






目 录
第二章——预备知识
1 前 言
机器学习需要处理大型数据集,然后可以将数据集视为一个表,类似于数据库的关系表,行对应样本,列对应属性。我们将会使用线性代数处理表格数据,因此重点就会落在矩阵运算的基本原理及其实现。
2 数据操作
简单来说数据操作可以分俩步:获取数据 + 将数据读入计算机并进行处理
在学习torch时,首先需要了解张量(tensor)也就是n维数组。之所以选择使用张量,是因为虽然张量类与numpy的ndarry类似,但numpy仅支持支持CPU计算,不能利用到GPU的支持加速运算能力。 其次,张量类支持自动微分
2.1 入门
Pytorch也就是Python + torch;因此在代码中使用的是torch
张量表示一个由数值组成的数组,这个数组可能有多个维度。 具有一个轴的张量对应数学上的向量; 具有两个轴的张量对应数学上的矩阵
(1)arange默认创建一个行向量x,这个行向量包含以0开始的前6个整数,它们默认创建为整数。也可指定创建类型为浮点数,建议使用浮点数,否则后面有些运算可能会出现一些问题。张量中的每个值都称为张量的元素。x = torch.arange(6) x实际上就是:tensor([ 0, 1, 2, 3, 4, 5])
(2)shape属性来访问张量的形状x.shape 结果为:torch.Size([6]) 代表单个轴有6个元素
(3)改变张量的形状,可以调用
reshape函数。 例如,可以设置x从形状为(6)的行向量转换为形状为(3,2)的矩阵。 形状发生了改变,元素值不变。X = x.reshape(3, 2)
(4)如果希望使用全0、全1、其他常量,或者从特定分布中随机采样的数字来初始化矩阵
全0:torch.zeros((2, 3, 4))
全1:torch.ones((2, 3, 4))
(5)随机采样来得到张量中每个元素的值
torch.randn(3, 4)
(6)连接:torch.cat((X,Y), dim=0)
X,Y是矩阵为例,dim=0就是按行,dim=1就是按列连接
2.2 运算
加减乘幂不过多介绍,很多运算可以参考之前写过的这篇:动手学习深度学习--torch 实现乘法计算向量、计算矩阵、张量乘法、对位相乘、axis的用法-CSDN博客
2.3 内存分配
在张量中的一些操作可能会导致为新结果分配内存,这样就会很浪费,不推荐。
例如,如果我们用Y=X+Y,我们将取消引用Y指向的张量,而是指向新分配的内存处的张量。
替代方案:如果在后续计算中没有重复使用X, 我们也可以使用X[:]=X+Y或X+=Y来减少操作的内存开销。
理解:第一种操作可以理解为分配一个新的矩阵,然后将X和Y的每一个对应的数据相加之后放入新矩阵,然后Y再重新指向这个新矩阵。第二种操作就是取出矩阵的一个数据与对应的Y的数据相加之后替换矩阵X的值,因此不会重新进行分配内存。
2.4 张量与其他Python对象的相互转化
假设:a = torch.tensor([3.5])
a:tensor([3.5000])
a.item():3.5
float(a):3.5
int(a):3
3 数据预处理
NAN代表缺失值,处理缺失的数据项的典型方法包括插值法和删除法;插值法用一个替代值弥补缺失值,而删除法则直接忽略缺失值。这里需要用到pandas包,作为Python常用的数据分析工具,pandas可以与张量兼容
位置索引 iloc 可以将数据集分成多列,具体处理参考书本:2.2. 数据预处理 — 动手学深度学习 2.0.0 documentation
4 向量与矩阵
4.1 向量
向量可以被视为标量值组成的列表。与普通的Python数组一样,我们可以通过调用Python的内置len()函数来访问张量的长度。向量或轴的维度被用来表示向量或轴的长度,即向量或轴的元素数量。 然而,张量的维度用来表示张量具有的轴数。
4.2 矩阵
向量将标量从零阶推广到一阶,矩阵将向量从一阶推广到二阶。
当调用函数来实例化张量时, 我们可以通过指定两个分量m和n来创建一个形状为m×n的矩阵。
A = torch.arange(20).reshape(5, 4)就形成了一个5*4的矩阵
矩阵A的转置:A.T
相关运算:动手学习深度学习--torch 实现乘法计算向量、计算矩阵、张量乘法、对位相乘、axis的用法-CSDN博客
4.3 范数
线性代数中最有用的一些运算符是范数(norm)。 非正式地说,向量的范数是表示一个向量有多大。 这里考虑的大小概念不涉及维度,而是分量的大小。
简单理解就是范数就是一个向量的长度,等于各个分量平方和的平方根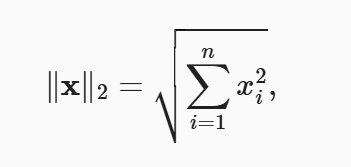
4.4 小结
标量、向量、矩阵和张量是线性代数中的基本数学对象。
向量泛化自标量,矩阵泛化自向量。
标量、向量、矩阵和张量分别具有零、一、二和任意数量的轴。
一个张量可以通过sum和mean沿指定的轴降低维度。
两个矩阵的按元素乘法被称为他们的Hadamard积,它与矩阵乘法不同。
在深度学习中,我们经常使用范数,如L1范数、L2范数和Frobenius范数。
我们可以对标量、向量、矩阵和张量执行各种操作。
5 微积分
在深度学习中,我们训练模型,不断更新它们,使它们在看到越来越多的数据时变得越来越好。 通常情况下,变得更好意味着最小化一个损失函数。 最终,我们真正关心的是生成一个模型,它能够在从未见过的数据上表现良好。 但训练模型只能将模型与我们实际能看到的数据相拟合。 因此,我们可以将拟合模型的任务分解为两个关键问题:
优化:用模型拟合观测数据的过程;
泛化:数学原理和实践者的智慧,能够指导我们生成出有效性超出用于训练的数据集本身的模型。
6 自动微分
深度学习框架通过自动计算导数,即自动微分来加快求导。 实际中,根据设计好的模型,系统会构建一个计算图, 来跟踪计算是哪些数据通过哪些操作组合起来产生输出。 自动微分使系统能够随后反向传播梯度。 这里,反向传播意味着跟踪整个计算图,填充关于每个参数的偏导数。
6.1 梯度
计算y关于x的梯度之前,需要一个地方来存储梯度。 重要的是,我们不会在每次对一个参数求导时都分配新的内存。 因为我们经常会成千上万次地更新相同的参数,每次都分配新的内存可能很快就会将内存耗尽。
x = torch.arange(4.0)
x.requires_grad_(True)等价于x=torch.arange(4.0,requires_grad=True)
这里的x是tensor([0., 1., 2., 3.]) 梯度的默认值是none
y = 2 * torch.dot(x, x)y 就是 tensor(28., grad_fn=<MulBackward0>)
x是一个长度为4的向量,计算x和x的点积,得到了我们赋值给y的标量输出。 接下来,通过调用反向传播函数来自动计算y关于x每个分量的梯度,并打印这些梯度。
y.backward()x.grad 就是 tensor([ 0., 4., 8., 12.])
在默认情况下,PyTorch会累积梯度,我们需要清除之前的值
x.grad.zero_()
y = x.sum()
y.backward()此时再求 x.grad 是tensor([1., 1., 1., 1.])
理解:对于第一个可以理解为 y=2*x^2 然后求梯度就是反向传播(求导)结果为4x,这时你可以进行判断 x.grad==4x,结果是 tensor([true,true,true,true]) 这样的一个张量
小结:
深度学习框架可以自动计算导数:我们首先将梯度附加到想要对其计算偏导数的变量上,然后记录目标值的计算,执行它的反向传播函数,并访问得到的梯度。
6.2 练习
(1)在运行反向传播函数之后,立即再次运行它,看看会发生什么。
会报错Runtime Error:因为计算运算的时候,中间的结果会被释放,导致超时报错
(2)在控制流的例子中,我们计算d关于a的导数,如果将变量a更改为随机向量或矩阵,会发生什么?
也会报错:因为grad只能隐式的为标量创建输出,上述中的y计算结果为标量,因此x可以调用grad
7 结 语
参考链接:2. 预备知识 — 动手学深度学习 2.0.0 documentation
学习链接:【视频+教材】原著大佬李沐带你读《动手学习深度学习》真的通俗易懂!深度学习入门必看!(人工智能、机器学习、神经网络、计算机视觉、图像处理、AI)_哔哩哔哩_bilibili
如果你有任何建议或疑问,欢迎留言讨论,最近每天基本上都会看留言,看到会及时回复。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









