







九、测试用例分层
在自动化测试领域,自动化测试用例的可维护性是极其重要的因素,直接关系到自动化测试能否持续有效地在项目中开展。
概括来说,测试用例分层机制的核心是将接口定义、测试步骤、测试用例、测试场景进行分离,单独进行描述和维护,从而尽可能地减少自动化测试用例的维护成本。
逻辑关系图如下所示:
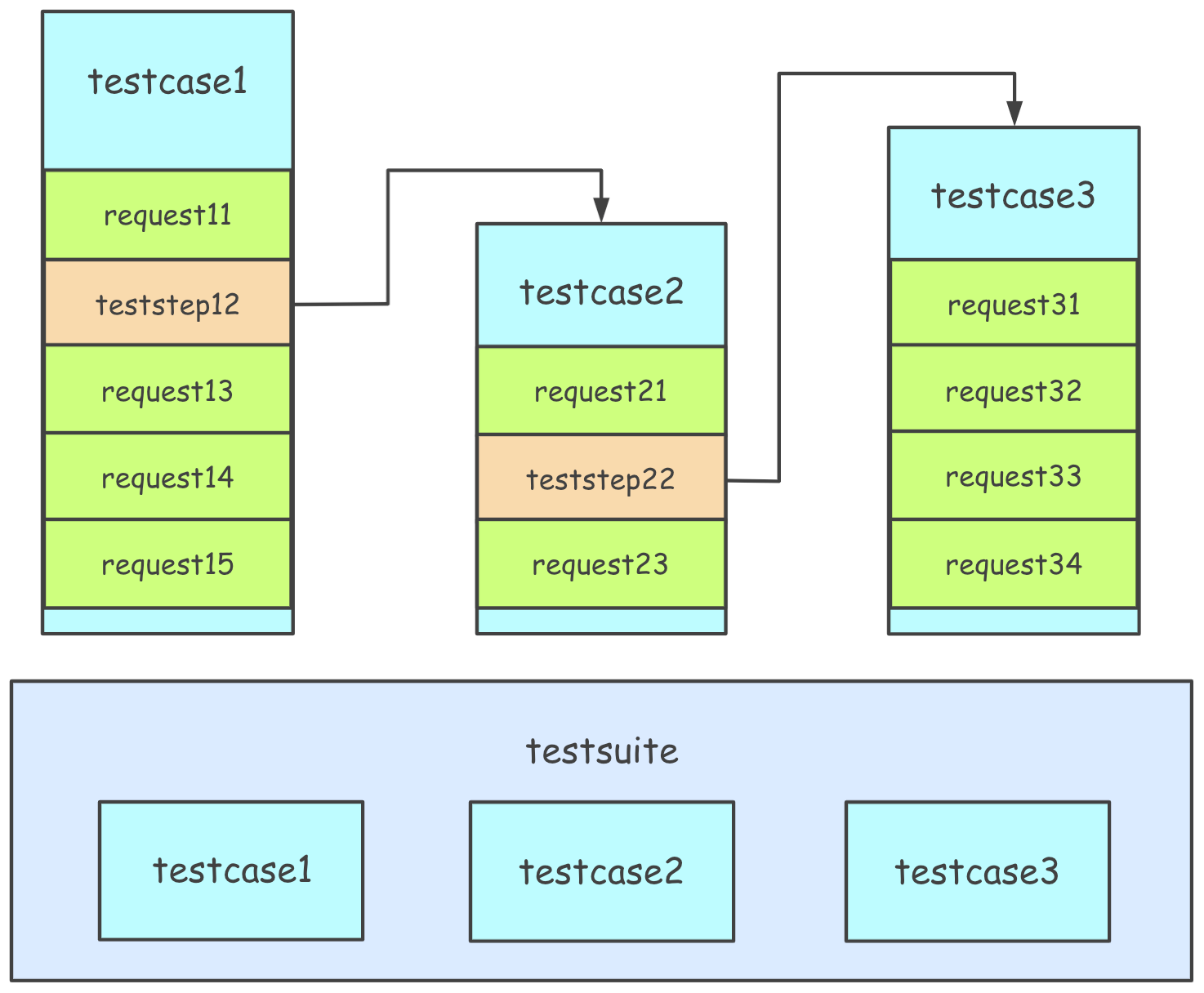
同时,强调如下几点核心概念:
- 测试用例(testcase)应该是完整且独立的,每条测试用例应该是都可以独立运行的
- 测试用例是测试步骤(teststep)的 有序 集合,每一个测试步骤对应一个 API 的请求描述
- 测试用例集(testsuite)是测试用例的 无序 集合,集合中的测试用例应该都是相互独立,不存在先后依赖关系的;如果确实存在先后依赖关系,那就需要在测试用例中完成依赖的处理
如果对于上述第三点感觉难以理解,不妨看下上图中的示例:
- testcase1 依赖于 testcase2,那么就可以在测试步骤(teststep12)中对 testcase2 进行引用,然后 testcase1 就是完整且可独立运行的;
- 在 testsuite 中,testcase1 与 testcase2 相互独立,运行顺序就不再有先后依赖关系了。
十、参数化数据驱动
在自动化测试中,经常会遇到如下场景:
- 测试搜索功能,只有一个搜索输入框,但有10种不同类型的搜索关键字;
- 测试账号登录功能,需要输入用户名和密码,按照等价类划分后有20种组合情况。
单个独立参数:例如前面的第一种场景,我们只需要变换搜索关键字这一个参数。
多个具有关联性的参数:例如登录场景,我们需要变换名用户和密码两个参数,并且这两个参数需要关联组合。
然后,对于参数而言,我们可能具有一个参数列表,在脚本运行时需要按照不同的规则去取值,例如顺序取值、随机取值、循环取值等。
这就是典型的参数化和数据驱动。
对于没有现成参数列表,或者需要更灵活的方式动态生成参数的情况,可以通过在 debugtalk.py 中自定义函数生成参数列表,并在 YAML/JSON 引用自定义函数的方式。
例如,若需对 user_id 进行参数化数据驱动,参数取值范围为 1001~1004,那么就可以在 debugtalk.py 中定义一个函数,返回参数列表。
def get_user_id():
return [
{"user_id": 1001},
{"user_id": 1002},
{"user_id": 1003},
{"user_id": 1004}
]对于具有关联性的多个参数,实现方式也类似。 例如,在debugtalk.py中定义函数get_account,生成指定数量的账号密码参数列表。
def get_account(num):
accounts = []
for index in range(1, num+1):
accounts.append(
{"username": "user%s" % index, "password": str(index) * 6},
)
return accounts十一、信息安全
很多时候项目代码在运行时需要使用到账号、密码、key等敏感数据信息,但是从信息安全的角度考虑,我们是不能将这些敏感数据提交到代码仓库的,主要原因有两个:
- 加强权限管控:参与项目的开发人员可能会有很多,大家都有读取代码仓库的权限,但是像 key 这类极度敏感的信息不应该所有人都有权限获取;
- 减少代码泄漏的危害性:假如代码出现泄漏,敏感数据信息不应该也同时泄漏。
那代码部署到服务器或 Jenkins 执行机后,运行时要使用到这些敏感数据信息,该怎么操作呢?
推荐的操作方式为:
- 对服务器进行权限管控,只有运维人员(或者核心开发人员)才有登录服务器的权限;
- 运维人员(或者核心开发人员):在运行的机器上将敏感数据设置到系统的环境变量中;
- 普通开发人员:只需要知道敏感信息的变量名称,在代码中通过读取环境变量的方式获取敏感数据。
十二、文件上传
对于上传文件类型的测试场景,HttpRunner 集成 requests_toolbelt 实现了上传功能。
在使用之前,确保已安装如下依赖库: * requests_toolbelt * filetype
使用内置 upload 关键字,可轻松实现上传功能(适用版本:2.4.1+)。















 2875
2875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









