







shuffle及Spark shuffle历史简介
shuffle,中文意译“洗牌”,是所有采用map-reduce思想的大数据计算框架的必经阶段,也是最重要的阶段。它处在map与reduce之间,又可以分为两个子阶段:
- shuffle write:map任务写上游计算产生的中间数据;
- shuffle read:reduce任务读map任务产生的中间数据,用于下游计算。
下图示出在Hadoop MapReduce框架中,shuffle发生的时机和细节。
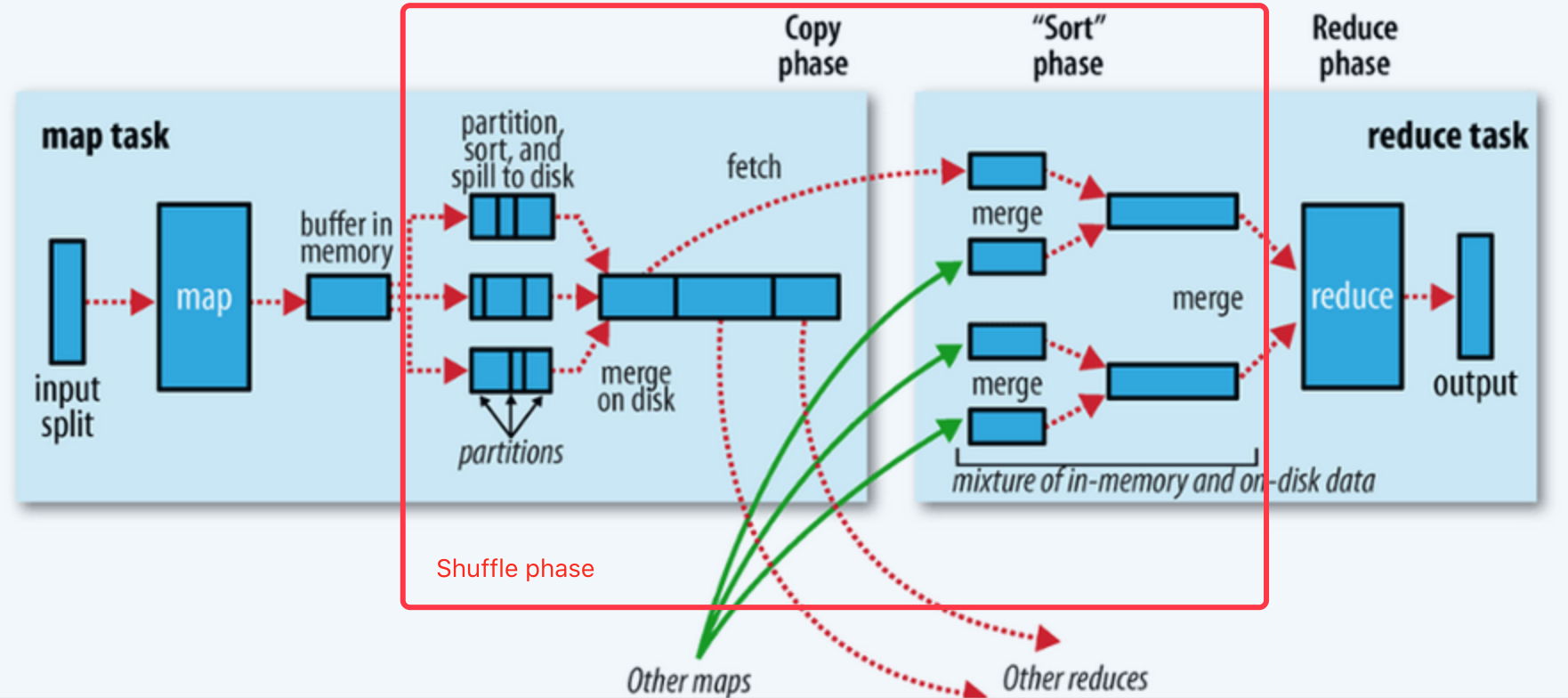
image
Spark的shuffle机制虽然也采用MR思想,但Spark是基于RDD进行计算的,实现方式与Hadoop有差异,并且中途经历了比较大的变动,简述如下:
- 在久远的Spark 0.8版本及之前,只有最简单的hash shuffle,后来引入了consolidation机制;
- 1.1版本新加入sort shuffle机制,但默认仍然使用hash shuffle;
- 1.2版本开始默认使用sort shuffle;
- 1.4版本引入了tungsten-sort shuffle,是基于普通sort shuffle创新的序列化shuffle方式;
- 1.6版本将tungsten-sort shuffle与sort shuffle合并,由Spark自动决定采用哪一种方式;
- 2.0版本之后,hash shuffle机制被删除,只保留sort shuffle机制至今。
下面的代码分析致力于对Spark shuffle先有一个大致的了解。
shuffle机制的最顶层:ShuffleManager特征
鉴于shuffle的重要性,shuffle机制的初始化在Spark执行环境初始化时就会进行。查看SparkEnv.create()方法:
val shortShuffleMgrNames = Map(
"sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName,
"tungsten-sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName)
val shuffleMgrName = conf.get("spark.shuffle.manager", "sort")
val shuffleMgrClass & 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 414
414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











