







容器篇
1、队列与堆栈
摘选自http://blog.csdn.net/hguisu/article/details/7674195(队列和堆栈)
队列就像一个大箱子,先进去的后出来。
栈就像一个管道,先进去的从另一头先出来。
2、迭代器(public interface Iterator<E>)
Iterator接口,只要是实现了Collection接口,就可以调用iterator()方法,该方法返回Iterator对象。
我们知道ArrayList集合,底层是以数组的形式存储数据(比如说我们要找一个数据,直接通过下标,跳过多少个字节,查询效率高,增删效率低。),LinkedList底层是以链表来存储数据的(一个一个挨着一个的去找,效率比较低,但是如果要是增删的话,效率会比ArrayList高)。
由于它们底层实现的不同,我们无法写出一个统一的版本,所以此时Iterator接口就出现了。
我们知道Collection接口继承了Iterable接口,该接口中有一个方法iterator()方法
所以Collection接口就有了这个方法,这个方法返回一个
实现了Itreator接口的对象,我们可以调用Itreator接口的hasNext()方法、next()方法、remove()方法。
这样我们就可以遍历集合中的所有元素。
Iterator在底层其实就相当于一个指针一样。
Iterator i=c.iterator();
while(i.hasNext()){
Name n=(Name)i.next(); }
}扯得有点远了,需要了解一下内部接口。(一下内部接口的例子摘自博客园的一篇博客)
http://www.cnblogs.com/chenpi/p/5518400.html#_label0
1、什么是内部接口?
内部接口也称为嵌套接口,记载一个接口内部定义另外一个接口,举个例子是,Entry接口是定义在Map接口里面,
public interface Map {
interface Entry{
int getKey();
}
void clear();
}
一种对那些在同一个地方使用的接口进行逻辑上分组。
封装思想的体现。
嵌套接口可以增强代码的易读性和可读性。
3、内部类如何工作。
为了弄清楚内部接口是如何工作的,我们可以拿他与内部类作比较,内部类可以被认为是一个外部类内部定义的一个常规方法
因为一个方法可以被声明为静态和非静态,类似的内部类也可以被声明为静态的和非静态的。静态类类似于静态方法,他只能访问外部类的静态成员属性,非静态方法可以访问外部类所有成员属性。

因为接口是不能实例化的,内部接口只有当它是静态的才有意义。因此,默认情况下,内部接口是静态的,不管你是否动手加了static关键字。
4、内部接口的例子
Map.java
public interface Map {
interface Entry{
int getKey();
}
void clear();
}public class MapImpl implements Map {
class ImplEntry implements Map.Entry{
public int getKey() {
return 0;
}
}
@Override
public void clear() {
//clear
}
}好了回到我们的正轨
Map是java中的接口,Map.Entry是Map的一个内部接口。
http://blog.csdn.net/ddplayer12/article/details/17142491(参考自CSDN的一篇博客。)
| static interface | Map.Entry<K,V> |
其实Map.Entry和Map都是一样的,但是最起码有点区别吧。
下面我们来分析一下
Map接口的所有方法。
void clear()移除所有键值对
boolean containskey(Object key)是否有该键
boolean containsValue(Object value)是否有该值。
Set<Map.Entry<K,V>> entrySet()
set<K> keySet()
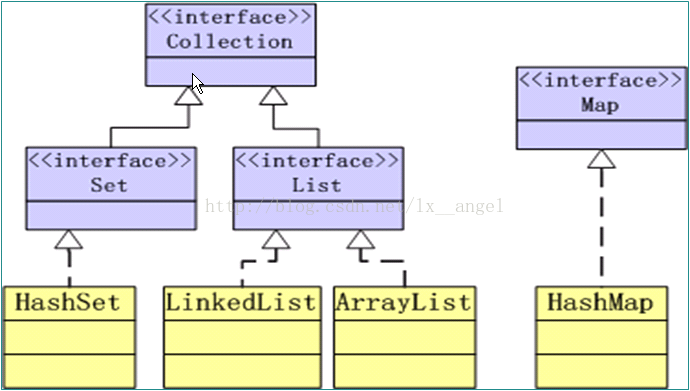
我为什么要把这两个方法拿出来一起讲呢,以为我想啊,其实是这两个方法放在一起讲比较容易懂一点。
所谓keySet()方法,顾名思义,就是将Map集合(这里Map只是接口,它的实现类才是具体的集合,我这里像这样说,你咬我)中
的所有键(key)值拿出来,然后再放到Set集合中,这里怕你弄混了,下面有一张它们的关系图谱。
entrySet()方法是将Map结合中一些元素放到Set集合中,也就是想到于把它们提取出来。不可能说把所有都提取出来吧,当然是有一定的条件,
就是这个元素是属于Map.Entry类型的元素。这里Map.Entry是个什么类型,别急啊,待会再讨论。
至于为什么要放到Set集合里去呢,肯定是做进一步的研究或是操作啊,我猜的。
Collection<T> values()讲Map集合中的值(value)放到Collection中,你当然要弄一个Collection结合来承接它啊。
其它方法我就不一一介绍了,我懒啊。
现在就是我们来讨论这个Map.Entry这个嵌套接口的时候了。
Map.Entry是Map接口的内部接口
https://zhidao.baidu.com/question/396998395.html
一般情况下,要输出Map中的key 和 value 是先得到key的集合,然后再迭代(循环)由每个key得到每个value
3、泛型Generic
http://www.cnblogs.com/lzq198754/p/5780426.html(泛型详解博客)
以前把一个东西放入集合中都会当做Object类型对待,就像一个大杂烩一样。比较凌乱,现在我们可以指定某个集合中只能装一种类型的数据。
好处是增强程序的可读性和稳定性(貌似好像有点)。
List<String> list=new ArrayList<String>();这种集合中就只能装String类型的数据。
然后我们可以提取出来然后用一个String类型的变量来承接这个数据。
javaAPI文档中后面某个类后面只要有那个尖括号,你就可以用泛型。
class MyName implements Comparable<MyName mn>{
int age;
public int compareTo(MyName mn){
.......
}
}
我想谈谈泛型类和泛型方法。
泛型类我们在类名出用一个尖括号,定义一个泛型。我们将来用到这个类可能传入各种类型的参数。
public static class FX<T> {
private T ob; // 定义泛型成员变量
public FX(T ob) {
this.ob = ob;
}
public T getOb() {
return ob;
}
public void showTyep() {
System.out.println("T的实际类型是: " + ob.getClass().getName());
}
}
public static void main(String[] args) {
FX<Integer> intOb = new FX<Integer>(100);
intOb.showTyep();
System.out.println("value= " + intOb.getOb());
System.out.println("----------------------------------");
FX<String> strOb = new FX<String>("CSDN_SEU_Calvin");
strOb.showTyep();
System.out.println("value= " + strOb.getOb());
} public class Test3{
public static void main(String[] args) {
MyList<?> myList = new MyList();
myList.show("hello");
myList.show(123);
myList.show(new Date());
}
}
class MyList<T>{//用在类上
private T obj;
public T getObj() {
return obj;
}
public void setObj(T obj) {
this.obj = obj;
}
@SuppressWarnings("hiding")
public<T>void show(T obj){//用在方法上
System.out.println(obj);
}
}其中?是通配符
http://www.linuxidc.com/Linux/2013-10/90928.htm(这是一系列的关于泛型通配符的问题,感觉挺详细的。)
? 表示不确定的java类型。
T 表示java类型。
K V 分别代表java键值中的Key Value。
E 代表Element。
T 表示java类型。
K V 分别代表java键值中的Key Value。
E 代表Element。
http://blog.csdn.net/wingbin/article/details/8689460
扯点题外话,Comparable<T>接口
这个接口的作用是我们用来比较两个对象之间的大小。目前有好多类去实现了这个接口。
典型的有String、Integer、Date、Long等等,可以去API中查阅。
我们只要实现了这个接口,重写该接口唯一的方法compareTo(),就可以比较两个对象之间的大小。
该方法返回一个int类型的数,
如果返回负数,就说明该对象小于指定对象。
如果返回正数,就说明该对象大于指定对象。
0,就不解释了。
4、for-each遍历
part2中是一个数组对象,或者是带有泛性的集合.
part1定义了一个局部变量,这个局部变量的类型与part2中的对象元素的类型是一致的.
part3当然还是循环体.
foreach语句是java5的新特征之一,在遍历数组、集合方面,foreach为开发人员提供了极大的方便。
foreach语句是for语句的特殊简化版本,但是foreach语句并不能完全取代for语句,然而,任何的foreach语句都可以改写为for语句版本。
foreach并不是一个关键字,习惯上将这种特殊的for语句格式称之为“foreach”语句。从英文字面意思理解foreach也就是“for 每一个”的意思。实际上也就是这个意思。
part1定义了一个局部变量,这个局部变量的类型与part2中的对象元素的类型是一致的.
part3当然还是循环体.
foreach语句是java5的新特征之一,在遍历数组、集合方面,foreach为开发人员提供了极大的方便。
foreach语句是for语句的特殊简化版本,但是foreach语句并不能完全取代for语句,然而,任何的foreach语句都可以改写为for语句版本。
foreach并不是一个关键字,习惯上将这种特殊的for语句格式称之为“foreach”语句。从英文字面意思理解foreach也就是“for 每一个”的意思。实际上也就是这个意思。
foreach还有一定的局限性,比如说不可以用for循环赋值。
5、Collection接口和Map接口来自哪个包
它们来自java.util包中,这题竟然能错。
6、关于Set接口和List接口
Set接口是无顺序、不重复的
List接口是有顺序可重复的。
7、浅谈Map中HashMap、TreeMap、Hashtable实现类
我们知道Map中的键值对,键不可重复,而值却是可以重复的。
AbstractMap, Attributes, AuthProvider, ConcurrentHashMap, EnumMap,
HashMap,
Hashtable, IdentityHashMap, LinkedHashMap, PrinterStateReasons, Properties, Provider, RenderingHints, TabularDataSupport,
TreeMap, UIDefaults, WeakHashMap
蓝色字体的是Map接口的其中三个实现类。
蓝色字体的是Map接口的其中三个实现类。
HashMap,基于
哈希表的实现(),
键
不可以可重复。如果出现两个数据项的键相同,那么先前散列映射中的键-值对将被替换,并且返回回去,你爱接不接。HashMap的键是根据它的HashCode值来存储数据,可以根据键值获取它的值。又很快的访问速度,其中键最多只能有一个null值,而它的值却可以有多个null,HashMap不支持线程同步,比较抽象哈,我也是这样认为的。就是同时可以有多个线程同时往里面写键值对、读键值对啊,那有人就要问了,我给它加一把锁不就完了,是不是傻啊你,这个方法已经在java.util包里面了,已经深入jdk的骨髓了,你咋写啊,你写了谁用啊。
如果你要是想实现同步,咋办呢?可以用Collections的synchronizedMap方法是HashMap具有同步的能力。(这个我们待会儿再谈。)
咳咳,讲完了HashMap,我们参照它来讲一讲我们的Hashtable,它俩主要有以下六点的不同。
1、Hashtable的方法是同步的,不信啊,不信自己查API文档去啊。HashMap未经同步,所以在多线程场合要手动同步HashMap这个区别就像Vector和ArrayList一样。 (这里ArrayList也不是同步的,这句话理解起来好复杂,因为我也是copy的。这里的Vector的父亲是AbstractList<E>类,它爷爷是AbstractCollection<E>类,它太爷爷是Collection<E>接口,它太奶奶是Iterator<E>接口,我这里的讲解其实比较片面,具体可以去查API文档。
Vector 类可以实现可增长的对象数组。与数组一样,它包含可以使用整数索引进行访问的组件,但是,Vector 的大小可以根据需要增大或缩小,以适应创建 Vector 后进行添加或移除项的操作。Vertor是同步的。
)
2、HashTable不允许null值,key和value都不可以,HashMap允许null值,key和value都可以。HashMap允许key值只能由一个null值,因为hashmap如果key值相同,新的key, value将替代旧的。
3、HashTable有一个contains(Object value)功能和containsValue(Object value)功能一样。众所周知,Map接口有containsKey(Object key)和containsValue(Object value)两个方法。但是HashTable接口独开小灶,又自定义了一个方法contains(Object value)方法。
4、Hashtable使用Enumeration接口,HashMap使用Iterator。
boolean | hasMoreElements()测试此枚举是否包含更多的元素。 |
E | nextElement()如果此枚举对象至少还有一个可提供的元素,则返回此枚举的下一个元素。 |
Enumeration<V> | elements()返回此哈希表中的值的枚举。 |
Enumeration<K> | keys()返回此哈希表中的键的枚举。 |
注:此接口的功能与 Iterator 接口的功能是重复的。此外,Iterator 接口添加了一个可选的移除操作,并使用较短的方法名。新的实现应该优先考虑使用 Iterator 接口而不是 Enumeration 接口。 (摘自API文档)
5、HashTable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。
6、哈希值的使用不同,HashTable直接使用对象的hashCode。
TreeMap类
能够把它保存的记录根据键排序,默认是按升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。
你理解起来是不是比较麻烦呢?其实我理解起来也很麻烦,为啥,因为我也是个java小白在遨游于java编程的海洋中,好吧,也可以说是煎熬,开个玩笑。
class HashMaps
{
public static void main(String[] args)
{
Map map=new HashMap(); map.put(“a”, “aaa”);
map.put(“b”, “bbb”);
map.put(“c”, “ccc”);
map.put(“d”, “ddd”);
Iterator iterator = map.keySet().iterator();
while (iterator.hasNext()) {
Object key = iterator.next();
System.out.println(“map.get(key) is :”+map.get(key));
}
Hashtable tab=new Hashtable();
tab.put(“a”, “aaa”);
tab.put(“b”, “bbb”);
tab.put(“c”, “ccc”);
tab.put(“d”, “ddd”);
Iterator iterator_1 = tab.keySet().iterator();
while (iterator_1.hasNext()) {
Object key = iterator_1.next();
System.out.println(“tab.get(key) is :”+tab.get(key));
}
TreeMap tmp=new TreeMap();
tmp.put(“a”, “aaa”);
tmp.put(“b”, “bbb”);
tmp.put(“c”, “ccc”);
tmp.put(“d”, “ddd”);
Iterator iterator_2 = tmp.keySet().iterator();
while (iterator_2.hasNext()) {
Object key = iterator_2.next();
System.out.println(“tmp.get(key) is :”+tmp.get(key));
}
}
}
=========map=========
map.get(key) is :ddd
map.get(key) is :bbb
map.get(key) is :ccc
map.get(key) is :aaa
=========Hashtable=========
tab.get(key) is :bbb
tab.get(key) is :aaa
tab.get(key) is :ddd
tab.get(key) is :ccc
=========TreeMap=========
tmp.get(key) is :aaa
tmp.get(key) is :bbb
tmp.get(key) is :ccc
tmp.get(key) is :dddhttp://www.cnblogs.com/liunanjava/p/4515688.html(摘自此)
TreeMap<K,V>()按照关键字key的大小顺序来对键-值对进行升序排序,key的顺序是按其字符串表示的字典顺序。
TreeMap<K,V>(Comparator<K> comp)关键字key的大小顺序按照Comparator接口规定的大小顺序对树映射中的键-值对进行排序,即可以升序,也可以降序,取决于里面重写的方法。
摘自http://blog.csdn.net/u013159040/article/details/45575327(还算详细吧。)
http://blog.sina.com.cn/s/blog_78efec1501019v62.html(对几种集合的排序问题的博客)
8、Collections类浅谈
其实在之前看马士兵java基础视频时就已经了解了这个类,但是后来我又把它给忘了。今天算是一个小小的复习吧,记住有这么一个类,你是不是之前把它看成了Collection接口,
此类完全由在 collection 上进行操作或返回 collection 的静态方法组成。
static
| addAll(Collection<? super T> c, T... a)将所有指定元素添加到指定 collection 中。 | |
static
| binarySearch(List<? extendsComparable<? super T>> list, T key)使用二进制搜索算法来搜索指定列表,以获得指定对象。 | |
static
| binarySearch(List<? extends T> list, T key,Comparator<? super T> c)使用二进制搜索算法来搜索指定列表,以获得指定对象。 | |
你是不是不太懂那个?extends T,叫你好好看前面的通配符那个博客链接你不看,其实我也不太懂,我才看一遍,待会再看。这不是我要说的重点啊,重点是我不可能把所有方法都列出来,所以还是要养成自己查API的习惯。
下面才是我真正要说的重点了,之前不是说过将那个实现那些集合类的同步问题了吗?!
static
| synchronizedCollection(Collection<T> c)返回由指定 collection 支持的同步(线程安全的)collection。 | |
static
| synchronizedList(List<T> list)返回由指定列表支持的同步(线程安全的)列表。 | |
static
| synchronizedMap(Map<K,V> m)返回由指定映射支持的同步(线程安全的)映射。 | |
static
| synchronizedSet(Set<T> s)返回由指定 set 支持的同步(线程安全的)set。 | |
static
| synchronizedSortedMap(SortedMap<K,V> m)返回由指定有序映射支持的同步(线程安全的)有序映射。 | |
static
| synchronizedSortedSet(SortedSet<T> s)返回由指定有序 set 支持的同步(线程安全的)有序 set。 |
9、装载因子
在java语言中,通过负载因子(load factor)来决定何时对散列表进行再
散列.例如:如果负载因子是0.75,当散列表中已经有75%的位置已经放满,
那么将进行散列.
负载因子越高(越接近1.0),内存的使用率越高,元素的寻找时间越长.
负载因子越低(越接近0.0),元素的寻找时间越短,内存浪费越多.
HashSet类的缺省负载因子是0.75.
散列.例如:如果负载因子是0.75,当散列表中已经有75%的位置已经放满,
那么将进行散列.
负载因子越高(越接近1.0),内存的使用率越高,元素的寻找时间越长.
负载因子越低(越接近0.0),元素的寻找时间越短,内存浪费越多.
HashSet类的缺省负载因子是0.75.
摘选自http://tanrishou.blog.163.com/blog/static/150250200807101210762/(我感觉这是一篇很不错的博客,但是有点冗长乏味,是重点的地方没有凸显出重点。)
http://blog.csdn.net/hguisu/article/details/6155636(异常处理,牛)
线程篇
1、线程优先级
java线程优先级是说明高优先级的线程具有更高几率得到执行,低优先级的也可能有机会得到执行。
一般线程默认优先级是5
通过Thread的
getPriority
()方法可以获取优先级,该方法是终态的,不可重写。
通过Thread的setPriority()方法可以设置线程的优先级,该方法是终态的,不可重写。
2、基于哈希表的 Map 接口的实现之HashMap类
哈希表:我的理解就是根据一对关键字码(key-value),有一个函数,将key代入函数,我们就可以得到一个地址,通过这个地址找到一个数组中的位置,从而得到value值,
这个数组叫做哈希表(也叫散列表),那个函数叫做哈希函数。
3、interrupt()方法会抛出SecurityException异常,但该异常是RuntimeException异常的子类。可捕获也可不捕获。
4、线程重要方法简介。
sleep()方法,让线程休眠一定时间,抛出InterruptedException异常,不放线程锁,就是一个方法有锁的话,它是不会放的,其它线程依然不可访问该方法。
join()方法,那个线程调用了该方法,必须要等到该线程执行完毕才可以,抛出InterruptedException异常
yield()方法,该方法是让出执行的机会,让有同等优先级的线程具有执行的机会,该方法是静态的。
wait()方法,该方法让调用它的线程陷入阻塞状态,并且放开线程锁,等待notify()/notifyAll()方法去唤醒该线程,也可以设置一定的睡眠时间。
interrupt()方法,中断线程。http://blog.csdn.net/wxwzy738/article/details/8516253
5、线程家族的那点关系。
Runnable接口,该接口有几个实现类AsyncBoxView.ChildState, FutureTask, RenderableImageProducer,Thread, TimerTask 。
TimerTask类具有计时的功能。
Thread类线程类,它的构造方法中传入了一个Runnable接口引用。该线程中有关于线程处理的很多方法
6、Thread和Runnable接口都是在java.lang包中的,所以使用时不需要引入。
7、同步块时更好的选择,因为它不会锁住整个对象(当然你也可以让它锁住整个对象)。同步方法会锁住整个对象,哪怕这个类中有很多不相关联的同步块,这通常会导致他们停止执行并需要等待获得这个对象上的锁。
8、volatile关键字去修饰变量的时候,所有线程都会直接读取该变量并且不缓存它。这确保了线程读取到的变量是同内存中是一致的。
http://www.cnblogs.com/aigongsi/archive/2012/04/01/2429166.html
IO篇
1、Java输入/输出流包括字节流、字符流、文件流以及管道流。
字节流是一个字节一个字节的进行操作。
字符流是一个字符一个字符的进行操作。
文件流是直接对文件进行的操作。
管道流也就是处理流。在原始操作流的外面在套一层流,对其进行处理。















 6016
6016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









