







散列表(hashTable的原理)
也叫哈希表,是根据关键码值(key-value),直接进行访问的数据结构。将关键码值映射到表的一个位置来访问,加快查找速度。这个映射函数叫散列函数。存放记录的数组叫散列表。
y = f(x); x是关键字,f是散列函数(哈希函数),y是记录的存储位置。
目的:
数组特点:寻址容易,插入和删除困难
链表特点:寻址困难,插入和删除容易
二者结合,最常用的一种方法-拉链法。
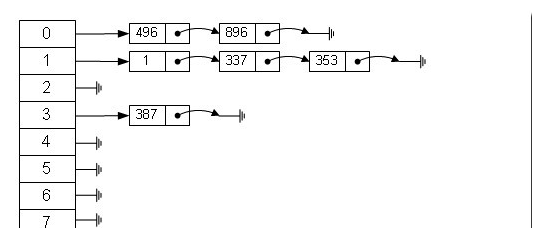
优点:不论哈希表有多少数据,查找、插入、删除,需要接近常量的时间即o(1)的时间级。哈希表运行的非常快。查找明显比树快,树的操作是o(n)的时间级。
缺点:它是基于数组,数组创建后难扩展。哈希表被基本填满时,性能下降非常严重。
散列冲突的解决方案:
开放寻址法,再散列法。
1.建立一个缓冲区,把拼音重复的人放在缓存区中。当我通过名称找人时,发现找的不对,则在缓存区找。
2.再探测,在其他的地方查找。
百度面试题:海量日志数据,提取出某日访问百度次数最多的IP
方案:IP数目是有限的,最多2^32个。但是2^32 = 4G不能完全放在内存。所以可以考虑使用将部分hash将ip存入内存,然后统计。















 236
236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









