







 本文介绍了一种Python爬虫策略,通过手动登录获取cookie来模拟已登录状态,进而抓取招标网的受限数据。使用requests和bs4库进行网页请求和解析,详细分析了如何获取和使用请求头、POST参数以及判断是否有下一页的方法。虽然成功抓取了部分数据,但遇到模板不一致导致的解析难题。
本文介绍了一种Python爬虫策略,通过手动登录获取cookie来模拟已登录状态,进而抓取招标网的受限数据。使用requests和bs4库进行网页请求和解析,详细分析了如何获取和使用请求头、POST参数以及判断是否有下一页的方法。虽然成功抓取了部分数据,但遇到模板不一致导致的解析难题。
如题。
本次爬数据的网站是招标网,数据是需要登录之后才能看到。这里并没有模拟登录而是直接通过手动登录后,拿到cookie等参数模拟已登录。本次爬数据使用python第三方模块requests和bs4。
首先打开招标网看下基本情况:
一.不需要登录时爬基本信息
直接搜索查询关键词的话,查询的一些关于关键词的一些文件的基本信息(标题,时间等等基本信息)时,并不需要登录。比如下图所示:
这里需要注意的有:(F12打开开发者工具)
1.在network栏里,查看查询的那个接口(一般都是在最上方,下面一大堆都是数据包的)的请求方式:get或post,本次爬基本信息是post请求。
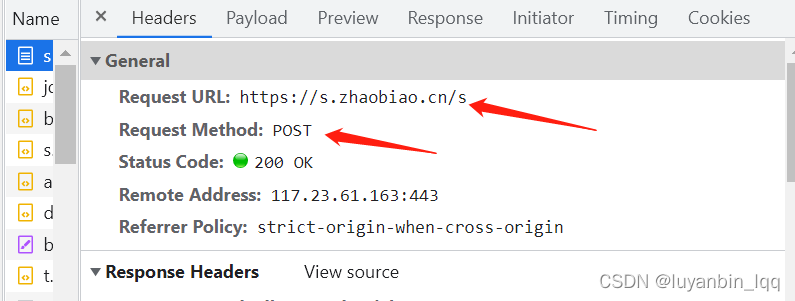
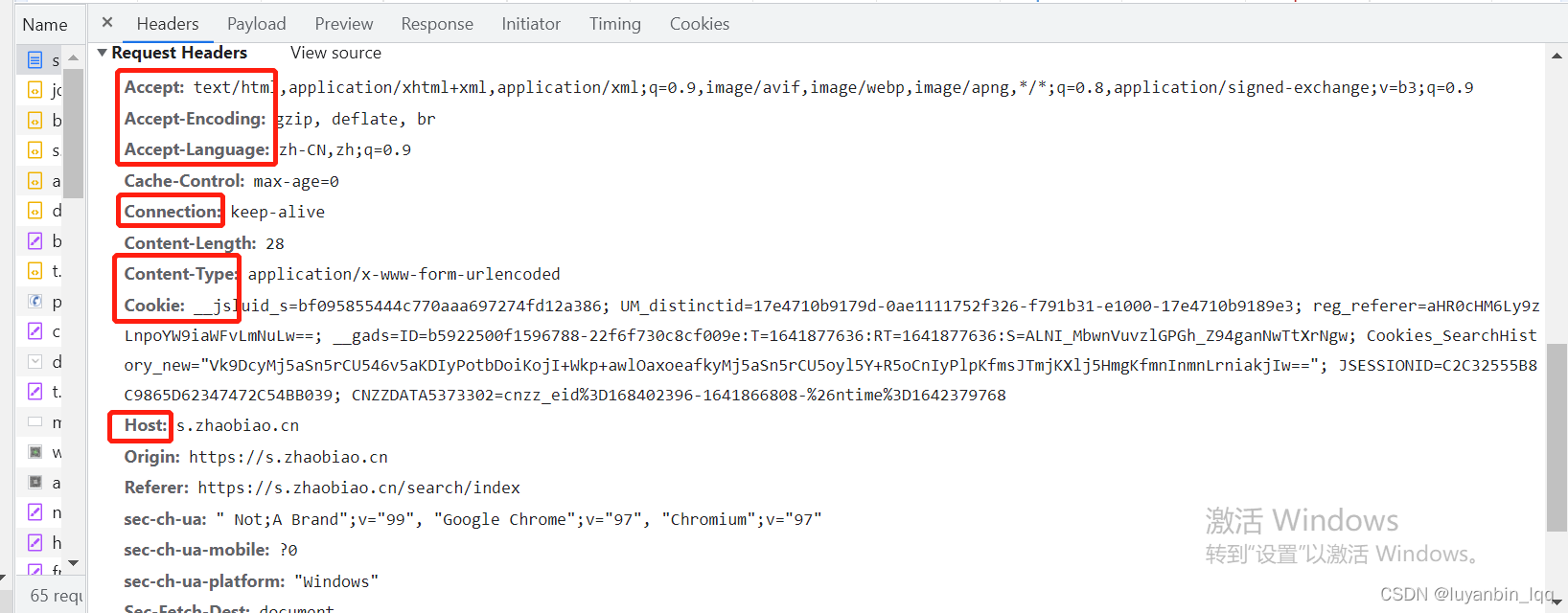
2.然后需要查看请求头信息:(爬虫需要把自己伪装成浏览器,则需要将这些请求头信息在爬数据调用接口时也将其放到请求头中),User-agent没截上去。具体的请求头参数信息的多少跟网站的反爬有关。
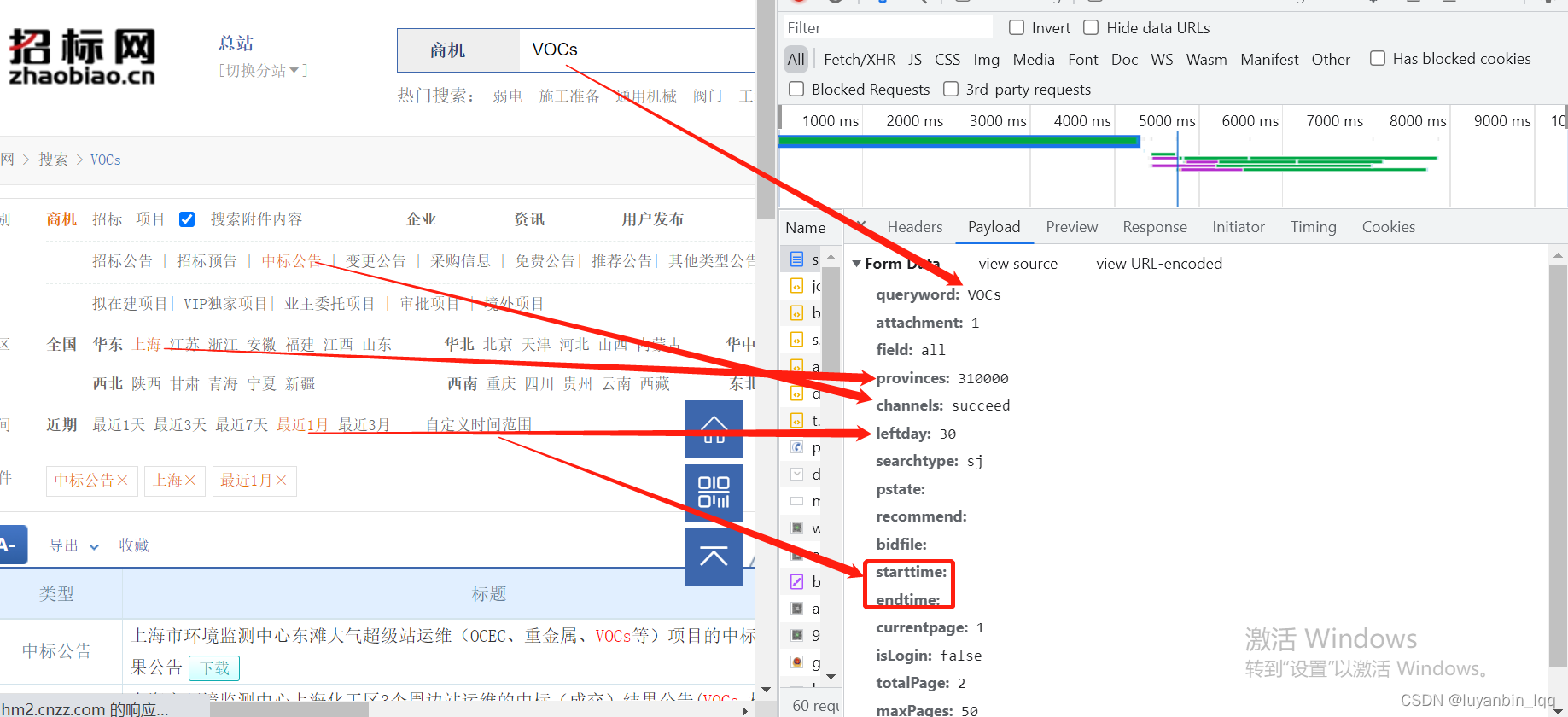
3.post查询请求中的其他参数,如查询的地区,类型以及查询关键词等,(可多查询几次不同参数的,查看有哪些改变的,有些参数也可以见名知意)
然后就可以发送请求获取响应的页面数据了。
def open_url(url, target, area_code, change_page_num):
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9"
, "Content-Type": "application/x-www-form-urlencoded"
,
"Cookie": "JSESSIONID=EEF277E486AA189166E5F7E35D38A35E; __jsluid_s=2442e0abcfce1cc95879c14188e84d2e; UM_distinctid=17e491a711a692-06109effa73b9d-3a674402-fa000-17e491a711b63b; Cookies_SearchHistory_new=Vk9DcyMj; CNZZDATA5373302=cnzz_eid=276313271-1641899209-&ntime=1641898392; reg_referer=aHR0cHM6Ly9zLnpoYW9iaWFvLmNuLw==; __gads=ID=63839929da8d80ff-22e1017bc7cf00eb:T=1641905637:RT=1641905637:S=ALNI_MZZ80gvOaC1BGChvtRmVE0EJK9Luw; Cookies_token=6252a963-212b-47a3-8760-b4659769c7a9"
,
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
, "Accept-Language": "zh-CN,zh;q=0.9"
, "Accept-Encoding": "gzip, deflate, br"
, "Host": "s.zhaobiao.cn"
, "Referer": "https://s.zhaobiao.cn/s"
, "Connection": "keep-alive"
}
# 设置请求参数
from_data = {
"searchtype": "sj"
, "queryword": target
, "channels": "succeed"
, "provinces": area_code
, "leftday": "90"
, "currentpage": change_page_num
}
# 调接口发送请求
res = requests.post(url, data=from_data, headers=headers)
# 将响应结果返回
return res
获取到响应的整个页面之后,通过bs4.BeautifulSoup(“res_url.text”,“html.parser”)将响应解析为html格式,然后根据想要爬取的目标所在的标签位置,针对性的获取数据,如下所示:(将开发者工具中数据所在位置的截图也放在下方)
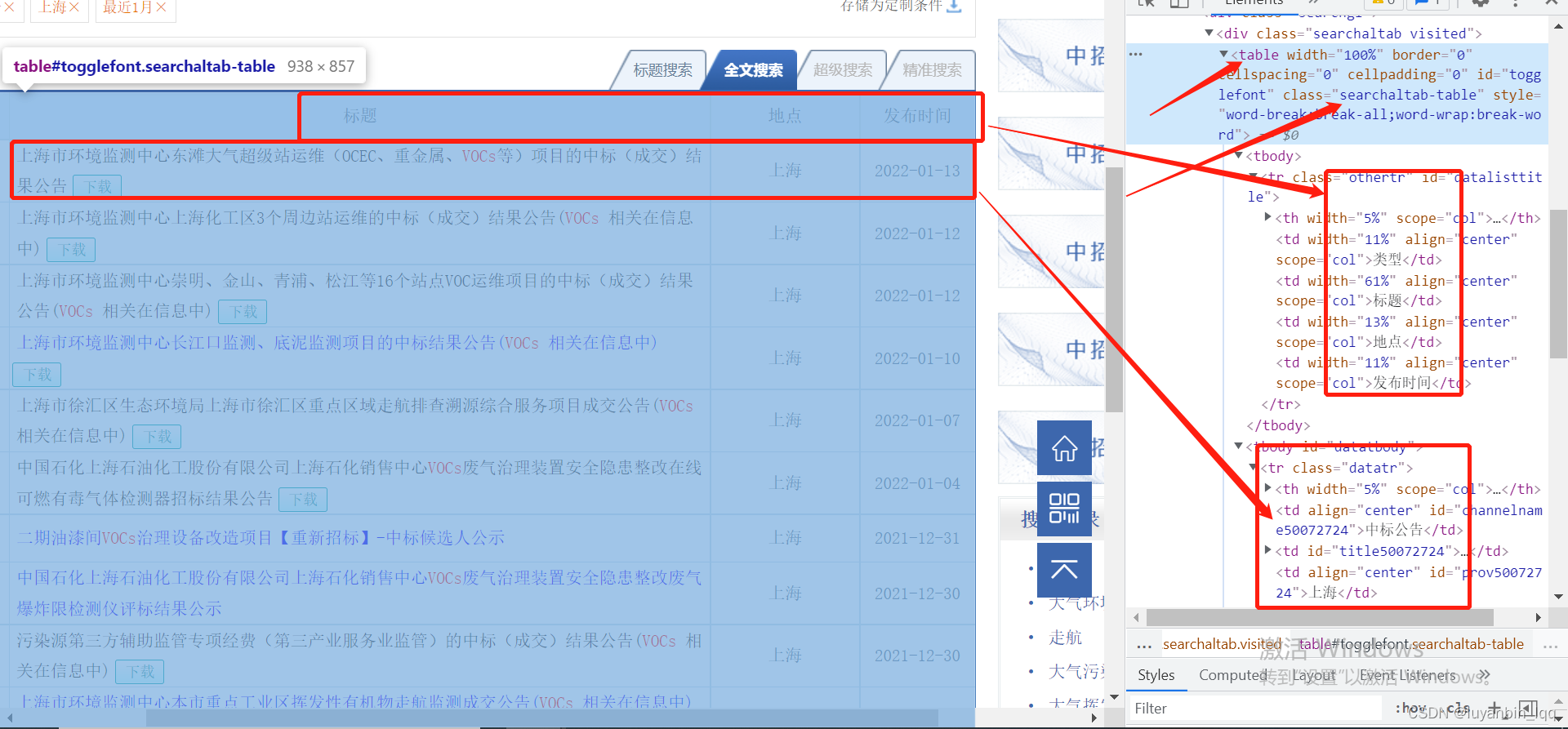
由上图可得知,所需要的数据都在一张表中,且table的class为"searchaltab-table",
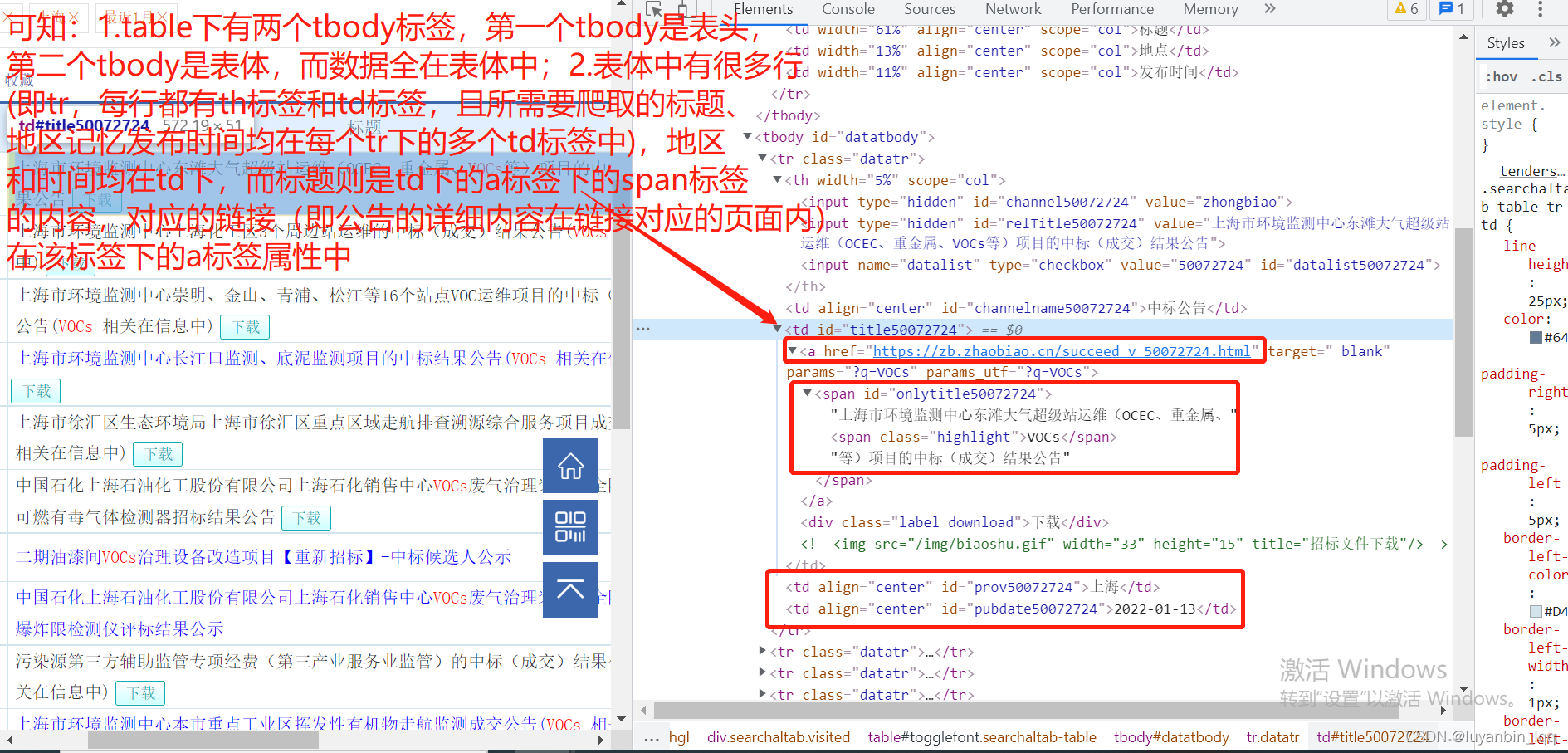
所以由上述分析可得,获取页面中所需要的哪几种数据的代码如下:
# 根据主页面(无需登录cookie即可根据条件查询中标的基本信息)的html获取:类型、报告标题、报告链接、
# 发布时间以及下一页的页码数所在的div,即nextpage2_div
def get_infos_from_open_url(res_url):
soup = bs4.BeautifulSoup(res_url.text, "html.parser")
nextpage2_div = soup.find("div", id="nextpage2")
table = soup.find("table", class_="searchaltab-table")
tbody = table.find_all("tbody")[1]
trs = tbody.find_all("tr")
# 每一行包含所需要的标题、中标报告链接以及发布时间
# 为了确认中标公告与地点与查询无误,这里将类型列和地点列也查出来
for tr in trs:
# 第一列包含类型:中标公告
td0 = tr.find_all("td")[0]
type = td0.text
# 第二列包含所需要的标题、中标报告链接
td1 = tr.find_all("td")[1]
# 拿到标题
title = td1.a.span.text
# 拿到报告信息的链接
bgurl = td1.a["href"]
# 第三列包含地点
td2 = tr.find_all("td")[2]
site = td2.text
# 第四列包含所需要的发布时间
td3 = tr.find_all("td")[3]
rea_time = td3.text
print(type + "\t" + title + "\t" + bgurl + "\t" + site + "\t" + rea_time)
这个时候获取到查询结果中的默认第一页的数据了,那么第二页、第三页、一直到最后一页的该则么得到呢?
首先随便查一个关键词然后查看参数:发现参数就两个。。。

再多限制点参数呢?发现参数多了。
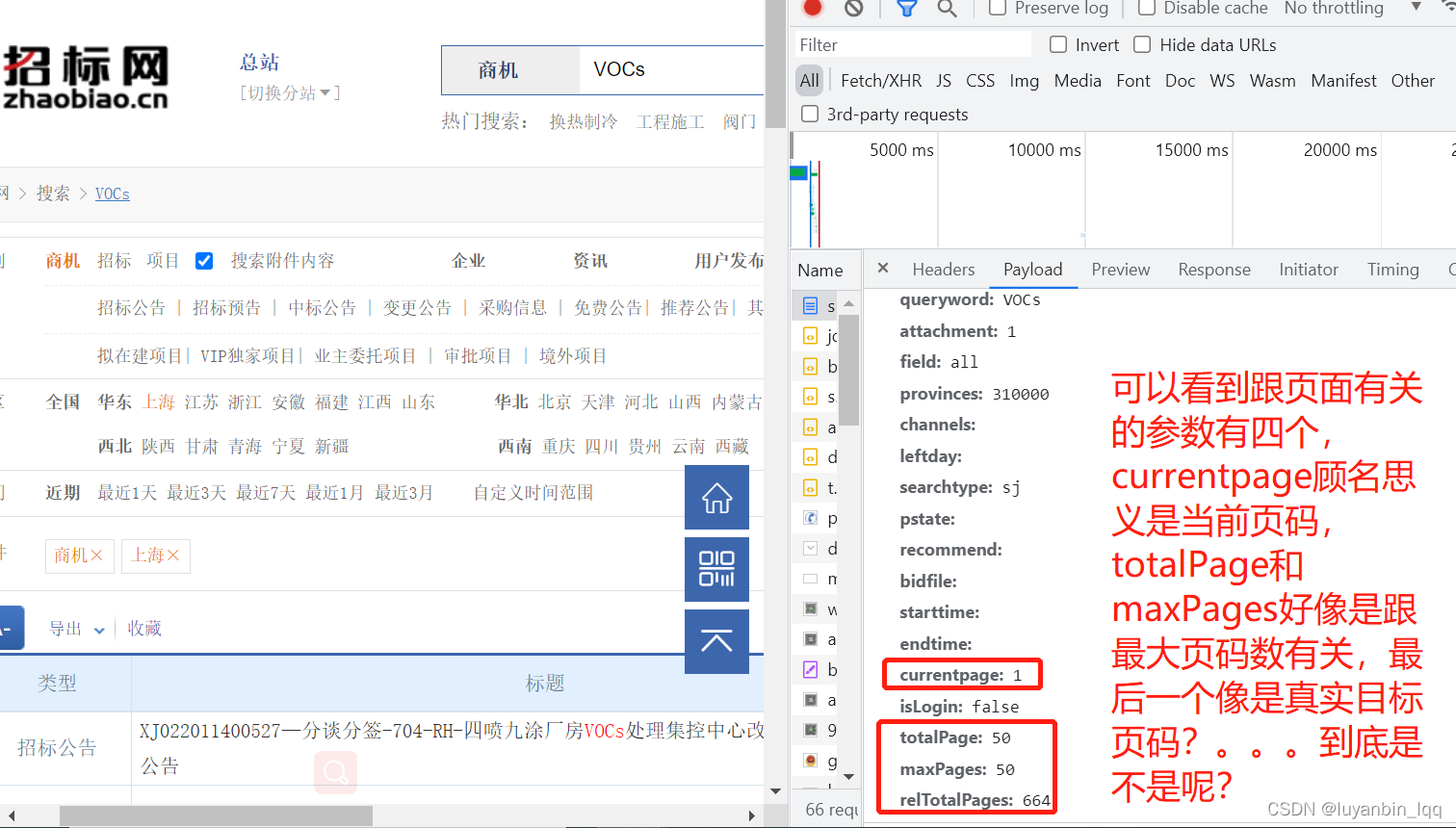
将页面拉倒最后可以看到。。。只有四页。。。
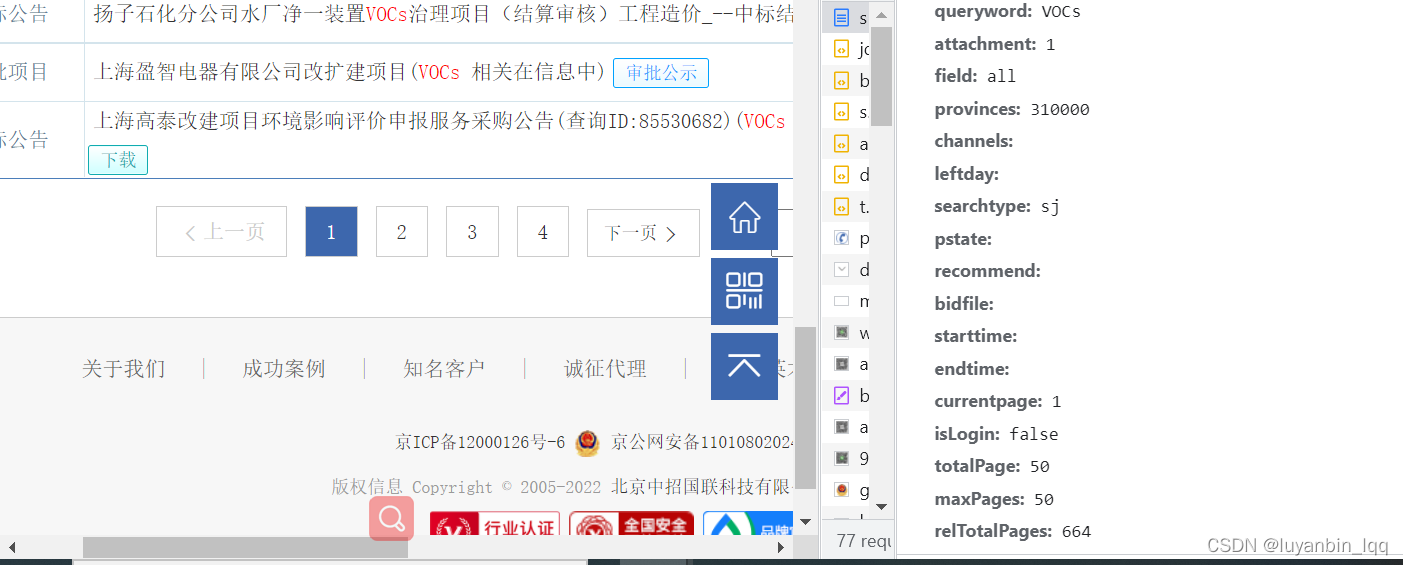
那就点个下一页再看看。。
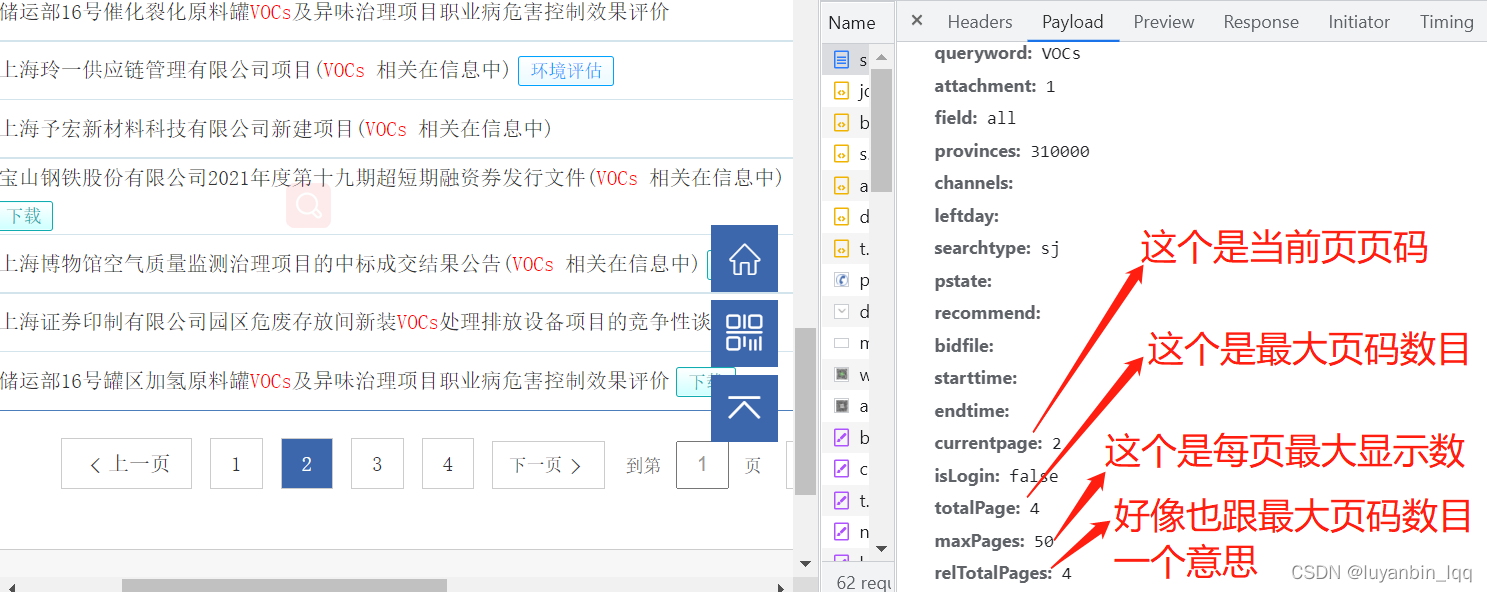
那就再多点限制条件再试试。
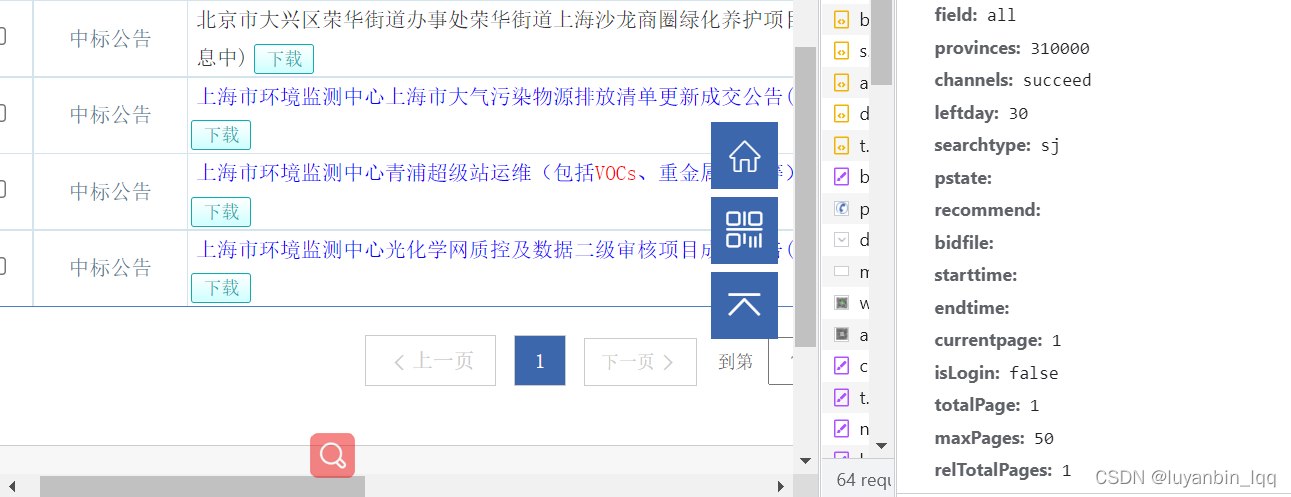
的确,猜测的的确符合现在的查询结果。那么是查询所有页的数据的话,理论上只需要得到总页数,然后给currentpage从1开始,一直请求到最后一页就可以了,就可以获取到所有页的数据了,其他参数保持不变。那么问题来了,怎么拿到总页数呢?emmm,我不知道。所以我换了种方式;
我们继续回到开发者工具页面。
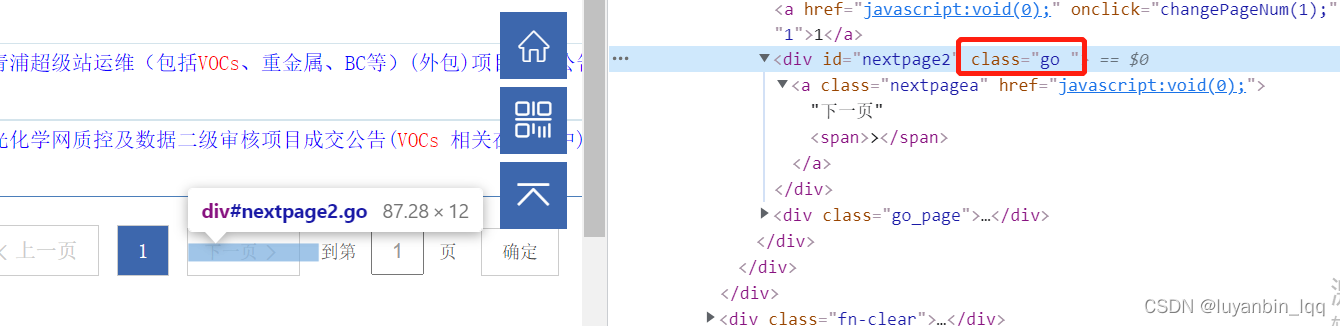
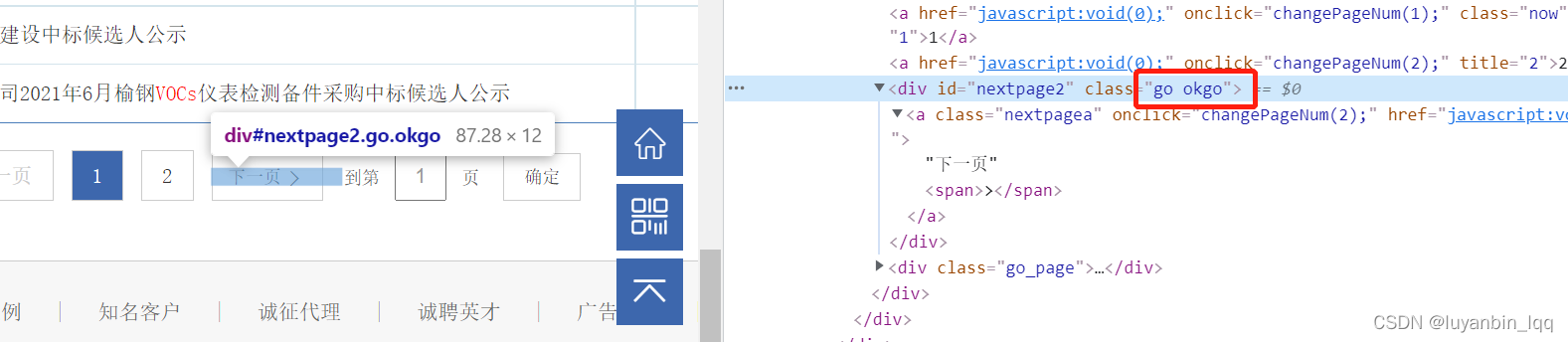
可以看到如果还有下一页,则下一页按钮对应的div标签中的class属性是不一样的,而且有下一页的话,该标签下有个a标签,a标签中的onclick属性值中有下一页对应的页码数,所以也可以根据这一点去判断是否还真正的有下一页,如果class为go okgo,则去该标签下找a标签的onclick属性值,如果没有,那就说明已经是最后一页。
递归代码如下:(根据长度判断,是因为go和go okgo在python里面获取class属性值的时候将这go okgo解析成了一个列表,长度为2)
def recursion(nextpage2_div, url_url, target, area_code):
# 先获取到下一页的页码数,是后续判断是否有下一页的依据
# 而为了将查询的所有页的数据都读出来,这个需要通过判断是否有下一页来循环查下页
# 通过html可知:当有下一页数据时,nextpage2_div标签内的class值为"go okgo",没有下一页数据时则为'go',
# 不过bs4解析时将'go okgo'解析为['go','okgo']了,则可以判断该对象的长度来判断是否有下一页
# 当len()=1时,没有下一页,当len()=2时,有下一页,且nextpage2_div中会出现onclick属性,值中有下一页的页码值
# 例如:当有两页时,在第一页时,len()=2,且onclick属性值为changePageNum(2)
if len(nextpage2_div["class"]) == 2:
changePageNumOnClick = nextpage2_div.a["onclick"]
changePageNum = int(changePageNumOnClick.replace("changePageNum", '').replace("(", '').replace(");", ''))
print(changePageNum)
# 设置一个随机等待时间(间隔性爬数据不会对网站造成太大压力)
time.sleep(random.randint(1,  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 768
768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









