







Flink是标准的实时流处理框架,相较于SparkStreaming,Flink是基于事件驱动的,即每一个事件发生就会进行一次处理;
Flink流处理通过构建流处理环境对象StreamExecutionEnvironment进行,Flink同时也提供批处理环境对象ExecutionEnvironment,两者使用方面差别不大,下面将重点以StreamExecutionEnvironment为例演示各项功能。
入门案例
下面使用Flink监听指定IP端口发送的数据,对获取的数据进行词频统计,结果打印在控制台上
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
object WordCount {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val socketStream: DataStream[String] = env.socketTextStream("192.168.226.10", 7777)
val resultDataStream: DataStream[(String, Int)] = socketStream.flatMap(_.split("\\s+"))
.filter(_.trim.length > 0)
.map((_, 1))
.keyBy(0)
.sum(1)
resultDataStream.print("WC")
env.execute("WordCount")
}
}
在指定IP的主机上,使用netcat发送数据,观察结果:

在上述案例中,首先通过StreamExecutionEnvironment的getExecutionEnvironment方法获取了流处理对象,通过流处理对象的socketTextStream方法监控指定IP端口的数据(获取数据流DataStream),经过一些列操作转换为单词和对应出现次数后,调用print方法输出到了控制台。
注意,代码编写到这个位置时,只是制定了获取数据后的运行逻辑,程序既没有去监听指定IP端口,更没有去获取数据进行处理。需要调用execute方法后,程序才会按照设定好的逻辑开始运行。
Source
Flink用于获取数据的API,Flink提供了一些基础的数据获取方式,例如上述案例中的中指定IP端口获取、从集合中获取(fromCollection)、从文件中读取(readFile和readTextFile)等;
除了这些基础数据读取方式外,Flink也提供了连接常用数据存储/中间件的API,例如:Kafka、Elasticsearch、Redis和ActiveMQ等框架。


下面演示如何从Kafka中读取数据:
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011
import org.apache.kafka.clients.consumer.ConsumerConfig
object KafkaSource {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val pro = new Properties()
pro.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.226.10:9092")
pro.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer")
pro.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer")
pro.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "test_read_1")
val kafkaStream: DataStream[String] = env.addSource(new FlinkKafkaConsumer011[String](
"FlinkDemo",
new SimpleStringSchema(),
pro
))
kafkaStream.print()
env.execute()
}
}
效果演示:

除了预定的数据源外,我们也可以自定义数据源,可以看到addSource函数需要传入的是一个SoruceFunction对象,所以我们自定义的数据源类需要继承SoruceFunction类
下面仍以读取kafka为例,演示如何自定义数据源:
import java.util
import java.util.{Collections, Properties}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.source.{RichSourceFunction, SourceFunction}
import org.apache.flink.streaming.api.scala._
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord, ConsumerRecords, KafkaConsumer}
object MySource {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val kafkaStream: DataStream[Student] = env.addSource(KafkaSource)
kafkaStream.print("MyKafkaSource")
env.execute()
}
private object KafkaSource extends RichSourceFunction[Student] {
var flag: Boolean = true
var consumer: KafkaConsumer[String, String] = _
override def open(parameters: Configuration): Unit = {
val pro = new Properties()
pro.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.226.10:9092")
pro.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer")
pro.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer")
pro.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false")
pro.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest")
pro.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "MyKafkaSource_Read_1")
consumer = new KafkaConsumer(pro)
consumer.subscribe(Collections.singletonList("MyKafkaSource"))
}
override def run(ctx: SourceFunction.SourceContext[Student]): Unit = {
while (flag) {
val records: ConsumerRecords[String, String] = consumer.poll(100)
val iter: util.Iterator[ConsumerRecord[String, String]] = records.iterator()
while (iter.hasNext) {
val fields: Array[String] = iter.next().value().toString.split(",")
ctx.collect(Student(fields(0).toInt, fields(1), fields(2)))
}
}
}
override def cancel(): Unit = {
flag = false
consumer.close()
}
}
case class Student(id: Int, name: String, gender: String)
}
案例演示:

可以看到,当我们按照规定的格式输入字符串时,字符串将被转化成Student类型输出到控制台
上面KafkaSource类继承的RichSourceFunction类实际上是SourceFunction接口的一个实现类

Flink中每个Function都有对应的RichFunction(富函数),相较于普通函数,富函数拥有函数调用的上下文对象,并且拥有完整的证明周期,可以调用open等方法,用于实现更加复杂的功能。
在上述案例中,如果我们直接使用SourceFunction接口的实现类,就会由于KafkaConsumer构建过程中的某些类无法序列化而出现异常。
Transform
TransformOperator是中间对数据进行操作的算子,是程序的核心部分。Flink的TransformOperator和Spark Streaming的转换算子大部分类似。下面演示几个不同的转换操作
案例数据:
sensor_1,1624864851297,37.57
sensor_2,1624864848789,36.58
sensor_3,1624864851281,43.83
sensor_4,1624864852102,39.85
sensor_5,1624864852032,38.85
sensor_6,1624864851939,36.05
sensor_7,1624864851628,40.37
sensor_5,1624864851538,38.69
sensor_2,1624864852451,41.80
sensor_1,1624864850952,35.71
准备工作:
import org.apache.flink.streaming.api.scala._
object TransformOperator_1 {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val source: DataStream[String] = env.readTextFile("resources/sensor_record.txt")
val sensorStream: DataStream[SensorReading] = source.filter(_.matches("^sensor_\\d{1},\\d{13},\\d{2}\\.\\d{2}"))
.map(line => {
val fields: Array[String] = line.split(",")
SensorReading(fields(0), fields(1).toLong, fields(2).toDouble)
})
env.execute()
}
}
case class SensorReading(id: String, timeStamp: Long, temperature: Double)
keyBy
拿到上述的sensorStream,发现DataStream中是没有groupBy操作的,Flink中的分组使用keyBy完成。keyBy函数有四种使用方式:
// 使用索引表示元素的位置,从0开始。注意:这种方式只能用于数据类型为元组的DataStream
sensorStream.keyBy(0)
// 使用元素名称表示
sensorStream.keyBy("id")
// 使用函数,根据返回值分组
sensorStream.keyBy(sensor => sensor.id)
// 使用KeySelector,逻辑和上面使用函数的一致
sensorStream.keyBy(new MySelector)
private class MySelector extends KeySelector[SensorReading, String] {
override def getKey(value: SensorReading): String = value.id
}
通过keyBy函数,获得的对象变成了KeyedStream,为DataStream的子类。除了继承来的函数外,KeyedStream中还包含许多聚合函数
def max(position: Int): DataStream[T]
def min(position: Int): DataStream[T]
def sum(position: Int): DataStream[T]
def maxBy(position: Int): DataStream[T]
def minBy(position: Int): DataStream[T]
def reduce(fun: (T, T) => T): DataStream[T]
这些函数的参数指定也可以用类似于keyBy的方式指定。
函数的调用比较简单,与SparkStreaming没太大区别。但是由于Flink是事件驱动的流处理,因此处理的结果会有些不同,下面以max和maxBy为例说明
max maxBy
上面的keyBy函数选择一种,获取KeyedStream
val keyedStream: KeyedStream[SensorReading, String] = sensorStream.keyBy(sensor => sensor.id)
接下来,取温度的最大值:
keyedStream.max("temperature")
.print
为了演示效果,我们不从文件中读取数据,改用端口发送或者kafka发送

可以看到,每当一条数据产生时,控制台也会对应输出一条数据,且温度仅记录已出现的最高值,但是无论新出现的数据温度是否高于已记录的最高值,timestamp属性记录的值都不会被更改。
如果希望记录最高温度,且记录最高温度出现的时间,这时就要用到maxBy函数:
keyedStream.maxBy("temperature")
.print()
效果演示:

在上面案例的基础上,如果我们希望保留最高的温度和最近的时间,即截至最后一条记录时的时间和最高温度,这时就需要使用reduce函数解决。
reduce
keyedStream.reduce((value1, value2) => SensorReading(
value1.id,
Math.max(value1.timeStamp, value2.timeStamp),
Math.max(value1.temperature, value2.temperature)
))
.print()
逻辑比较简单,就不演示效果了
分流与合流
split和select
split可以将一条数据流中的元素按照不同的条件打上不同的标签,而select则是从流中挑选出指定的标签形成一条新的数据流,两者配合使用便可以将一条数据流切分为多条数据流
使用案例:
import org.apache.flink.streaming.api.scala._
object SplitAndSelect {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val dataSource: DataStream[String] = env.socketTextStream("192.168.226.10", 7777)
val dataStream: DataStream[SensorReading] = dataSource.filter(_.matches("^sensor_\\d{1},\\d{13},\\d{2}\\.\\d{2}$"))
.map(line => {
val fields: Array[String] = line.split(",").map(_.trim)
SensorReading(fields(0), fields(1).toLong, fields(2).toDouble)
})
val splitStream: SplitStream[SensorReading] = dataStream.split(sensorReading => {
if (sensorReading.temperature > 37) Seq("High")
else if (sensorReading.temperature < 35) Seq("Low")
else Seq("Normal")
})
val highStream: DataStream[SensorReading] = splitStream.select("High")
val normalStream: DataStream[SensorReading] = splitStream.select("Normal")
val lowStream: DataStream[SensorReading] = splitStream.select("Low")
highStream.print("High")
normalStream.print("Normal")
lowStream.print("Low")
env.execute("SplitStream")
}
}

输入三条记录,可以看到按照输入数据的温度值分到了不同的数据流中
union和connect
两个函数的作用均为合并数据流,区别在于union要求合并的流数据类型完全一致,否则就会报错,但是union不限制合并的流条数。
而connect并不要求合并的流数据类型完全一致,而是在后面的map操作中将其转换为统一的格式。不过connect一次只能合并两条数据流。
下面演示union的用法(以上面获得的三条数据流为例)
// 三条流格式类型完全一致,可以顺利合流
highStream.union(normalStream,lowStream).print("union")
如果我们对上面的获取的流格式做了修改:
val normalStream: DataStream[(String, Long)] = splitStream.select("Normal")
.map(sensor=>(sensor.id,sensor.timeStamp))
现在,union就会报错了
再来看connect的用法:
val highStream: DataStream[SensorReading] = splitStream.select("High")
val normalStream: DataStream[(String, Long)] = splitStream.select("Normal")
.map(sensor => (sensor.id, sensor.timeStamp))
val lowStream: DataStream[SensorReading] = splitStream.select("Low")
highStream.print("High")
normalStream.print("Normal")
lowStream.print("Low")
val connectStream: ConnectedStreams[SensorReading, (String, Long)] = highStream.connect(normalStream)
connectStream.map(
sensor => sensor.toString,
tuple => tuple.toString()
).print("connect")
当highStream与normalStream连接后获得的对象是ConnectedStreams对象,一般情况下会调用map函数统一数值,ConnectedStreams对象的map函数与普通的map函数不同,需要传递两个函数:
def map[R: TypeInformation](fun1: IN1 => R, fun2: IN2 => R): DataStream[R]
在上述案例中,IN1就是SensorReading,IN2就是(String,Long),R为返回的数值类型。map就是将两个函数分别作用于两条流的元素上,使其返回统一的数值类型,最后的返回值又是普通的DataStream对象
Sink
与Source类似,Flink也提供了一些基础的Sink功能,例如writeToSocket(输出到指定端口)、print(输出到控制台)。
同时Flink也提供了将数据写回到其他框架(还是Source中的那些框架,详见官方文档)中的方法,下面仍以Kafka为例演示如何使用官方提供的API将数据写入到Kafka:
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer010
import org.apache.kafka.clients.producer.ProducerConfig
object KafkaSink {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val pro = new Properties()
pro.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"num01:9092")
env.fromCollection(Seq("one","two","three","four","five"))
.addSink(new FlinkKafkaProducer010[String]("FlinkDemo",new SimpleStringSchema(),pro))
env.execute()
}
}
效果演示:

整体过程和读取Kafka很类似,每运行一次程序,就会有五个单词被写入的对应主题中。
Flink也提供了自定义Sink的API,下面以写出到MySQL为例演示自定义Sink:
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.flink.streaming.api.scala._
object MySink {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.fromCollection(
Seq(
"1,zs,20",
"2,ls,18",
"3,ww,25",
"4,zl,21",
"5,tq,24"
)
).addSink(MySQLSink).setParallelism(1) // 重点:将并行度设为1
env.execute()
}
private object MySQLSink extends RichSinkFunction[String] {
var connection: Connection = _
var insertStatement: PreparedStatement = _
var updateStatement: PreparedStatement = _
override def open(parameters: Configuration): Unit = {
connection = DriverManager.getConnection(
"jdbc:mysql://192.168.226.10:3306",
"root",
"ok"
)
insertStatement = connection.prepareStatement("insert into test.stu(id,name,age) values(?,?,?)")
updateStatement = connection.prepareStatement("update test.stu set name = ?, age = ? where id =?")
}
override def invoke(value: String, context: SinkFunction.Context[_]): Unit = {
val fields: Array[String] = value.split(",")
updateStatement.setString(1, fields(1))
updateStatement.setInt(2, fields(2).toInt)
updateStatement.setInt(3, fields(0).toInt)
if (updateStatement.executeUpdate() == 0) {
insertStatement.setInt(1, fields(0).toInt)
insertStatement.setString(2, fields(1))
insertStatement.setInt(3, fields(2).toInt)
insertStatement.executeUpdate()
}
}
override def close(): Unit = {
if (updateStatement != null) updateStatement.close()
if (insertStatement != null) insertStatement.close()
if (connection != null) connection.close()
}
}
}
运行程序,可以看到5条数据顺利插入到了MySQL中
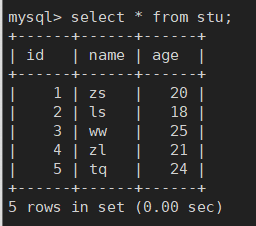
修改下要插入的数据:
Seq(
"1,zs,40",
"2,ls,38",
"3,ww,45",
"4,zl,41",
"5,tq,44"
)
重新运行,可以看到数据更新了:
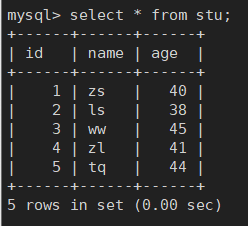















 757
757











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









