数据竞跑,造成counter最终值为1(而不是正确值2)。
例1:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
|
#include <pthread.h>
int
counter = 0;
void
*func(
void
*params)
{
counter++;
}
void
main()
{
pthread_t thread1, thread2;
pthread_create(&thread1, 0, func, 0);
pthread_create(&thread2, 0, func, 0);
pthread_join(thread1, 0 );
pthread_join(thread2, 0 );
}
|
这是因为counter++本身是由三条汇编指令构成的(从主存中将counter的值读到寄存器中;对寄存器进行加1操作;将寄存器中的新值写回主存),所以例1中的两个线程可能按如下交错顺序执行,导致counter的最终值为1:
例2:
|
01
02
03
04
05
06
|
load [%counter], rax;
add rax, 1;
load [%counter], rbx;
store rax [%counter];
add rbx, 1;
store rbx, [%counter];
|
为了防止例1中的数据竞跑现象,我们可以使用锁来保证每个线程对counter++操作的独占访问(即保证该操作是原子的)。在例3的程序中,我们使用mutex锁将counter++操作放入临界区中,这样同一时刻只有获取锁的线程能访问该临界区,保证了counter++的原子性:即只有在线程1执行完counter++的三条指令之后线程2才能执行counter++操作,保证了counter的最终值必定为2。
例3:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
#include <pthread.h>
int
counter = 0;
pthread_mutex_t mutex;
void
*func(
void
*params)
{
pthread_mutex_lock(&mutex);
counter++;
pthread_mutex_unlock(&mutex);
}
void
main()
{
pthread_t thread1, thread2;
pthread_mutex_init(&mutex);
pthread_create(&thread1, 0, func, 0);
pthread_create(&thread2, 0, func, 0);
pthread_join(thread1, 0 );
pthread_join(thread2, 0 );
pthread_mutex_destroy(&mutex);
}
|
2. 死锁和活锁
然而,锁的使用非常容易导致多线程Bug,最常见的莫过于死锁和活锁。从原理上讲,死锁的产生是由于两个(或多个)线程在试图获取正被其他线程占有的资源时造成的线程停滞。在下例中,假设线程1在获取mutex_a锁之后正在尝试获取mutex_b锁,而线程2此时已经获取了mutex_b锁并正在尝试获取mutex_a锁,两个线程就会因为获取不到自己想要的资源、且自己正占有着对方想要的资源而停滞,从而产生死锁。
例4:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
|
void
func1()
{
LOCK(&mutex_a);
LOCK(&mutex_b);
counter++;
UNLOCK(&mutex_b);
UNLOCK(&mutex_a);
}
void
func2()
{
LOCK(&mutex_b);
LOCK(&mutex_a);
counter++;
UNLOCK(&mutex_a);
UNLOCK(&mutex_b);
}
|
例4中的死锁其实是最简单的情形,在实际的程序中,死锁往往发生在复杂的函数调用过程中。在下面这个例子中,线程1在func1()中获取了mutex_a锁,之后调用func_call1()并在其函数体中尝试获取mutex_b锁;与此同时线程2在func2()中获取了mutex_b锁之后再在func_call2()中尝试获取mutex_a锁从而造成死锁。可以想象,随着程序复杂度的增加,想要正确的检测出死锁会变得越来越困难。
例5:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
void
func1()
{
LOCK(&mutex_a);
...
func_call1();
UNLOCK(&mutex_a);
}
func_call1()
{
LOCK(&mutex_b);
...
UNLOCK(&mutex_b);
...
}
void
func2()
{
LOCK(&mutex_b);
...
func_call2()
UNLOCK(&mutex_b);
}
func_call2()
{
LOCK(&mutex_a);
...
UNLOCK(&mutex_b);
...
}
|
其实避免死锁的方法非常简单,其基本原则就是保证各个线程加锁操作的执行顺序是全局一致的。例如,如果上例中的线程1和线程2都是先对mutex_a加锁再对mutex_b进行加锁就不会产生死锁了。在实际的软件开发中,除了严格遵守相同加锁顺序的原则防止死锁之外,我们还可以使用RAII(Resource Acquisition Is Initialization,即“资源获取即初始化”)的手段来封装加锁解锁操作,从而帮助减少死锁的发生[1]。
除死锁外,多个线程的加锁、解锁操作还可能造成活锁。在下例中,程序员为了防止死锁的产生而做了如下处理:当线程1在获取了mutex_a锁之后再尝试获取mutex_b时,线程1通过调用一个非阻塞的加锁操作(类似pthread_mutex_trylock)来尝试进行获得mutex_b:如果线程1成功获得mutex_b,则trylock()加锁成功并返回true,如果失败则返回false。线程2也使用了类似的方法来保证不会出现死锁。不幸的是,这种方法虽然防止了死锁的产生,却可能造成活锁。例如,在线程1获得mutex_a锁之后尝试获取mutex_b失败,则线程1会释放mutex_a并进入下一次while循环;如果此时线程2在线程1进行TRYLOCK(&mutex_b)的同时执行TRYLOCK(&mutex_a),那么线程2也会获取mutex_a失败,并接着释放mutex_b及进入下一次while循环;如此反复,两个线程都可能在较长时间内不停的进行“获得一把锁、尝试获取另一把锁失败、再解锁之前已获得的锁“的循环,从而产生活锁现象。当然,在实际情况中,因为多个线程之间调度的不确定性,最终必定会有一个线程能同时获得两个锁,从而结束活锁。尽管如此,活锁现象确实会产生不必要的性能延迟,所以需要大家格外注意。
例6:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
void
func1()
{
int
done = 0;
while
(!done) {
LOCK(&mutex_a);
if
(TRYLOCK(&mutex_b)) {
counter++;
UNLOCK(&mutex_b);
UNLOCK(&mutex_a);
done = 1;
}
else
{
UNLOCK(&mutex_a);
}
}
}
void
func2()
{
int
done = 0;
while
(!done) {
LOCK(&mutex_b);
if
(TRYLOCK(&mutex_a)) {
counter++;
UNLOCK(&mutex_a);
UNLOCK(&mutex_b);
done = 1;
}
else
{
UNLOCK(&mutex_b);
}
}
}
|
3. 锁竞争性能瓶颈
在多线程程序中锁竞争是最主要的性能瓶颈之一。在前面我们也提到过,通过使用锁来保护共享变量能防止数据竞跑,保证同一时刻只能有一个线程访问该临界区。但是我们也注意到,正是因为锁造成的对临界区的串行执行导致了并行程序的性能瓶颈。
3.1阿姆达尔法则(Amdahl’s Law)
在介绍锁竞争引起的性能瓶颈之前,让我们先来了解一下阿姆达尔法则。我们知道,一个并行程序是由两部分组成的:串行执行的部分和可以并行执行的部分。假设串行部分的执行时间为S,可并行执行部分的执行时间为P,则整个并行程序使用单线程(单核)串行执行的时间为S+P。阿姆达尔法则规定,可并行执行部分的执行时间与线程数目成反比:即如果有N个线程(N核CPU)并行执行这个可并行的部分,则该部分的执行时间为P/N。由此我们可以得到并行程序总体执行时间的公式:
根据这个公式,我们可以得到一些非常有意思的结论。例如,如果一个程序全部代码都可以被并行执行,那么它的加速比会非常好,即随着线程数(CPU核数)的增多该程序的加速比会线性递增。换句话说,如果单线程执行该程序需要16秒钟,用16个线程执行该程序就只需要1秒钟。
然而,如果这个程序只有80%的代码可以被并行执行,它的加速比却会急剧下降。根据阿姆达尔法则,如果用16个线程并行执行次程序可并行的部分,该程序的总体执行时间T = S + P/N = (16*0.2) + (16*0.8)/16 = 4秒,这比完全并行化的情况(只需1秒)足足慢了4倍!实际上,如果该程序只有50%的代码可以被并行执行,在使用16个线程时该程序的执行时间仍然需要8.5秒!
从阿姆达尔法则我们可以看到,并行程序的性能很大程度上被只能串行执行的部分给限制住了,而由锁竞争引起的串行执行正是造成串行性能瓶颈的主要原因之一。
3.2锁竞争的常用解决办法
3.2.1 避免使用锁
为了提高程序的并行性,最好的办法自然是不使用锁。从设计角度上来讲,锁的使用无非是为了保护共享资源。如果我们可以避免使用共享资源的话那自然就避免了锁竞争造成的性能损失。幸运的是,在很多情况下我们都可以通过资源复制的方法让每个线程都拥有一份该资源的副本,从而避免资源的共享。如果有需要的话,我们也可以让每个线程先访问自己的资源副本,只在程序的后讲各个线程的资源副本合并成一个共享资源。例如,如果我们需要在多线程程序中使用计数器,那么我们可以让每个线程先维护一个自己的计数器,只在程序的最后将各个计数器两两归并(类比二叉树),从而最大程度提高并行度,减少锁竞争。
3.2.2 使用读写锁
如果对共享资源的访问多数为读操作,少数为写操作,而且写操作的时间非常短,我们就可以考虑使用读写锁来减少锁竞争。读写锁的基本原则是同一时刻多个读线程可以同时拥有读者锁并进行读操作;另一方面,同一时刻只有一个写进程可以拥有写者锁并进行写操作。读者锁和写者锁各自维护一份等待队列。当拥有写者锁的写进程释放写者锁时,所有正处于读者锁等待队列里的读线程全部被唤醒并被授予读者锁以进行读操作;当这些读线程完成读操作并释放读者锁时,写者锁中的第一个写进程被唤醒并被授予写者锁以进行写操作,如此反复。换句话说,多个读线程和一个写线程将交替拥有读写锁以完成相应操作。这里需要额外补充的一点是锁的公平调度问题。例如,如果在写者锁等待队列中有一个或多个写线程正在等待获得写者锁时,新加入的读线程会被放入读者锁的等待队列。这是因为,尽管这个新加入的读线程能与正在进行读操作的那些读线程并发读取共享资源,但是也不能赋予他们读权限,这样就防止了写线程被新到来的读线程无休止的阻塞。
需要注意的是,并不是所有的场合读写锁都具备更好的性能,大家应该根据Profling的测试结果来判断使用读写锁是否能真的提高性能,特别是要注意写操作虽然很少但很耗时的情况。
3.2.3 保护数据而不是操作
在实际程序中,有不少程序员在使用锁时图方便而把一些不必要的操作放在临界区中。例如,如果需要对一个共享数据结构进行删除和销毁操作,我们只需要把删除操作放在临界区中即可,资源销毁操作完全可以在临界区之外单独进行,以此增加并行度。
正是因为临界区的执行时间大大影响了并行程序的整体性能,我们必须尽量少在临界区中做耗时的操作,例如函数调用,数据查询,I/O操作等。简而言之,我们需要保护的只是那些共享资源,而不是对这些共享资源的操作,尽可能的把对共享资源的操作放到临界区之外执行有助于减少锁竞争带来的性能损失。
3.2.4 尽量使用轻量级的原子操作
在例3中,我们使用了mutex锁来保护counter++操作。实际上,counter++操作完全可以使用更轻量级的原子操作来实现,根本不需要使用mutex锁这样相对较昂贵的机制来实现。在今年程序员第四期的《volatile与多线程的那些事儿》中我们就有对Java和C/C++中的原子操作做过相应的介绍。
3.2.5 粗粒度锁与细粒度锁
为了减少串行部分的执行时间,我们可以通过把单个锁拆成多个锁的办法来较小临界区的执行时间,从而降低锁竞争的性能损耗,即把“粗粒度锁”转换成“细粒度锁”。但是,细粒度锁并不一定更好。这是因为粗粒度锁编程简单,不易出现死锁等Bug,而细粒度锁编程复杂,容易出错;而且锁的使用是有开销的(例如一个加锁操作一般需要100个CPU时钟周期),使用多个细粒度的锁无疑会增加加锁解锁操作的开销。在实际编程中,我们往往需要从编程复杂度、性能等多个方面来权衡自己的设计方案。事实上,在计算机系统设计领域,没有哪种设计是没有缺点的,只有仔细权衡不同方案的利弊才能得到最适合自己当前需求的解决办法。例如,Linux内核在初期使用了Big Kernel Lock(粗粒度锁)来实现并行化。从性能上来讲,使用一个大锁把所有操作都保护起来无疑带来了很大的性能损失,但是它却极大的简化了并行整个内核的难度。当然,随着Linux内核的发展,Big Kernel Lock已经逐渐消失并被细粒度锁而取代,以取得更好的性能。
3.2.6 使用无锁算法、数据结构
首先要强调的是,笔者并不推荐大家自己去实现无锁算法。为什么别去造无锁算法的轮子呢?因为高性能无锁算法的正确实现实在是太难了。有多难呢?Doug Lea提到java.util.concurrent库中一个Non Blocking的算法的实现大概需要1个人年,总共约500行代码。事实上,我推荐大家直接去使用一些并行库中已经实现好了的无锁算法、无锁数据结构,以提高并行程序的性能。典型的无锁算法的库有java.util.concurrent,Intel TBB等,它们都提供了诸如Non-blocking concurrent queue之类的数据结构以供使用。
HAHAHAHAHAHAHHAHAHAHAHAHAHAHAHAHAHAHAHAHHAHAHHAHAHHA
http://blog.csdn.net/iamherego/article/details/12704881 哈哈哈哈哈哈和























 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









