






LinkedHashMap
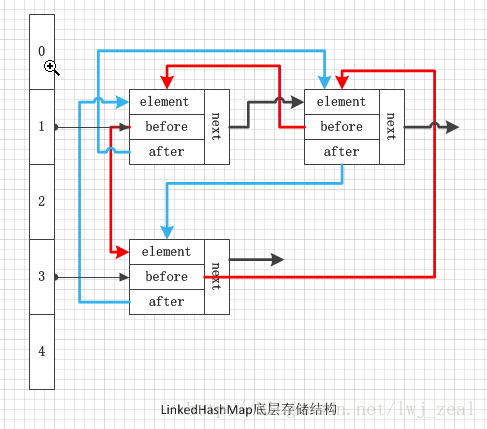
LinkedHashMap 是 HashMap 的子类,其数据结构是和 HashMap 是差不多的,也是由数组组成,每一个数组的元素都是由链表去维护。但是 LinkedHashMap 还增加了双向链表来维护数据的顺序。
数据结构图解:
1、按照访问顺序存取数据
最近最少使用算法的原理就是按照对数据的访问顺序进行的一次排序,在指定的时间对在链表中比较靠前的元素进行移除操作。
LinkedHashMap<String, String> map = new LinkedHashMap<>(0, 0.75f, true);
public LinkedHashMap(int initialCapacity,float loadFactor,boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}上面创建 LinkedHashMap 对象,注意第三个参数为 true ,也就是内部的 accessOrder = true,默认情况该属性是为 false 的,表示按照插入顺序排序,若是为 true 表示按照访问顺序排序。因为当前的 LinkedHashMap 是需要按照访问顺序排序的因此 accessOrder 应该需要赋值为 true 才行。
2、成员属性
在分析源码之前首先了解几个需要知道的成员属性。
- HashMapEntry
HashMapEntry 是一种数据结构,用于对 key-value 的封装,并且定义了 next 属性,这个属性是在链表中使用的,它用于指向该 HashMapEntry 在链表中的下一个 HashMapEntry 对象。
static class HashMapEntry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
HashMapEntry<K,V> next;
int hash;
...
} - table
table 是一个 HashMapEntry 数组类型数据,每次通过 put 方法添加进来的 key-value 都会被封装为 HashMapEntry 对象,然后添加到该 table 的指定位置上。
transient HashMapEntry<K,V>[] table = (HashMapEntry<K,V>[]) EMPTY_TABLE;3、存数据
map.put("1", "hello1");
map.put("2", "hello2");
map.put("3", "hello3");
map.put("4", "hello4");因为 LinkedHashMap 没有重写 HashMap 的 put 方法,因此存储数据的会调用父类 HashMap 的 put 方法。下面来关注一下 HashMap#put 方法。因为真正存储还要计算 hash 值之类,因此下面的图解只是简单的描述一些数据的存储。

- HashMap#put
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//key 为 null 的情况
if (key == null)
return putForNullKey(value);
//根据 key 计算出对应的 hash 值
int hash = sun.misc.Hashing.singleWordWangJenkinsHash(key);
//调用 indexFor 方法计算出这个 key-value 应该存放在 table 数组的哪个角标位置i上。
int i = indexFor(hash, table.length);
//遍历整个 table 数组
for (HashMapEntry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//当前需要存储的 key 是存在的
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
//更新操作
V oldValue = e.value;
e.value = value;
//该方法在 HashMap 中是空实现,但是在 LinkedHashMap 中有具体的实现。
//这个方法是用于对当前的 HashMapEntry 进行排序操作。
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//addEntry 已经被 LinkedHashMap 复写了,因此直接关注 LinkedHashMap 的具体实现即可。
addEntry(hash, key, value, i);
return null;
}
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}- LinkedHashMap#addEntry
void addEntry(int hash, K key, V value, int bucketIndex) {
// Remove eldest entry if instructed
//注意 header.after 指向就是双向链表的头部,在 accessOrder = true 的情况下的,也就是最近最少使用的一些元素。
// header.after 为啥是双向链表的头部呢,下面会有图解。
LinkedHashMapEntry<K,V> eldest = header.after;
if (eldest != header) {
boolean removeEldest;
size++;
try {
//removeEldestEntry 这个方法默认返回 false,它表示是否要移除先前存储的元素,
//这个操作得让用户去实现这个方法,例如可以定义当 size() 超过了指定得值后,返回true 等。
removeEldest = removeEldestEntry(eldest);
} finally {
size--;
}
if (removeEldest) {
//移除指定元素。
removeEntryForKey(eldest.key);
}
}
//上面的代码只是判断是否要移除先前的元素
//下面还是回调到 Hashmap#addEntry 方法了。
super.addEntry(hash, key, value, bucketIndex);
}
- HashMap#addEntry,真正添加的操作还是有 HashMap 的 addEntry 去实现的。
void addEntry(int hash, K key, V value, int bucketIndex) {
//判断是否要进行扩容操作。
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? sun.misc.Hashing.singleWordWangJenkinsHash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
//根据 key 和 value 创建出一个 entry 对象出来
createEntry(hash, key, value, bucketIndex);
}
- LinkedHashMap #createEntry
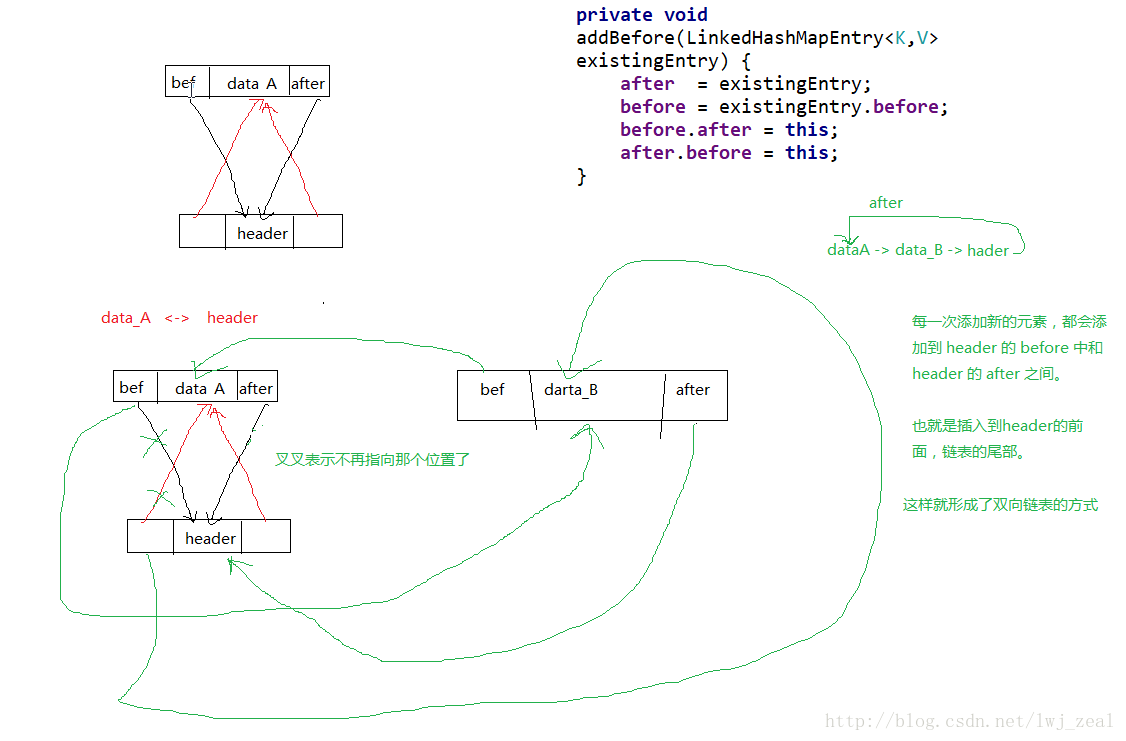
代码执行到了 createEntry 中,因为 LinkedHashMap 已经实现了该方法,因此直接浏览 LinkedHasdhMap 即可;在该方法中,首先根据第四个参数 bucjetIndex 找到对应 table 数组指定位置的 LinkedHashMapEntry 对象,将该 LinkedHashMapEntry 添加到指定的位置上。然后调用 e.addBefore(header) ,注意该方法是维护双向链表的核心方法,表示将该元素添加到双向链表的尾部,也就是 header 节点的前面位置,具体的操作可以看下面的图解。现在可以知道,每次新添加进来的数据都会放在双向链表的尾部,那么就是说头部就是比较少去访问到的元素,因此若是需要移除一些没有怎么访问到的元素,就应该从头部开始移除,这就是为什么上面的 addEntry 方法中要用到 header.after 了,因为 header.after 表示的就是双向链表中最少使用的那个 entry 对象。
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMapEntry<K,V> old = table[bucketIndex];
LinkedHashMapEntry<K,V> e = new LinkedHashMapEntry<>(hash, key, value, old);
table[bucketIndex] = e;
e.addBefore(header);
size++;
}维护双向链表的 e.addBefore(header)
private void addBefore(LinkedHashMapEntry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
4、取数据
因为取出这个数据表示该 Entry 被访问,因此该 Entry 在双向链表的顺序要重新排序,因此LinkedHashMap 重写了 get 方法。
- LinkedHashMap#get
public V get(Object key) {
LinkedHashMapEntry<K,V> e = (LinkedHashMapEntry<K,V>)getEntry(key);
if (e == null)
return null;
//排序操作
e.recordAccess(this);
return e.value;
}- HashMap#getEntry()
该方法并没有被 LinkedHashMap 复写,它表示根据指定的 key 获取到保存该 key-value 的 Entry 对象。内部实现的原理就是通过遍历 table 数组,找到每一个 Entry 元素,然后遍历该 Entry 链表的所有元素,判断链表的每一个 Entry 的 hash 值和需要获取的 key 的 hash 是否一致。
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : sun.misc.Hashing.singleWordWangJenkinsHash(key);
for (HashMapEntry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
//找到对应的元素
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}遍历数据
循环遍历获取每一个 Entry 对象,然后输出对应的 key 和 value 值。从下面的输出值中可以看出,它是一种顺序输出的。
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println("key:" + entry.getKey() + ";value:" + entry.getValue());
}
方式1:
map.put("1", "hello1");
map.put("2", "hello2");
map.put("3", "hello3");
map.put("4", "hello4");
key:1;value:hello1
key:2;value:hello2
key:3;value:hello3
key:4;value:hello4
方式2:
map.put("1", "hello1");
map.put("2", "hello2");
map.put("3", "hello3");
//在这里取出了 key 为 "1" 的元素,那么该 Entry 的排序就会发生改变。
map.get("1");
map.put("4", "hello4");
key:2;value:hello2
key:3;value:hello3
key:1;value:hello1
key:4;value:hello4- HashMap#entrySet()
获取所有 Entry 对象的 set 集合
public Set<Map.Entry<K,V>> entrySet() {
//内部调用了entrySet0
return entrySet0();
}
private Set<Map.Entry<K,V>> entrySet0() {
Set<Map.Entry<K,V>> es = entrySet;
return es != null ? es : (entrySet = new EntrySet());
}- EntrySet#iterator()
注意 foreach 循环底层也是通过调用 EntrySet 的 iterator() 不断的去调用 next() 方法循环的。
private final class EntrySet extends AbstractSet<Map.Entry<K,V>> {
public Iterator<Map.Entry<K,V>> iterator() {
//内部调用了 newEntryIterator()
return newEntryIterator();
}- LinkedHashMap#newEntryIterator
这里的 newEntryInterator 已经被 LinkedHashMap 复写了,因此只看 LinkedHahMap 的 newEntryInterator 方法
Iterator<Map.Entry<K,V>> newEntryIterator() {
return new EntryIterator();
}
private class EntryIterator extends LinkedHashIterator<Map.Entry<K,V>> {
public Map.Entry<K,V> next() {
return nextEntry();
}
}- LinkedHashIterator#nextEntry()
private abstract class LinkedHashIterator<T> implements Iterator<T> {
//header.after 上面描述过了,这表示双向链表的头部的下一个 Entry 对象,是最近最少使用的元素。
LinkedHashMapEntry<K,V> nextEntry = header.after;
LinkedHashMapEntry<K,V> lastReturned = null;
/**
* The modCount value that the iterator believes that the backing
* List should have. If this expectation is violated, the iterato
* has detected concurrent modification.
*/
int expectedModCount = modCount;
public boolean hasNext() {
return nextEntry != header;
}
public void remove() {
if (lastReturned == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
LinkedHashMap.this.remove(lastReturned.key);
lastReturned = null;
expectedModCount = modCount;
}
//关键方法,获取下一个 Entry 的方法,该方法会在 Iterator.next() 方法内部调用
Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (nextEntry == header)
throw new NoSuchElementException();
LinkedHashMapEntry<K,V> e = lastReturned = nextEntry;
nextEntry = e.after;
return e;
}
}5、在 DiskLruCache 移除最近最少使用的元素的的源码 trimeToSize()
在这里也是获取了 EntrySet 的 iterator() 然后不断地调用 next() 方法获取最近最少使用的元素,然后调用 remove 方法进行移除操作。
private void trimToSize() throws IOException {
while (size > maxSize) {
final Map.Entry<String, Entry> toEvict = lruEntries.entrySet().iterator().next();
remove(toEvict.getKey());
}
}














 608
608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









