







关于用shell处理两Excel的方法。
方法一思路:
1、先把
两Exce中的列数据转为txt文件如附件中的a.txt,b.txt
2、对
a.txt,b.txt进行数据处理见方法一种的cat函数
3、在利用comm函数进行比较
另外可用数据库的思想(利用ODBC导入器把数据导入到数据库中)进行解决,前提都是需要对数据的去重和唯一处理(有重复数据在作in操作的时候,若求两交集的时候,以a.txt为基准和以b.txt为基准数据会不一样,造成数据不一致的问题;不同的数据也会多算数据的个数)。
在这里写个处理的例子:
a.txt:
20110225
20110224
20110228
20110301
20110302
b.txt:
20110228
20110301
20110302
20110303
20110304
方法1:
cat a.txt | sort | uniq > a_u.txt #排序,唯一数据处理
cat b.txt | sort | uniq > b_u.txt #排序,唯一数据处理
comm a_u.txt b_u.txt #显示 1-2-3列的结果
comm a_u.txt b_u.txt > c.txt #显示 1-2-3列的结果,并在c.txt中输出
comm -23 a_u.txt b_u.txt > c.txt #在a中有,在b中没有(显示1结果)
方法2:
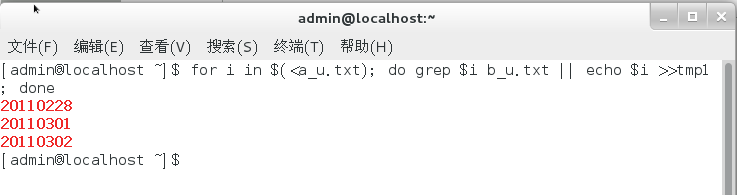
for i in $(<a_u.txt); do grep $i b_u.txt || echo $i >>tmp1 ; done
#显示a_u.txt与b_u.txt中相同行
方法3:
grep -wf a_u.txt b_u.txt #输出a_u.txt与b_u.txt 相同行
grep -wvf a_u.txt b_u.txt #输出b_u.txt有,a_u.txt没有 ,同comm -13
方法4:
awk '{print $0}' a_u.txt b_u.txt |sort|uniq -u ##输出a_u.txt与b_u.txt 不同行
其他方法如diff,cut,perl的模块化处理等方法
附件:
方法一截图:

方法2截图:
方法三截图:

方法四截图:
















 1210
1210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









