







本论文在《Particular object retrieval with integral max-pooling of CNN activations》 的基础上重新提出一种Reranking的方法。
在叙述开始之前,先理解一下卷积Feature Map
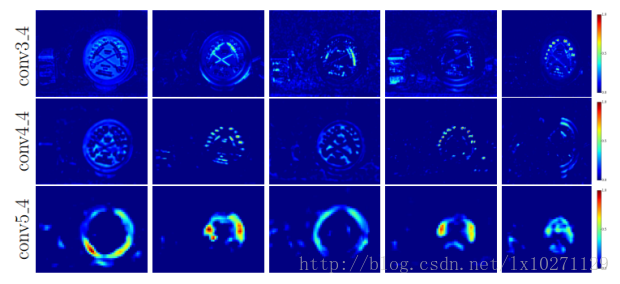
上图是对不同卷积层的一个可视化,我们可以看到,early convolutional layer捕捉的是一个主要的视觉模型,而late convolutional layer更多的则是对目标轮廓的表示。
这篇论文那里面的Reranking过程整理:
一 方法介绍
1生产base regions,方法有两种:
1.1 Feature Map Pooling(FMP)
对于卷积网络某一层,若有D个卷积核,可以生产D张Feature Map(FM) 图。对于每一个FM,我们选取响应值非零的位置作为一个Base Regions(BR),这样BR的数量就相当于FM的数量。然后对BR中的响应值作sum-pooling,这样每一个FM都会得到一个值fd。但是对于一个给定的Image,很多FM有很大的重叠,所以其对应的pooling特征,也就是fd基本相同,我们对这些Fd值进行一个聚类,聚类中心设置为K。(这里可以理解把D个BR聚类成K个BR)。
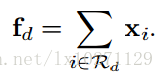
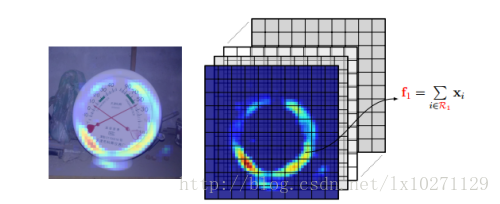
sum-pooling图示意(把响应值相加)
1.2 Overlapped Spatial Pyramid Pooling (OSPP)
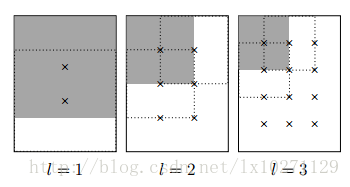
OSPP法与提出R-MAC论文里的Regions提取方法相同,对应不同尺度,我们提取 l × (l + m − 1) 个Regions,其宽度= 2 min(W; H)/(l + 1),再均匀采样出m个区域(BR区域)
2 Reranking过程
论文提出Query Adaptive Matching(QAM)的一个方法进行Reranking,其实就是对BR进行归并成一个Merge Region,而这个选取过程转化成一个最优化问题。利用下面这个过程,对于某张图片而言,选出与query最相似的一个合并区域(merge regions)
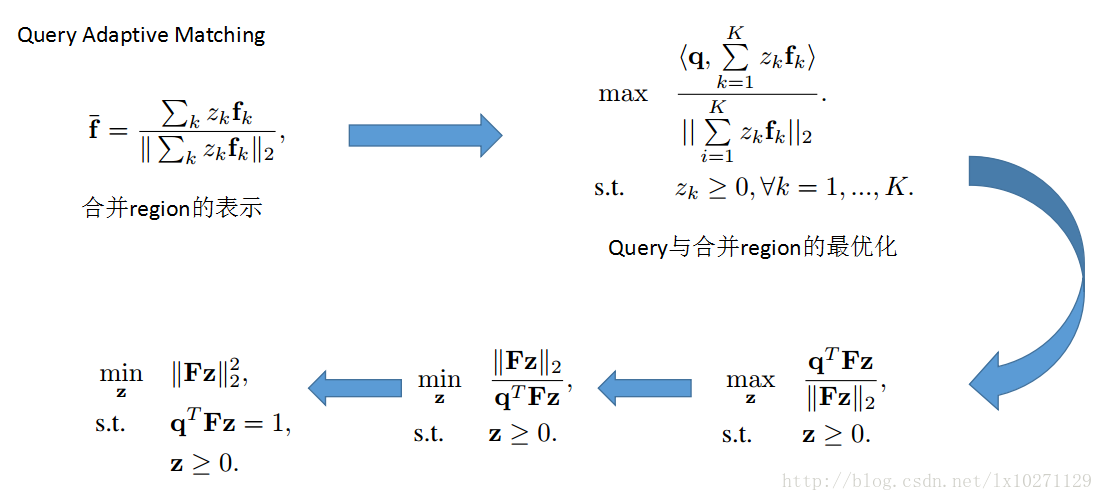
通过以上的的优化过程(其实最后就是一个普通的二次规划问题)我们选取出某张图片一个Merge Region。计算出query和Merge region的相似度得分做为Reranking的Score,最终进行排名。
这里说一下我对上面Base region 的生成过程 结合QAM的理解:
对于FMP方法:每一个Feature Map我们会得到一个Base Region,所以,通过FMP的方法,我们最后得到的Base region的数量等于该层卷积核的数量。而最终base-region的表示,论文确用了一个sum-pooling的方式,这样每一个Base Region最终只会得出一个值,而在最优化过程中,Merge Region最终表示也会成为一个值,也就无法与query的向量做内积。这也是我一直对这篇论文疑惑的地方,如果哪个学长(先于闻道为长之)看明白了这个问题,还请不吝赐教。(也可能是论文的一个错误)
对于OSPP法:由于在不同FM上做不同尺度的Base Region选取,所以对应不同的Base Region有不同的向量表达形式。我们可以很轻松的应用QAM对Base Region进行选取。
二 实验
数据库:Oxford5K,Paris6K,Sculpture6K,INSTRE
论文做了大量的实验,值得一提的是两个实验结果
首先是不同Base Region生成方法对应的Reranking的mAP值

FMP大体上优于OSPP
其次是跟目前的方法进行对比:

论文的最后,作者换了网络,使用GoogleNet和ResNet网络,通过对这两个网络不同层的mAP,我们选择ResNet152的res5b这一层,最终于VGGNET19做对比:

可以看出ResNet152的网络优于VGG19















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









