






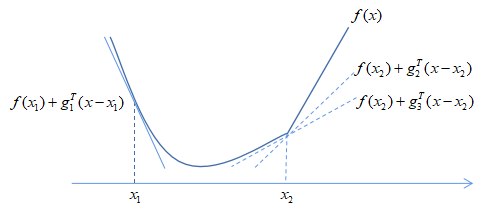


拟牛顿法
牛顿法在理论上有很好的效果,然而对于大规模问题,函数的海塞矩阵计算待解特别大或者难以得到,即便得到海塞矩阵我们还需要求解一个大规模线性方程组。那么能否使用海塞矩阵或其逆矩阵的近似来进行牛顿迭代呢?拟牛顿法便是这样的算法,它能够在每一步以较小的代价生成近似矩阵,并且使用近似矩阵代替海塞矩阵,而产生的迭代序列仍具有超线性收敛的性质。
拟牛顿法不计算海塞矩阵
∇
2
f
(
x
)
\nabla^2f(x)
∇2f(x),而是构造其近似矩阵
B
k
B^k
Bk或其逆的近似矩阵
H
k
H^k
Hk。我们希望
B
k
B^k
Bk或
H
k
H^k
Hk仍然保留海塞矩阵的部分性质,例如使得
d
k
d^k
dk仍然为下降方向。
一、割线方程
回顾牛顿法的推导过程。设
f
(
x
)
f(x)
f(x)是二阶连续可微函数,根据泰勒展开,向量值函数
∇
f
(
x
)
\nabla f(x)
∇f(x)在点
x
k
+
1
x^{k+1}
xk+1处的近似为:
∇
f
(
x
)
=
∇
f
(
x
k
+
1
)
+
∇
2
f
(
x
k
+
1
)
(
x
−
x
k
+
1
)
+
O
(
∣
∣
x
−
x
k
+
1
∣
∣
)
(1)
\nabla f(x)=\nabla f(x^{k+1})+\nabla^2f(x^{k+1})(x-x^{k+1}) + O(||x-x^{k+1}||) \tag{1}
∇f(x)=∇f(xk+1)+∇2f(xk+1)(x−xk+1)+O(∣∣x−xk+1∣∣)(1)
令
x
=
x
k
,
s
k
=
x
k
+
1
−
x
k
x=x^k,s^k=x^{k+1}-x^k
x=xk,sk=xk+1−xk及
y
k
=
∇
f
(
x
k
+
1
)
−
∇
f
(
x
k
)
y^k=\nabla f(x^{k+1})-\nabla f(x^k)
yk=∇f(xk+1)−∇f(xk),得到
∇
2
f
(
x
k
+
1
)
s
k
+
O
(
∣
∣
s
k
∣
∣
)
=
y
k
(2)
\nabla^2f(x^{k+1})s^k+O(||s^k||)=y^k \tag{2}
∇2f(xk+1)sk+O(∣∣sk∣∣)=yk(2)
忽略高阶项
∣
∣
s
k
∣
∣
||s^k||
∣∣sk∣∣,我们希望海塞矩阵的近似矩阵
B
k
+
1
B^{k+1}
Bk+1满足方程
y
k
=
B
k
+
1
s
k
(3)
y^k=B^{k+1}s^k \tag{3}
yk=Bk+1sk(3)
或者其逆矩阵的近似矩阵
H
k
+
1
H^{k+1}
Hk+1满足方程
s
k
=
H
k
+
1
y
k
(4)
s^k=H^{k+1}y^k \tag{4}
sk=Hk+1yk(4)
并称(3)式与(4)式为割线方程。
在通常情况下,近似矩阵
B
k
+
1
B^{k+1}
Bk+1或
H
k
+
1
H^{k+1}
Hk+1是由上一步迭代加上一个修正得到的,并且要求满足割线方程。这里先给出拟牛顿法的一般计算框架
拟牛顿算法的一般算法框架
- 给定 x 0 ∈ R x^0\in\mathbb{R} x0∈R,初始矩阵 B 0 ∈ R n × n B^0\in\mathbb{R^{n\times n}} B0∈Rn×n或 H 0 H^0 H0,令 k = 0 k=0 k=0
- while 未达到停机准则 do
- 计算方向 d k = − ( B k ) − 1 ∇ f ( x k ) d^k=-(B^k)^{-1}\nabla f(x^k) dk=−(Bk)−1∇f(xk)或 d k = − H k ∇ f ( x k ) d^k=-H^k\nabla f(x^k) dk=−Hk∇f(xk)
- 通过线搜索找到合适的步长 α k > 0 \alpha_k>0 αk>0,令 x k + 1 = x k + α k d k x^{k+1}=x^k+\alpha^kd^k xk+1=xk+αkdk
- 更新海塞矩阵的近似矩阵 B k + 1 B^{k+1} Bk+1或其逆矩阵的近似矩阵 H k + 1 H^{k+1} Hk+1
- k ← k + 1 k\leftarrow k+1 k←k+1
- end while
二、BFGS算法
在实际应用中基于
H
k
H^k
Hk的拟牛顿法更加实用,这是因为根据
H
k
H^k
Hk计算下降方向
d
k
d^k
dk不需要求解线性方程组,而求解线性方程组在大规模问题上是非常耗时的。
后续我们重点关注在以
H
k
H^k
Hk为目标的拟牛顿计算方法
这里给出秩2的BFGS公式推导过程,我们采用待定系数法推导公式,设
B
k
+
1
=
B
k
+
a
u
u
T
+
b
v
v
T
B^{k+1}=B^k+auu^T+bvv^T
Bk+1=Bk+auuT+bvvT
其中
u
,
v
∈
R
n
,
a
,
b
∈
R
u,v\in\mathbb{R^n},a,b\in\mathbb{R}
u,v∈Rn,a,b∈R。根据割线方程(3)有
B
k
+
1
s
k
=
(
B
k
+
a
u
u
T
+
b
v
v
T
)
s
k
=
y
k
B^{k+1}s^k=(B^k+auu^T+bvv^T)s^k=y^k
Bk+1sk=(Bk+auuT+bvvT)sk=yk
整理可得
(
a
⋅
u
T
s
k
)
u
+
(
b
⋅
v
T
s
k
)
v
=
y
k
−
B
k
s
k
(a\cdot u^Ts^k)u+(b\cdot v^Ts^k)v=y^k-B^ks^k
(a⋅uTsk)u+(b⋅vTsk)v=yk−Bksk
我们通过选取
u
u
u和
v
v
v让以上等式成立即可。实际上
u
u
u和
v
v
v有非常多的取法,一种最直接的取法是让上面灯饰左右两边分别对应相等,即
u
=
y
k
,
a
⋅
u
T
s
k
=
1
,
v
=
B
k
s
k
,
b
⋅
v
T
s
k
=
−
1
\begin{aligned} u=y^k,a\cdot u^Ts^k=1,\\ v=B^ks^k,b\cdot v^Ts^k=-1 \end{aligned}
u=yk,a⋅uTsk=1,v=Bksk,b⋅vTsk=−1
因此得到更新方式
B
k
+
1
=
B
k
+
y
k
(
y
k
)
T
(
s
k
)
T
y
k
−
B
k
s
k
(
B
k
s
k
)
T
(
s
k
)
T
B
k
s
k
(5)
B^{k+1}=B^k+\frac{y^k(y^k)^T}{(s^k)^Ty^k}-\frac{B^ks^k(B^ks^k)^T}{(s^k)^TB^ks^k} \tag{5}
Bk+1=Bk+(sk)Tykyk(yk)T−(sk)TBkskBksk(Bksk)T(5)
(5)式被成为基于
B
k
B^k
Bk的BFGS公式,同理假设
H
k
=
(
B
k
)
−
1
H^k=(B^k)^{-1}
Hk=(Bk)−1,可推出基于
H
k
H^k
Hk的BFGS公式
H
k
+
1
=
(
I
−
ρ
k
s
k
(
y
k
)
)
T
H
k
(
I
−
ρ
k
s
k
(
y
k
)
)
+
ρ
k
s
k
(
s
k
)
T
(6)
H^{k+1}=(I-\rho_ks^k(y^k))^TH^k(I-\rho_ks^k(y^k))+\rho_ks^k(s^k)^T \tag{6}
Hk+1=(I−ρksk(yk))THk(I−ρksk(yk))+ρksk(sk)T(6)
其中
ρ
k
=
1
(
s
k
)
T
y
k
\rho_k=\frac{1}{(s^k)^Ty^k}
ρk=(sk)Tyk1。容易看出,若要BFGS公式更新产生的矩阵
H
k
+
1
H^{k+1}
Hk+1正定,一个充分条件式不等式
(
s
k
)
T
y
k
>
0
(s^k)^Ty^k>0
(sk)Tyk>0成立且上一步更新矩阵
H
k
H^k
Hk正定,在问题求解过程中,不等式不一定会得到满足,此时应该使用Wolfe准则的线搜索来迫使不等式成立。
BFGS公式式目前最有效的拟牛顿更新格式之一,它有比较好的理论性质,实现起来也并不复杂,通过对(6)式进行改动可得到优先内存的BFGS格式(L-BFGS),它是常用的处理大规模优化问题的拟牛顿算法。
BFGS算法实现与数值实验
BFGS代码实现
function [fmin, xmin] = BFGS(func, gfunc, x0, epsilon)
HOld = eye(length(x0));
maxIter = 500;
xOld = x0;
iIter = 1;
while iIter < maxIter
gOld = feval(gfunc, xOld);
dk = -HOld * gOld;
[~, ~, alpha] = armijo_rule(func, gfunc, xOld, 0.2, dk);
xNew = xOld + alpha * dk;
gNew = feval(gfunc, xNew);
if norm(gNew, 2) < epsilon
xmin = xNew;
break;
end
gDiff = gNew - gOld;
xDiff = xNew - xOld;
I = eye(length(xNew));
rho = 1 / ((xDiff)' * gDiff);
HNew = (I - rho * gDiff * xDiff')' * HOld * (I - rho * gDiff * xDiff') ...
+ rho * xDiff * xDiff';
HOld = HNew;
xOld = xNew;
iIter = iIter + 1;
end
if iIter == maxIter
fprintf('exceed maximum iteration, and not found xmin\n');
xmin = xNew;
end
fmin = feval(func, xmin);
end
armijo-rule代码实现
function [fnew, xnew, alpha] = armijo_rule(func, gfunc, x0, alpha0, dk)
c1 = 1e-3;
alpha = alpha0;
gamma = 0.8;
iIter = 0;
iterMax = 200;
alphaMin = 1e-5;
while iIter < iterMax
xnew = x0 + alpha * dk;
fnew = feval(func, xnew);
f0 = feval(func, x0);
if fnew <= f0 + c1 * feval(gfunc, x0)' * dk
break;
end
if alpha < alphaMin
break;
end
alpha = gamma * alpha;
iIter = iIter + 1;
end
if iIter == iterMax
alpha = alphaMin;
fprintf('reach maximum iteration, and not found suitable alpha.\n');
end
xnew = x0 + alpha * dk;
fnew = feval(func, xnew);
end
算例
(0)
f
0
=
x
1
2
+
2
x
2
2
−
2
x
1
x
2
−
4
x
1
f_0 = x_1^2+2x_2^2-2x_1x_2-4x_1
f0=x12+2x22−2x1x2−4x1
(1)
f
1
=
x
2
2
+
x
2
2
−
x
1
x
2
−
10
x
1
−
4
x
2
f_1 =x_2^2+x_2^2-x_1x_2-10x_1-4x_2
f1=x22+x22−x1x2−10x1−4x2
(2)
f
2
=
x
1
2
−
2
x
1
x
2
+
2
x
2
2
−
4
x
1
f_2 =x_1^2-2x_1x_2+2x_2^2-4x_1
f2=x12−2x1x2+2x22−4x1
(3)
f
3
=
x
1
2
−
2
x
1
x
2
+
3
x
2
2
−
4
x
1
−
5
x
2
f_3 = x_1^2 -2x_1x_2+3x_2^2-4x_1-5x_2
f3=x12−2x1x2+3x22−4x1−5x2
数值实验代码
% test bfgs
% example
x0 = [1, 1]';
epsilon = 1e-6;
[fmin, xmin] = BFGS('bfgsTestFun0', 'bfgsTestGfun0', x0, epsilon);
fprintf('fmin = %f, xmin = (%f, %f)\n', fmin, xmin(1), xmin(2));
[x, f] = fminsearch('bfgsTestFun0', x0);
fprintf('build-in search: fmin = %f, xmin = (%f, %f)\n', f, x(1), x(2));
% exercise
% ex 4-4 (1)
x0 = [1, 1]';
epsilon = 1e-6;
[fmin, xmin] = BFGS('bfgsTestFun1', 'bfgsTestGfun1', x0, epsilon);
fprintf('fmin = %f, xmin = (%f, %f)\n', fmin, xmin(1), xmin(2));
[x, f] = fminsearch('bfgsTestFun1', x0);
fprintf('build-in search: fmin = %f, xmin = (%f, %f)\n', f, x(1), x(2));
% ex 4-4 (2)
x0 = [1, 1]';
epsilon = 1e-6;
[fmin, xmin] = BFGS('bfgsTestFun2', 'bfgsTestGfun2', x0, epsilon);
fprintf('fmin = %f, xmin = (%f, %f)\n', fmin, xmin(1), xmin(2));
[x, f] = fminsearch('bfgsTestFun2', x0);
fprintf('build-in search: fmin = %f, xmin = (%f, %f)\n', f, x(1), x(2));
% ex 4-4 (3)
x0 = [1, 1]';
epsilon = 1e-6;
[fmin, xmin] = BFGS('bfgsTestFun3', 'bfgsTestGfun3', x0, epsilon);
fprintf('fmin = %f, xmin = (%f, %f)\n', fmin, xmin(1), xmin(2));
[x, f] = fminsearch('bfgsTestFun3', x0);
fprintf('build-in search: fmin = %f, xmin = (%f, %f)\n', f, x(1), x(2));
function f = bfgsTestFun0(x)
f = x(1)^2 + 2 * x(2)^2 - 2 * x(1) * x(2) - 4 * x(1);
end
function f = bfgsTestFun1(x)
f = x(1)^2 + x(2)^2 - x(1) * x(2) - 10 * x(1) - 4 * x(2);
end
function f = bfgsTestFun2(x)
f = x(1)^2 - 2 * x(1) * x(2) + 2 * x(2)^2 - 4 * x(1);
end
function f = bfgsTestFun3(x)
f = x(1)^2 - 2 * x(1) * x(2) + 3 * x(2)^2 - 4 * x(1) - 5 * x(2);
end
function g = bfgsTestGfun0(x)
g = [2 * x(1) - 2 * x(2) - 4; ...
-2 * x(1) + 4 * x(2)];
end
function g = bfgsTestGfun1(x)
g = [2 * x(1) - x(2) - 10;...
2 * x(2) - x(1) - 4];
end
function g = bfgsTestGfun2(x)
g = [2 * x(1) - 2 * x(2) - 4;...
-2 * x(1) + 4 * x(2)];
end
function g = bfgsTestGfun3(x)
g = [2 * x(1) - 2 * x(2) - 4;...
-2 * x(1) + 6 * x(2) - 5];
end
计算结果为:
>> bfgsTest
fmin = -8.000000, xmin = (3.999999, 1.999999)
build-in search: fmin = -8.000000, xmin = (3.999976, 1.999973)
fmin = -52.000000, xmin = (7.999999, 6.000000)
build-in search: fmin = -52.000000, xmin = (8.000014, 5.999992)
fmin = -8.000000, xmin = (3.999999, 1.999999)
build-in search: fmin = -8.000000, xmin = (3.999976, 1.999973)
fmin = -14.125000, xmin = (4.250000, 2.250000)
build-in search: fmin = -14.125000, xmin = (4.249959, 2.249993)
三、L-BFGS算法
拟牛顿法虽然克服了计算海塞矩阵的困难,但是它仍然无法应用在大规模优化问题上。一般来说,拟牛顿矩阵
B
k
B^k
Bk或
H
k
H^k
Hk是稠密矩阵,而存储稠密矩阵要小号
O
(
n
2
)
O(n^2)
O(n2)的内存,这对于大规模问题,尤其是处理高分辨率图像问题时是不可能接受的。本部分介绍有效内存的BFGS方法解决了这一问题,从而使得人们在大规模问题上也可应用拟牛顿方法加速迭代的收敛。
L-BFGS方法根据公式(5)和(6)变形而来的。为了推导方便,我们以
H
k
H^k
Hk的更新公式(6)为基础推导相应的L-BFGS,为了方便推导,引入新的记号重写公式(6)
H
k
+
1
=
(
V
k
)
T
H
k
V
k
+
ρ
s
k
(
s
k
)
T
(7)
H^{k+1}=(V^k)^TH^kV^k+\rho s^k(s^k)^T \tag{7}
Hk+1=(Vk)THkVk+ρsk(sk)T(7)
其中
ρ
k
=
1
(
y
k
)
T
s
k
,
V
k
=
I
−
ρ
k
y
k
(
s
k
)
T
(8)
\rho^k=\frac{1}{(y^k)^Ts^k},V^k=I-\rho^ky^k(s^k)^T \tag{8}
ρk=(yk)Tsk1,Vk=I−ρkyk(sk)T(8)
观察到(7)式有类似地推的性质,为了我们将(7)式递归地展开
m
m
m次,其中
m
m
m是一个给定的整数:
H
k
=
(
V
k
−
m
⋯
V
k
−
1
)
T
H
k
−
m
(
V
k
−
m
⋯
V
k
−
1
)
+
ρ
k
−
m
(
V
k
−
m
+
1
⋯
V
k
−
1
)
T
s
k
−
m
(
s
k
−
m
)
(
V
k
−
m
+
1
⋯
V
k
−
1
)
+
ρ
k
−
m
+
1
(
V
k
−
m
+
2
⋯
V
k
−
1
)
T
s
k
−
m
+
1
(
s
k
−
m
+
1
)
(
V
k
−
m
+
2
⋯
V
k
−
1
)
+
⋯
+
ρ
k
−
1
s
k
−
1
(
s
k
−
1
)
T
(9)
\begin{aligned} &H^k = \\ &(V^{k-m}\cdots V^{k-1})^TH^{k-m}(V^{k-m}\cdots V^{k-1})+\\ &\rho_{k-m}(V^{k-m+1}\cdots V^{k-1})^Ts^{k-m}(s^{k-m})^(V^{k-m+1}\cdots V^{k-1})+\\ &\rho_{k-m+1}(V^{k-m+2}\cdots V^{k-1})^Ts^{k-m+1}(s^{k-m+1})^(V^{k-m+2}\cdots V^{k-1})+\cdots + \\ &\rho_{k-1}s^{k-1}(s^{k-1})^T \end{aligned} \tag{9}
Hk=(Vk−m⋯Vk−1)THk−m(Vk−m⋯Vk−1)+ρk−m(Vk−m+1⋯Vk−1)Tsk−m(sk−m)(Vk−m+1⋯Vk−1)+ρk−m+1(Vk−m+2⋯Vk−1)Tsk−m+1(sk−m+1)(Vk−m+2⋯Vk−1)+⋯+ρk−1sk−1(sk−1)T(9)
为了达到节省内存的目的,(7)式不能无限展开下去,当这会产生一个问题,
H
k
−
m
H^{k-m}
Hk−m还是无法求出。一个自然的想法就是用
H
k
−
m
H^{k-m}
Hk−m的近似矩阵来代替
H
k
−
m
H^{k-m}
Hk−m进行计算,近似矩阵的选取方式很多,但基本原则是要保证近似矩阵具有非常简单的结构,假定我们给出了
H
k
−
m
H^{k-m}
Hk−m的一个近似矩阵(9)式便可以用于计算拟牛顿迭代。
在拟牛顿迭代中,实际上并不需要计算
H
k
H^k
Hk的显示形式,只需要利用
H
k
∇
f
(
x
k
)
H^k\nabla f(x^k)
Hk∇f(xk)来计算迭代方向
d
k
d^k
dk。为此先直接给出一个利用展开式(9)直接求解
H
k
∇
f
(
x
k
)
H^k\nabla f(x^k)
Hk∇f(xk)的算法。见L-BFGS双循环递归算法。改算法的设计很精妙,充分利用了(9)式的结构来尽量节省计算
H
k
∇
f
(
x
k
)
H^k\nabla f(x^k)
Hk∇f(xk)的开销。
L-BFGS双循环递归算法
- 初始化 q ← ∇ f ( x k ) q\leftarrow\nabla f(x^k) q←∇f(xk)
- for i = k-1,k-2, …, k-m do
- 计算并保存 α i ← ρ i ( s i ) T q \alpha_i\leftarrow\rho_i(s^i)^Tq αi←ρi(si)Tq.
- 更新 q ← q − α i y i q\leftarrow q-\alpha_iy^i q←q−αiyi.
- end for
- 初始化 r ← H ^ k − m q r\leftarrow\hat{H}^{k-m}q r←H^k−mq,其中 H ^ k − m \hat{H}^{k-m} H^k−m是 H k − m {H}^{k-m} Hk−m的近似矩阵
- for i = k-m, k-m+1, …, k-1 do
- 计算 β ← ρ i ( y i ) T r \beta\leftarrow\rho_i(y^i)^Tr β←ρi(yi)Tr
- 更新 r ← r + ( α i − β ) s i r\leftarrow r+(\alpha_i-\beta)s^i r←r+(αi−β)si
- end for
- 输出 r r r,即 H k ∇ f ( x k ) H^k\nabla f(x^k) Hk∇f(xk)
上述L-BFGS双循环递归算法约需要4mn次乘法运算与2mn次加法运算,若近似矩阵
H
^
k
−
m
\hat{H}^{k-m}
H^k−m是对角矩阵,则额外需要n次乘法运算。由于m不会很大,因此该算法的复杂度为
O
(
m
n
)
O(mn)
O(mn)。算法所需要的额外存储为临时变量
α
i
\alpha_i
αi,它的大小是
O
(
m
)
O(m)
O(m)。综上所述,L-BFGS双循环算法是非常高效的。
近似矩阵
H
^
k
−
m
\hat{H}^{k-m}
H^k−m的取法可以是对角矩阵
H
^
k
−
m
=
γ
k
I
\hat{H}^{k-m}=\gamma_kI
H^k−m=γkI,其中
γ
k
=
(
s
k
−
1
)
T
y
k
−
1
(
y
k
−
1
)
T
y
k
−
1
\gamma_k=\frac{(s^{k-1})^Ty^{k-1}}{(y^{k-1})^Ty^{k-1}}
γk=(yk−1)Tyk−1(sk−1)Tyk−1
这恰好是BB方法的第一个步长。
这里给出L-BFGS的具体算法流程
- 选择初始点 x 0 x^0 x0,参数 m > 0 , k ← 0 m>0,k\leftarrow 0 m>0,k←0.
- while 未达到收敛准者 do
- 选择近似矩阵 H ^ k − m \hat{H}^{k-m} H^k−m.
- 使用双循环算法计算下降方向 d k = − H k ∇ f ( x k ) d^k=-H^k\nabla f(x^k) dk=−Hk∇f(xk)
- 使用线搜索算法计算满足Wolfe准则的步长 α k \alpha_k αk.
- 更新 x k + 1 = x k + α k d k x^{k+1}=x^k+\alpha_kd^k xk+1=xk+αkdk.
- if k > m then
- 从内存空间中删除 s k − m , y k − m s^{k-m},y^{k-m} sk−m,yk−m.
- end if
- 计算并保存 s k = x k + 1 − x k , y k = ∇ f ( x k + 1 ) − ∇ f ( x k ) s^k=x^{k+1}-x^k,y^k=\nabla f(x^{k+1})-\nabla f(x^k) sk=xk+1−xk,yk=∇f(xk+1)−∇f(xk)
- k = ← k + 1 k=\leftarrow k+1 k=←k+1
- end while
正因为L-BFGS方法的出现,人们可以使用拟牛顿类算法求解优化问题。虽然有关L-BFGS方法的收敛性依然有限,但实际应用中L-BFGS方法很快成为应用最广泛的拟牛顿类算法。
















 1449
1449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









