






» Zookeeper 作为 Hadoop 项目中的一个子项目,是Hadoop 集群管理的一个必不可少的模块,它主要用来控制集群中的数据,如它管理 Hadoop
集群中的NameNode,还有 Hbase 中 Master Election、Server 之间状态同步等。
» Zoopkeeper 提供了一套很好的分布式集群管理的机制,就是它这种基于层次型的目录树的数据结构,并对树中的节点进行有效管理,从而可以设计出
多种多样的分布式的数据管理模型
==============================================================================
============================================================================================================================================================
==============================================================================
之前,我们说过Hadoop的两个核心为HDFS和MapReduce,既然我们已经学习了Hadoop的HDFS,那么我们就来看看MapReduce是什么。当然,我们学习的顺序还是先看看基本概念,再研究一下原理,最后做一些练习。
一、是什么
1、概念理解
Hadoop Map/Reduce是一个使用简易的软件框架,基于它写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理上T级别的数据集。
2、Map(映射)
“Map”:主结点读入输入数据,把它分成可以用相同方法解决的小数据块(这里是一个分而治之的思想),然后把这些小数据块分发到不同的工作节点上(worder nodes)上,每一个工作节点(worder node)循环做同样的事,这就行成了一个树行结构(分布式计算中的很多模型都和图论有关,pageRank也是),而每一个叶子节点有来处理每一个具体的小数据块,再把这些处理结果返回给父节点。
3、Reduce(归约)
“Reduce”:主结节得到所有子节点的处理结果,然后把所有结果组合并且返回到输出。
4、个人理解
简单的来讲,map就是分,reduce就是合。怎么理解呢?我们来看个例子。
我们将100吨砖,从山东运到北京,如果我们用一辆能装1吨的大卡车来运,一天跑一个来回,那么我们需要100天,可是如果我们用10辆这样的车来做同样的事情,那么我们10天就可以完成了。虽然在现实生活中,我们增加了车费等一系列支出,可能不太划算,但是对于计算机来说,我们的成本是相当低的。所以在迎接大数据的到来时,MapReduce将大大提高的计算的速度,特别方便。
二、原理解析
1、图解细说
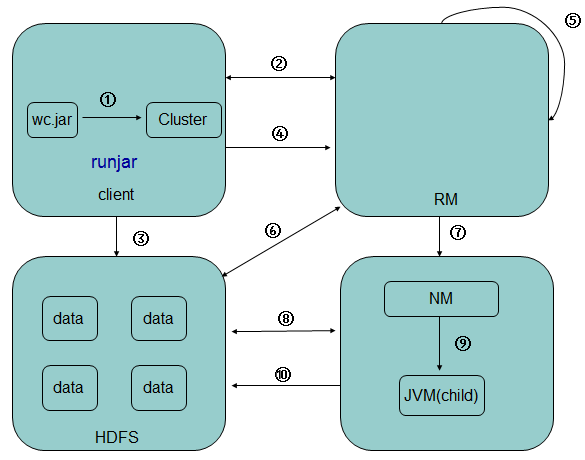
(1).客户端提交一个mr的jar包给JobClient(提交方式:hadoop jar ...)- 1
(2).JobClient通过RPC和JobTracker进行通信,返回一个存放jar包的地址(HDFS)和jobId- 1
(3).client将jar包写入到HDFS当中(path = hdfs上的地址 + jobId)- 1
(4).开始提交任务(任务的描述信息,不是jar, 包括jobid,jar存放的位置,配置信息等等)- 1
(5).JobTracker进行初始化任务(放入调度器)- 1
(6).读取HDFS上的要处理的文件,开始计算输入分片,每一个分片对应一个MapperTask- 1
(7).TaskTracker通过心跳机制领取任务(任务的描述信息)- 1
(8).下载所需的jar,配置文件等- 1
(9).TaskTracker启动一个java child子进程,用来执行具体的任务(MapperTask或ReducerTask)- 1
(10).将结果写入到HDFS当中- 1
经过自己的理解后,自己又画了一张运行图
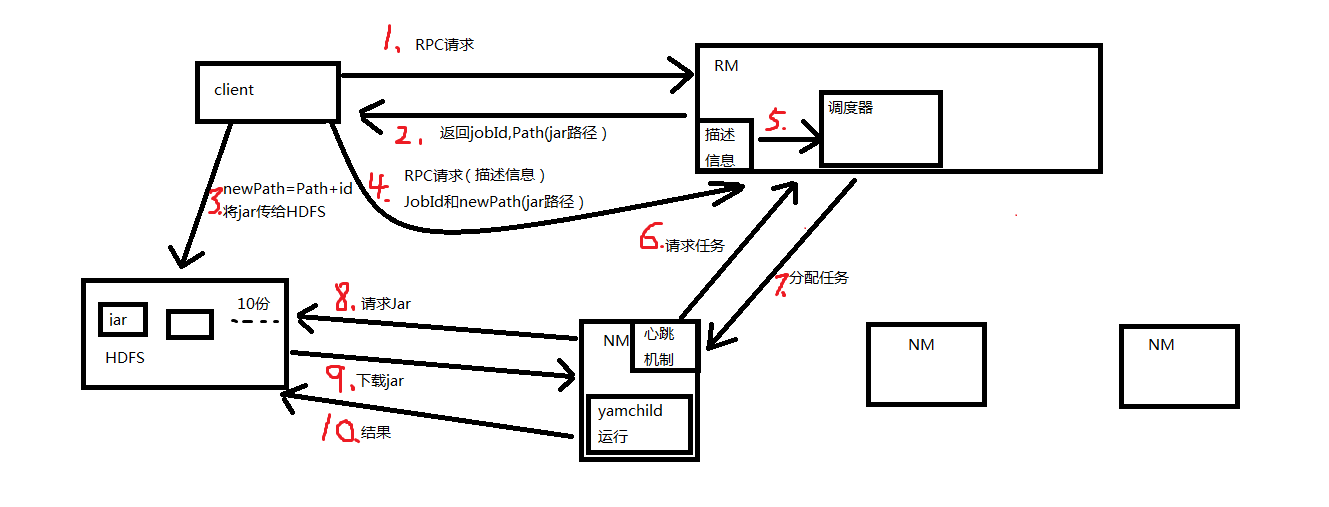
2、详细流程
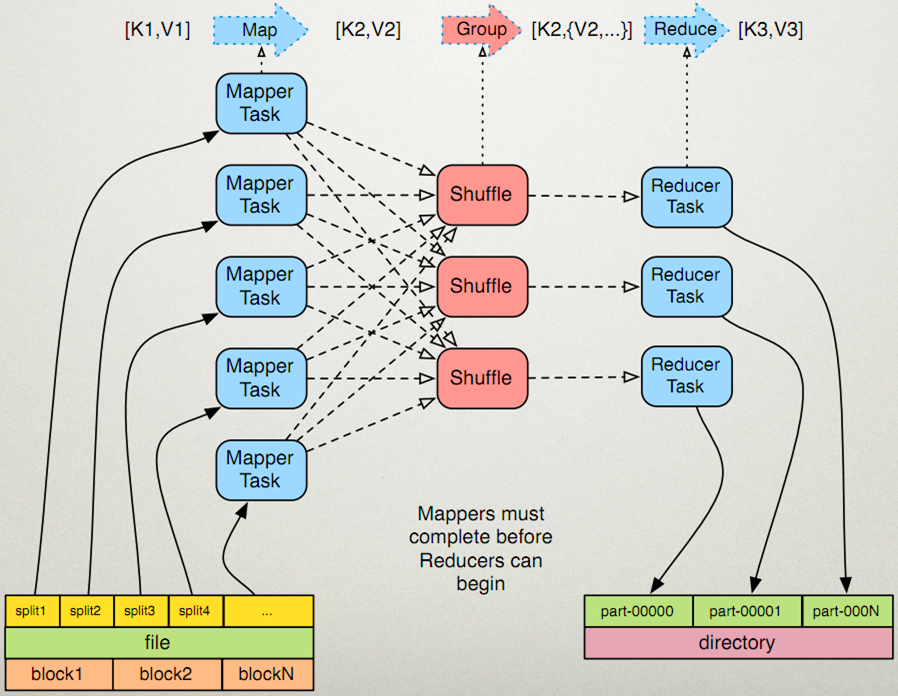
- map任务处理
读取输入文件内容,解析成key、value对。对输入文件的每一行,解析成key、value对。每一个键值对调用一次map函数。- 1
写自己的逻辑,对输入的key、value处理,转换成新的key、value输出。- 1
对输出的key、value进行分区。- 1
对不同分区的数据,按照key进行排序、分组。相同key的value放到一个集合中。- 1
(可选)分组后的数据进行归约。- 1
- reduce任务处理
对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。- 1
对多个map任务的输出进行合并、排序。写reduce函数自己的逻辑,对输入的key、value处理,转换成新的key、value输出。- 1
把reduce的输出保存到文件中。- 1
总结:
虽然之前学到的HDFS与今天的MapReduce是两个完全不一样的东西,但是通过今天的学习,我们知道了两者是如何协同工作的,这样对我们以后的实战是非常有帮助的。下次我们将通过实例,来深层解析MapReduce的运行机制,请大家继续关注。
=========================================================================================================================================================================================================================================================================================================================================================
Redis 优势
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s
=========================================================================================================================================================================================================================================================================================================================================================
Memcache和Redis区别:
- Redis中,并不是所有的数据都一直存储在内存中的,这是和Memcache相比一个最大的区别。
- Redis在很多方面具备数据库的特征,或者说就是一个数据库系统,而Memcache只是简单的K/V缓存。
- 他们的扩展都需要做集群;实现方式:master-slave、Hash。
- 在100k以上的数据中,Memcache性能要高于Redis。
- 如果要说内存使用效率,使用简单的key-value存储的话,Memcached的内存利用率更高,而如果Redis采用hash结构来做key-value存储,由于其组合式的压缩,其内存利用率会高于Memcache。当然,这和你的应用场景和数据特性有关。
- 如果你对数据持久化和数据同步有所要求,那么推荐你选择Redis,因为这两个特性Memcache都不具备。即使你只是希望在升级或者重启系统后缓存数据不会丢失,选择Redis也是明智的。
- Redis和Memcache在写入性能上面差别不大,读取性能上面尤其是批量读取性能上面Memcache更强
共同点:Memcache,Redis 都是内存数据库
区别:
Memcache
Memcache可以利用多核优势,单实例吞吐量极高,可以达到几十万QPS,适用于最大程度扛量
只支持简单的key/value数据结构,不像Redis可以支持丰富的数据类型。
无法进行持久化,数据不能备份,只能用于缓存使用,且重启后数据全部丢失
Redis
支持多种数据结构,如string,list,dict,set,zset,hyperloglog
单线程请求,所有命令串行执行,并发情况下不需要考虑数据一致性问题。
支持持久化操作,可以进行aof及rdb数据持久化到磁盘,从而进行数据备份或数据恢复等操作,较好的防止数据丢失的手段。
支持通过Replication进行数据复制,通过master-slave机制,可以实时进行数据的同步复制,支持多级复制和增量复制.
支持pub/sub消息订阅机制,可以用来进行消息订阅与通知。
支持简单的事务需求,但业界使用场景很少,并不成熟
====================================================================================================================================================================================================================================================================================
Hadoop是一个开发和运行处理大规模数据的软件平台,是Apache的一个用java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算。Hadoop框架中最核心设计就是:MapReduce和HDFS。MapReduce提供了对数据的计算,HDFS提供了海量数据的存储。
================================================================================================================================================================================================================================================================================================================================================================
MapReduce的缺陷很多,最大的缺陷之一是Map + Reduce的模型。这个模型并不适合描述复杂的数据处理过程。很多公司(包括我们)把各种奇怪的Machine Learning计算用MR模型描述,不断挖(lan)掘(yong)MR潜力
========================================================================================================================================================================================================================================================================================================================================================================================================================================================
Hadoop生态系统包含了用于协助Hadoop的不同的子项目(工具)模块,如Sqoop, Pig 和 Hive。
Sqoop: 它是用来在HDFS和RDBMS之间来回导入和导出数据。
Pig: 它是用于开发MapReduce操作的脚本程序语言的平台。
Hive: 它是用来开发SQL类型脚本用于做MapReduce操作的平台。
Hadoop发展到今天家族产品已经非常丰富,能够满足不同场景的大数据处理需求。作为目前主流的大数据处理技术,市场上很多公司的大数据业务都是基于Hadoop开展,而且对很多场景已经具有非常成熟的解决方案。
作为开发人员掌握Hadoop及其生态内框架的开发技术,就是进入大数据领域的必经之路。
下面详细介绍一下,学习Hadoop开发技术的路线图。
Hadoop本身是用java开发的,所以对java的支持性非常好,但也可以使用其他语言。
下面的技术路线侧重数据挖掘方向,因为Python开发效率较高所以我们使用Python来进行任务。
因为Hadoop是运行在Linux系统上的,所以还需要掌握Linux的知识。
第一阶段:Hadoop生态架构技术
语言基础
Java:掌握javase知识,多理解和实践在Java虚拟机的内存管理、以及多线程、线程池、设计模式、并行化就可以,不需要深入掌握。
Linux:系统安装(命令行界面和图形界面)、基本命令、网络配置、Vim编辑器、进程管理、Shell脚本、虚拟机的菜单熟悉等等。
Python:基础语法,数据结构,函数,条件判断,循环等基础知识。
环境准备
这里介绍在windows电脑搭建完全分布式,1主2从。
VMware虚拟机、Linux系统(Centos6.5)、Hadoop安装包,这里准备好Hadoop完全分布式集群环境。
MapReduce
MapReduce分布式离线计算框架,是Hadoop核心编程模型。主要适用于大批量的集群任务,由于是批量执行,故时效性偏低。
HDFS1.0/2.0
Hadoop分布式文件系统(HDFS)是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
Yarn(Hadoop2.0)
前期了解即可,Yarn是一个资源调度平台,主要负责给任务分配资源。Yarn是一个公共的资源调度平台,所有满足条件的框架都可以使用Yarn来进行资源调度。
Hive
Hive是一个数据仓库,所有的数据都是存储在HDFS上的。使用Hive主要是写Hql,非常类似于Mysql数据库的Sql。其实Hive在执行Hql,底层在执行的时候还是执行的MapRedce程序。
Spark
Spark 是专为大规模数据处理而设计的快速通用的计算引擎,其是基于内存的迭代式计算。Spark 保留了MapReduce 的优点,而且在时效性上有了很大提高。
Spark Streaming
Spark Streaming是实时处理框架,数据是一批一批的处理。
Spark Hive
基于Spark的快速Sql检索。Spark作为Hive的计算引擎,将Hive的查询作为Spark的任务提交到Spark集群上进行计算,可以提高Hive查询的性能。
Storm
Storm是一个实时计算框架,和MR的区别就是,MR是对离线的海量数据进行处理,而Storm是对实时新增的每一条数据进行处理,是一条一条的处理,可以保证数据处理的时效性。
Zookeeper
Zookeeper是很多大数据框架的基础,它是集群的管理者。监视着集群中各个节点的状态根据节点提交的反馈进行下一步合理操作。
最终,将简单易用的接口和性能高效、功能稳定的系统提供给用户
Hbase
Hbase是一个Nosql 数据库,是一个Key-Value类型的数据库,是高可靠、面向列的、可伸缩的、分布式的数据库。
适用于非结构化的数据存储,底层的数据存储在HDFS上。
Kafka
kafka是一个消息中间件,在工作中常用于实时处理的场景中,作为一个中间缓冲层。
Flume
Flume是一个日志采集工具,常见的就是采集应用产生的日志文件中的数据,一般有两个流程。
一个是Flume采集数据存储到Kafka中,方便Storm或者SparkStreaming进行实时处理。
另一个流程是Flume采集的数据存储到HDFS上,为了后期使用hadoop或者spark进行离线处理。
第二阶段:数据挖掘算法
中文分词
开源分词库的离线和在线应用
自然语言处理
文本相关性算法
推荐算法
基于CB、CF,归一法,Mahout应用。
分类算法
NB、SVM
回归算法
LR、Decision Tree
聚类算法
层次聚类、Kmeans
神经网络与深度学习
NN、Tensorflow
以上就是学习Hadoop开发的一个详细路线,鉴于篇幅原因只列举和解释了框架作用。
学习完第一阶段的知识,已经可以从事大数据架构相关的工作,可以在企业中负责某些或某个的开发与维护工作。
学习完第二阶段的知识,可以从事数据挖掘相关的工作,这也是目前进入大数据行业含金量最高的工作。
【福利】Hadoop大数据学习视频资料
资料包括:
1、最新Hadoop开发视频课程(MapReduce、Storm、Hbase、spark等框架开发技术和神经网络、算法等前沿技术)
2、Hadoop生态圈各框架安装包集合
3、大数据、人工智能学习必读书籍
4、100道面试题(百度专家亲自整理)
5、50个必会算法















 662
662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









