






目 录
第三章 ——— 线性神经网络
章节导航:在介绍深度神经网络之前,我们需要在本章了解神经网络的基础知识。经典统计学习技术中的线性回归和softmax回归可以视为线性神经网络,本章将会以此为基础进行学习。
1 线性回归
回归是是能为一个或多个自变量与因变量之间关系建模的一类方法。 在自然科学和社会科学领域,回归经常用来表示输入和输出之间的关系。
在机器学习领域中的大多数任务通常都与预测有关。
1.1 线性回归基本知识
1.1.1 线性回归基本元素
为了解释线性回归,书中举了一个实际的例子:根据房屋的面积和房龄来估算房屋价格。 为了开发一个能预测房价的模型,我们需要收集一个真实的数据集。 这个数据集包括了房屋的销售价格、面积和房龄。
相对应的,在机器学习的术语中
数据集:训练数据集或训练集
每行数据:称为样本,也可以称为数据点或数据样本
试图预测的目标(如房屋价格):称为标签(label)或目标(target)
预测所依据的自变量(面积和房龄):称为特征(feature)或协变量(covariate)
1.1.2 线性模型
线性假设:目标(房屋价格)可以表示为特征(面积和房龄)的加权和
其中
- warea和wage 称为权重:决定了每个特征对我们预测值的影响
- b:称为偏置、偏移量或截距
给定一个数据集,我们的目标是寻找模型的权重w和偏置b, 使得根据模型做出的预测大体符合数据里的真实价格。
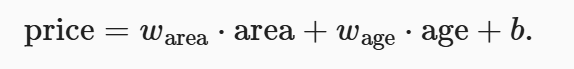
假设现有很多个房子(样本),将每一个房子的area和age作为样本乘以对应的权重加上偏置量就是该房子的价格。那我们就考虑运用线性代数的知识:
- 各个属性的权重:单独提取成一个列向量w
- 单个房子的多个特征作为一个行向量
- 多个房子就组成了一个矩阵X
所以就可以得到下列的式子,其中y是一个列向量,代表每一个房子的价格
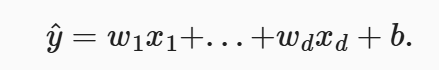
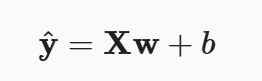
1.1.3 损失函数
损失函数能够量化目标的实际值与预测值之间的差距。 我们一般采用平方误差函数作为损失函数,其中y代表真实值,y^代表模型的预测值:
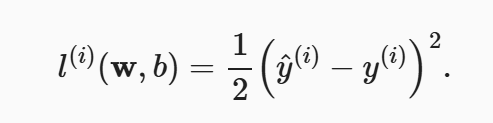
1.1.4 解析解
首先,我们将偏置b合并到参数w中,合并方法是在包含所有参数的矩阵中附加一列。 我们的预测问题是最小化‖y−Xw‖^2。 这在损失平面上只有一个临界点,这个临界点对应于整个区域的损失极小点。 将损失关于w的导数设为0,得到解析解(可以通过自己动手算出来,比较简单):
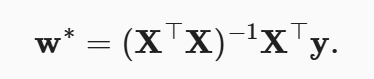
1.1.5 梯度下降
梯度下降最简单的用法是计算损失函数(数据集中所有样本的损失均值) 关于模型参数的导数(在这里也可以称为梯度)。 但实际中的执行可能会非常慢:因为在每一次更新参数之前,我们必须遍历整个数据集。 因此,我们通常会在每次需要计算更新的时候随机抽取一小批样本, 这种变体叫做小批量随机梯度下降,通过如下公式进行更新w,b
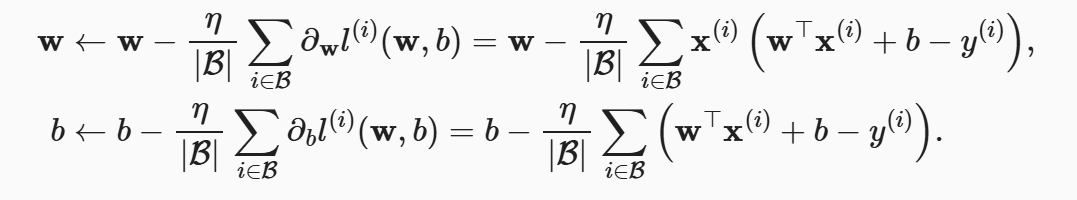
- |B|:表示每个小批量中的样本数,这也称为批量大小(batch size)
- η:表示学习率
批量大小和学习率的值通常是手动预先指定,而不是通过模型训练得到的。 这些可以调整但不在训练过程中更新的参数称为超参数。调参是选择超参数的过程。 超参数通常是我们根据训练迭代结果来调整的, 而训练迭代结果是在独立的验证数据集上评估得到的。在上述过程中我们就是不断调整w和b。
1.1.6 正态分布
正态分布想必大家并不陌生,如果有遗忘或者想重新了解可以参考:3.1. 线性回归 — 动手学深度学习 2.0.0 documentation
1.2 向量化加速
在训练我们的模型时,我们经常希望能够同时处理整个小批量的样本。 为了实现这一点,需要我们对计算进行矢量化, 从而利用线性代数库,而不是编写开销高昂的for循环。
书中这样进行证明的,制作一个定时器。在数据开始之前记下一个时间,然后采取俩种方式进行读取数据:使用For循环;使用重载的+运算符。在运算结束后计算所消耗的时间并打印出来,结果显示for循环的开销很大。因此:矢量化代码通常会带来数量级的加速。 另外,我们将更多的数学运算放到库中,而无须自己编写那么多的计算,从而减少了出错的可能性。
1.3 从线性回归到深度网络
我们将线性回归模型描述为一个神经网络。 需要注意的是,该图只显示连接模式,即只显示每个输入如何连接到输出,隐去了权重和偏置的值。
- 输入:x1,…,xd, 因此输入层中的输入数或称特征维度为d
- 输出:网络的输出为o1,因此输出层中的输出数是1
- 每个输入都与每个输出相连, 我们将这种变换 称为全连接层或称为稠密层
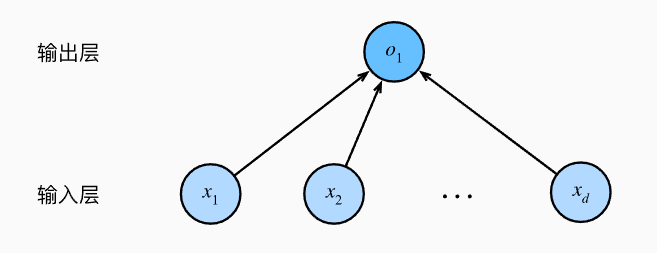
因为输入值都是已经给定的,并且只有一个计算神经元。 由于模型重点在发生计算的地方,所以通常我们在计算层数时不考虑输入层。 也就是说,上图中神经网络层数为1。 我们可以将线性回归模型视为仅由单个人工神经元组成的神经网络,或称为单层神经网络。
Question:什么时候可能比使用随机梯度下降更好?这种方法何时会失效?
Anwser:当解析解不存在或者太麻烦的时候就采用反向传播梯度下降,有时对于w的最大似然估计就是平方误差的解析解。
1.4 线性回归从0开始实现
代码内容较多,可以去笔记实现,也可参考:3.2. 线性回归的从零开始实现 — 动手学深度学习 2.0.0 documentation
Question:尝试使用不同的学习率,观察损失函数值下降的快慢。
Anwser:可以得到结论如下:
- 正常情况下,学习率大一点,损失函数的值就小一点
- 学习率太大,导致在最优解附近震荡,甚至会发散
- 学习率太小,下降的太慢
- 极端情况下,学习率极大,无法训练,梯度爆炸
- 一般建议在e^-5 ~ e^-1
1.5 线性回归的简洁实现
1.5.1 知识总结
包含步骤:生成数据集、读取数据集、定义模型、初始化模型参数、定义损失函数、定义优化算法、训练
对于标准深度学习模型,我们可以使用框架的预定义好的层。这使我们只需关注使用哪些层来构造模型,而不必关注层的实现细节。也许在后面的使用中,我们就可以只需要在相应的层中使用对应框架模型就可以。
1.5.2 函数使用
使用
iter构造Python迭代器,并使用next从迭代器中获取第一项next(iter(data_iter))
net[0]选择网络中的第一个图层, 然后使用weight.data和bias.data方法访问参数,使用替换方法normal_和fill_来重写参数值net[0].weight.data.normal_(0, 0.01) net[0].bias.data.fill_(0)计算均方误差使用的是
MSELoss类,也称为平方L2范数。 默认情况下,它返回所有样本损失的平均值,这里的nn代表神经网络(是从torch中导入的,from torch import nn)loss = nn.MSELoss()PyTorch在
optim模块实现了该算法的许多变种。 实例化一个SGD实例时,我们要指定优化的参数 (可通过net.parameters()从我们的模型中获得)以及优化算法所需的超参数字典。lr值设置为0.03。
1.5.3 简单练习
Question:如果将小批量的总损失替换为小批量损失的平均值,需要如何更改学习率?
Anwser:对比总损失来说,平均值意味着缩小了损失函数总损失的系数,这样就会要求学习率的调整变得更加细微才可以。
1.5.4 本节链接
3.3. 线性回归的简洁实现 — 动手学深度学习 2.0.0 documentation
1.6 小结
机器学习模型中的关键要素是训练数据、损失函数、优化算法,还有模型本身。
矢量化使数学表达上更简洁,同时运行的更快。
最小化目标函数和执行极大似然估计等价。
线性回归模型也是一个简单的神经网络。
深度网络实现和优化的一过程中只使用张量和自动微分,不需要定义层或复杂的优化器。
可以使用PyTorch的高级API更简洁地实现模型。
在PyTorch中,data模块提供了数据处理工具,
nn模块定义了大量的神经网络层和常见损失函数。我们可以通过
_结尾的方法将参数替换,从而初始化参数。
2 softmax回归
2.1 分类问题
从一个图像分类问题开始。 假设每次输入是一个2×2的灰度图像。 我们可以用一个标量表示每个像素值,每个图像对应四个特征x1,x2,x3,x4。 此外,假设每个图像属于类别“猫”“鸡”和“狗”中的一个。
书中介绍了一种表示分类数据的简单方法:独热编码。 独热编码是一个向量,它的分量和类别一样多。 类别对应的分量设置为1,其他所有分量设置为0。 在我们的例子中,标签y将是一个三维向量, 其中(1,0,0)对应于“猫”、(0,1,0)对应于“鸡”、(0,0,1)对应于“狗”。
可以这样进行理解:
- 标签向量的维数取决于有多少个目标类别,猫、鸡、狗三个类别就代表是三维向量
- 每个向量的值代表取该类的概率
2.2 网络架构
书中为解决线性模型的分类问题,需要和输出一样多的仿射函数,每个输出都有对应于它自己的仿射函数。
- 由于有4个特征和3个输出类别,因此需要12个标量来表示权重(带下标的w)
- 3个标量来表示偏置(带下标的b)
- 为每个输入计算三个未规范化的预测:o1、o2和o3
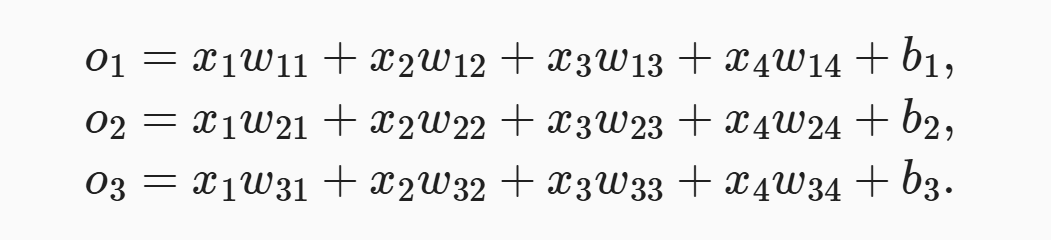
与线性回归一样,softmax回归也是一个单层神经网络。 由于计算每个输出o1、o2和o3取决于 所有输入x1、x2、x3和x4, 所以softmax回归的输出层也是全连接层。
全连接层的参数开销:对于任何具有d个输入和q个输出的全连接层, 参数开销为O(dq),这个数字在实践中可能高得令人望而却步。 幸运的是,将d个输入转换为q个输出的成本可以减少到O(dq/n), 其中超参数n可以由我们灵活指定。
2.3 softmax运算
现在我们需要将预测的o直视为概率输出,所以需要解决2个问题:概率值输出总和为1,概率非负值。
- 概率值输出总和为1:可以理解为向量的归一化
- 概率值非负:采用取指数的方法
softmax函数能够将未规范化的预测变换为非负数并且总和为1,同时让模型保持可导的性质。
尽管softmax是一个非线性函数,但softmax回归的输出仍然由输入特征的仿射变换决定。 因此,softmax回归是一个线性模型。

2.3.1 小批量样本的矢量化
假设读取了一个批量的样本X, 其中特征维度为d,批量大小为n,输出中有q个类别。
则小批量样本的特征为X∈R(n×d), 权重为W∈R(d×q), 偏置为b∈R(1×q)。
softmax回归的矢量计算表达式为:
由于X中的每一行代表一个数据样本, 那么softmax运算可以按行执行: 对于O的每一行,我们先对所有项进行幂运算,然后通过求和对它们进行标准化。
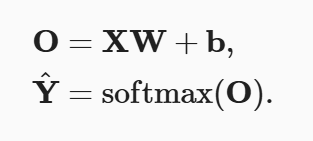
2.3.2 对数似然
softmax函数给出了一个向量y^, 我们可以将其视为对给定任意输入x的每个类的条件概率
根据最大似然估计,我们最大化P(Y∣X),相当于最小化负对数似然
对于任何标签y和模型预测y^,损失函数为:
上述的损失函数通常被称为交叉熵损失。 由于y是一个长度为q的独热编码向量, 所以除了一个项以外的所有项j都消失了。 由于所有y^j都是预测的概率,所以它们的对数永远不会大于0。
理解:对于一个样本,肯定有具体的分类,所以实际的y只有一个值为1,其余的概率均为0;而y^一定是小于等于1的,因此他们的对数永远不会>0。
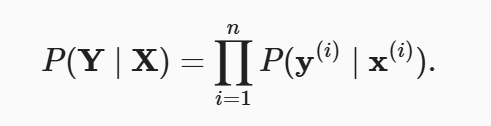
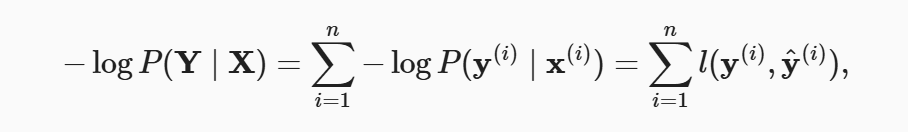
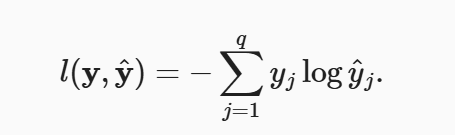
2.3.3 softmax及其导数
将图3.4.3代入损失3.4.8中。 利用softmax的定义,可以得到:
其中 3.4.9 的理解:在真实的y中,只有一个是1,其他为0时,所以在下图第二个式子中将y^的下标换成了概率为1的那个y值


2.4 softmax回归的简洁实现
继续通过深度学习框架的高级API能够使实现
2.4.1 图像分类数据集
MNIST数据集是图像分类中广泛使用的数据集之一,但作为基准数据集过于简单。 我们将使用类似但更复杂的Fashion-MNIST数据集。
%matplotlib inline import torch import torchvision from torch.utils import data from torchvision import transforms from d2l import torch as d2l d2l.use_svg_display()1)读取数据集
# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式, # 并除以255使得所有像素的数值均在0~1之间 trans = transforms.ToTensor() mnist_train = torchvision.datasets.FashionMNIST( root="../data", train=True, transform=trans, download=True) mnist_test = torchvision.datasets.FashionMNIST( root="../data", train=False, transform=trans, download=True)Fashion-MNIST由10个类别的图像组成, 每个类别由训练数据集(train dataset)中的6000张图像 和测试数据集(test dataset)中的1000张图像组成。 因此,训练集和测试集分别包含60000和10000张图像。 测试数据集不会用于训练,只用于评估模型性能。
len(mnist_train), len(mnist_test)每个输入图像的高度和宽度均为28像素。 数据集由灰度图像组成,其通道数为1。 为了简洁起见,本书将高度h像素、宽度w像素图像的形状记为h×w或(h,w)。
mnist_train[0][0].shapeFashion-MNIST中包含的10个类别,分别为t-shirt(T恤)、trouser(裤子)、pullover(套衫)、dress(连衣裙)、coat(外套)、sandal(凉鞋)、shirt(衬衫)、sneaker(运动鞋)、bag(包)和ankle boot(短靴)。 以下函数用于在数字标签索引及其文本名称之间进行转换。
def get_fashion_mnist_labels(labels): #@save """返回Fashion-MNIST数据集的文本标签""" text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat', 'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot'] return [text_labels[int(i)] for i in labels]2)读取小批量
为了使我们在读取训练集和测试集时更容易,我们使用内置的数据迭代器,而不是从零开始创建。 回顾一下,在每次迭代中,数据加载器每次都会读取一小批量数据,大小为
batch_size。 通过内置数据迭代器,我们可以随机打乱了所有样本,从而无偏见地读取小批量。batch_size = 256 def get_dataloader_workers(): #@save """使用4个进程来读取数据""" return 4 train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True, num_workers=get_dataloader_workers()) # 我们看一下读取训练数据所需的时间。 timer = d2l.Timer() for X, y in train_iter: continue f'{timer.stop():.2f} sec'3) 整合所有组件
现在我们定义
load_data_fashion_mnist函数,用于获取和读取Fashion-MNIST数据集。 这个函数返回训练集和验证集的数据迭代器。 此外,这个函数还接受一个可选参数resize,用来将图像大小调整为另一种形状。def load_data_fashion_mnist(batch_size, resize=None): #@save """下载Fashion-MNIST数据集,然后将其加载到内存中""" trans = [transforms.ToTensor()] if resize: trans.insert(0, transforms.Resize(resize)) trans = transforms.Compose(trans) mnist_train = torchvision.datasets.FashionMNIST( root="../data", train=True, transform=trans, download=True) mnist_test = torchvision.datasets.FashionMNIST( root="../data", train=False, transform=trans, download=True) return (data.DataLoader(mnist_train, batch_size, shuffle=True, num_workers=get_dataloader_workers()), data.DataLoader(mnist_test, batch_size, shuffle=False, num_workers=get_dataloader_workers())) # 下面,我们通过指定resize参数来测试load_data_fashion_mnist函数的图像大小调整功能。 train_iter, test_iter = load_data_fashion_mnist(32, resize=64) for X, y in train_iter: print(X.shape, X.dtype, y.shape, y.dtype) breaktrain_iter, test_iter = load_data_fashion_mnist(32, resize=64) for X, y in train_iter: print(X.shape, X.dtype, y.shape, y.dtype) break
2.4.2 softmax回归的简洁实现
import torch from torch import nn from d2l import torch as d2l batch_size = 256 train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)初始化模型参数
如我们在 3.4节所述, softmax回归的输出层是一个全连接层。 因此,为了实现我们的模型, 我们只需在
Sequential中添加一个带有10个输出的全连接层。 同样,在这里Sequential并不是必要的, 但它是实现深度模型的基础。 我们仍然以均值0和标准差0.01随机初始化权重。# PyTorch不会隐式地调整输入的形状。因此, # 我们在线性层前定义了展平层(flatten),来调整网络输入的形状 net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10)) def init_weights(m): if type(m) == nn.Linear: nn.init.normal_(m.weight, std=0.01) net.apply(init_weights);重新审视Softmax的实现
loss = nn.CrossEntropyLoss(reduction='none')优化算法
trainer = torch.optim.SGD(net.parameters(), lr=0.1) # 训练 num_epochs = 10 d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
3 结 语
本章链接:
3. 线性神经网络 — 动手学深度学习 2.0.0 documentation
学习链接:【视频+教材】原著大佬李沐带你读《动手学习深度学习》真的通俗易懂!深度学习入门必看!(人工智能、机器学习、神经网络、计算机视觉、图像处理、AI)_哔哩哔哩_bilibili
如果你有任何建议或疑问,欢迎留言讨论,最近每天基本上都会看留言,看到会及时回复。

















 1140
1140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









