







前提
开源的搜索引擎,从海量数据中快速找到需要的内容。(分词检索,类似百度查询、博客文章关键词搜索)
elasticsearch结合 Kibana、Logstas、Beats,也就是 elastic stack(简称ELK),广泛应用于日志分析、实时监控。
JDK兼容性:https://www.elastic.co/cn/support/matrix#matrix_jvm
操作系统兼容性:https://www.elastic.co/cn/support/matrix
自身兼容性:https://www.elastic.co/cn/support/matrix#matrix_compatibility
对于ES 8.1 及以上版本而言,支持 JDK 17、JDK 18
倒排索引
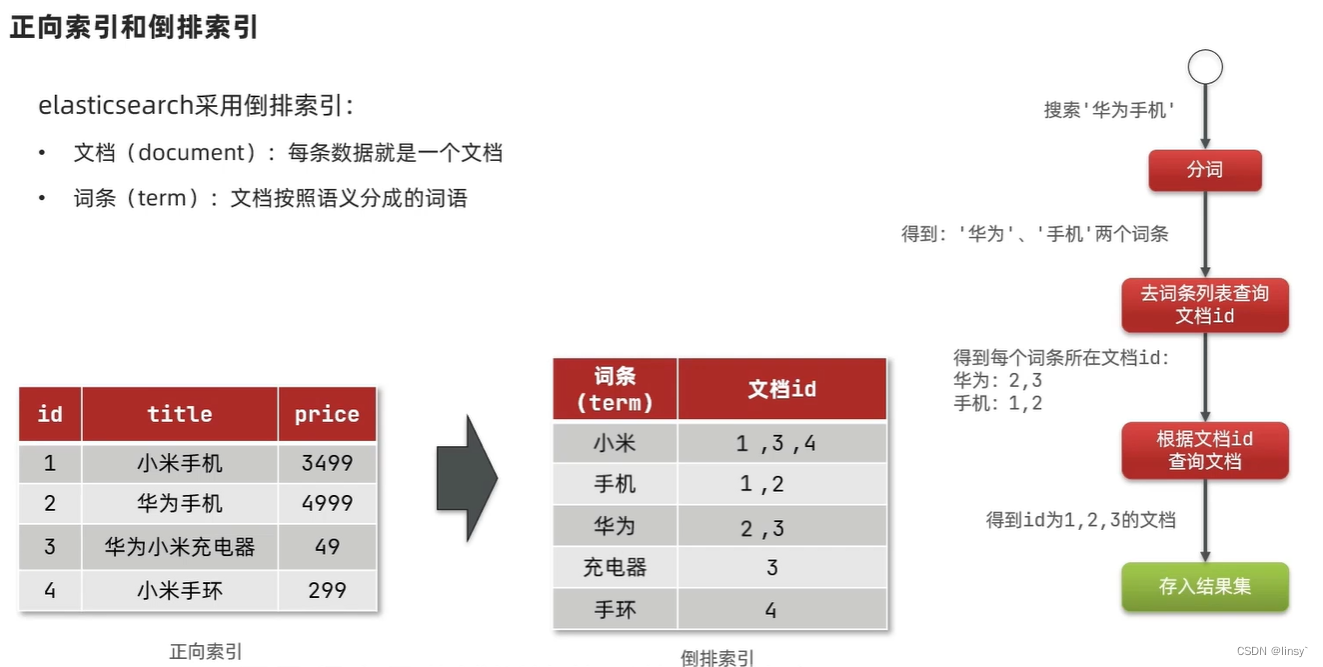
MySQL、ES的区别和关联
mysql擅长事务操作(ACID),确保数据安全和一致性
ES擅长海量数据搜索、分析、计算
文档
elasticsearch是面向文档存储的(JSON),每一条数据就是一个文档

索引
es中的索引是指相同类型的文档集合,即mysql中表的概念
映射:索引中文档字段的约束,比如名称、类型


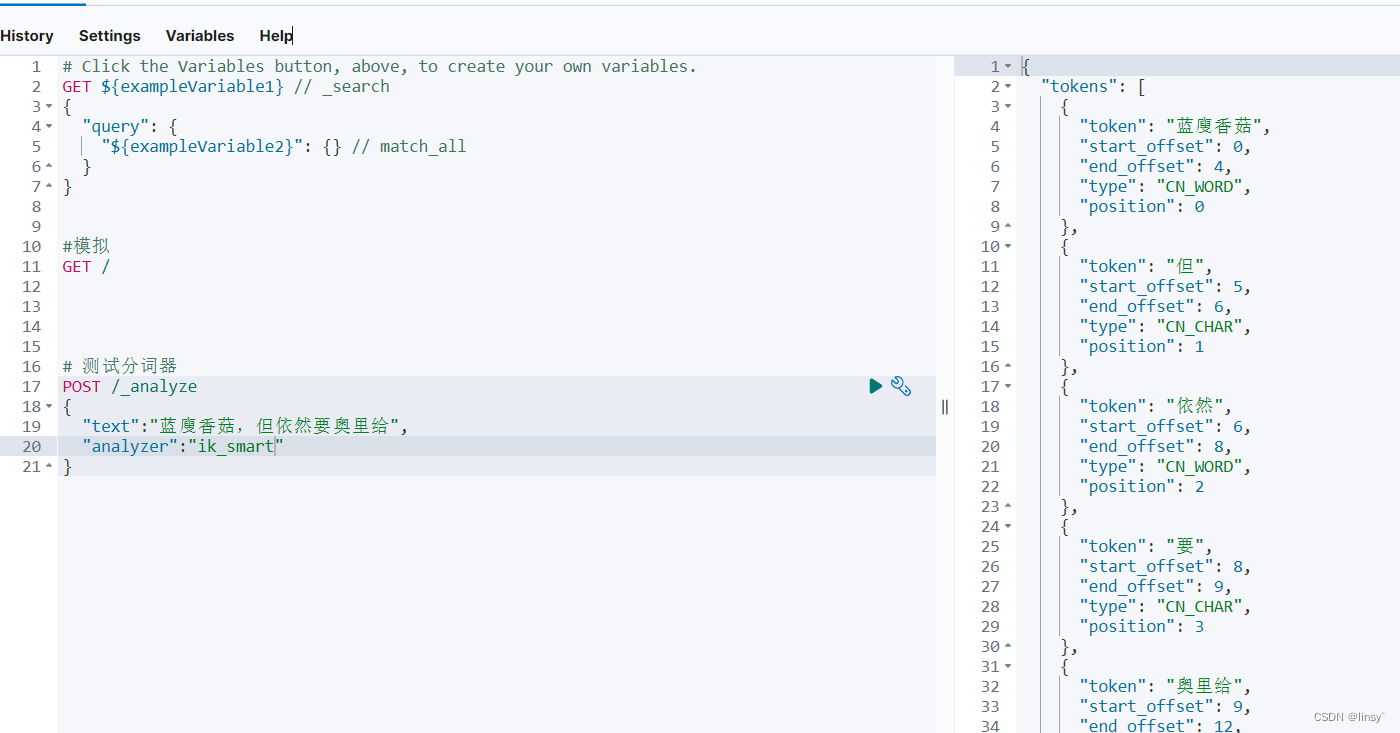
IK分词器
作用:
- 在创建倒排索引时对文档进行分词
- 用户搜索时,对内容进行分词
ik分词器的两种模式
POST /_analyze
{
“text”:“这是程序员的一次测试,包含English”,
“analyzer”:“ik_max_word”
}
ik_smart:最小切分(粗粒度),分出来的词不会再细分(程序员)
ik_max_word:最细切分(细粒度),分出来的词更多更细(程序员、程序)

拓展词条、停用词条
进入docker 创建的容器的插件目录,找到Ik分词器下的 IKAnalyzer.cfg.xml 文件,扩展词典在 中添加文件名称(例如ext.dic),停用词典在 中添加,(例如stopword.dic)。当然之后需要你手段创建词典文件,内容格式为一词一行。

















 216
216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









