







目录
KNN算法简介
KNN算法思想
如果一个样本在特征空间中的 k 个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别,比如:根据你的“邻居”来推断出你的类别
那么,如何确定样本的相似性?
样本相似性:样本都是属于一个任务数据集的。样本距离越近则越相似。
电影类型预测例子
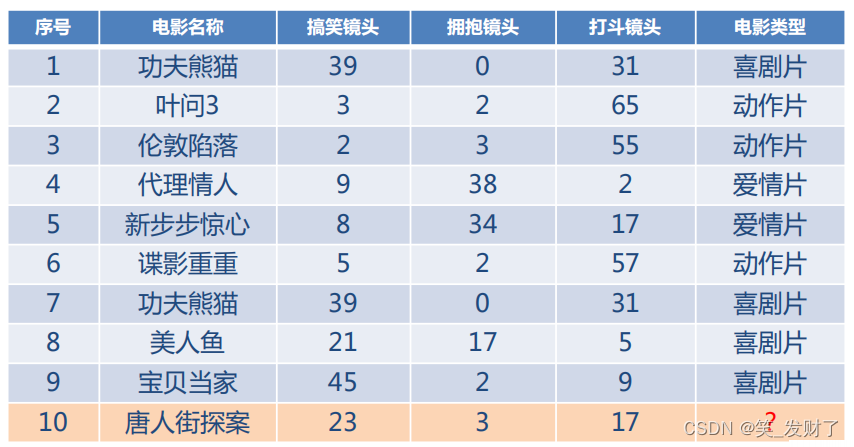
分别计算10号电影(唐人街探案)与前九个电影的距离


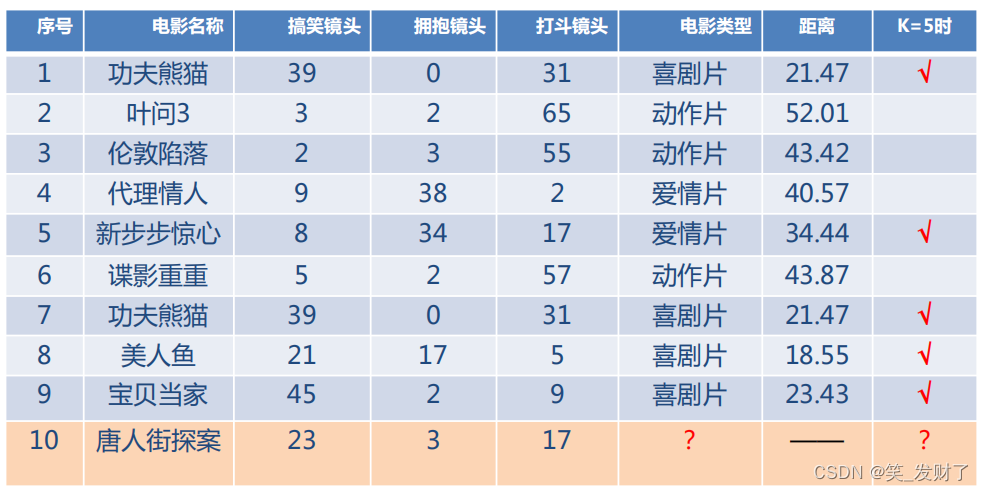
令k=5(超参数,人为指定)找出最相似(距离最近)的5个电影的类别,查看哪个类别最多,来决定10号电影的类别
K值的选择
K值过小:用较小邻域中的训练实例进行预测
容易受到异常点的影响
k值的减少就意味着整体模型变得复杂,容易发生过拟合
K值过大:用较大邻域中的训练实例进行预测
受到样本均衡的问题
且K值的增大就意味着整体的模型变得简单,欠拟合
举个栗子:当K=N(N为训练样本个数)
无论输入实例是什么,只会按照训练集中最多的类别进行预测,受到样本均衡的影响
如何对K超参数进行调优?
需要一些方法寻找这个最合适的K值
交叉验证、网格搜索
KNN解决的问题
解决问题:分类问题、回归问题
算法思想:若一个样本在特征空间中的 K 个最相似的样本大多数属于某一个类别,则该样本也属于这个类别
相似性:欧氏距离
分类流程
- 计算未知样本到每一个训练样本的距离
- 将训练样本根据距离大小升序排列
- 取出距离最近的 K 个训练样本
- 进行多数表决,统计 K 个样本中哪个类别的样本个数最多
- 将未知的样本归属到出现次数最多的类别
回归流程
- 计算未知样本到每一个训练样本的距离
- 将训练样本根据距离大小升序排列
- 取出距离最近的 K 个训练样本
- 把这个 K 个样本的目标值计算其平均值
- 将未知的样本预测的值了
KNN分类算法API
# 导入工具 包
# 分类
from sklearn.neighbors import KNeighborsClassifier # KNN Classifier 分类
# 创建数据
X = [[1], [2], [3], [4], [5], [6]]
y = [1, 2, 3, 2, 2, 1]
# 类实例化/实例化模型
estimator = KNeighborsClassifier(n_neighbors=3) # n_neighbors=3 K=3 int,可选(默认= 5),
# k_neighbors查询默认使用的邻居数
# fit模型训练函数
estimator.fit(X, y)
# 数据预测
myret = estimator.predict([[4]])
print(myret) #结果 [2]KNN回归算法API
# 回归
from sklearn.neighbors import KNeighborsRegressor
X = [[0, 0, 1],
[1, 0, 0],
[3, 10, 10],
[4, 11, 12]
]
y = [0.1, 0.2, 0.3, 0.4]
estimator = KNeighborsRegressor(n_neighbors=2) # Regressor 回归
estimator.fit(X, y)
myret = estimator.predict([[1, 0, 0]])
print(myret) #结果 [0.15]总结
- KNN概念 K Nearest Neighbor
- KNN分类流程
- KNN回归流程
- K值的选择
K值过小:过拟合
K值过大:欠拟合















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









