







前言
数据分析中有些指标比如要每个用户进行分组排名,取组内前x名数据等,这种对于一般的查询语句实现的比较复杂,然而mysql8.0 支持了许多的窗口函数,能很好的支持这类似的复杂查询。
MySQL从8.0开始支持窗口函数,这个功能在大多商业数据库和部分开源数据库中早已支持,有的也叫分析函数。
什么叫窗口?
窗口的概念非常重要,它可以理解为记录集合,窗口函数也就是在满足某种条件的记录集合上执行的特殊函数。对于每条记录都要在此窗口内执行函数,有的函数随着记录不同,窗口大小都是固定的,这种属于静态窗口;有的函数则相反,不同的记录对应着不同的窗口,这种动态变化的窗口叫滑动窗口。
窗口函数和普通聚合函数也很容易混淆,二者区别如下:
-
聚合函数是将多条记录聚合为一条;而窗口函数是每条记录都会执行,有几条记录执行完还是几条。
-
聚合函数也可以用于窗口函数中
下面我们就看一下mysql8.0 常用的函数如何使用。
数据准备
1、建表我们常规的订单数据来对这些函数进行使用。
CREATE TABLE `order_tab` (
`order_id` int(10) NOT NULL COMMENT '订单ID',
`user_no` varchar(22) DEFAULT '' COMMENT '用户唯一标识',
`amount` int(10) DEFAULT NULL COMMENT '金额',
`create_date` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '订单时间',
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
2、插入测试数据
insert into `order_tab` (`order_id`, `user_no`, `amount`, `create_date`) values('0','001','100','2021-01-01 00:00:00');
insert into `order_tab` (`order_id`, `user_no`, `amount`, `create_date`) values('2','001','300','2021-01-02 00:00:00');
insert into `order_tab` (`order_id`, `user_no`, `amount`, `create_date`) values('3','001','500','2021-01-02 00:00:00');
insert into `order_tab` (`order_id`, `user_no`, `amount`, `create_date`) values('4','001','800','2021-01-03 00:00:00');
insert into `order_tab` (`order_id`, `user_no`, `amount`, `create_date`) values('5','001','900','2021-01-04 00:00:00');
insert into `order_tab` (`order_id`, `user_no`, `amount`, `create_date`) values('6','002','500','2021-01-03 00:00:00');
insert into `order_tab` (`order_id`, `user_no`, `amount`, `create_date`) values('7','002','600','2021-01-04 00:00:00');
insert into `order_tab` (`order_id`, `user_no`, `amount`, `create_date`) values('8','002','300','2021-01-10 00:00:00');
insert into `order_tab` (`order_id`, `user_no`, `amount`, `create_date`) values('9','002','800','2021-01-16 00:00:00');
insert into `order_tab` (`order_id`, `user_no`, `amount`, `create_date`) values('10','002','800','2021-01-22 00:00:00');
序号函数
函数名([expr]) over子句
-
partition子句:窗口按照那些字段进行分组,窗口函数在不同的分组上分别执行。
-
order by子句:按照哪些字段进行排序,窗口函数将按照排序后的记录顺序进行编号。
序号函数——row_number() / rank() / dense_rank()。
-
用途:显示分区中的当前行号
-
使用场景:希望查询每个用户订单金额最高的前三个订单
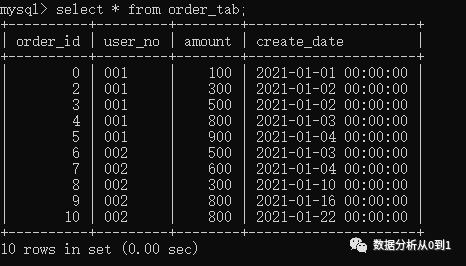
SELECT *
FROM
(SELECT row_number() OVER(PARTITION BY user_no
ORDER BY amount DESC) AS row_num,
order_id,
user_no,
amount,
create_date
FROM order_tab) t
WHERE row_num<=3;
此时可以使用ROW_NUMBER()函数按照用户进行分组并按照订单日期进行由大到小排序,最后查找每组中序号<=3的记录。
对于用户‘002’的订单,大家发现订单金额为800的有两条,序号随机排了1和2,但很多情况下二者应该是并列第一,而订单为600的序号则可能是第二名,也可能为第三名,这时候,row_number就不能满足需求,需要rank和dense_rank出场。
这两个函数和row_number()非常类似,只是在出现重复值时处理逻辑有所不同。
SQL中用row_number() / rank() / dense_rank()分别显示序号,我们看一下有什么差别:
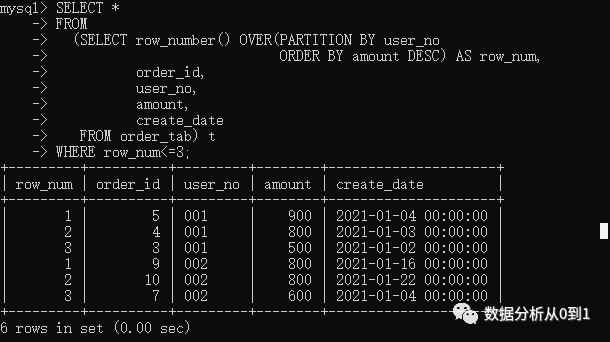
SELECT *
FROM
(SELECT row_number() OVER(PARTITION BY user_no
ORDER BY amount DESC) AS row_num1,
rank() OVER(PARTITION BY user_no
ORDER BY amount DESC) AS row_num2,
dense_rank() OVER(PARTITION BY user_no
ORDER BY amount DESC) AS row_num3,
order_id,
user_no,
amount,
create_date
FROM order_tab) t;

上面三个函数的区别,row_number()在amount都是800的两条记录上随机排序,但序号按照1、2递增,后面amount为600的的序号继续递增为3,中间不会产生序号间隙;rank()/dense_rank()则把amount为800的两条记录序号都设置为1,但后续amount为600的需要则分别设置为3(rank)和2(dense_rank)。即rank()会产生序号相同的记录,同时可能产生序号间隙;而dense_rank()也会产生序号相同的记录,但不会产生序号间隙。
分布函数
分布函数——percent_rank()/cume_dist()。
percent_rank()
-
用途:和之前的RANK()函数相关,每行按照如下公式进行计算:
-
(rank - 1) / (rows - 1)
-
其中,rank为RANK()函数产生的序号,rows为当前窗口的记录总行数。
-
应用场景:用的比较少,了解就好。
SELECT *
FROM
(SELECT rank() OVER w AS row_num,
percent_rank() OVER w AS percent,
order_id,
user_no,
amount,
create_date
FROM order_tab WINDOW w AS (PARTITION BY user_no
ORDER BY amount DESC) ) t;
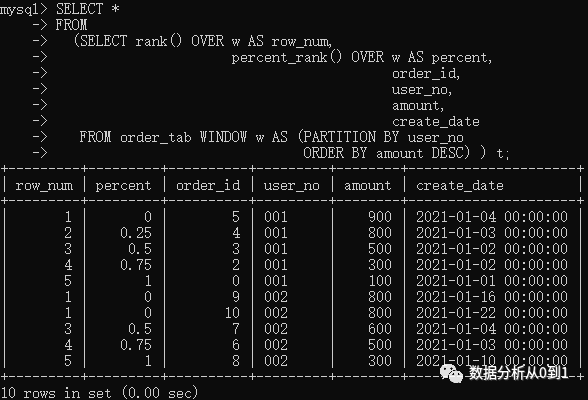
从结果看出,percent列按照公式(rank - 1) / (rows - 1)带入rank值(row_num列)和rows值(user_no为‘001’和‘002’的值均为5)。
cume_dist()
-
用途:分组内小于等于当前rank值的行数/分组内总行数,这个函数比percen_rank使用场景更多。
-
应用场景:大于等于当前订单金额的订单比例有多少。
SELECT *
FROM
(SELECT rank() OVER w AS row_num,
cume_dist() OVER w AS cume,
order_id,
user_no,
amount,
create_date
FROM order_tab WINDOW w AS (PARTITION BY user_no
ORDER BY amount DESC) ) t;

最后总结
本篇讲述了2个函数,分别是:
-
序号函数
-
row_number() / rank() / dense_rank()
-
分布函数
-
percent_rank()/cume_dist()
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









