







(一) 对于大型WEB日志(比如8G),可以用awk编程分析日志,满足自己的特别需求(awk适合标准输入,再标准输出的分析编程):
如8G日志:
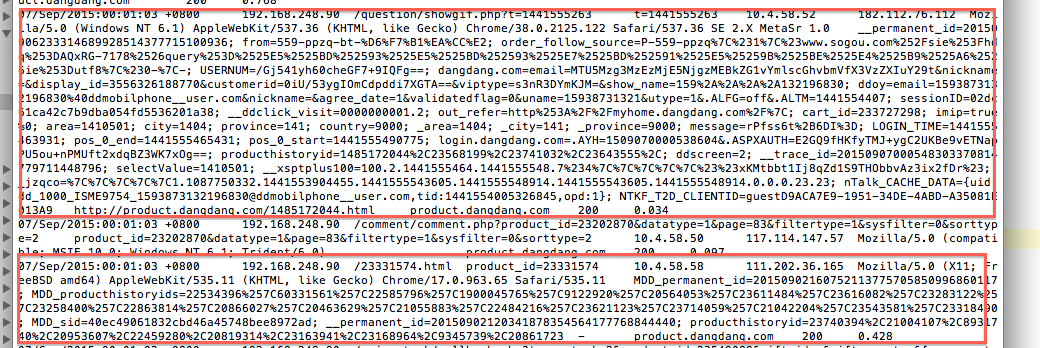
WEB日志一般格式比较标准,适合awk来抽取需要的部分字段。
可先将WEB日志中需要的字段抽取出来,存入一个文件中,比如我抽取第一列(
1):时间,第三列(
3):请求站点,倒数第三列(
10):访问站点,倒数第二列(
11):该次请求状态(200表示OK),倒数最后一列($12):该次请求花费时间。
利用awk命令:
awk -F '\t' '{split($1, access_time, " "); split($3, access_url, "?"); print access_time[1] "\t" access_url[1] "\t" $12 "\t" $10 "\t" $11 ;}' access_log.20150907 > product_log_step1.res分析:先得到几百M的文件再说,为了方便,否则每次针对8G的文件来运行很头疼。。源文件是access_log.20150907,根据 ‘\t’ 分割后源文件每一行得到12小块,再根据需要获取
1,
3,
10,
11,
12,只不过针对
1,$3再根据自己的需求split掉多余的部分,最后保存在服务器上同目录下的product_log_step1.res文件(文件自己命名,也可以.txt格式)
product_log_step1.res文件如下:
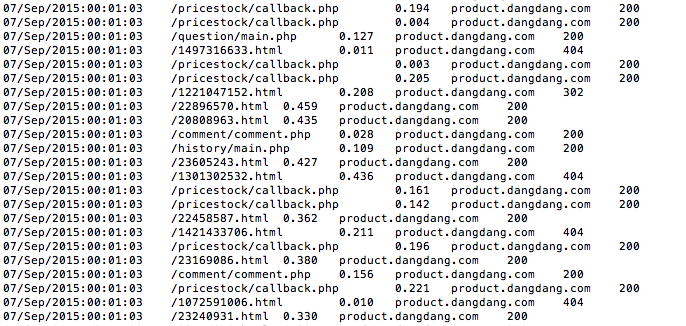
再根据自己的需求,比如统计请求正常的次数,5分钟内每秒请求次数,等等。。。
比如需求:
1、每5分钟内,平均每秒请求次数(共24小时,总请求一千万次左右)
2、请求状态正常次数,非正常次数
3、0-1秒内请求次数,1-2秒请求次数,2-3秒请求次数,3-4秒请求次数,4-5秒请求次数,大于5秒请求次数
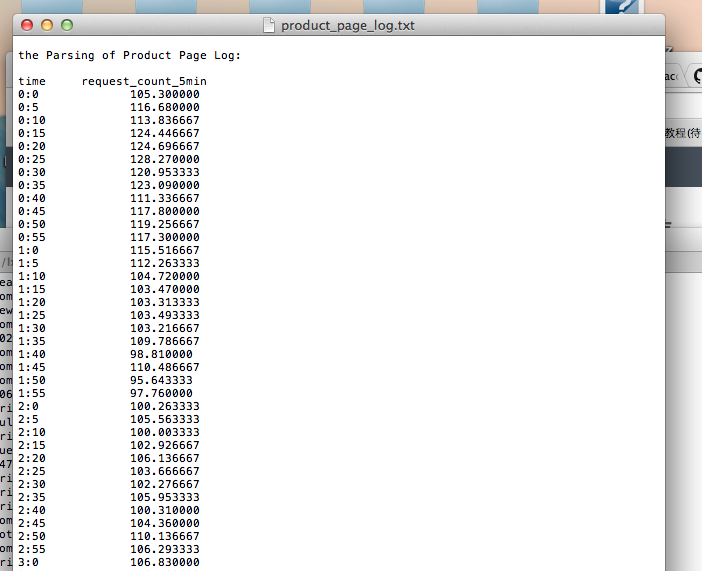
生成文件:

代码如下:
awk -F "\t" '
function getHours(times){
split (times, t, ":");
return int(t[2]);
}
function getMinutes(times){
split (times, t, ":");
return int(t[3]);
}
BEGIN{
for (i = 0; i < 24; i++){
for (j = 0; j < 12; j++){
request[i,j] = 0;
}
}
for(k=0; k<2; k++){
request_state[k] = 0;
}
for(k=0; k<6; k++){
request_time[k] = 0;
}
}
{
h = getHours($1);
min = int(getMinutes($1)/5);
request[h,min] +=1;
if($5=="200"){
request_state[0] +=1;
}else{
request_state[1] +=1;
}
if($3>"0" && $3<="1"){
request_time[0] +=1;
}else if($3>1 && $3<=2){
request_time[1] +=1;
}else if($3>2 && $3<=3){
request_time[2] +=1;
}else if($3>3 && $3<=4){
request_time[3] +=1;
}else if($3>4 && $3<=5){
request_time[4] +=1;
}else{
request_time[5] +=1;
}
}
END{
printf("\nthe Parsing of Product Page Log:\n\n");
printf("time \t request_count_5min\n");
for (i=0; i < 24; i++){
for(j=0; j<12; j++){
printf("%s:%s\t\t%f\n",i,j*5,request[i,j]/300);
}
}
printf("OK \t\t NOT_OK\n");
printf("%s \t %s\n",request_state[0],request_state[1]);
printf(" (0s-1s)\t (1s-2s)\t (2s-3s)\t (3s-4s)\t (4s-5s)\t (>5s)\n");
printf("%s\t\t %s\t\t %s\t\t %s\t\t %s\t\t %s\n",request_time[0],request_time[1],request_time[2],request_time[3],request_time[4],request_time[5]);
}
' product_log.res > product_page_log.txt
只要按照awk语言格式编写就行,格式如下:
然后根据业务逻辑把需要的数据的数据抽取出来,保存在一个文件中吧,比如代码中的product_page_log.txt文件,源文件是product_log.res。
(二) awk,sed,grep,sort,uniq,wc,split,tail,less 命令
(待完善)















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









