







1、Map集合介绍Map<K,V>
Map集合:该集合存储键值对。一对一对往里存。而且要保证键的唯一性。
共性方法:
1,添加。put(K key, V value)
putAll(Map<? extends K,? extends V> m)
2,删除。
clear()
remove(Object key)
3,判断。
containsValue(Object value)
containsKey(Object key)
isEmpty()
4,获取。
get(Object key)
size()
values()
entrySet()
keySet()
Map
|--Hashtable:底层是哈希表数据结构,不可以存入null键null值。该集合是线程同步的。jdk1.0.效率低。
|--HashMap:底层是哈希表数据结构,允许使用 null 值和 null 键,该集合是不同步的。将hashtable替代,jdk1.2.效率高。
|--TreeMap:底层是二叉树数据结构。线程不同步。可以用于给map集合中的键进行排序。
和Set很像。
其实大家,Set底层就是使用了Map集合。
基本操作一些代码:
import java.util.*;
public class MapDemo
{
public static void main(String[] arg)
{
Map<String,String> m=new TreeMap<String,String>();
m.put("001", "zhangsan"); //增
m.put("002", "wangwu");
m.put("003", "zhaoliu");
show(m);
m.remove("002"); //删
show(m);
System.out.println(m.get("003")+"..."+m.containsKey("002")+".."); //获取+判断
System.out.println(m);
System.out.println(m.put("003", "wangwu")); //增的操作是:先查找有没有相同的键值,有的话,则返回当前value,并用新的value替代原来
System.out.println(m);
}
public static void show(Map<String,String> m)
{
Set<String> s=m.keySet();
Collection<String> t=m.values();
System.out.println(s);
System.out.println(t);
}
}

2、Map集合两种取出方法
2.1、Set<k> keySet:将map中所有的键存入到Set集合。因为set具备迭代器。
所有可以迭代方式取出所有的键,在根据get方法。获取每一个键对应的值。
Map集合的取出原理:将map集合的键转成set集合。在通过迭代器取出。
public static void show(Map<String,String> m)
{
Set<String> s=m.keySet();
Iterator<String> it=s.iterator();
while(it.hasNext())
{
System.out.println(m.get(it.next()));
}
}
2.2、Set<Map.Entry<k,v>> entrySet:将map集合中的映射关系存入到了set集合中,
而这个关系的数据类型就是:Map.EntryEntry其实就是Map中的一个static内部接口。
为什么要定义在内部呢?
因为只有有了Map集合,有了键值对,才会有键值的映射关系。
关系属于Map集合中的一个内部事物。
而且该事物在直接访问Map集合中的元素。
public static void EntryShow(Map<String,String> m)
{
Set<Map.Entry<String,String>> s=m.entrySet();
Iterator<Map.Entry<String,String>> it=s.iterator();
while(it.hasNext())
{
Map.Entry<String,String> map=it.next();
String k=map.getKey();
String v=map.getValue();
System.out.println(k+":.."+v);
}
}
其是static修饰的,因为只有在类中成员位置中才能被static修饰,因此其必定为内部接口!

其在java中的机理为:
/*
Map.Entry 其实Entry也是一个接口,它是Map接口中的一个内部接口。
interface Map
{
public static interface Entry
{
public abstract Object getKey();
public abstract Object getValue();
}
}
class HashMap implements Map
{
class Hahs implements Map.Entry
{
public Object getKey(){}
public Object getValue(){}
}
}
*/3、TreeMap练习
3.1、"sdfgzxcvasdfxcvdf"获取该字符串中的字母出现的次数。
希望打印结果:a(1)c(2).....
通过结果发现,每一个字母都有对应的次数。
说明字母和次数之间都有映射关系。
注意了,当发现有映射关系时,可以选择map集合。
因为map集合中存放就是映射关系。
什么使用map集合呢?
当数据之间存在这映射关系时,就要先想map集合。
思路:
1,将字符串转换成字符数组。因为要对每一个字母进行操作。
2,定义一个map集合,因为打印结果的字母有顺序,所以使用treemap集合。
3,遍历字符数组。
将每一个字母作为键去查map集合。
如果返回null,将该字母和1存入到map集合中。
如果返回不是null,说明该字母在map集合已经存在并有对应次数。
那么就获取该次数并进行自增。,然后将该字母和自增后的次数存入到map集合中。覆盖调用原理键所对应的值。
4,将map集合中的数据变成指定的字符串形式返回。
import java.util.*;
public class TreeMapTest01
{
public static void main(String[] arg)
{
show("aaaaaabb");
}
public static void show(String s)
{
char[] b=s.toCharArray();
TreeMap<Character,Integer> T=new TreeMap<Character,Integer>();
for(int i=0;i<s.length();i++)
{
int count=0; //方法一
if(T.get(b[i])!=null)
{
count=T.get(b[i]); //自动拆箱
}
/*
Integer count=T.get(b[i]);//方法二
if(count==null)
{
count=0; //自动装箱
}
*/
count++;
T.put(b[i], count);
}
System.out.println(T);
StringBuilder sb=new StringBuilder(); //建立输出字符串容器
//方法一:以keySet方法取出map中的元素
Set<Character> set=T.keySet(); //将map中的键值以set集合取出
Iterator<Character> it1=set.iterator(); //以迭代器的方式逐一取出key值对应的value值
while(it1.hasNext())
{
Character o=it1.next();
sb.append(o+"("+T.get(o)+")"); //按照输出类型将字符窜装进字符串容器中
}
System.out.println(sb);
//方法二:以Map.Entry方法取出map中的元素
Set<Map.Entry<Character, Integer>> myEntry= T.entrySet(); //将map中的k-v对应关系取出存放在set集合中
Iterator<Map.Entry<Character, Integer>> it2=myEntry.iterator(); //建立此集合的迭代器
sb.delete(0, sb.length()); //清除字符串容器中的元素
while(it2.hasNext())
{
Map.Entry<Character, Integer> entry=it2.next(); //取出当前迭代器中的k-v关系
char k=entry.getKey(); //取出k值
int v=entry.getValue(); //取出v值
sb.append(k+"("+v+")");
}
System.out.println(sb);
}
}
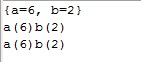















 247
247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









