







了解GC,首先需要了解jvm,之前写过关于虚拟机的文章《Java虚拟机简单介绍》
其次就是了解设置jvm内存参数和设置方法,这也写过文章《jvm 常用调试工具和设置jvm GC方法和指令》 PermSize 永久代 NewSize 新生代 Xms Xmx 堆 Xss 栈
再者就是了解jvm中有几种GC以及启动方法,也有写过文章《java 基础知识部分提炼》;但是为什么jvm中有好几款GC呢?你可以这样思考:如果你是jvm的开发者,jvm中要嵌入自己的GC算法。你开发出来的jvm可能需要跑在单cpu的PC上,也有可能跑在多CPU集群的服务器上,也有可能被用来开发大型的应用,也有可能被用来开发单线程的命令行程序等等。那么不同的平台或者开发的软件类别不能一概而论的使用同一款,或者同一种算法的GC。那么这样太粗糙了!所以JVM中嵌入了几款不同GC,用户可以根据自己的需要强行设置自己的jvm GC方式。注意:安装了jre,跑了好几款不同的Java应用,那么就对应好几个jvm,那么要指定JVM指配GC方式。
在pc上cmd中设置GC类型:
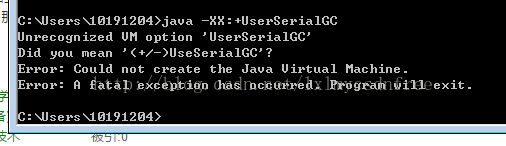
爆出没有启动的jvm,所以需要有运行的jvm,指定jvm设置GC类型。
在Tomcat 服务器上设置GC类型: 在tomcat的catalina.bat中设置启动参数
- set JAVA_OPTS=-Xms10240m -Xmx10240m -Xmn3000m -XX:PermSize=1024m -XX:MaxPermSize=2048m -XX:MaxNewSize=256m -Xss1024K -XX:-UseConcMarkSweepGC -XX:+ScavengeBeforeFullGC -XX:+PrintGC -XX:+PrintGCTimeStamps -Xloggc:"c:\gc_20121128.log"
-XX:+/- 解释:-XX: 是设置jvm命令符,后面的加号或者减号是表示增加或者去掉的意思。
今天的文章就是说说不同GC的工作大致原理。
基本的GC回收算法:
1. 引用计数(Reference Counting)
比较古老的回收算法。原理是此对象有一个引用,即增加一个计数,删除一个引用则减少一个计数。垃圾回收时,只用收集计数为0的对象。此算法最致命的是无法处理循环引用的问题。
2. 标记-清除(Mark-Sweep)
此算法执行分两阶段。第一阶段从引用根节点开始标记所有被引用的对象,第二阶段遍历整个堆,把未标记的对象清除。此算法需要暂停整个应用,同时,会产生内存碎片。
3. 复制(Copying)
此算法把内存空间划为两个相等的区域,每次只使用其中一个区域。垃圾回收时,遍历当前使用区域,把正在使用中的对象复制到另外一个区域中。次算法每次只处理正在使用中的对象,因此复制成本比较小,同时复制过去以后还能进行相应的内存整理,不过出现“碎片”问题。当然,此算法的缺点也是很明显的,就是需要两倍内存空间。
4. 标记-整理(Mark-Compact)
此算法结合了 “标记-清除”和“复制”两个算法的优点。也是分两阶段,第一阶段从根节点开始标记所有被引用对象,第二阶段遍历整个堆,把清除未标记对象并且把存活对象 “压缩”到堆的其中一块,按顺序排放。此算法避免了“标记-清除”的碎片问题,同时也避免了“复制”算法的空间问题。
5. 增量收集(Incremental Collecting)
实施垃圾回收算法,即:在应用进行的同时进行垃圾回收。不知道什么原因JDK5.0中的收集器没有使用这种算法的。
6. 分代(Generational Collecting)
基于对对象生命周期分析后得出的垃圾回收算法。把对象分为年青代、年老代、持久代,对不同生命周期的对象使用不同的算法(上述方式中的一个)进行回收。现在的垃圾回收器(从J2SE1.2开始)都是使用此算法的。
1. Young(年轻代)
年轻代分三个区。一个Eden区,两个 Survivor区。大部分对象在Eden区中生成。当Eden区满时,还存活的对象将被复制到Survivor区(两个中的一个),当这个 Survivor区满时,此区的存活对象将被复制到另外一个Survivor区,当这个Survivor去也满了的时候,从第一个Survivor区复制过来的并且此时还存活的对象,将被复制“年老区(Tenured)”。需要注意,Survivor的两个区是对称的,没先后关系,所以同一个区中可能同时存在从Eden复制过来对象,和从前一个Survivor复制过来的对象,而复制到年老区的只有从第一个Survivor去过来的对象。而且,Survivor区总有一个是空的。
2. Tenured(年老代)
年老代存放从年轻代存活的对象。一般来说年老代存放的都是生命期较长的对象。
3. Perm(持久代)
用于存放静态文件,如今Java类、方法等。持久代对垃圾回收没有显著影响,但是有些应用可能动态生成或者调用一些class,例如Hibernate等,在这种时候需要设置一个比较大的持久代空间来存放这些运行过程中新增的类。持久代大小通过-XX:MaxPermSize=<N>进行设置。
试想,如果是你写一个GC回收算法,你会思考怎么是实现呢?对于我,我认为我肯定是和“标记-清除”算法思维一样。纯粹的计数法太过于简单,搞不好数据就清除掉了。那么为什么会和“标记-清除”思维一样呢?Java里面所有的类都是继承于object,依次类推开发者每一次在内存中创建对象都是在以object的为根节点的父节点上创建。那么整个内存中所有的对象在数据关联方面就是一个很大的树结构。唯一做到的就是记录对象生存周期,那么只要记录比较一个父节点不可到达,或者声明结束,那么下面的子树结构都标记删除。但是这样做貌似在记录上很复杂。当然也可以在某一个子树结构执行完,不可到达的时候,将树的其他整体分支,copy出来,新建的整体树相当于砍去不可到达的结构之后的大树,每一次都发现有不可到达的就copy一次整体的树形结构。当内存不足的时候除了最后创建的整体树结构保留之外其他的都删除。但是这样貌似加大了内存消耗,内存消耗极快呀!你有好的思维发散吗?
对于不同的jvm(JVM种类多达几十种),GC一般大同小异,下面介绍的几种GC是传统较为标准的OracleJVM -- hotspot VM垃圾回收器。要知道很多公司只做jvm,有的jvm支持iOS系统,.net框架等(对的,有的jvm是针对支持iOS和.net)。针对不同平台如android、pc、服务器等有不同种类的jvm。
GC的种类:
新生代的GC:
新生代通常存活时间较短,因此基于Copying算法来进行回收,所谓Copying算法就是扫描出存活的对象,并复制到一块新的完全未使用的空间中,对应于新生代,就是在Eden和FromSpace或ToSpace之间copy。新生代采用空闲指针的方式来控制GC触发,指针保持最后一个分配的对象在新生代区间的位置,当有新的对象要分配内存时,用于检查空间是否足够,不够就触发GC。当连续分配对象时,对象会逐渐从eden到survivor,最后到旧生代,
用javavisualVM来查看,能明显观察到新生代满了后,会把对象转移到旧生代,然后清空继续装载,当旧生代也满了后,就会报outofmemory的异常,如下图所示:
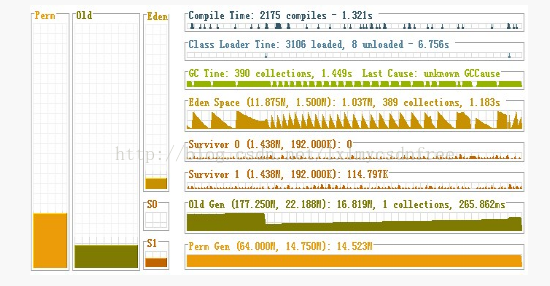
在执行机制上JVM提供了串行GC(SerialGC)、并行回收GC(ParallelScavenge)和并行GC(ParNew)
1)串行GC
在整个扫描和复制过程采用单线程的方式来进行,适用于单CPU、新生代空间较小及对暂停时间要求不是非常高的应用上,是client级别默认的GC方式,可以通过-XX:+UseSerialGC来强制指定
2)并行回收GC
在整个扫描和复制过程采用多线程的方式来进行,适用于多CPU、对暂停时间要求较短的应用上,是server级别默认采用的GC方式,可用-XX:+UseParallelGC来强制指定,用-XX:ParallelGCThreads=4来指定线程数
3)并行GC
与旧生代的并发GC配合使用
旧生代的GC:
旧生代与新生代不同,对象存活的时间比较长,比较稳定,因此采用标记(Mark)算法来进行回收,所谓标记就是扫描出存活的对象,然后再进行回收未被标记的对象,回收后对用空出的空间要么进行合并,要么标记出来便于下次进行分配,总之就是要减少内存碎片带来的效率损耗。在执行机制上JVM提供了串行GC(SerialMSC)、并行GC(parallelMSC)和并发GC(CMS),具体算法细节还有待进一步深入研究。
G1回收器:
1、并行于并发:G1能充分利用CPU、多核环境下的硬件优势,使用多个CPU(CPU或者CPU核心)来缩短stop-The-World停顿时间。部分其他收集器原本需要停顿Java线程执行的GC动作,G1收集器仍然可以通过并发的方式让java程序继续执行。
2、分代收集:虽然G1可以不需要其他收集器配合就能独立管理整个GC堆,但是还是保留了分代的概念。它能够采用不同的方式去处理新创建的对象和已经存活了一段时间,熬过多次GC的旧对象以获取更好的收集效果。
3、空间整合:与CMS的“标记--清理”算法不同,G1从整体来看是基于“标记整理”算法实现的收集器;从局部上来看是基于“复制”算法实现的。
4、可预测的停顿:这是G1相对于CMS的另一个大优势,降低停顿时间是G1和CMS共同的关注点,但G1除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为M毫秒的时间片段内,
5、G1运作步骤:1、初始标记;2、并发标记;3、最终标记;4、筛选回收














 460
460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









