






Soft-Actor-Critic一共有两个版本,笔者称为SAC1与SAC2,鉴于它是一个非常火爆好用的算法,笔者首先给出它的代码,网传版本有很多,但是存在诸多问题譬如:
1.算法不收敛
2.由于值网络的更新导致策略网络无法更新
3.SAC效果不好
这导致了网络上几乎没有一个代码可以同时的在三种机器人控制(游戏)环境:“BipedalWalker-v3”,“LunarLanderContinuous-v2”,"Pendulum-v1"上表现很好
笔者通过一周的试错和阅读了大量代码并总结了以下三点错误产生的原因,正是这些错误导致了网络上代码出现这样的效果,并汇聚了一个自己版本的SAC代码,(本篇更新SAC2代码),可以解决网络上代码未对齐的问题和效果差的问题,并附效果图。笔者还测试了其余环境,均可通过此代码获得良好效果。希望大家可以从本篇中得到收获,首先给予问题解决:
1.算法不收敛:
1⃣️、网络编写错误,请仔细检查是否网络存在细节小问题
2⃣️、learning-rate过高(3e-4)比较常见,target网络更新参数TAU过大(0.05或0.1)比较常见
3⃣️、方差clip范围过大,方差log取值在[-20,2]比较常见。
2.由于值网络的更新导致策略网络无法更新
1⃣️、一定要先算完所有的Loss再更新,而不是每计算一个loss更新一次。
2⃣️、(重点)Policy网络一定要更新在ValueNetwork和QNetwork的前面!
3.SAC效果不好:
1⃣️、(重点)先检查你的gym环境Reward是否差距过大:如"BipedalWalker-v3"这种环境奖励差距过大(因为机器人倒下Reward=-100,不倒下Reward都是一个[-1,1]的小值。若差距过大,需要进行Reward-scale,笔者亲测,这是一个主要原因而不是你算法写错了。
2⃣️、(重点)与网络层数和hidden-layer关系并不是很大(不是没有效果,但是不是关键原因),不要浪费时间调整,按照256-256-256即可,笔者亲测。
3⃣️、(重点)检查网络是否进行初始化。我看到了有些笔者和作者认为需要Batch-Norm和Layer-Norm,我认为无需它们,效果一样好,与他们关系不大,不信可以自行测试。
4⃣️、(重点)检查是否匹配了所对应环境的输出范围,因为正常Policy网络通过tanh输出后是一个[-1,1]的值,但有的环境输出动作范围并不是这样,你需要进行Distribution方差和均值的偏移。
下面各位可以按照顺序进行笔者代码的复制以验证效果。
1、SAC2代码(无需V网络,只需Alpha)
1.1、Reply-Buffer
import numpy as np
import random
from collections import deque
class Buffer:#Buffer the data from online/offline
def __init__(self,buffer_size):
self.buffer=deque(maxlen=buffer_size)
self.maxSize=buffer_size
self.len=0
def sample(self,count):
count=min(count, self.len)
batch=random.sample(self.buffer, count)
s_arr=np.float32([arr[0] for arr in batch])
a_arr=np.float32([arr[1] for arr in batch])
r_arr=np.float32([arr[2] for arr in batch])
s1_arr=np.float32([arr[3] for arr in batch])
d_arr=np.float32([arr[4] for arr in batch])
return s_arr, a_arr, r_arr, s1_arr, d_arr
def len(self):
return self.len
def add(self,s,a,r,s1,d1):
transition=(s,a,r,s1,d1)
self.len += 1
if self.len > self.maxSize:
self.len = self.maxSize
self.buffer.append(transition)
1.2、NLP层搭建(将其存储为NetworkLayer):
import torch
def weight_init(m):
if isinstance(m,torch.nn.Linear):
torch.nn.init.xavier_uniform_(m.weight,gain=1)
torch.nn.init.constant_(m.bias,0)
def mlplayer(input_dim,hidden_dim,output_dim,hidden_depth):#[256,256,128]
if (hidden_depth==0):#if layer is one depth.
mods=[torch.nn.Linear(input_dim,output_dim)]
else:# if layer is more than one depth.
mods=[torch.nn.Linear(input_dim,hidden_dim[0]),torch.nn.ReLU(inplace=True)]
for i in range(hidden_depth-1):
mods+=[torch.nn.Linear(hidden_dim[i],hidden_dim[i+1]),torch.nn.ReLU(inplace=True)]
mods.append(torch.nn.Linear(hidden_dim[-1],output_dim))
mlpstruct=torch.nn.Sequential(*mods)
return mlpstruct
"""
mlplayer(5,[3,4,3],2,3):
Sequential(
(0): Linear(in_features=5, out_features=3, bias=True)
(1): ReLU(inplace=True)
(2): Linear(in_features=3, out_features=4, bias=True)
(3): ReLU(inplace=True)
(4): Linear(in_features=4, out_features=3, bias=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=3, out_features=2, bias=True)
)
"""
1.3、ActorNetwork和CriticNetwork(分别存储为Actor.py和Critic.py):
import torch
from NetworkLayer import mlplayer
from NetworkLayer import weight_init
device=torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
class Actor(torch.nn.Module):
def __init__(self,obs_dim,action_dim,hidden_dim,hidden_depth,log_std_bounds,
action_space):
super().__init__()
self.log_std_bounds=log_std_bounds #[logmin,logmax]
self.layer=mlplayer(obs_dim,hidden_dim,2*action_dim,hidden_depth)
self.apply(weight_init)
###Given this action fit the gym env.action.high and low
if(action_space is None):
self.action_scale=torch.tensor(1.0).to(device)
self.action_bias=torch.tensor(0.0).to(device)
else:
self.action_scale=torch.FloatTensor(
(action_space.high-action_space.low)/2.0).to(device)
self.action_bias=torch.FloatTensor(
(action_space.high+action_space.low)/2.0).to(device)
def forward(self,obs):
obs=obs.to(device)#[Batch_size*obs_dim]
mu,log_std=self.layer(obs).chunk(2,dim=-1)#cut it to two pieces: mu and log
log_std_min,log_std_max=self.log_std_bounds
log_std=torch.clamp(log_std,log_std_min,log_std_max)
return mu,log_std
def sample(self,obs,epsilon=1e-6):
obs=obs.to(device)
mu,log_std=self.forward(obs)
std=log_std.exp()#set it to std.
Distrubtion=torch.distributions.Normal(mu,std)
example=Distrubtion.rsample()
action=torch.tanh(example)#[Ouput-action]
log_prob=Distrubtion.log_prob(example)
log_prob=log_prob-torch.log(self.action_scale*(1-action.pow(2))+epsilon)
log_prob=log_prob.sum(1,keepdim=True)#log(\pi(a|s))and $a$
mu=torch.tanh(mu)*self.action_scale+self.action_bias
return action,log_prob,mu #[Batch*1],[Batch*1]
class Critic(torch.nn.Module):
def __init__(self,obs_dim,action_dim,hidden_dim,hidden_depth):
super().__init__()
self.Q=mlplayer(obs_dim+action_dim,hidden_dim,1,hidden_depth)
self.apply(weight_init)
def forward(self,obs,action):
obs=obs.to(device)
action=action.to(device)
obs_action=torch.cat([obs,action],dim=1)
q=self.Q(obs_action)
return q
class Vnetwork(torch.nn.Module):
def __init__(self,obs_dim,hidden_dim,hidden_depth):
super().__init__()
self.V=mlplayer(obs_dim,hidden_dim,1,hidden_depth)
self.apply(weight_init)
def forward(self,obs):
obs=obs.to(device)
v=self.V(obs)
return v
1.4、SAC-Network(原理请见笔者后续介绍):
import torch
from Critic import Critic,Vnetwork
from Actor import Actor
device=torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
LEARNING_RATE=3e-4
BATCH_SIZE=128
GAMMA=0.99
TAU=0.005
epsilon=1e-6
class SAC1:
def __init__(self,obs_dim,action_dim,hidden_dim,hidden_depth,
log_std_bounds,ram,action_space,alpha):
self.action_space=action_space
self.obs_dim=obs_dim
self.action_dim=action_dim
self.hidden_dim=hidden_dim
self.hidden_depth=hidden_depth
self.log_std_bounds=log_std_bounds
self.ram=ram
self.alpha=alpha
###Double Q-Learning or you like to use only one Q.It is also OK!
self.Q1=Critic(self.obs_dim,self.action_dim,self.hidden_dim,self.hidden_depth)
self.Q2=Critic(self.obs_dim,self.action_dim,self.hidden_dim,self.hidden_depth)
self.Q1_optimizer=torch.optim.Adam(self.Q1.parameters(),LEARNING_RATE)
self.Q2_optimizer=torch.optim.Adam(self.Q2.parameters(),LEARNING_RATE)
self.TQ1=Critic(self.obs_dim,self.action_dim,self.hidden_dim,self.hidden_depth)
self.TQ2=Critic(self.obs_dim,self.action_dim,self.hidden_dim,self.hidden_depth)
self.hard_update(self.TQ1, self.Q1)
self.hard_update(self.TQ2, self.Q2)
self.Q1loss=torch.nn.MSELoss()
self.Q2loss=torch.nn.MSELoss()
###preparing to update alpha.
self.target_entropy=-torch.prod(torch.Tensor(action_space.shape).to(device)).item()
self.log_alpha=torch.zeros(1,requires_grad=True,device=device)
self.alpha_optim=torch.optim.Adam([self.log_alpha],LEARNING_RATE)
###Policy Network
self.P=Actor(self.obs_dim,self.action_dim,self.hidden_dim,self.hidden_depth,
self.log_std_bounds,self.action_space)
self.P_optimizer=torch.optim.Adam(self.P.parameters(),LEARNING_RATE)
self.Q1=self.Q1.to(device)
self.Q2=self.Q2.to(device)
self.TQ1=self.TQ1.to(device)
self.TQ2=self.TQ2.to(device)
self.P=self.P.to(device)
def soft_update(self,target,source,tau):
for target_param, param in zip(target.parameters(),source.parameters()):
target_param.data.copy_(target_param.data*(1.0-tau)+param.data*tau
)
def hard_update(self,target,source):
for target_param,param in zip(target.parameters(),source.parameters()):
target_param.data.copy_(param.data)
def select_action(self,state,eval=False):
state=torch.FloatTensor(state).to(device).unsqueeze(0)
if eval == False:
action, _, _=self.P.sample(state)
else:
_, _, action=self.P.sample(state)
return action.detach().cpu().numpy()[0]
def update_parameters(self):
s1,a1,r1,s2,d1=self.ram.sample(BATCH_SIZE)
s1 = torch.autograd.Variable(torch.from_numpy(s1))
a1 = torch.autograd.Variable(torch.from_numpy(a1))
r1 = torch.autograd.Variable(torch.from_numpy(r1))
s2 = torch.autograd.Variable(torch.from_numpy(s2))
d1 = torch.autograd.Variable(torch.from_numpy(d1))
r1 = torch.reshape(r1,[BATCH_SIZE,1]).to(device)
d1 = torch.reshape(d1,[BATCH_SIZE,1]).to(device)
with torch.no_grad():
next_state_action,next_state_log_pi,_=self.P.sample(s2)
qf1_next_target=self.TQ1(s2,next_state_action)
qf2_next_target=self.TQ2(s2,next_state_action)
min_qf_next_target=torch.min(qf1_next_target,qf2_next_target)\
-self.alpha*next_state_log_pi
next_q_value=r1+(1-d1)*GAMMA*(min_qf_next_target)
qf1=self.Q1(s1,a1)
qf2=self.Q2(s1,a1)
qf1_loss=self.Q1loss(qf1,next_q_value)
qf2_loss=self.Q2loss(qf2,next_q_value)
pi,log_pi,_=self.P.sample(s1)
qf1_pi=self.Q1(s1,pi)
qf2_pi=self.Q2(s1,pi)
min_qf_pi=torch.min(qf1_pi,qf2_pi)
policy_loss=((self.alpha*log_pi)-min_qf_pi).mean()
alpha_loss=-(self.log_alpha*(log_pi+self.target_entropy).detach()).mean()
#upgrade:
self.P_optimizer.zero_grad()
policy_loss.backward()
self.P_optimizer.step()
self.Q1_optimizer.zero_grad()
qf1_loss.backward()
self.Q1_optimizer.step()
self.Q2_optimizer.zero_grad()
qf2_loss.backward()
self.Q2_optimizer.step()
self.alpha_optim.zero_grad()
alpha_loss.backward()
self.alpha_optim.step()
self.alpha=self.log_alpha.exp()
self.soft_update(self.TQ1,self.Q1,TAU)
self.soft_update(self.TQ2,self.Q2,TAU)
1.5、TrainingSAC:
##These two lines is my macbook error.
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'
import gym
import gc
import numpy as np
from Soft_ActorCritic import SAC1#in Section 1.4
from Buffer import Buffer# in Section 1.1
import pandas as pd
from matplotlib import pyplot as plt
alpha=0.036
env=(gym.make('Pendulum-v1'))#or other two envs you can try!
MAX_EPISODES = 20000
MAX_STEPS = 1000
MAX_BUFFER = 1000000
S_DIM = env.observation_space.shape[0]
A_DIM = env.action_space.shape[0]
A_MAX = env.action_space.high[0]
ram = Buffer(MAX_BUFFER)
HID=[256,256,256]
LOG_SIG_MAX=2#max_log
LOG_SIG_MIN=-20#min_log
trainer=SAC1(S_DIM,A_DIM,HID,3,[LOG_SIG_MIN,LOG_SIG_MAX],ram,env.action_space,alpha)
max_reward=-1000000
pic=[]
for _ep in range(MAX_EPISODES):
observation=env.reset()
done=False
sum_reward=0
state = observation[0]
step=0
while not done:
action=trainer.select_action(state,False)##Training.
new_state,reward,done,info,k=env.step(action)
###Warning:These three lines is only fit for BipedalWalker-v3 to scale it reward!!!!!!!
"""
if(reward==-100):
reward=-1
reward=reward*10
"""
sum_reward=sum_reward+reward
ram.add(state,action,reward,new_state,done)
state = new_state
if(ram.len>1000):
trainer.update_parameters()
step=step+1
if(step>MAX_STEPS):
break
if(_ep%10==0):
observation=env.reset()
done=False
sum_reward_test=0
state=observation[0]
step = 0
while not done:
action=trainer.select_action(state,False)##Testing
new_state,reward,done,info,k=env.step(action)
sum_reward_test=sum_reward_test+reward
state = new_state
step = step + 1
if (step > MAX_STEPS):
break
print("episode:",_ep, sum_reward,sum_reward_test)
pic.append(sum_reward_test)
plt.plot(pic)
plt.savefig("Result.jpg")
data1=pd.DataFrame([pic])
data1.to_csv("Reward_res.csv")
gc.collect()
2、SAC2结果展示(三个环境下的结果)
训练时建议用GPU来跑,笔者采用了三种GPU进行测试,具体时间如下,不建议使用CPU训练,使用CPU训练请把step调低:(当然笔者写的代码对GPU利用率也不高…当作练习程序吧)
1.A100/4090需要1.5~2小时可以训练结束(三种环境,1000step)
2.3090需要3.5~4小时可以训练结束(三种环境,1000step)
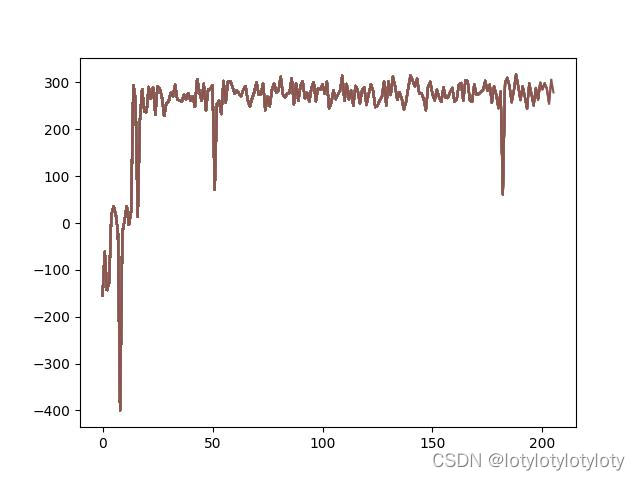
2.1、LunarLanderContinuous-v2(控制飞行器平稳降落训练epoch-Reward曲线变化):
可以发现在1000step下能够达到300+Reward的效果。
2.2、BipedalWalker-v3(控制机器人走路通关到达终点训练epoch-Reward曲线变化):
(想要收敛很容易,往后稍微调小一些lr即可,笔者只展现效果)
可以发现在1000step下也能够达到300+Reward的效果
(如果不进行Reward-scale那么效果将极差,大概在Reward=15~28左右的样子即无法继续学习信息了,有兴趣的读者可以为笔者解答这个疑问为什么会出现这样的效果),鉴于时间原因,笔者在未收敛前就展示了出来。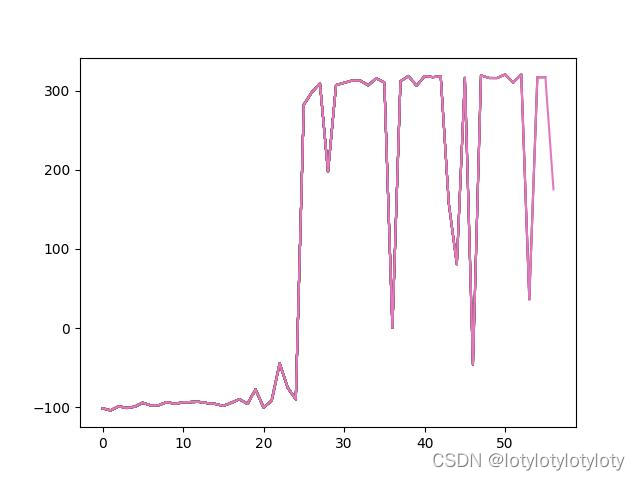
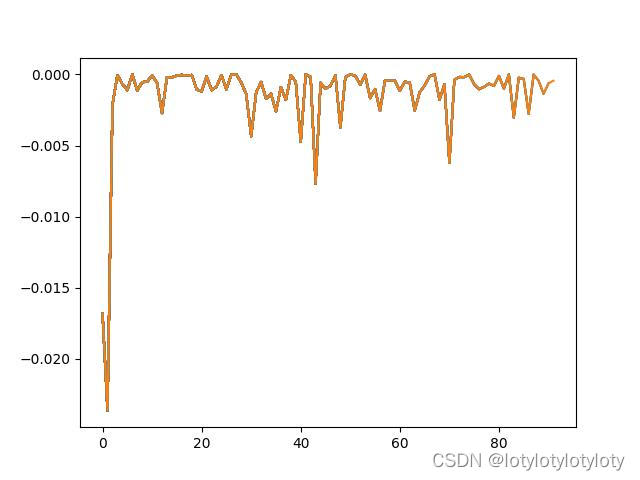
2.3、Pendulum-v1(控制一个杆子在满足一定动力学方程下保持稳定不倒下的状态的训练epoch-Reward曲线变化):
不同于其他两个,这个最大的累积Reward就是0


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









