






一、代理原理
代理的核心思想是使用语言模型来选择一系列操作。在链中,一系列操作是硬编码的。在代理中,语言模型被用作推理引擎来确定要采取哪些操作以及按什么顺序。
需要了解的重要概念:
需要了解的重要概念:
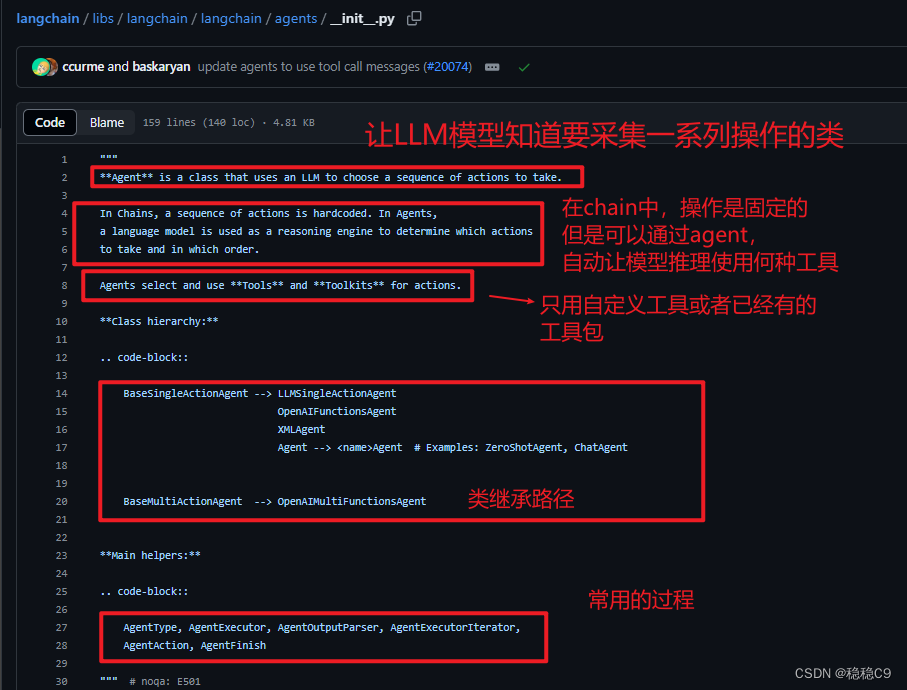
AgentAction:表示代理应采取的操作。它有一个tool属性(要调用的工具的名称)和一个tool_input属性(该工具的输入)AgentFinish:表示代理已完成,应返回给用户。它有一个return_values参数,它通常只有一个键——output,即一个字符串,因此通常只返回这个键。intermediate_steps:代表之前的代理操作和相应输出。这对于传递给未来迭代非常重要,所以代理知道它已经完成了哪些工作。它被编码为List[Tuple[AgentAction, Any]].
总的来说,代理的核心思想是:
- 使用语言模型来选择一系列操作
AgentAction表示一个操作 [] (messagelog)AgentFinish表示代理已完成 [AgentFinish(return_values={‘output’: ‘单词"color"有5个字母。’}, log=‘单词"color"有5个字母。’)]intermediate_steps记录之前的操作和输出,用于未来迭代【tool3 ,tools2,tools3】
语言模型作为推理引擎,确定要采取哪些操作和按什么顺序。
Agent(代理):在 Langchain 中,Agent 是指一个智能合约的实例。它代表了合约的执行者,可以看作是一个具有特定功能的智能合约的化身。Agent 能够根据合约的逻辑执行相应的操作,如转账、查询余额等。它是区块链网络中的一个基本单位,可以理解为一个可编程的、自主执行任务的角色。
Chain(链):Langchain 中的 Chain 指的是一个由多个 Agent 组成的序列。这些 Agent 按照一定的顺序链接在一起,形成一个链式结构。Chain 是 Langchain 平台的基本组织结构,用于实现分布式账本、智能合约等功能。每个 Chain 都对应一个唯一的标识符,如一个哈希值。Chain 中的 Agent 按照预先设定的规则执行任务,共同维护整个链的稳定和安全。
Agent 是 Chain 的基本组成单元,一个 Chain 由多个 Agent 构成。
Chain 是 Agent 存在的载体,Agent 通过加入 Chain 来实现其功能和价值。
Agent 和 Chain 共同构成了 Langchain 平台的核心技术体系
1、源码查看
2、创建工具 (装饰器方法)
from langchain.chat_models import ChatOpenAI
# 创建语言模型
llm = ChatOpenAI(temperature=0)
# 构建工具
from langchain.agents import tool
@tool
def get_word_length(word: str) -> int:
"""返回单词的长度"""
return len(word)
# 创建工具清单
tools = [get_word_length]
看看工具函数
一个name参数,代表这个函数名称
一个description,返回这个工具的使用说明

3、绑定工具
# 绑定工具
from langchain.tools.render import format_tool_to_openai_function # 格式化函数作为符合openai格式的描述体
llm_with_tools = llm.bind(
functions=[format_tool_to_openai_function(t) for t in tools]
)
format_tool_to_openai_function 这个方法将工具函数,转换为符合 OpenAi格式的描述体,即 fucntion calling
函数调用是构建由 LLM 驱动的聊天机器人或代理的一项重要功能,这些聊天机器人或代理需要检索 LLM 的上下文或通过将自然语言转换为 API 调用来与外部工具交互。

4、创建代理
下面代码,一个是prompt,创建了2个输入key
- input 用于用户输入内容
- agent_scratchpad 用户代理中间使用过程的记录
# 创建代理
from langchain.agents.format_scratchpad import format_to_openai_functions
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个非常优秀的人,但是不会计算单词的长度"),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"), # 消息体当中添加一个 key,记录代理的使用过程
])
agent = {
"input": lambda x: x["input"],
"agent_scratchpad": lambda x: format_to_openai_functions(x['intermediate_steps']) # 代理的使用过程
} | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
现在来使用它
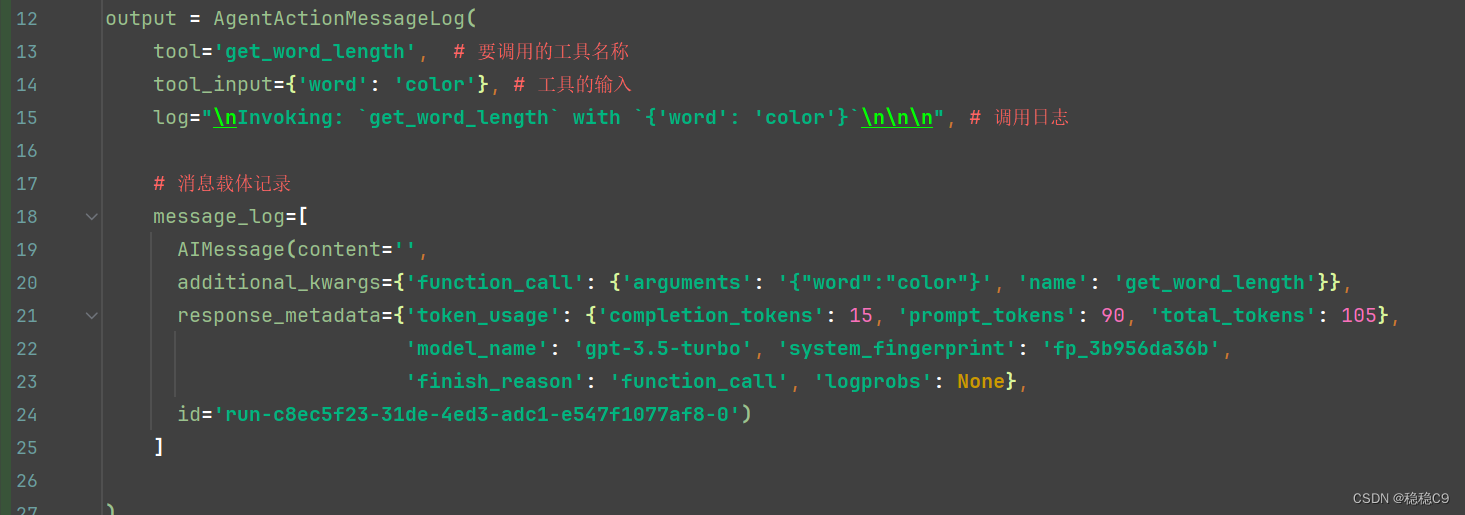
output = agent.invoke({
"input": "关于color有多少个字母?",
"intermediate_steps": [],# 中间步骤
})
可以看到生成了 一个 AgentActionMessageLog ,这个表示代理应该要采集的动作,并没有到结束

为了更加直观,我复制出来
可以看到,将用户的问:“关于color有多少个字母?” 这个问题去,提取了 color,并且准备调用 get_word_length 工具函数
关键字:tool、tool_input
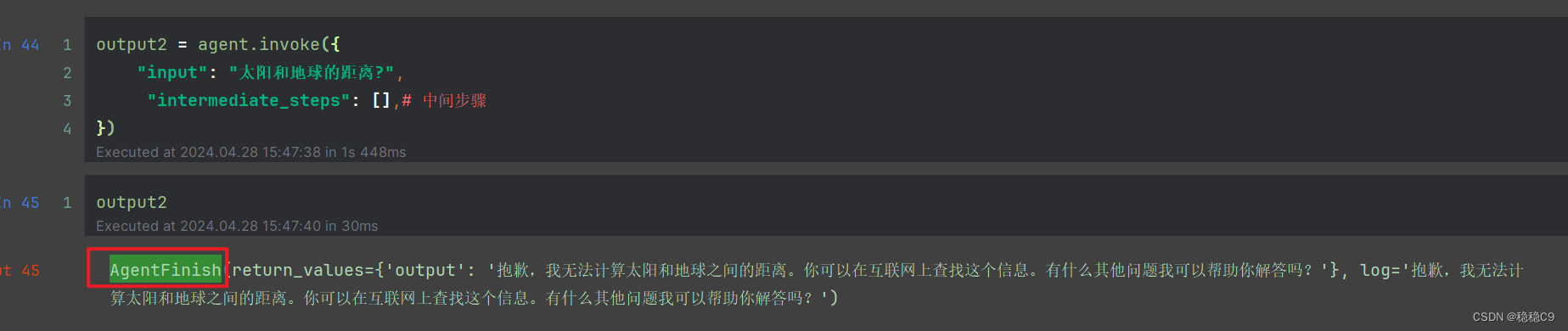
现在我询问另外一个问题,看看输出的样式,直接为 AgentFinish,这个表明代理已经完成动作,原因在于,我们封装的工具函数,并没有解决 “太阳和地球的距离”
关键字:return_values
5、完整代码
好了,到现在是不是看起来有点懵逼,现在,通过下面代码来加深一步过程
一个代理Agent,从白话文来说-简化成2个过程
- AgentAction 代理开始
- AgentFinish 代理结束,当只有看到这个类型才视为结束
那么现在,将前面的代码抽取出来,通过while True 完善 工具链的使用
from langchain.chat_models import ChatOpenAI
# 创建语言模型
llm = ChatOpenAI(temperature=0)
# 构建工具
from langchain.agents import tool
@tool
def get_word_length(word: str) -> int:
"""返回单词的长度"""
return len(word)
# 创建工具清单
tools = [get_word_length]
# 绑定工具
from langchain.tools.render import format_tool_to_openai_function # 格式化函数作为符合openai格式的描述体
llm_with_tools = llm.bind(
functions=[format_tool_to_openai_function(t) for t in tools]
)
# 创建代理
from langchain.agents.format_scratchpad import format_to_openai_functions
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个非常优秀的人,但是不会计算单词的长度"),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"), # 消息体当中添加一个 key,记录代理的使用过程
])
agent = {
"input": lambda x: x["input"],
"agent_scratchpad": lambda x: format_to_openai_functions(x['intermediate_steps']) # 代理的使用过程
} | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
from langchain.schema.agent import AgentFinish
intermediate_steps = []
count = 1
while True:
output = agent.invoke({
"input": "关于color有多少个字母?",
"intermediate_steps": intermediate_steps
})
print(f'\n轮询第{count}次',output,'过程对象:',type(output))
count +=1
# 判断代理是否有结束标记,有的话结束
if isinstance(output, AgentFinish):
final_result = output.return_values["output"]
break
else:
# 从AgentAction 中提取要执行的 tool(工具名称),跟tool_input(工具的输入参数)
tool = {
"get_word_length": get_word_length
}[output.tool]
observation = tool.run(output.tool_input) # 运行工具函数,并且得到结果
intermediate_steps.append((output, observation))
查看结果,可以看到出来了回复

6、简化代码
前面的代码,更多的是为了让大家了解底层原理,langchain提供了一个函数,用于简化操作。
from langchain.chat_models import ChatOpenAI
# 创建语言模型
llm = ChatOpenAI(temperature=0)
# 构建工具
from langchain.agents import tool
@tool
def get_word_length(word: str) -> int:
"""返回单词的长度"""
return len(word)
# 创建工具清单
tools = [get_word_length]
# 绑定工具
from langchain.tools.render import format_tool_to_openai_function # 格式化函数作为符合openai格式的描述体
llm_with_tools = llm.bind(
functions=[format_tool_to_openai_function(t) for t in tools]
)
# 创建代理
from langchain.agents.format_scratchpad import format_to_openai_functions
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个非常优秀的人,但是不会计算单词的长度"),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"), # 消息体当中添加一个 key,记录代理的使用过程
])
agent = {
"input": lambda x: x["input"],
"agent_scratchpad": lambda x: format_to_openai_functions(x['intermediate_steps']) # 代理的使用过程
} | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
# 使用代理
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_executor.invoke({"input": "关于color有多少个字母?"})
看看结果:
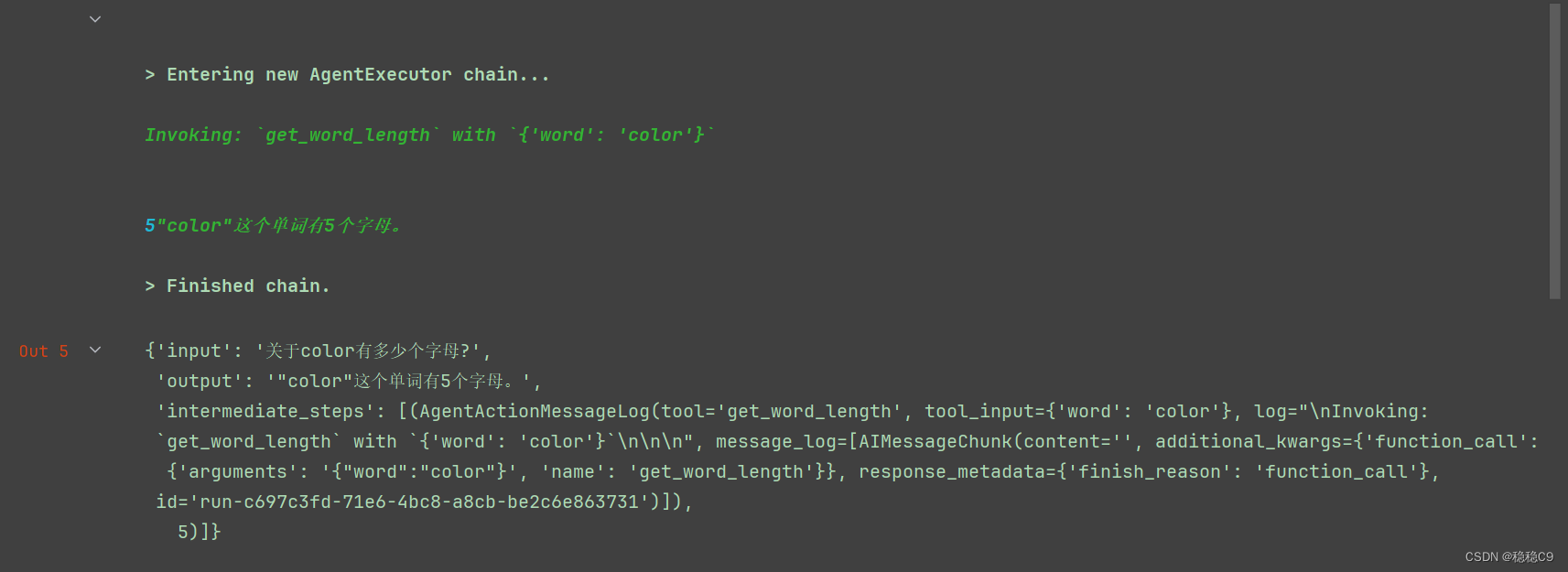
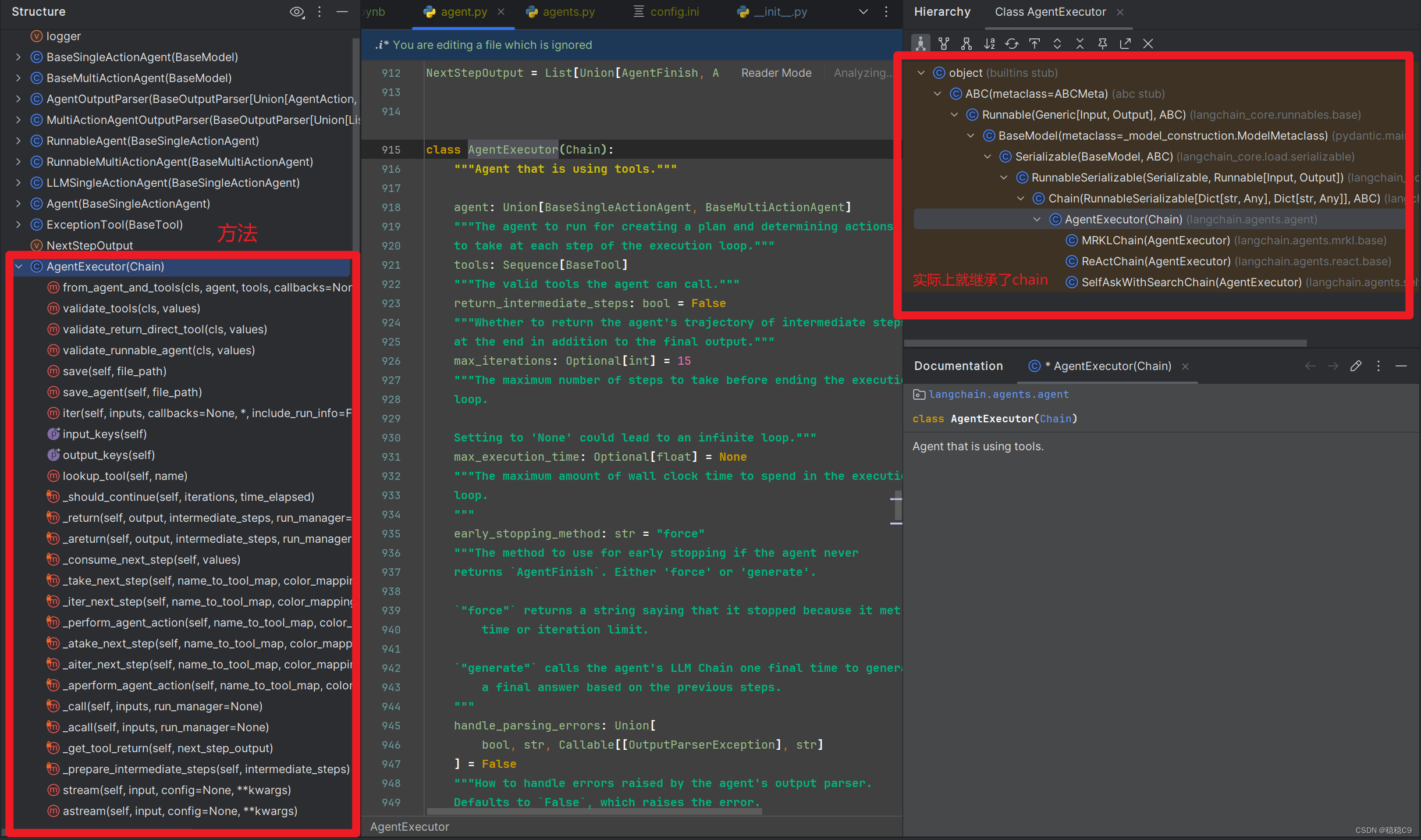
关于 AgentExecutor 这个方法常用参数说明
- max_iterations 默认迭代工具15次,可以设置
- return_intermediate_steps 是否返回代理的中间步骤轨迹在最后除了最终输出之外
关于 AgentExecutor 的源码
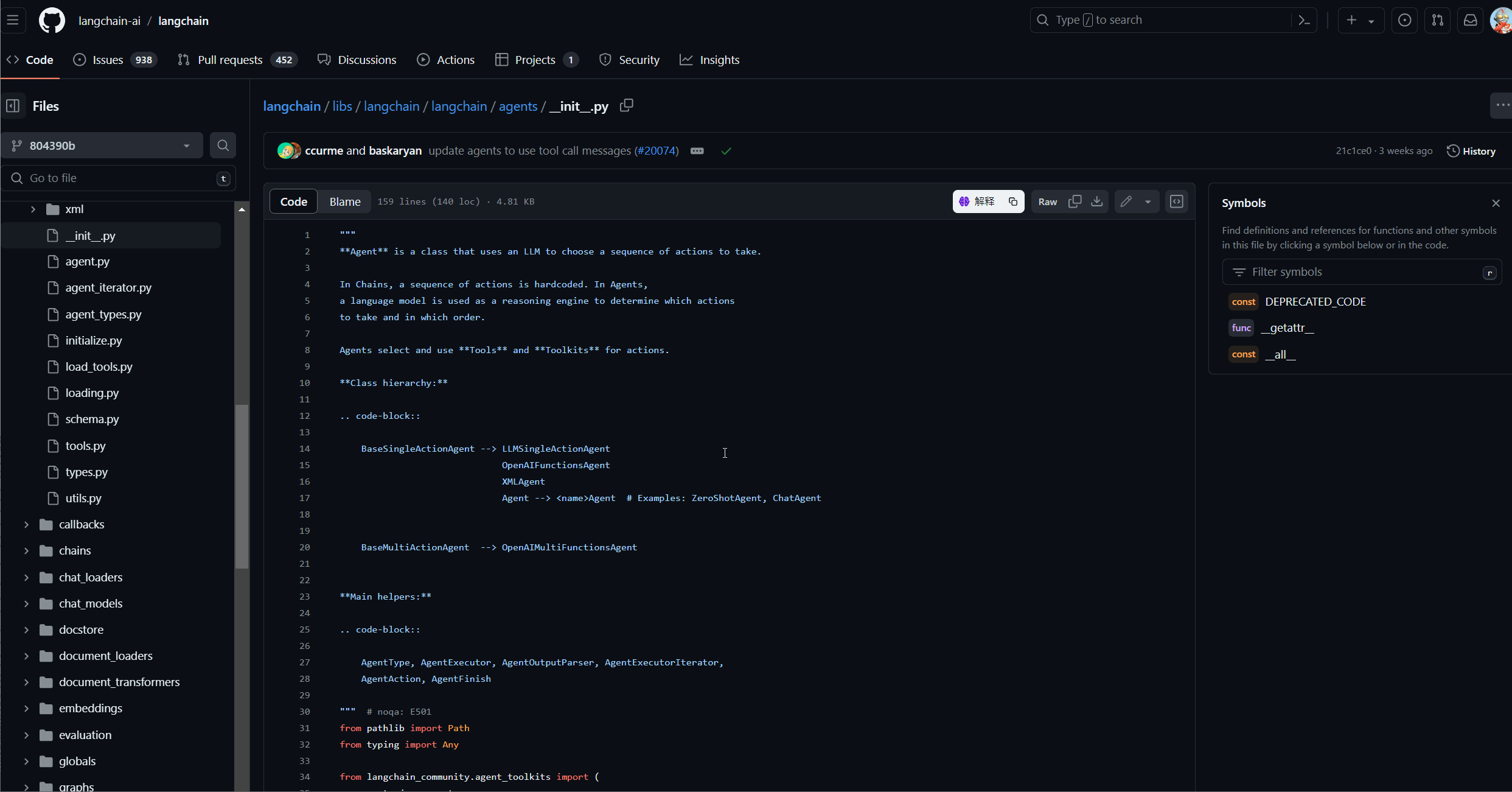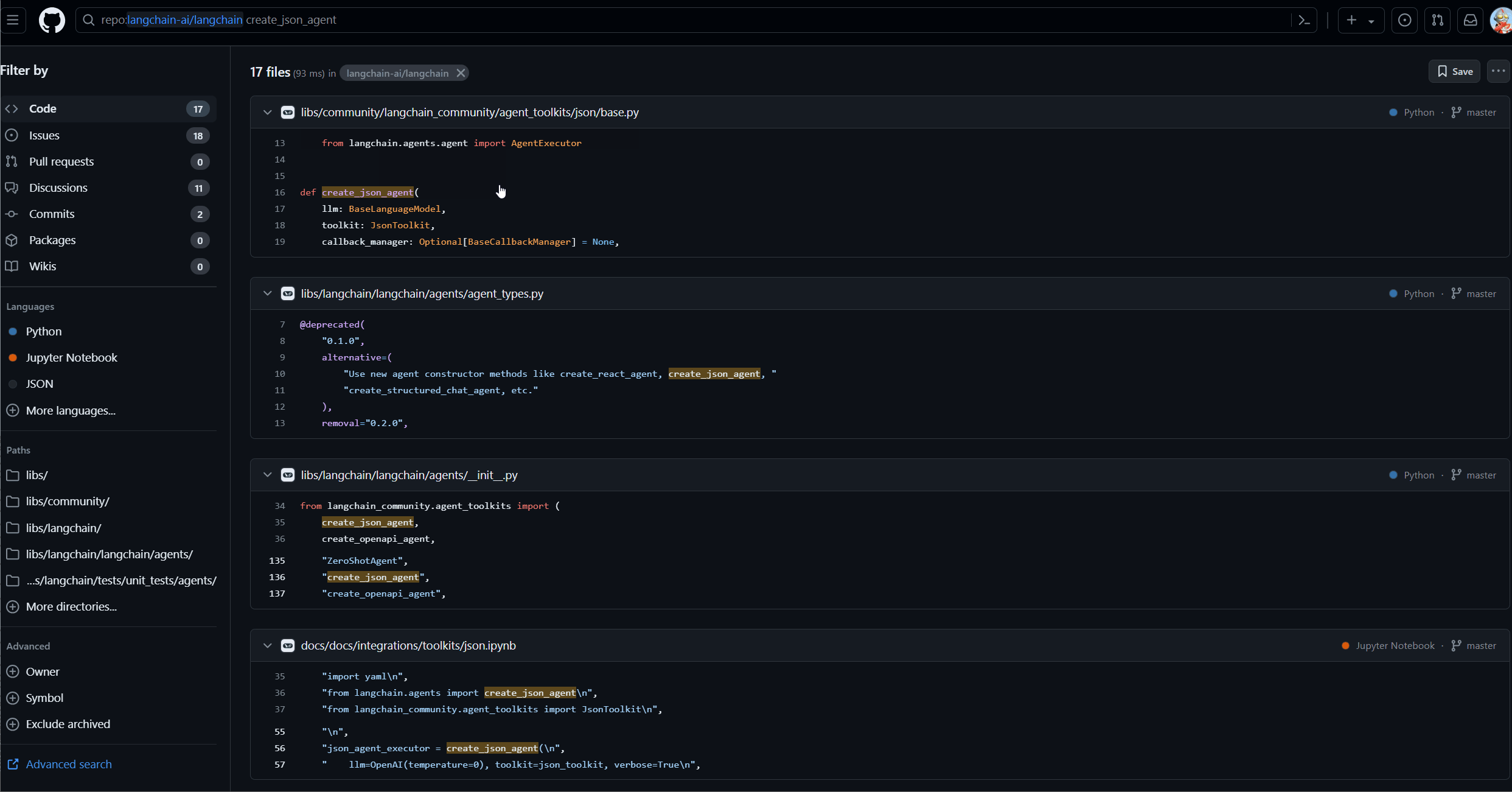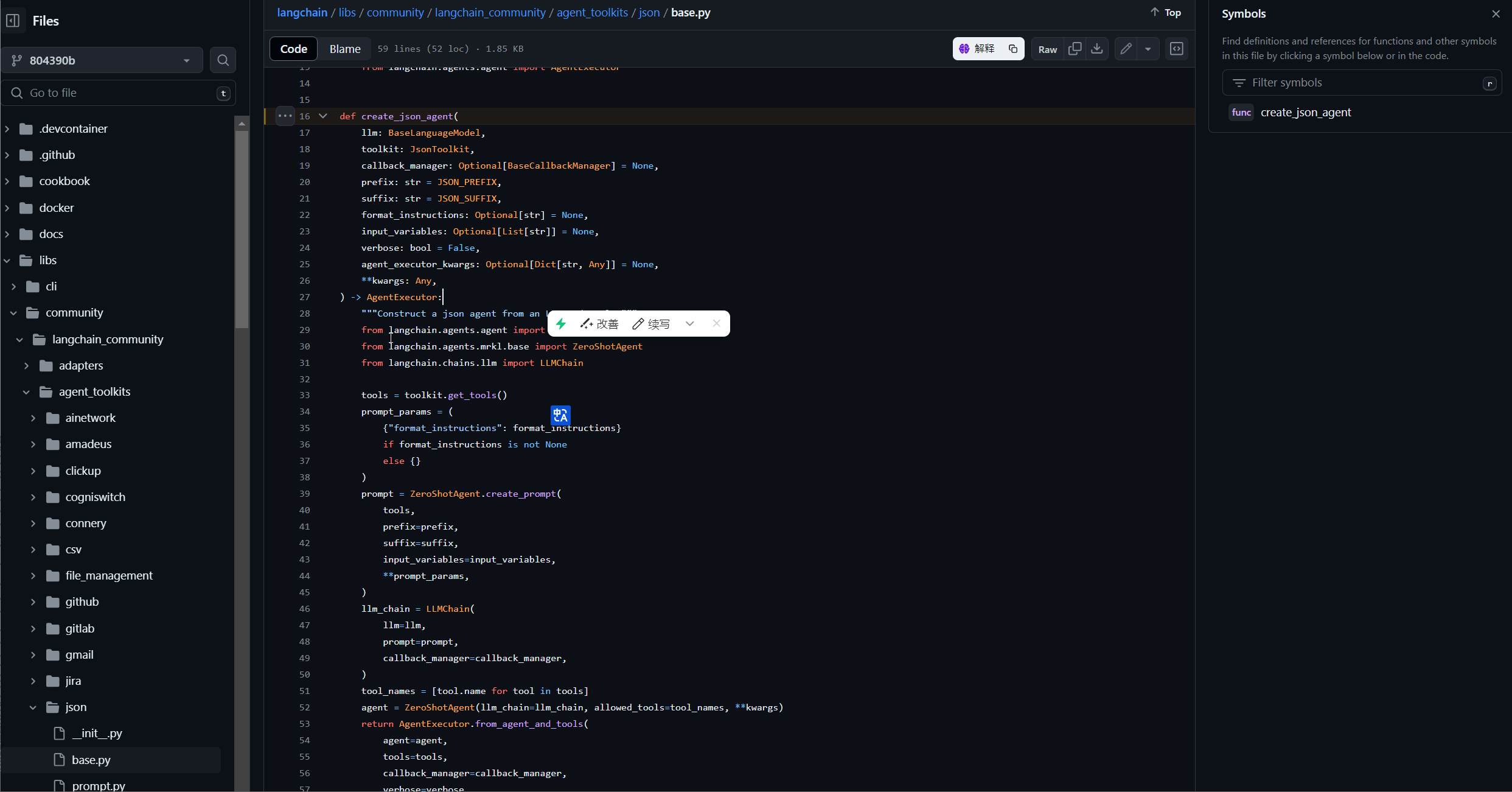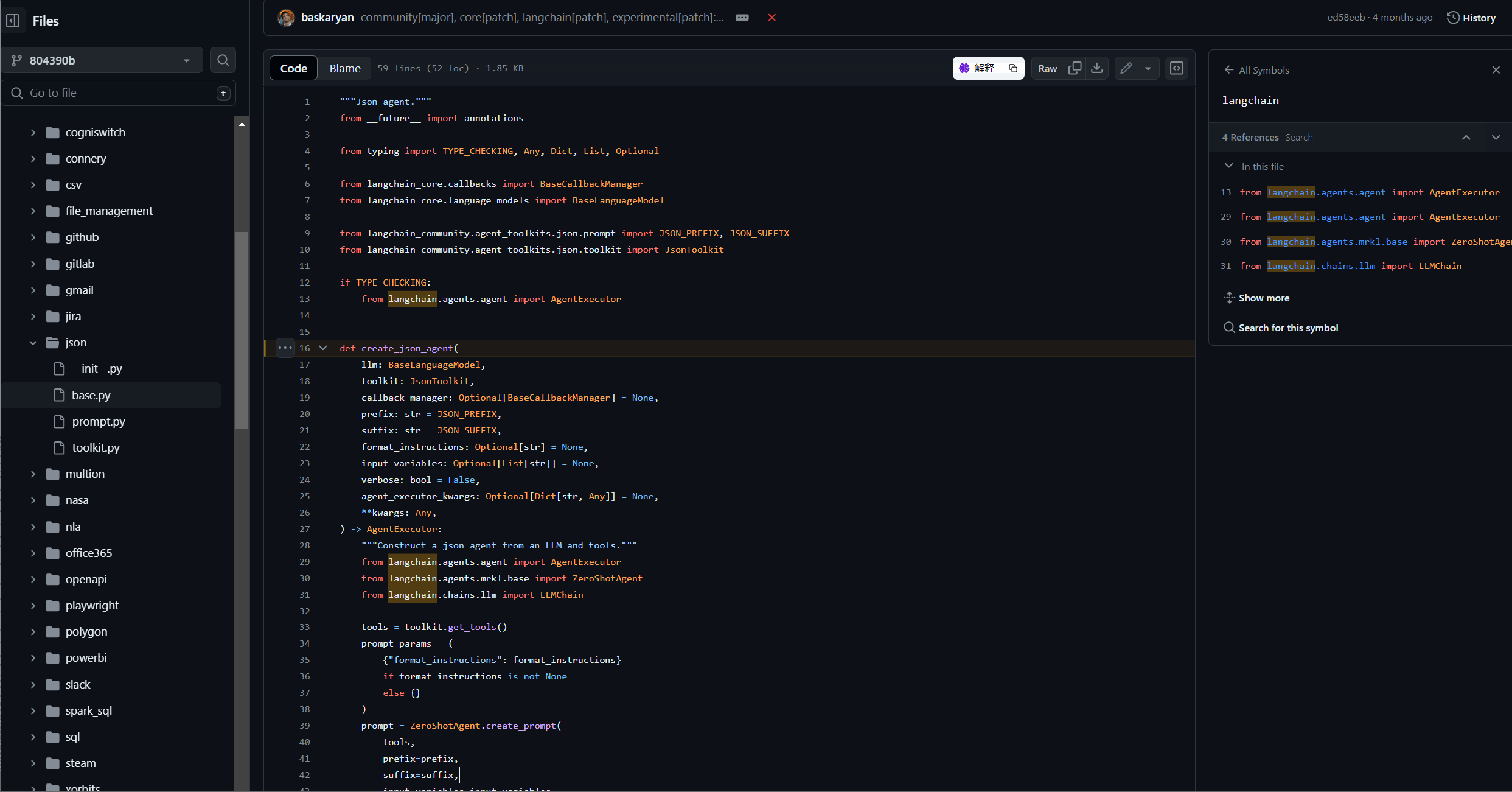
https://github.com/langchain-ai/langchain/blob/804390ba4bcc306b90cb6d75b7f01a4231ab6463/libs/langchain/langchain/agents/agent.py#L917
7、加上历史对话
为了做到这一点,需要添加内存来解决这个问题:
1、在提升中添加内存变量的位置
2、跟踪聊天记录
首先在提示中添加一个内存位置。通常使用带有key的消息添加占位符来实现此目的的“chat_history”
这个放入的位置是有讲究,放到新用户输入的之上(符合对话流程) MessagesPlaceholder 注意看 prompt 该位置
from langchain.agents.format_scratchpad import format_to_openai_functions
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain.prompts import MessagesPlaceholder, ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.agents import tool, AgentExecutor
from langchain.tools.render import format_tool_to_openai_function
# 创建语言模型
llm = ChatOpenAI(temperature=0)
# 构建工具
@tool
def get_word_length(word: str) -> int:
"""返回单词的长度"""
return len(word)
tools = [get_word_length]
# 绑定工具
llm_with_tools = llm.bind(
functions=[format_tool_to_openai_function(t) for t in tools]
)
MEMORY_KEY = "chat_history"
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个非常优秀的人,但是不会计算单词的长度"),
MessagesPlaceholder(variable_name=MEMORY_KEY),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
])
chat_history = []
agent = {
"input": lambda x: x["input"],
"agent_scratchpad": lambda x: format_to_openai_functions(x['intermediate_steps']),
"chat_history": lambda x: x["chat_history"]
} | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# 模拟已经对话过一次
input1 = "关于color有多少个字母?"
result = agent_executor.invoke({"input": input1, "chat_history": chat_history})
# 历史消息加上聊天记录
chat_history.append(HumanMessage(content=input1))
chat_history.append(AIMessage(content=result['output']))
agent_executor.invoke({"input": "这个单词中文翻译是什么?", "chat_history": chat_history})
可以看到执行了2次

二、Agent使用
在开始下面之前,以1,2 小节知识作为更好理解代理,Agent,既可以看到成tool工具,chain链,等等
1、langchain-smith 介绍
在开始之前,先了解一下 langchain - smith 上提供的 hub 平台,当然这个平台还有其它功能,比如测试应用的流等等
https://smith.langchain.com/hub
其中这个平台提供了很多 prompt 的用例,我们可以通过代码拉取现成的prompt 在langchain中使用
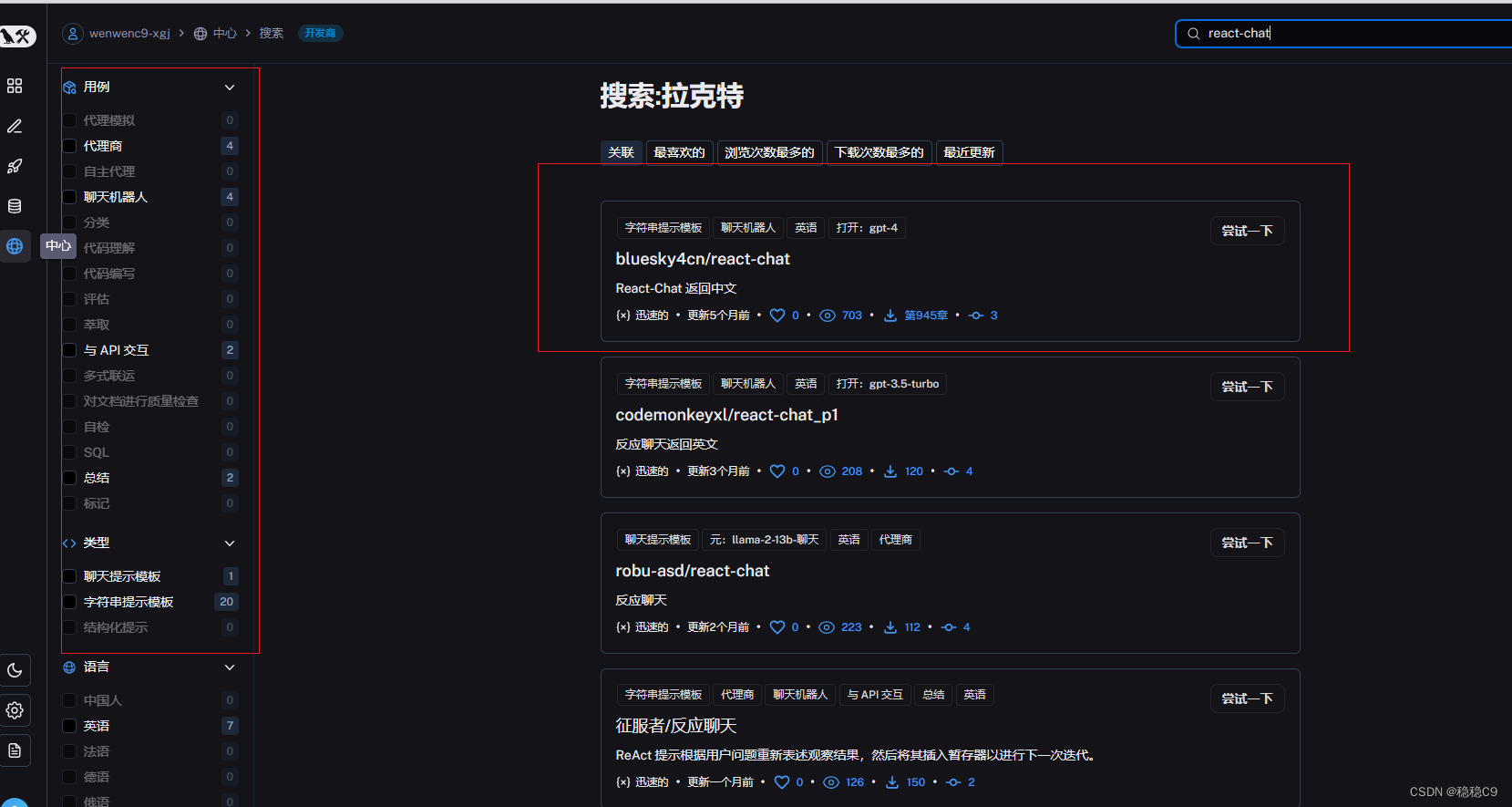
我们来看一下这个 prompt
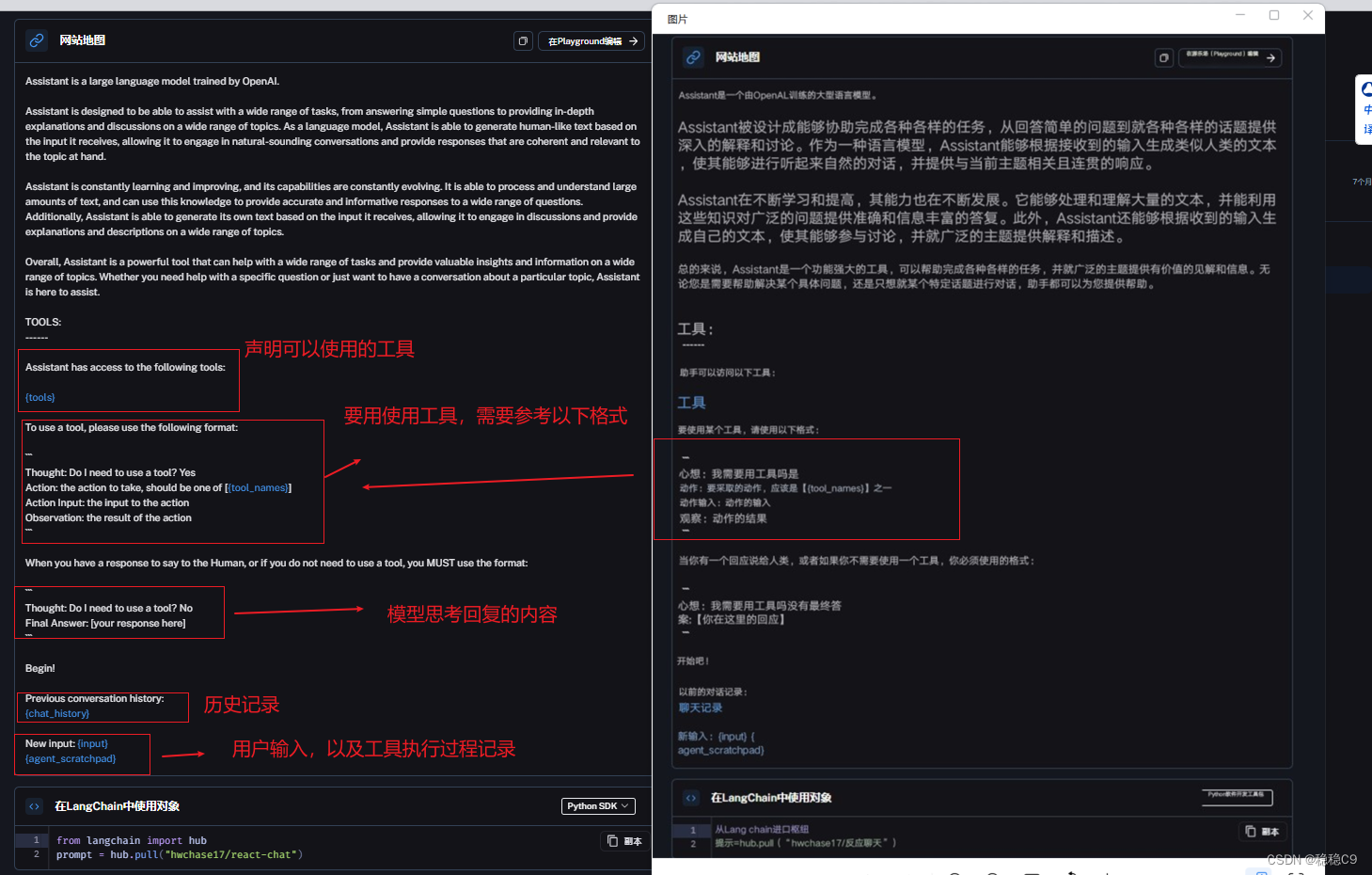
2、ReAct 介绍
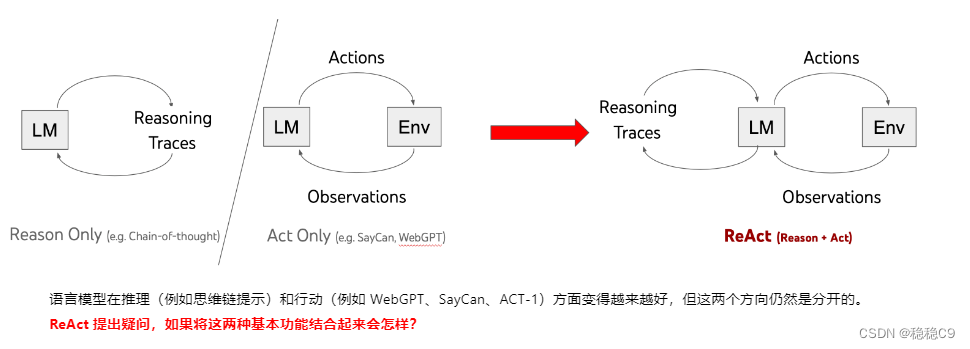
ReAct 是一个结合了推理和行动功能的方法,通过交叉生成推理轨迹和特定于任务的动作,从而实现更大的协同作用。它在问答和决策任务中表现优秀,具有较高的可解释性和可信度。通过人类对齐的 ReAct 提示设计,使得模型能够更好地理解和应用人类思维的模式,取得了令人印象深刻的结果。虽然还存在改进的空间,但ReAct 在许多任务上展示出了很高的潜力和有效性。

关键词记忆:
- Action 行动
- Thought 思考做出何种决策
- Observation 观察决策的结果
- Answer 回复总结答案
- Finish 结束推理决策
当然,这是一种prompt的写法,能够很好的提升对于交互问题,另外还有,COT、TOT等架构,如果想了解更多promtp等使用,可以阅读下面网站
https://www.promptingguide.ai/research
3、使用内置工具
在本案例中,通过内置工具调用,并且利用langchain-smith 中 hub 的prompt ,将工具绑定进去使用
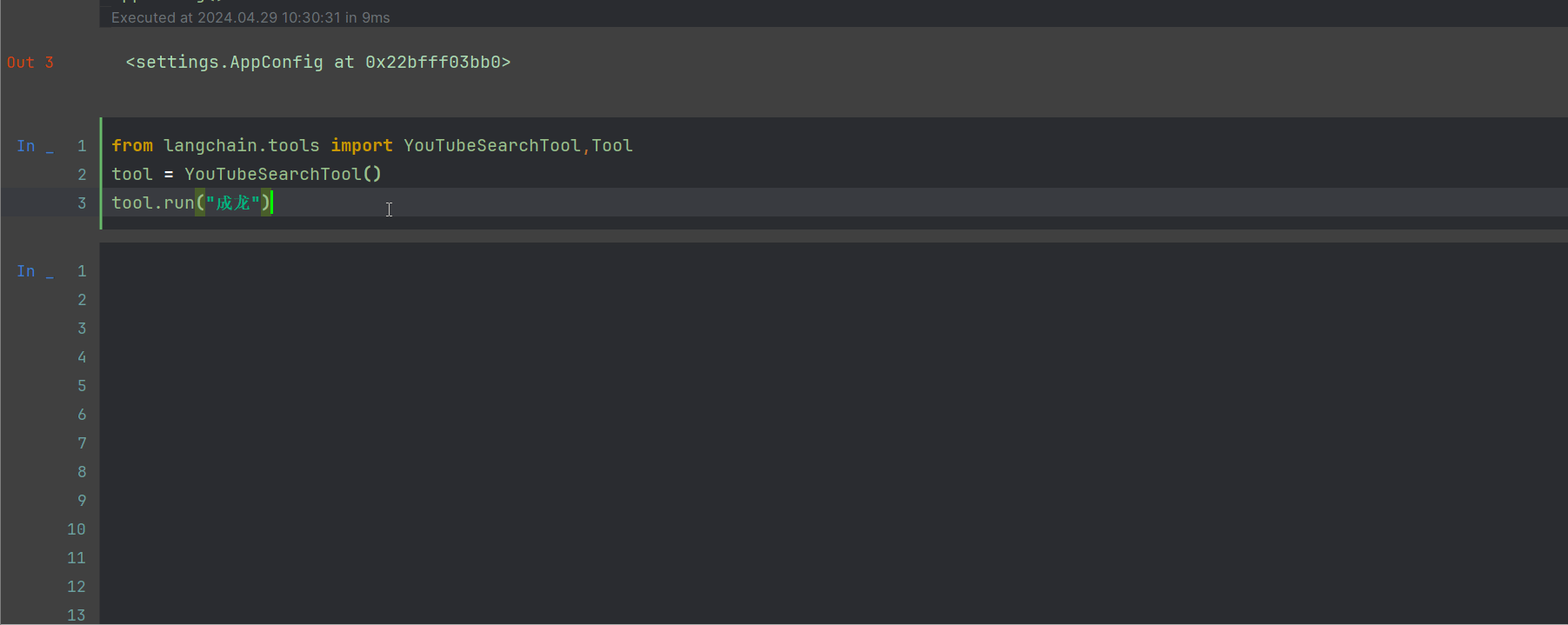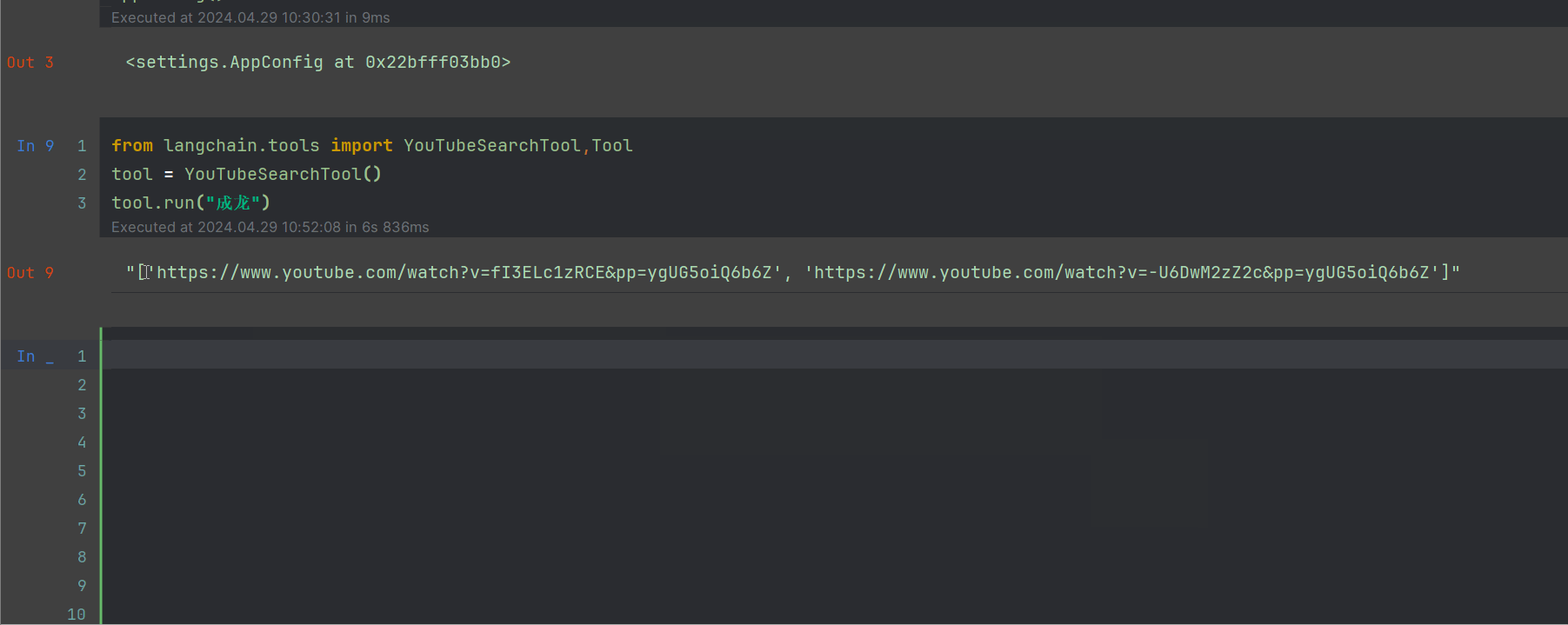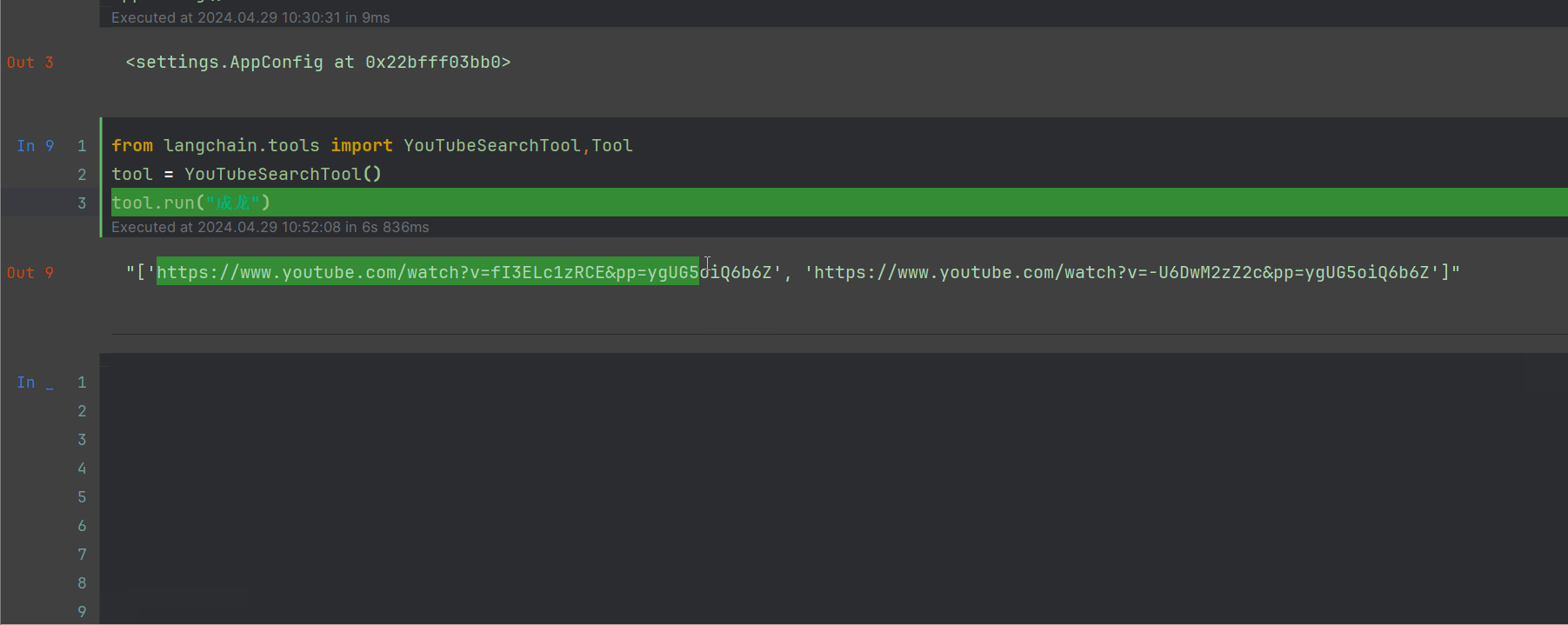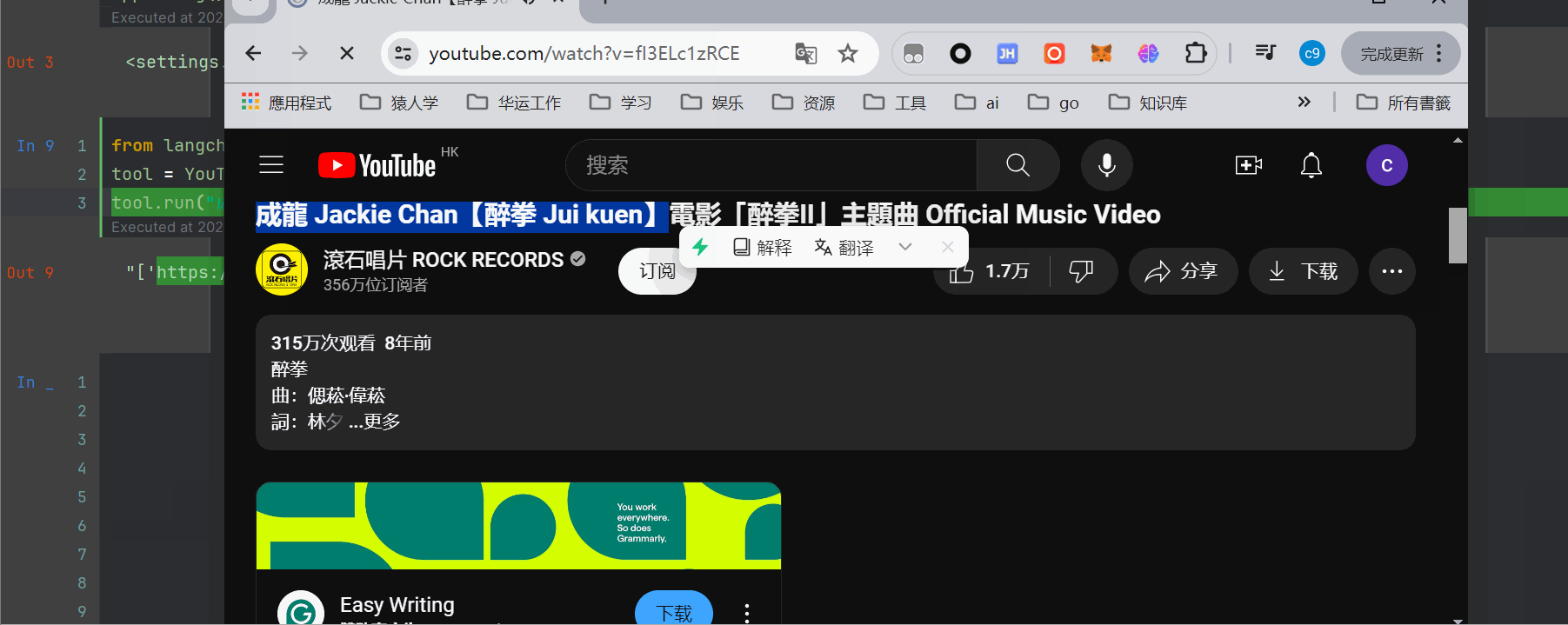
from langchain.tools import YouTubeSearchTool,Tool
tool = YouTubeSearchTool()
tool.run("成龙")
可以看到,能够出来2个url,此时打开网页查询一下
利用partial,格式化部分模版的参数,这里将hub模版拉下来,指定2个参数添加内容(这个模版有5个参数,这里只要2个使用)
https://github.com/langchain-ai/langchain/blob/804390ba4bcc306b90cb6d75b7f01a4231ab6463/libs/core/langchain_core/prompts/base.py#L181
如果用format_prompt 则需要指定额外参数才行,可以看源码,或者自己体验,只传2个参数会出错
from langchain.tools import YouTubeSearchTool,Tool
tool = YouTubeSearchTool()
# 创建工具
tools = [
Tool(
name='youtube搜索',
func=tool.run,
description='用户如果问题有关成龙则使用这个工具'
)
]
# 在prompt中绑定工具
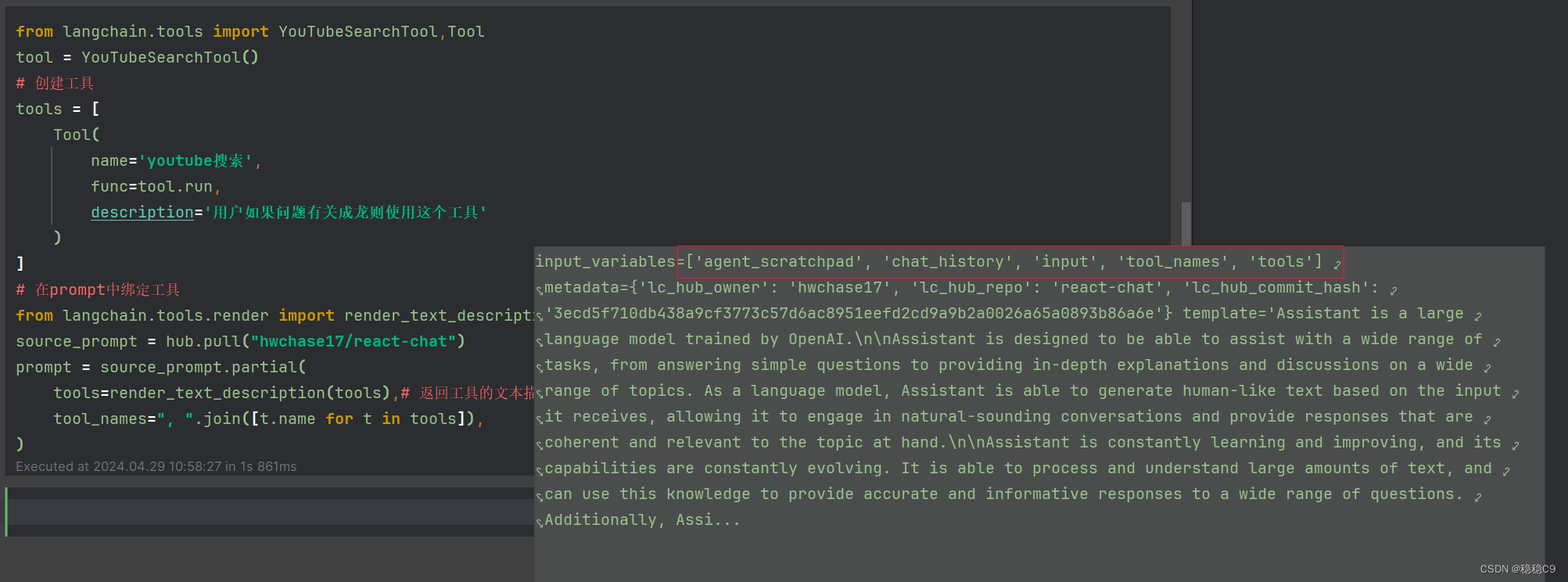
from langchain.tools.render import render_text_description
source_prompt = hub.pull("hwchase17/react-chat")
prompt = source_prompt.partial(
tools=render_text_description(tools),# 返回工具的文本描述
tool_names=", ".join([t.name for t in tools]),
)
# 绑定工具
from langchain.llms import OpenAI
llm = OpenAI(temperature=0)
llm_with_stop = llm.bind(stop=["\nObservation"]) # 参考ReAct架构,添加一个停止词
# 创建代理,可以看到这里对于模版剩下3个提示词,进行了操作,
from langchain.agents.output_parsers import ReActSingleInputOutputParser
from langchain.agents.format_scratchpad import format_log_to_str
agent = {
"input": lambda x: x["input"],# 用户输入
"agent_scratchpad": lambda x: format_log_to_str(x['intermediate_steps']),# 一个是代理执行步骤
"chat_history": lambda x: x["chat_history"] # 聊天记录
} | prompt | llm_with_stop | ReActSingleInputOutputParser()
# 创建代理执行执行器
from langchain.agents import AgentExecutor
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history")
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True, memory=memory)
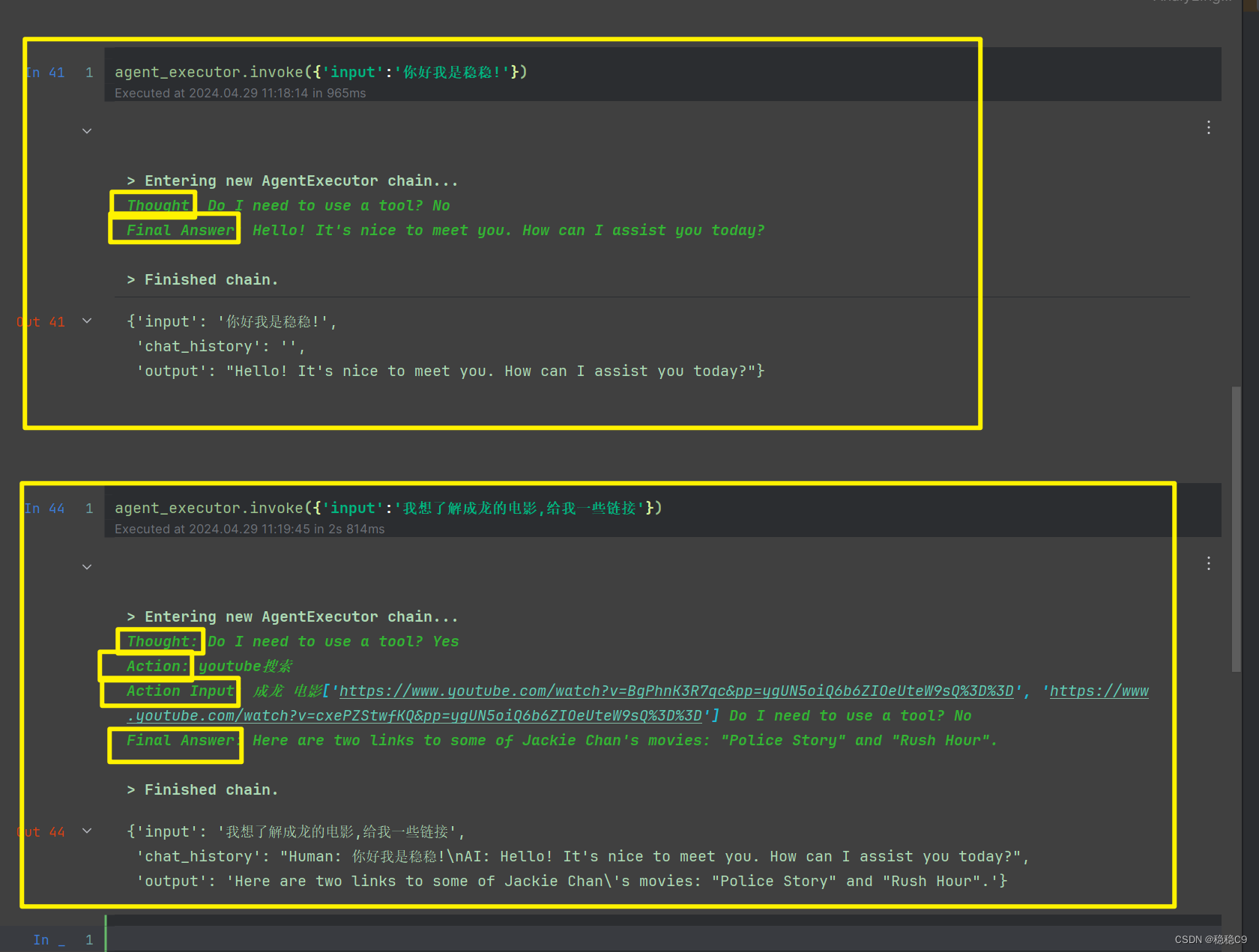
看看结果,2轮对话
4、AgentType
在前面,我们看到了工具创建好了,都通过自己创建Agent进行,使用,现在我们可以通过现成的封装直接使用,关于更多功能
查看源代码

准备工作,去这个平台注册一个key
https://serpapi.com/manage-api-key
安装一个包
pip install google-search-results
from langchain.agents import Tool
from langchain.agents import AgentType
from langchain.memory import ConversationBufferMemory
from langchain.llms import OpenAI
from langchain.utilities import SerpAPIWrapper
from langchain.agents import initialize_agent
import os
os.environ["SERPAPI_API_KEY"] = ""
search = SerpAPIWrapper()
tools = [
Tool(
name='物流工具',
func=search.run,
description='这对于回答相关船期与货物跟踪的时候非常有用,如果计算问题不要使用这个工具'
)
]
llm = OpenAI(temperature=0)
memory = ConversationBufferMemory(memory_key="chat_history")
# 使用现成的代理类创建代理
agent_executor = initialize_agent(
tools,
llm,
agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION,
verbose=True,
memory=memory,
)
关于 AgentType.CONVERSATIONAL_REACT_DESCRIPTION
执行一下看看结果
agent_executor.invoke({'盐田到洛杉矶会经过哪些港口'})
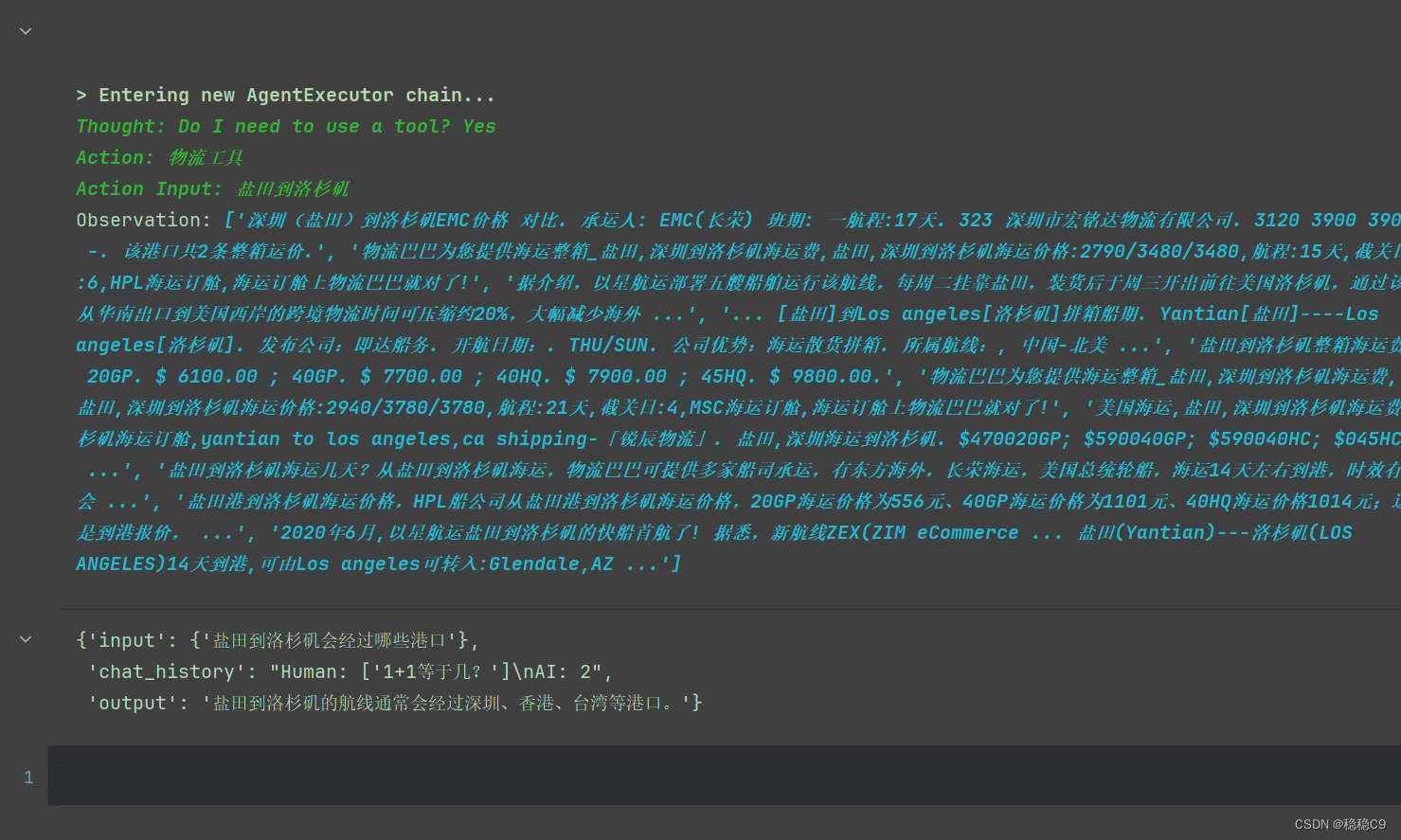
5、多工具组合以及AgentExecutorIterator使用
AgentExecutorIterator 在 langchain 中主要用于:
批量执行代理AgentExecutorIterator 可以将一组输入数据,批量传递给代理,并获取代理的批量输出。迭代执行代理AgentExecutorIterator 可以迭代执行代理,每次传递一个输入,获取一个输出。提供进度提示AgentExecutorIterator 可以提供进度提示,显示当前执行到第几个输入。
step1:创建模型跟链
from langchain.chains import LLMMathChain
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature=0, model="gpt-4")
llm_math_chain = LLMMathChain.from_llm(llm=llm, verbose=True)
step2:创建2个工具
import pydantic.v1 as pydantic
from langchain.agents.tools import Tool
primes = {998: 7901, 999: 7907, 1000: 7919}
class CalculatorInput(pydantic.BaseModel):
"""计算器的输入"""
question: str = pydantic.Field()
class PrimeInput(pydantic.BaseModel):
"""主输入"""
n: int = pydantic.Field()
def is_prime(n: int) -> bool:
if n <= 1 or (n % 2 == 0 and n > 2):
return False
for i in range(3, int(n ** 0.5) + 1, 2):
if n % i == 0:
return False
return True
def get_prime(n: int, primes: dict = primes) -> str:
"""计算素数"""
return str(primes.get(int(n)))
async def aget_prime(n: int, primes: dict = primes) -> str:
"""代理"""
return str(primes.get(int(n)))
# 工具清单
tools = [
Tool(
name="GetPrime",
func=get_prime,
description="返回第 n 个素数的工具",
args_schema=PrimeInput, # 以pydantic 进行约束字段
coroutine=aget_prime, # 异步
),
Tool.from_function(
func=llm_math_chain.run,
name="Calculator",
description="当您需要计算数学表达式时很有用",
args_schema=CalculatorInput, # 以pydantic 进行约束字段
coroutine=llm_math_chain.arun, # 异步
),
]
step3:创建代理并且使用代理
# 创建代理
agent = initialize_agent(
tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
# 使用代理
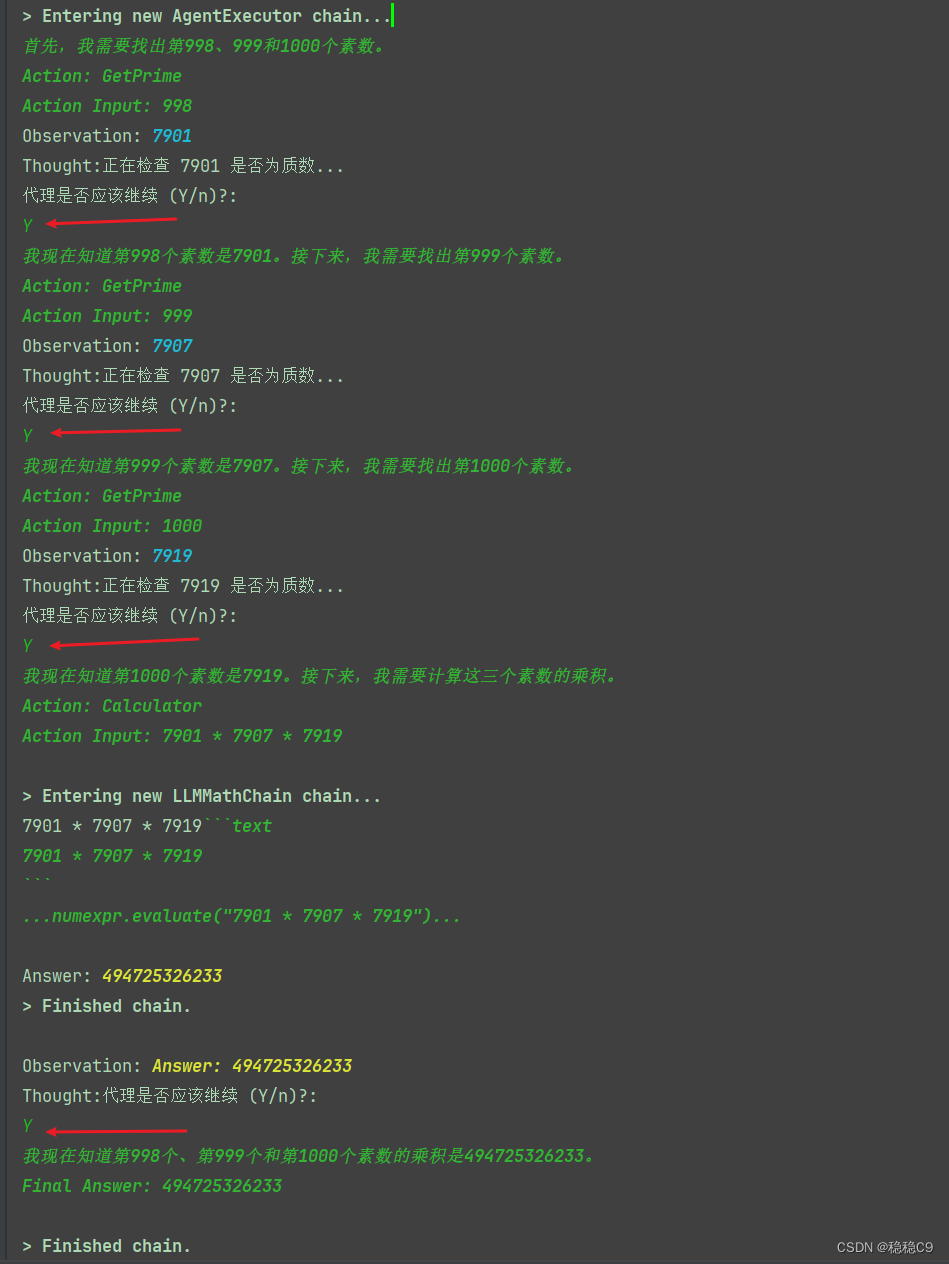
question = "第 998 个、第 999 个和第 1000 个素数的乘积是多少?"
for step in agent.iter(question):
if output := step.get("intermediate_step"):
action, value = output[0]
if action.tool == "GetPrime":
print(f"正在检查 {value} 是否为质数...")
assert is_prime(int(value))
# Ask user if they want to continue
_continue = input("代理是否应该继续 (Y/n)?:\n")
if _continue != "Y":
break
查看结果,很有意思
1、检查用户输入的998,999,1000 通过工具 is_prime 检查是否为素数
2、然后最后得到3个素数,调用 get_prime 工具进行计算
3、整个过程当中因为使用了ReAct ,能够看到关键词
- Action
- Action input
- Observation
- Thought
- Answer
- Final Answer
4、什么时候使用另外一个工具,也做到了,这就是prompt工程的魅力
平替方法:
from langchain.agents import AgentExecutorIterator
AgentExecutorIterator(
agent_executor=agent_executor,
inputs=[{'input': "第 998 个、第 999 个和第 1000 个素数的乘积是多少?"}]
)
# 迭代执行代理,获取输出
outputs = []
for output in iterator:
outputs.append(output)

6、总结
为了更好的理解Agent,langchain封装了挺多的函数
- 对于用户输入前内容处理的函数 比如,利用 prompt
- 对于模型与内容交互时候处理工艺的函数,比如利用 ReAct模式
- 对于返回结果,格式化某样式的工艺函数,比如输出JSON

对于Agent而言,前文也做了部分解释
Agent(代理):在 Langchain 中,Agent 是指一个智能合约的实例。它代表了合约的执行者,可以看作是一个具有特定功能的智能合约的化身。Agent 能够根据合约的逻辑执行相应的操作,如转账、查询余额等。它是区块链网络中的一个基本单位,可以理解为一个可编程的、自主执行任务的角色。
Chain(链):Langchain 中的 Chain 指的是一个由多个 Agent 组成的序列。这些 Agent 按照一定的顺序链接在一起,形成一个链式结构。Chain 是 Langchain 平台的基本组织结构,用于实现分布式账本、智能合约等功能。每个 Chain 都对应一个唯一的标识符,如一个哈希值。Chain 中的 Agent 按照预先设定的规则执行任务,共同维护整个链的稳定和安全。
Agent 是 Chain 的基本组成单元,一个 Chain 由多个 Agent 构成。
Chain 是 Agent 存在的载体,Agent 通过加入 Chain 来实现其功能和价值。
Agent 和 Chain 共同构成了 Langchain 平台的核心技术体系
源码地址
可以看到有很多方法跟功能

对于部分封装函数,以案例介绍,对于详细函数的理解,建议大家看源码,比如这样
复制 create_json_agent 这个函数,在源码进行查看
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓















 997
997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









