







在利用Spark开发各类计算任务时,Executor内存的配置永远是重中之重,因此了解Spark的内存管理机制是非常有益的。
在1.6版本之前,Spark只有一种内存管理机制,即静态内存管理(StaticMemoryManager),1.6版本以后又引入了新的统一内存管理(UnifiedMemoryManager)。下面分别来看一下这两种机制的细节。
静态内存管理
任何一个Spark Executor本质上都是一个JVM进程,因此我们使用spark.executor.memory参数指定的内存就是JVM堆的大小,叫做堆内(on-heap)内存。至于堆外(off-heap)内存不是这篇文章要讨论的。
下图示出在静态内存管理机制下的堆内内存分布。图中有一处遗漏,做了订正。
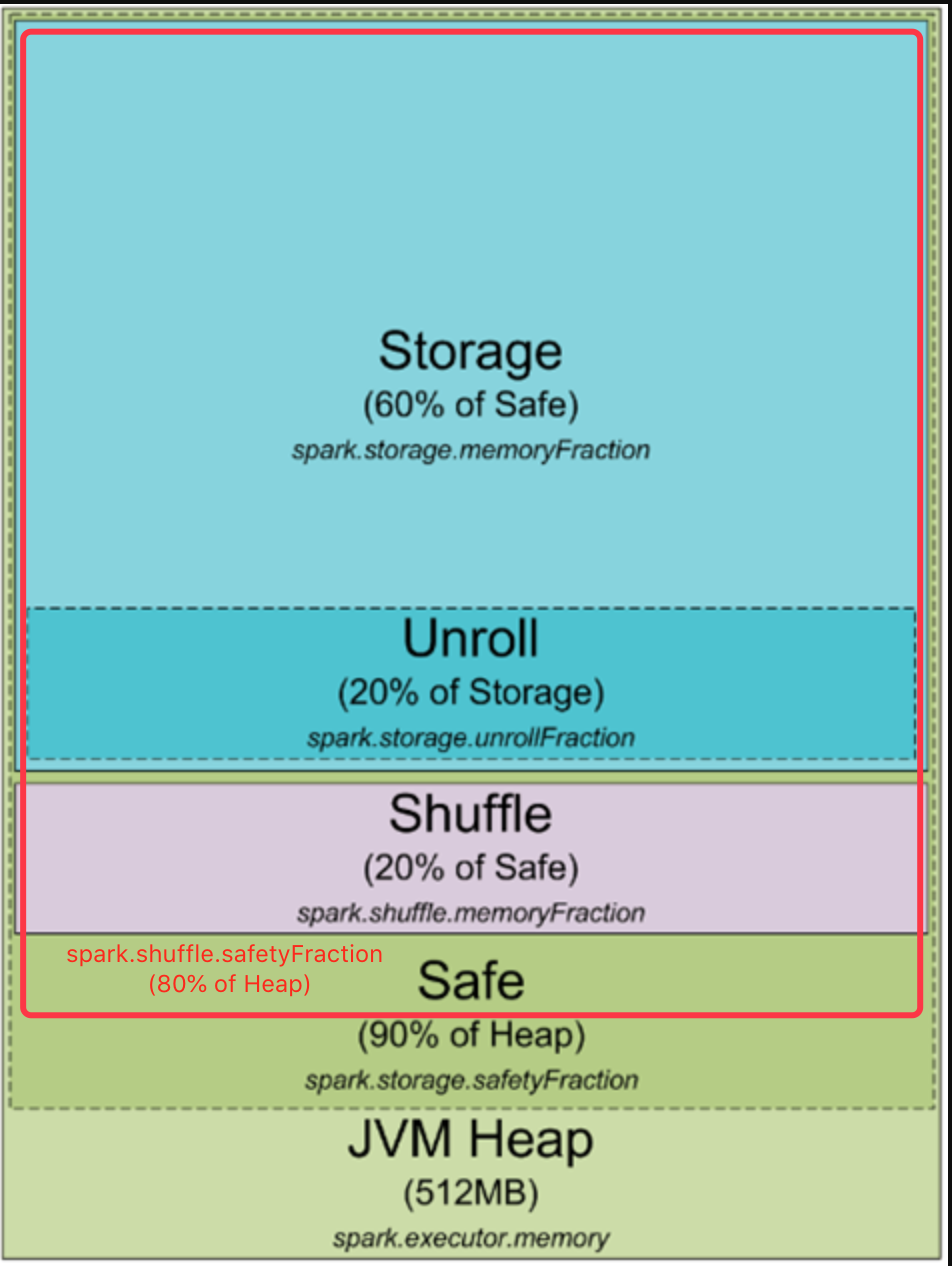
image
- JVM堆内存(Heap):由spark.executor.memory指定。如果不指定的话,默认会分配512MB,显然是很小的,所以推荐总是手动设定它。
- 安全(Safe)内存:为了最大限度地减少OOM,以及为用户代码的执行预留一定的内存,Spark设定了两个安全内存的阈值。由spark.storage.safetyFraction指定存储安全内存相对于JVM堆内存的比例,默认0.9,就是占堆内存的90%。Shuffle安全内存就是图中添加的那一部分,由spark.shuffle.safetyFraction指定比例,默认0.8。一般不要改。
- Shuffle内存:顾名思义,是专门供shuffle阶段使用的内存。不管HashShuffleManager还是SortShuffleManager都会产生中间数据,典型的就是排序数据。它由spark.shuffle.memoryFraction来指定相对于shuffle安全内存的比例,默认值0.2。如果shuffle阶段逻辑比较复杂的话,应该增大这个值。
- 存储(Storage)内存:专门用来存储数据的内存区域。在运算过程中读入的数据、广播变量等都会放在这里,如果对RDD显式调用cache()/persist()方法,也是缓存在这里。它由spark.storage.memoryFraction来指定相对于存储安全内存的比例,默认值0.6。如果数据量很大,或者经常需要缓存RDD,应该增大这个值。
- Unroll内存:所谓unroll就是我们常说的反序列化(deserialize)。Spark缓存的数据可能会有序列化的格式,必须反序列化后才能参与计算。它与storage内存共享区域,由spark.storage.unrollFraction来指定比例,默认值0.2。限定unroll内存的比例是为了防止反序列化对象过大,挤占过多storage内存,导致缓存的其他对象全部失效。
StaticMemoryManager类的源码非常简单,一目了然。下面的源码来自1.6版本。
/**
* A [[MemoryManager]] that statically partitions the heap space into disjoint regions.
*
* The sizes of the execution and storage regions are determined through
* `spark.shuffle.memoryFraction` and `spark.storage.memoryFraction` respectively. The two
* regions are cleanly separated such that neither usage can borrow memory from the other.
*/
private[spark] class StaticMemoryManager(
conf: SparkConf,
maxOnHeapExecutionMemory: Long,
override val maxStorageMemory: Long,
numCores: Int)
extends MemoryManager(
conf,
numCores,
maxStorageMemory,
maxOnHeapExecutionMemory) {
def this(conf: SparkConf, numCores: Int) {
this(
conf,
StaticMemoryManager.getMaxExecutionMemory(conf),
StaticMemoryManager.getMaxStorageMemory(conf),
numCores)
}
// Max number of bytes worth of blocks to evict when unrolling
private val maxUnrollMemory: Long = {
(maxStorageMemory * conf.getDouble("spark.storage.unrollFraction", 0.2)).toLong
}
override def acquireStorageMemory(
blockId: BlockId,
numBytes: Long,
evictedBlocks: mutable.Buffer[(BlockId, BlockStatus)]): Boolean = synchronized {
if (numBytes > maxStorageMemory) {
// Fail fast if the block simply won't fit
logInfo(s"Will not store $blockId as the required space ($numBytes bytes) exceeds our " +
s"memory limit ($maxStorageMemory bytes)")
false
} else {
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 499
499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











