







常用SPL简要笔记
1、query的基本格式
query 描述对原始日志的搜索条件,必须是管道的第一个命令。
语法:
[index=<index>] [starttime=<time-modifier>] [endtime=<time-modifier>] <query>
语法单元解释:
- index
- 参数:string
- 描述:指定所需搜索的索引,目前支持schedule, yotta,默认为yotta
- 示例:
index=schedule
- starttime
- 参数:<time-modifier>
- 描述:日志易支持的时间格式,表示搜索的时间区间的开始,包括该时间
- 示例:
starttime=2020-01-01:00:00:00
- endtime
- 参数:<time-modifier>
- 描述:日志易支持的时间格式,表示搜索的时间区间的结束,不包括该时间
- 示例:
endtime=2020-01-01:23:59:59 - 注意: 如果 query 中指定了 starttime 和 endtime ,则使用该时间区间,忽略页面中指定的时间区间。
保留字符
查询中包含以下保留字符,则需要进行转义,使用反斜杠转义。
+ - = && || > < ! ( ) { } [ ] ^ " ~ * ? : \ / |
由于空格是查询语句各个部分的分割符,如果查询语句包含空格也需要使用反斜杠转义。
多索引如何进行查询?
指定索引的时候,支持使用通配符*号和?号
示例如下:
-- 在所有myinde为前缀的索引返回包含myinfo的日志,比如myindex,myindeep索引等等
index=myinde* myinfo | ...
-- 不会查询schedule索引
index=* myinfo | ...
-- 查询schedule索引(内置索引)和其他用户指定索引
index=*,schedule myinfo | ...
-- 多个索引使用英文逗号分隔,中间不要包含空格
index=apache,nginx myinfo | ...
-- ip地址以10.开头,或者192.开头的所有日志
ip:10.* OR ip:192.* | ...
非统计查询的的最大返回结果数为1000用于页面展示,如果需要查全量数据,请下载当次搜索的数据查看,其对应的配置项为 query.max_result_count
2、append
一句话理解:将子查询的结果附加到主查询的结果之后。
语法:
append <sub-pipe>
示例代码:
-- 统计大前天和昨天的平均响应长度,将结果合并到一张表中
starttime="-3d/d" endtime="-2d/d" appname:dmz_nginx | stats avg(access.body_bytes_sent) | eval day="the day before yesterday" | append [[ starttime="-1d/d" endtime="now/d" appname:dmz_nginx | stats avg(access.body_bytes_sent) | eval day="yesterday" ]]
效果如下:

3、autoregress
一句话理解:将已有的列复制为新的列,列的向下偏移量必须≥1。
语法:
autoregress <field>[ as <as-field> ] p=<num> | <num>-<num>
关键参数:p ,将复制的列向下移 num 行。
示例代码:
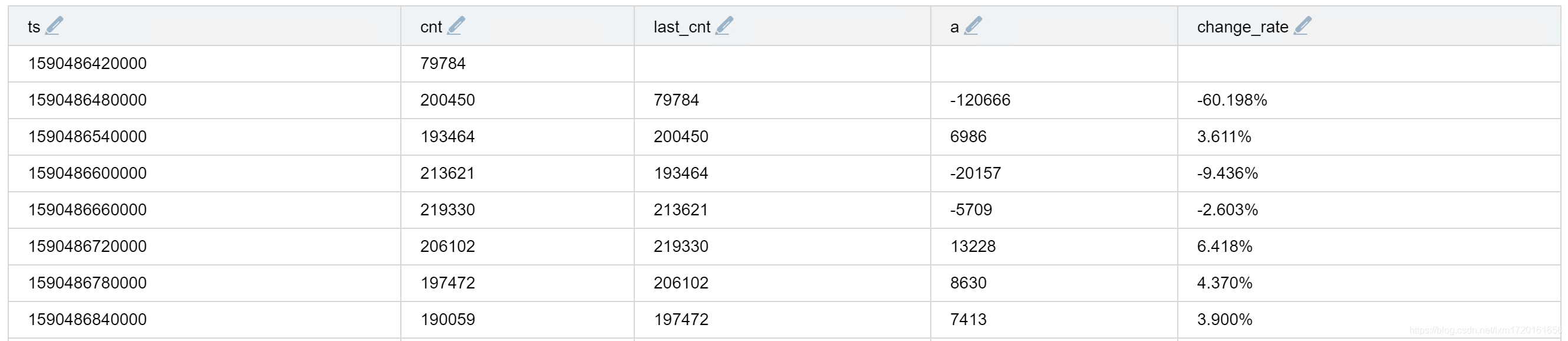
-- 计算当前分钟与上分钟的是建树变化比率
* | bucket timestamp span=1m as ts | stats count() as cnt by ts | autoregress cnt as last_cnt p=1 | eval a=(last_cnt - cnt) | eval change_rate=format("%.3f%%", (last_cnt - cnt)*100/cnt)
效果如下:
4、top
统计出现次数最多的前n个字段,并附带该字段的统计总数和百分比。
语法:
top <N> <field> [by <field-list>] [countfield=<field>] [percentfield=<field>]
示例代码:
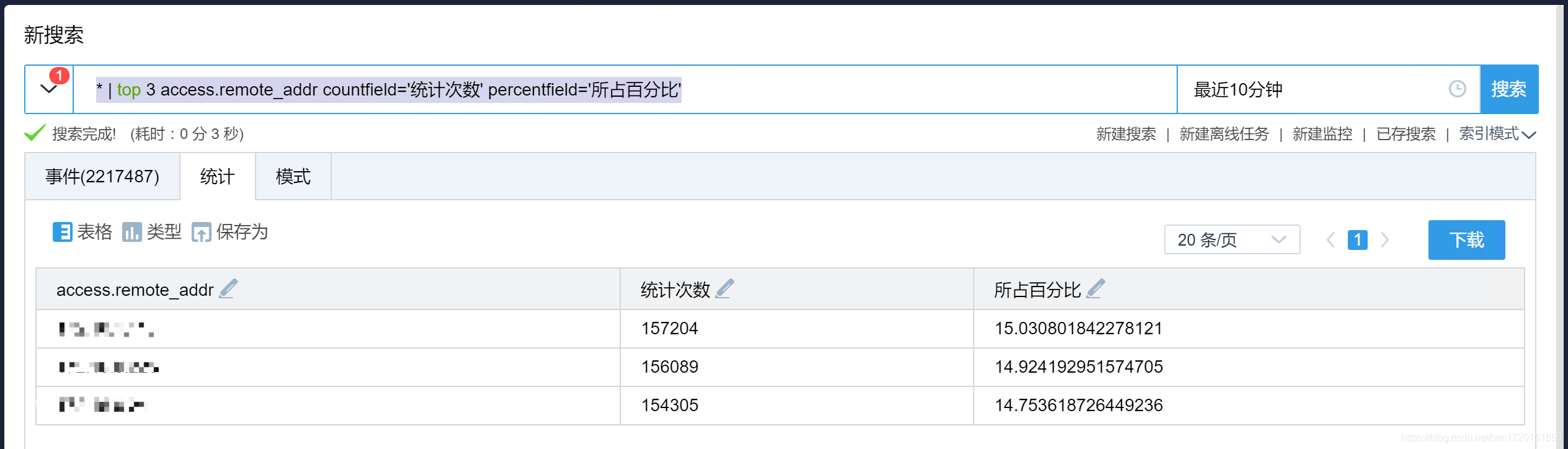
-- 返回 top 3 的 access.remote_addr ,同时返回该字段的统计出现次数和所占百分比
* | top 3 access.remote_addr
-- 可以指定统计出现次数(countfield=)和所占百分比名称(percentfield=)
* | top 3 access.remote_addr countfield='统计次数' percentfield='所占百分比'
效果如下:
5、by
分组关键字,常跟在统计函数后面
示例搜索:
-- 按 appname 进行分组进行统计
* | stats count() by appname
-- 按照 IP 来查找每个 IP 访问最多的3条日志
* | top 3 access.requestpath by access.remote_addr
6、limit
返回前 n 个结果
语法:
limit <number>
示例搜索:
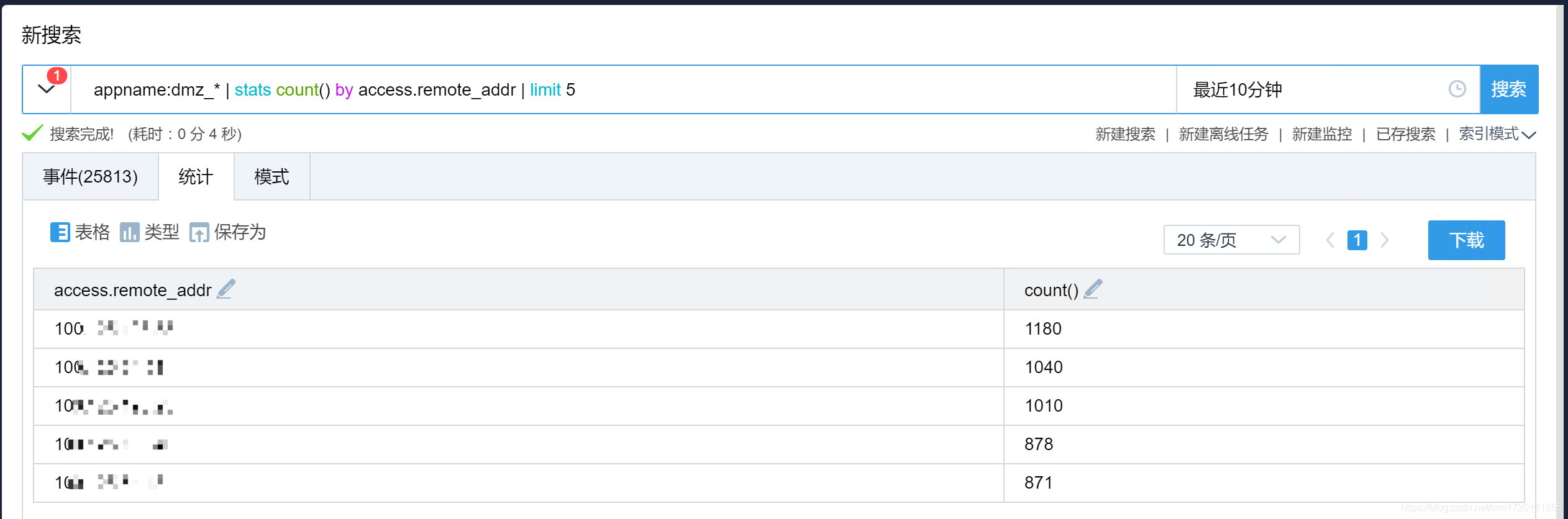
-- 对 stats 的结果仅保留前5条
appname:dmz_* | stats count() by access.remote_addr | limit 5
效果如下:
7、sort
按照指定字段对结果进行排序,默认为降序。
语法:
sort [<int>] by [(+|-)]<sort-by-field-list>
在字段前使用 + 或 - 指定排序方式。
示例搜索:
-- 按照 IP 来查找每个 IP 访问最多的3条日志,然后按 IP 进行排序
appname:dmz_* | top 3 access.requestpath by access.remote_addr | sort by access.remote_addr
-- 根据 appname 统计全部日志,按名称升序排序并只返回前6条
* | stats count() by appname | sort 6 by +appname
注意: 若指定 sort 返回的最大条数大于 200000 时会发生报错,对应配置项为sort.max_size;排序默认保留的条数为 10000 条,对应配置项为sort.maintain_size,若超过上述的值,多出部分的数据将会被丢弃。
8、rename
重命名字段
语法:
rename <src-field> as <dest-field> [<src-field> as <dest-field> ....]
示例使用:
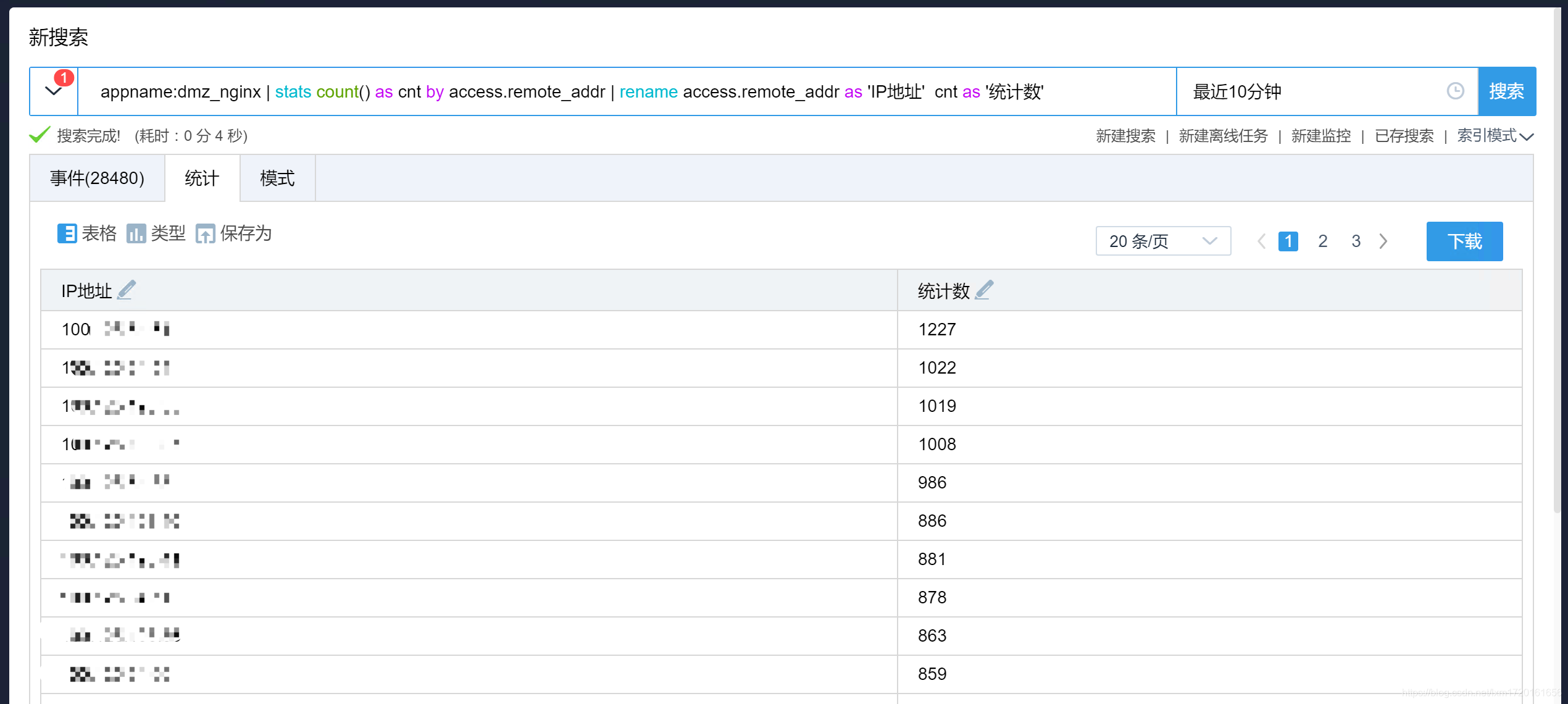
-- 修改字段名称
appname:dmz_nginx | stats count() as cnt by access.remote_addr | rename access.remote_addr as 'IP地址' cnt as '统计数'
效果如下:
9、fields
过滤字段并按照语句顺序排列字段,多个字段使用逗号分隔,支持通配符。
语法:
fields <field>[,field]
示例搜索:
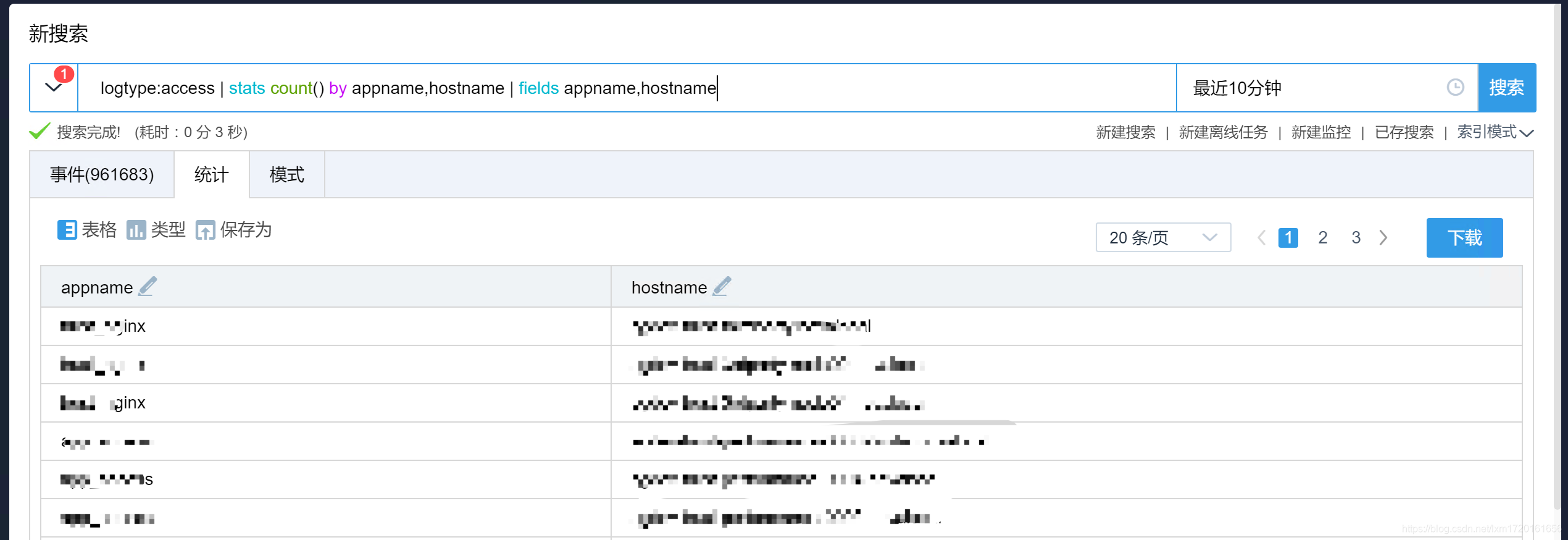
-- 仅保留 appname 和 hostname 字段
logtype:access | stats count() by appname,hostname | fields appname,hostname
-- 仅保留以 json.r 开头的字段
* | stats count() by json.acccess_name,json.uid,json.request_time,json.request_path,json.response_bytes_send | fields json.r*
效果如下:
10、table
利用字段来创建一张表格,一行其实就对于一条日志中的 n 个字段。
语法:
table <field>(,field)*
示例搜索:
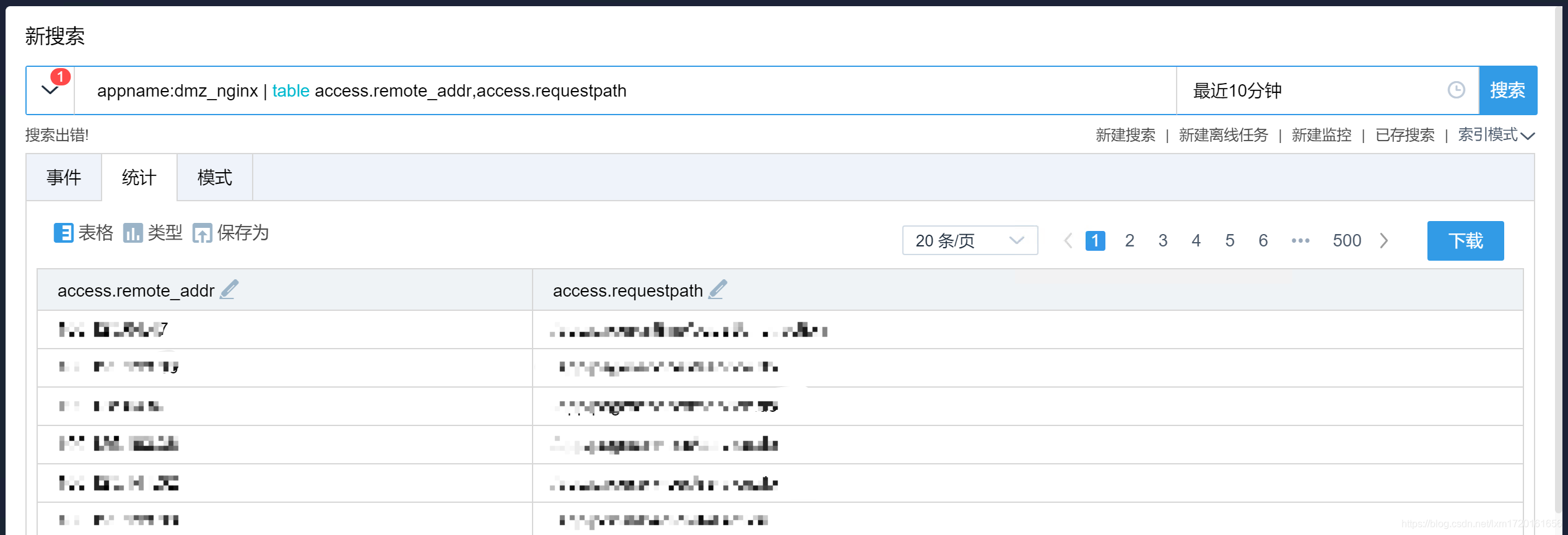
-- 使用每条日志的两个字段来创建一张表格
appname:dmz_nginx | table access.remote_addr,access.requestpath
效果如下:
11、parse
在搜索时对每条日志使用正则临时解析出新的字段
语法:
parse [field=<field>] "<regex>" [max_match=<int>]
示例搜索:
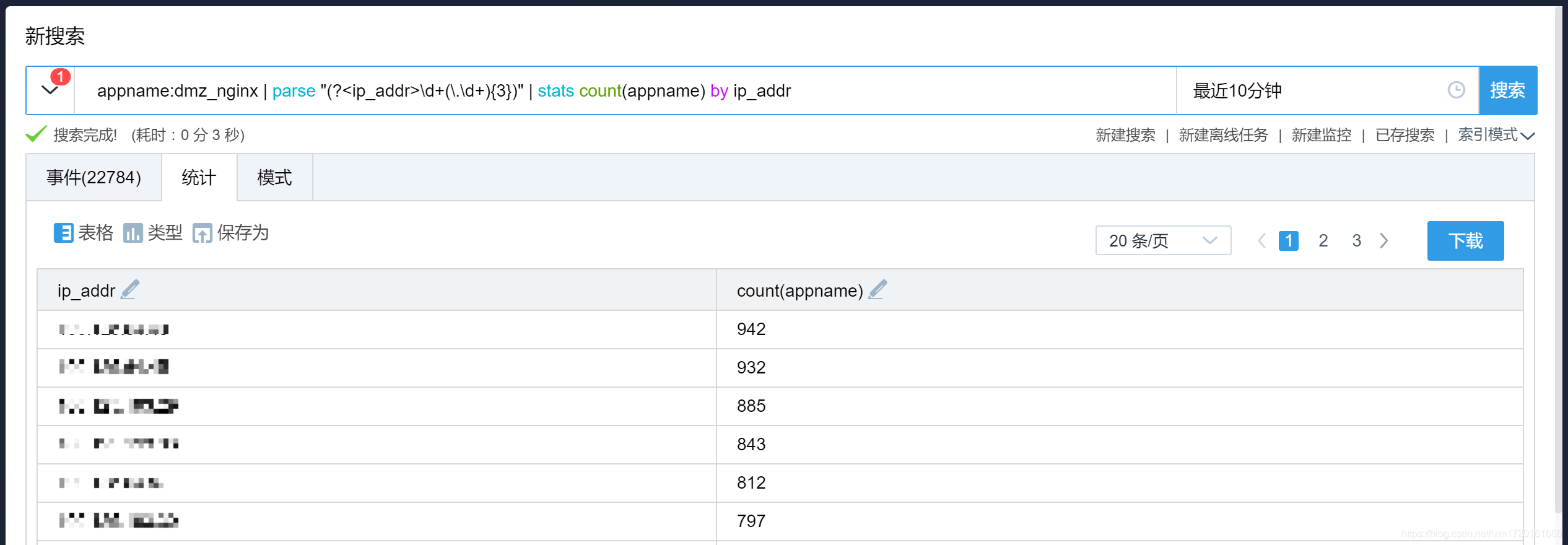
-- 提取 raw_message 中的 IP 地址并根据 appname 进行统计
appname:dmz_nginx | parse "(?<ip_addr>\d+(\.\d+){3})" | stats count(appname) by ip_addr
-- 从字段 access.requestpath 中提取一级路径并根据 appname 进行统计
appname:dmz_nginx | parse field=access.requestpath "(?<outer_path>/[^/]*)" | stats count(appname) by outer_path
效果如下:
12、eval
计算表达式并将生成的值,放入一个新的字段中(创建一个新的列并放入表达式的值)。
语法:
eval <eval-field>=<eval-expression>
示例搜索:
-- 可以使用等号直接复制一列
appname:dmz_nginx | stats count() as cnt by access.requestpath | eval '访问次数'=cnt
-- 使用表达式生成的值产生新的列,当然也可以进行数值的操作
appname:dmz_nginx | stats count() as cnt by access.requestpath | eval '访问次数'=access.requestpath+"_"+cnt
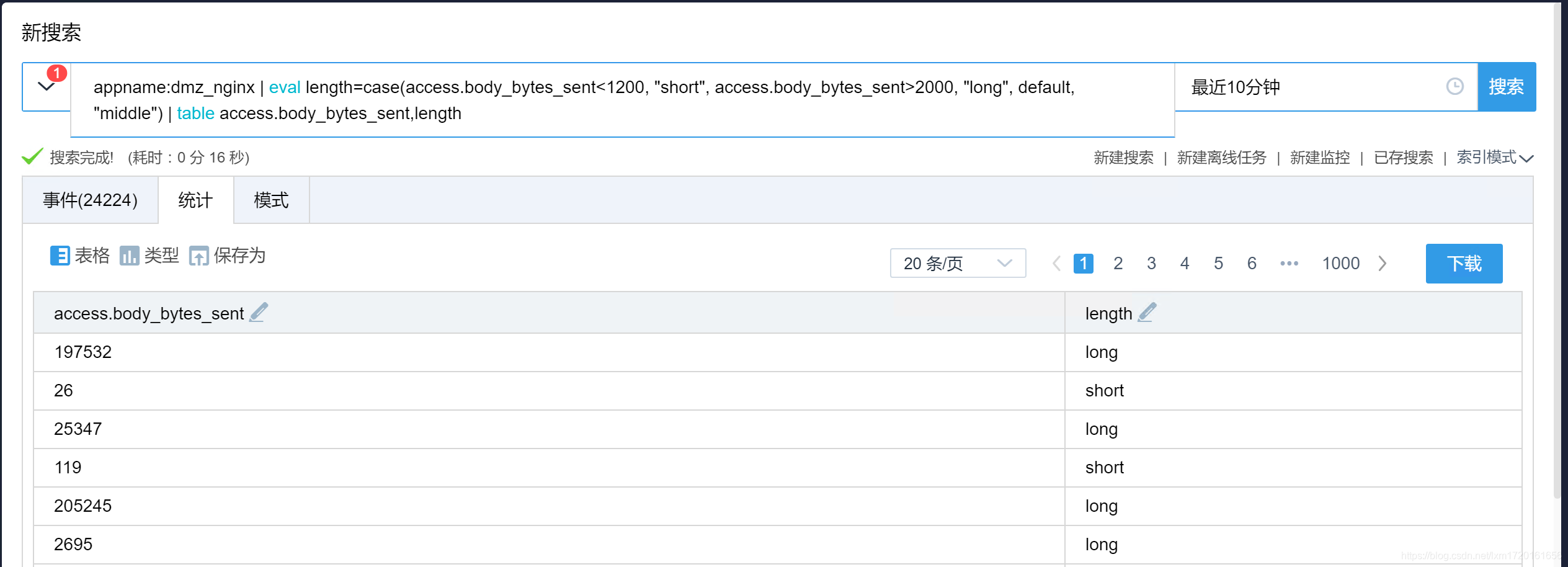
-- 对每条日志的 access.body_bytes_sent 字段进行分析并生成新的字段 length ,如果小于 1200 则 length 的值为“short”,如果大于 2000 则 length 的值为“long”,其他则为“middle”
appname:dmz_nginx | eval length=case(access.body_bytes_sent<1200, "short", access.body_bytes_sent>2000, "long", default, "middle") | table access.body_bytes_sent,length
效果如下:
eval支持的运算符与优先级
按照优先级 由高到低 排序
| 运算符 | 说明 |
|---|---|
| *、/、% | 算术乘,除,余,乘除支持数值类型 |
| +、- | 算术加减,支持数值类型,+另支持字符串 |
| >=、>、<=、 < | |
| !=、== | |
| && | (逻辑与)二元操作符,操作对象必须是布尔类型 |
| || | (逻辑或)二元操作符,操作对象必须是布尔类型 |
13、format() 函数
常用于对数值进行格式化















 4189
4189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









