







概述
生产者发送消息时在客户端就按照节点和Partition进行分组,属于同一个目标节点的多个Partition会作为同一个请求传送到服务端,作为目标节点的服务端也可以处理来自不同生产者客户端的请求。如果从网络层通信来看,客户端和服务端都会使用队列的方式确保顺序地客户端发送请求,服务端接收请求,服务端发送响应,客户端接收响应。从存储层来看,生产者会将消息分发到不同节点的不同Partition上,服务端的一个Partition的数据会来源于多个生产者。多个服务端节点组成的Kafka集群在物理层将消息分布在不同节点的不同Partition上,并且是以提交日志的形式追加到每个Partition中。对消息进行分区的好处是可以将大量的消息分成多批数据同时写到不同节点上,将写请求分担负载到各个节点。
消息系统的组成是生产者,存储系统和消费者,消费者会从存储系统读取生产者写入的消息。Kafka作为分布式的消息系统支持多个生产者和多个消费者,生产者可以将消息分布到集群中不同节点的不同Partition上,消费者也可以消费集群中多个Partition的多个Partition。写消息时允许多个生产者写到同一个Partition中,不过如果读消息时有多个消费者要同时读取同一个Partition,就需要在Partition级别的日志文件上控制确保将日志文件的不同数据分配给不同的消费者(不应该将同一份数据分配给两个相同的消费者,否则同一条消息就被重复处理了,虽然Kafka本身在消费者出现故障时可能会重复处理消息,但是如果在正常消费时就开始重复处理,这条路显然走不通),这种控制手段通常采用加锁同步严重影响性能的方式,所以如果我们约定同一个Partition只允许被一个消费者处理就不需要加锁同步了,不存在并发访问了,可以大大提升消费者的处理能力,而且也并不违反消息的处理语义:原先需要多个消费者处理,现在交给一个消费者处理也不是不可以,只要有消费者处理消息就可以了。
图4-1举例了一种最简单的消息系统部署模式,生产者的数据源多种多样,它们都统一写入到Kafka集群中,处理消息时有多个消费者进行任务分担,这些消费者的处理逻辑都是相同的,每个消费者处理的Partition都是不会重复的。
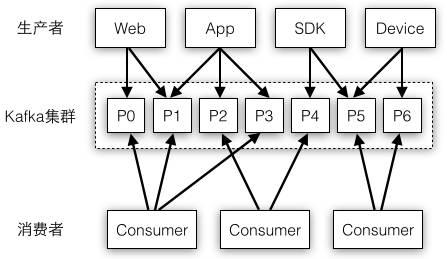
图4-1 消息系统包括生产者、消费者和存储系统
不过实际应用中消息通常存在多种处理方式,将图4-1中的多个消费者放到同一个消费组中,不同的消费组都可以有数量不同的消费者,比如可以根据实际情况对业务逻辑比较重要的消费组分配更多的消费者资源。图4-2示例了将消息系统作为数据处理系统的核心,消费组1将消息存储到Hadoop供离线分析,消费组3将消息存储到搜索引擎中,消费组2读取出消息时使用Storm/Spark等流处理系统进行实时分析。
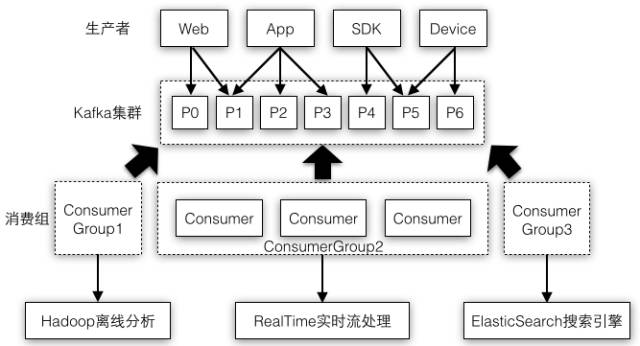
图4-2 不同消费组消费同一份消息
Kafka采用消费组保证了:一个Partition只允许被一个消费组中的一个消费者所消费,得出的结论是:在一个消费组中,一个消费者可以消费多个Partition,不同的消费者消费的Partition一定不会重复,所有消费者一起消费所有的Partition;在不同消费组中,每个消费组都会消费所有的Partition。也就是同一个消费组下消费者对Partition是互斥的,而不同消费组之间是共享的。比如有两个消费者订阅了一个topic,如果这两个消费者在不同的消费组中,则每个消费者都会获取到这个topic所有的记录;如果这两个消费者是在同一个消费组中,则它们会各自获取到一半的记录(两者的记录是对半分的,而且都是不重复的)。图4-3示例了多个消费者都在同一个消费组中(右图)或者各自组成一个消费组(左图)的不同消费场景,这样Kafka也可以实现传统消息队列的发布订阅模型和队列模型:
同一条消息会被多个消费组消费,如果有多个消费组,每个消费组只有一个消费者,实现广播(发布订阅模式)
只有一个消费组,这个消费组有多个消费者,一条消息只会被这个消费组的一个消费者所消费,实现单播(队列模式)
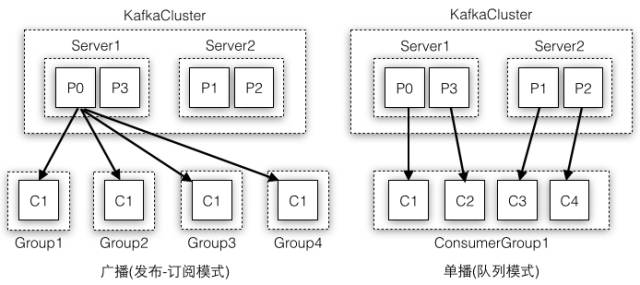
图4-3 传统消息队列的发布订阅模型和队列模型
实际应用中如图4-4消费者和消费组的组成通常是有多个消费组,并且每个消费组中也有多个消费组,这样既可以允许多种不同业务逻辑的消费组存在,也保证了同一个消费组内的多个消费者的协调工作,避免一个消费组只有一个消费者引起的数据丢失。
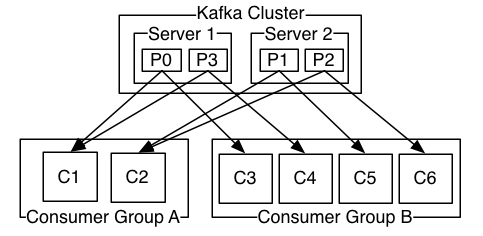
图4-4 Kafka集群的典型部署方式
图片引自:http://kafka.apache.org/documentation.html
Kafka使用消费组的概念,允许一组消费者进程对消费和读取记录的工作进行划分,每个消费者都可以配置一个所属的消费组并且订阅某些主题,Kafka会发送每条消息给每个消费组中的一个消费者线程(同一条消息广播给多个消费组,单播给同一组中的消费者),这是通过对每个消费组的所有消费者线程将订阅topic的所有partitions进行平衡负载rebalance,简单点说就是将topic的所有Partiti
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 6851
6851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











