







3,服务调用
10,Ribbon负载均衡:

Ribbon目前也进入维护,基本上不准备更新了

进程内LB(本地负载均衡)

集中式LB(服务端负载均衡)

区别

Ribbon就是负载均衡+RestTemplate



使用Ribbon:
1,默认我们使用eureka的新版本时,它默认集成了ribbon:

这个starter中集成了reibbon了
2,我们也可以手动引入ribbon
放到order模块中,因为只有order访问pay时需要负载均衡

3,RestTemplate类:


RestTemplate的:
xxxForObject()方法,返回的是响应体中的数据
xxxForEntity()方法.返回的是entity对象,这个对象不仅仅包含响应体数据,还包含响应体信息(状态码等)
Ribbon常用负载均衡算法:
IRule接口,Riboon使用该接口,根据特定算法从所有服务中,选择一个服务,
Rule接口有7个实现类,每个实现类代表一个负载均衡算法

使用Ribbon:
这里使用eureka的那一套服务

也就是不能放在主启动类所在的包及子包下
1,修改order模块
2,额外创建一个包

3,创建配置类,指定负载均衡算法

4,在主启动类上加一个注解

表示,访问CLOUD_pAYMENT_SERVICE的服务时,使用我们自定义的负载均衡算法
自定义负载均衡算法:
1,ribbon的轮询算法原理


2,自定义负载均衡算法:
1,给pay模块(8001,8002),的controller方法添加一个方法,返回当前节点端口
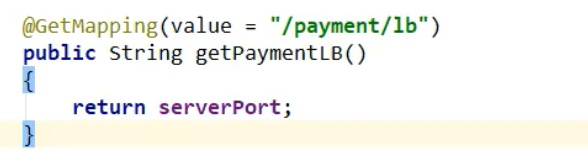

2,修改order模块
去掉@LoadBalanced

3,自定义接口

具体的算法在实现类中实现
4,接口实现类


5,修改controller:


6,启动服务,测试即可
11,OpenFeign

是一个声明式的web客户端,只需要创建一个接口,添加注解即可完成微服务之间的调用

就是A要调用B,Feign就是在A中创建一个一模一样的B对外提供服务的的接口,我们调用这个接口,就可以服务到B
Feign与OpenFeign区别

使用OpenFeign
之前的服务间调用,我们使用的是ribbon+RestTemplate
现在改为使用Feign
1,新建一个order项目,用于feign测试
名字cloud_order_feign-80
2,pom文件
3,配置文件

4,主启动类

5,fegin需要调用的其他的服务的接口
在80端口

下面这个是在provider中被调用的方法

6,controller

7测试:
启动两个erueka(7001,7002)
启动两个pay(8001,8002)
启动当前的order模块

Feign默认使用ribbon实现负载均衡
OpenFeign超时机制:
OpenFeign默认等待时间是1秒,超过1秒,直接报错
1,设置超时时间,修改配置文件:
因为OpenFeign的底层是ribbon进行负载均衡,所以它的超时时间是由ribbon控制

OpenFeign日志:

OpenFeign的日志级别有:

1,使用OpenFeign的日志:
实现在配置类中添加OpenFeign的日志类

2,为指定类设置日志级别:
监控如下这个接口

配置文件中:

3,启动服务即可
4,服务降级:
12,Hystrix服务降级



hystrix中的重要概念:
1,服务降级
比如当某个服务繁忙,不能让客户端的请求一直等待,应该立刻返回给客户端一个备选方案
这些情况会降级
- 程序运行异常
- 超时
- 服务熔断触发服务降级
- 线程池/信号量打满也会导致服务降级
2,服务熔断
当某个服务出现问题,卡死了,不能让用户一直等待,需要关闭所有对此服务的访问
然后调用服务降级
3,服务限流
限流,比如秒杀场景,不能访问用户瞬间都访问服务器,限制一次只可以有多少请求
使用hystrix,服务降级:
1,创建带降级机制的pay模块 :
名字: cloud-hystrix-pay-8007
2,pom文件
3,配置文件

4,主启动类

5,service

6,controller

7,先测试:
此时使用压测工具,并发20000个请求,请求会延迟的那个方法,
压测中,发现,另外一个方法并没有被压测,但是我们访问它时,却需要等待
这就是因为被压测的方法它占用了服务器大部分资源,导致其他请求也变慢了
8,先不加入hystrix,
2,创建带降级的order模块:
1,名字: cloud-hystrix-order-80
2,pom
3,配置文件

4,主启动类

5,远程调用pay模块的接口:

6,controller:

7,测试
启动order模块,访问pay
再次压测2万并发,发现order访问也变慢了

解决:


3,配置服务降级:
1,修改pay模块
1,为service的指定方法(会延迟的方法)添加@HystrixCommand注解

2,主启动类上,添加激活hystrix的注解

3,触发异常


可以看到,也触发了降级
2,修改order模块,进行服务降级
一般服务降级,都是放在客户端(order模块),

1,修改配置文件:
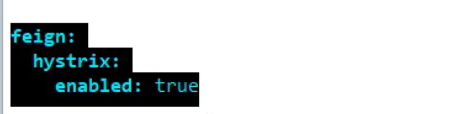
2,主启动类添加直接,启用hystrix:

3,修改controller,添加降级方法什么的

4,测试
启动pay模块,order模块,
注意:,这里pay模块和order模块都开启了服务降级
但是order这里,设置了1.5秒就降级,所以访问时,一定会降级
4,重构:
上面出现的问题:
1,降级方法与业务方法写在了一块,耦合度高
2.每个业务方法都写了一个降级方法,重复代码多
解决重复代码的问题:
配置一个全局的降级方法,所有方法都可以走这个降级方法,至于某些特殊创建,再单独创建方法
1,创建一个全局方法

2,使用注解指定其为全局降级方法(默认降级方法)


3,业务方法使用默认降级方法:

4,测试:

解决代码耦合度的问题:
修改order模块,这里开始,pay模块就不服务降级了,服务降级写在order模块即可
1,Payservice接口是远程调用pay模块的,我们这里创建一个类实现service接口,在实现类中统一处理异常

2,修改配置文件:添加:
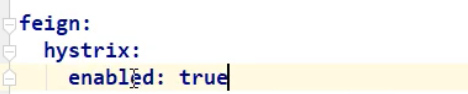
3,让PayService的实现类生效:

它的运行逻辑是:
当请求过来,首先还是通过Feign远程调用pay模块对应的方法
但是如果pay模块报错,调用失败,那么就会调用PayMentFalbackService类的
当前同名的方法,作为降级方法
4,启动测试
启动order和pay正常访问–ok
此时将pay服务关闭,order再次访问

可以看到,并没有报500错误,而是降级访问实现类的同名方法
这样,即使服务器挂了,用户要不要一直等待,或者报错
问题:
这样虽然解决了代码耦合度问题,但是又出现了过多重复代码的问题,每个方法都有一个降级方法
使用服务熔断:

比如并发达到1000,我们就拒绝其他用户访问,在有用户访问,就访问降级方法

1,修改前面的pay模块
1,修改Payservice接口,添加服务熔断相关的方法:

这里属性整体意思是:
10秒之内(窗口,会移动),如果并发超过10个,或者10个并发中,失败了6个,就开启熔断器

IdUtil是Hutool包下的类,这个Hutool就是整合了所有的常用方法,比如UUID,反射,IO流等工具方法什么的都整合了


断路器的打开和关闭,是按照一下5步决定的
1,并发此时是否达到我们指定的阈值
2,错误百分比,比如我们配置了60%,那么如果并发请求中,10次有6次是失败的,就开启断路器
3,上面的条件符合,断路器改变状态为open(开启)
4,这个服务的断路器开启,所有请求无法访问
5,在我们的时间窗口期,期间,尝试让一些请求通过(半开状态),如果请求还是失败,证明断路器还是开启状态,服务没有恢复
如果请求成功了,证明服务已经恢复,断路器状态变为close关闭状态

2,修改controller
添加一个测试方法;

3,测试:
启动pay,order模块
多次访问,并且错误率超过60%:

此时服务熔断,此时即使访问正确的也会报错:

但是,当过了几秒后,又恢复了
因为在10秒窗口期内,它自己会尝试接收部分请求,发现服务可以正常调用,慢慢的当错误率低于60%,取消熔断
Hystrix所有可配置的属性:
全部在这个方法中记录,以成员变量的形式记录,
以后需要什么属性,查看这个类即可
3,服务调用
10,Ribbon负载均衡:

Ribbon目前也进入维护,基本上不准备更新了

进程内LB(本地负载均衡)

集中式LB(服务端负载均衡)

区别

Ribbon就是负载均衡+RestTemplate



使用Ribbon:
1,默认我们使用eureka的新版本时,它默认集成了ribbon:

这个starter中集成了reibbon了
2,我们也可以手动引入ribbon
放到order模块中,因为只有order访问pay时需要负载均衡

3,RestTemplate类:


RestTemplate的:
xxxForObject()方法,返回的是响应体中的数据
xxxForEntity()方法.返回的是entity对象,这个对象不仅仅包含响应体数据,还包含响应体信息(状态码等)
Ribbon常用负载均衡算法:
IRule接口,Riboon使用该接口,根据特定算法从所有服务中,选择一个服务,
Rule接口有7个实现类,每个实现类代表一个负载均衡算法

使用Ribbon:
这里使用eureka的那一套服务

也就是不能放在主启动类所在的包及子包下
1,修改order模块
2,额外创建一个包

3,创建配置类,指定负载均衡算法

4,在主启动类上加一个注解

表示,访问CLOUD_pAYMENT_SERVICE的服务时,使用我们自定义的负载均衡算法
自定义负载均衡算法:
1,ribbon的轮询算法原理


2,自定义负载均衡算法:
1,给pay模块(8001,8002),的controller方法添加一个方法,返回当前节点端口

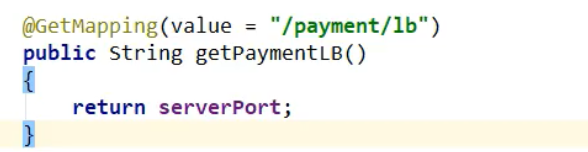
2,修改order模块
去掉@LoadBalanced

3,自定义接口

具体的算法在实现类中实现
4,接口实现类


5,修改controller:


6,启动服务,测试即可
11,OpenFeign

是一个声明式的web客户端,只需要创建一个接口,添加注解即可完成微服务之间的调用

就是A要调用B,Feign就是在A中创建一个一模一样的B对外提供服务的的接口,我们调用这个接口,就可以服务到B
Feign与OpenFeign区别

使用OpenFeign
之前的服务间调用,我们使用的是ribbon+RestTemplate
现在改为使用Feign
1,新建一个order项目,用于feign测试
名字cloud_order_feign-80
2,pom文件
3,配置文件

4,主启动类

5,fegin需要调用的其他的服务的接口
在80端口

下面这个是在provider中被调用的方法

6,controller

7测试:
启动两个erueka(7001,7002)
启动两个pay(8001,8002)
启动当前的order模块

Feign默认使用ribbon实现负载均衡
OpenFeign超时机制:
OpenFeign默认等待时间是1秒,超过1秒,直接报错
1,设置超时时间,修改配置文件:
因为OpenFeign的底层是ribbon进行负载均衡,所以它的超时时间是由ribbon控制

OpenFeign日志:

OpenFeign的日志级别有:

1,使用OpenFeign的日志:
实现在配置类中添加OpenFeign的日志类

2,为指定类设置日志级别:
监控如下这个接口

配置文件中:

3,启动服务即可
4,服务降级:
12,Hystrix服务降级



hystrix中的重要概念:
1,服务降级
比如当某个服务繁忙,不能让客户端的请求一直等待,应该立刻返回给客户端一个备选方案
这些情况会降级
- 程序运行异常
- 超时
- 服务熔断触发服务降级
- 线程池/信号量打满也会导致服务降级
2,服务熔断
当某个服务出现问题,卡死了,不能让用户一直等待,需要关闭所有对此服务的访问
然后调用服务降级
3,服务限流
限流,比如秒杀场景,不能访问用户瞬间都访问服务器,限制一次只可以有多少请求
使用hystrix,服务降级:
1,创建带降级机制的pay模块 :
名字: cloud-hystrix-pay-8007
2,pom文件
3,配置文件

4,主启动类

5,service

6,controller

7,先测试:
此时使用压测工具,并发20000个请求,请求会延迟的那个方法,
压测中,发现,另外一个方法并没有被压测,但是我们访问它时,却需要等待
这就是因为被压测的方法它占用了服务器大部分资源,导致其他请求也变慢了
8,先不加入hystrix,
2,创建带降级的order模块:
1,名字: cloud-hystrix-order-80
2,pom
3,配置文件

4,主启动类

5,远程调用pay模块的接口:

6,controller:

7,测试
启动order模块,访问pay
再次压测2万并发,发现order访问也变慢了

解决:


3,配置服务降级:
1,修改pay模块
1,为service的指定方法(会延迟的方法)添加@HystrixCommand注解

2,主启动类上,添加激活hystrix的注解

3,触发异常


可以看到,也触发了降级
2,修改order模块,进行服务降级
一般服务降级,都是放在客户端(order模块),

1,修改配置文件:

2,主启动类添加直接,启用hystrix:

3,修改controller,添加降级方法什么的

4,测试
启动pay模块,order模块,
注意:,这里pay模块和order模块都开启了服务降级
但是order这里,设置了1.5秒就降级,所以访问时,一定会降级
4,重构:
上面出现的问题:
1,降级方法与业务方法写在了一块,耦合度高
2.每个业务方法都写了一个降级方法,重复代码多
解决重复代码的问题:
配置一个全局的降级方法,所有方法都可以走这个降级方法,至于某些特殊创建,再单独创建方法
1,创建一个全局方法

2,使用注解指定其为全局降级方法(默认降级方法)


3,业务方法使用默认降级方法:

4,测试:

解决代码耦合度的问题:
修改order模块,这里开始,pay模块就不服务降级了,服务降级写在order模块即可
1,Payservice接口是远程调用pay模块的,我们这里创建一个类实现service接口,在实现类中统一处理异常

2,修改配置文件:添加:
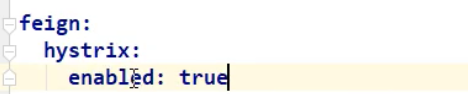
3,让PayService的实现类生效:

它的运行逻辑是:
当请求过来,首先还是通过Feign远程调用pay模块对应的方法
但是如果pay模块报错,调用失败,那么就会调用PayMentFalbackService类的
当前同名的方法,作为降级方法
4,启动测试
启动order和pay正常访问–ok
此时将pay服务关闭,order再次访问

可以看到,并没有报500错误,而是降级访问实现类的同名方法
这样,即使服务器挂了,用户要不要一直等待,或者报错
问题:
这样虽然解决了代码耦合度问题,但是又出现了过多重复代码的问题,每个方法都有一个降级方法
使用服务熔断:

比如并发达到1000,我们就拒绝其他用户访问,在有用户访问,就访问降级方法

1,修改前面的pay模块
1,修改Payservice接口,添加服务熔断相关的方法:

这里属性整体意思是:
10秒之内(窗口,会移动),如果并发超过10个,或者10个并发中,失败了6个,就开启熔断器

IdUtil是Hutool包下的类,这个Hutool就是整合了所有的常用方法,比如UUID,反射,IO流等工具方法什么的都整合了


断路器的打开和关闭,是按照一下5步决定的
1,并发此时是否达到我们指定的阈值
2,错误百分比,比如我们配置了60%,那么如果并发请求中,10次有6次是失败的,就开启断路器
3,上面的条件符合,断路器改变状态为open(开启)
4,这个服务的断路器开启,所有请求无法访问
5,在我们的时间窗口期,期间,尝试让一些请求通过(半开状态),如果请求还是失败,证明断路器还是开启状态,服务没有恢复
如果请求成功了,证明服务已经恢复,断路器状态变为close关闭状态

2,修改controller
添加一个测试方法;

3,测试:
启动pay,order模块
多次访问,并且错误率超过60%:

此时服务熔断,此时即使访问正确的也会报错:

但是,当过了几秒后,又恢复了
因为在10秒窗口期内,它自己会尝试接收部分请求,发现服务可以正常调用,慢慢的当错误率低于60%,取消熔断
Hystrix所有可配置的属性:
全部在这个方法中记录,以成员变量的形式记录,
以后需要什么属性,查看这个类即可

总结:

当断路器开启后:

其他参数:





熔断整体流程:

-
创建HystrixCommand (用在依赖的服务返回单个操作结果的时候)或HystrixObserableCommand (用在依赖的服务返回多个操作结果的时候)对象。
-
命令执行。其中HystrixComand实现了下面前两种执行方式;而HystrixObservableCommand实现了后两种执行方式: execute(): 同步执行,从依赖的服务返回一个单一的结果对象,或是在发生错误的时候抛出异常。queue(): 异步执行,直接返回一个Future对象,其中包含了服务执行结束时要返回的单一结果对象。observe(): 返回Observable对象。它代表了操作的多个结果,它是一个Hot Obserable (不论“事件源”是否有“订阅者"。都会在创建后对事件进行发布,所以对于Hot Observable的每一个“订阅者"都有可能是从"事件源"的中途开始的,并可能只是看到了整个操作的局部过程) 。 toObservable(): 同样会返回 Observable对象,也代表了操作的多个结果,但它返回的是一个Cold Observable (没有“订阅者"的时候并不会发布事件,而是进行等待,直到有“订阅者"之后才发布事件,所以对于Cold Observable的订阅者,它可以保证从一开始看到整个操作的全部过程) 。
-
若当前命令的请求缓存功能是被启用的,并且该命令缓存命中。那么缓存的结果会立即以Observable对象的形式返回。
-
检查断路器是否为打开状态。如果断路器是打开的,那么Hystrix不会执行命令,而是转接到fallback处理逻辑(第8步) ;如果断路器是关闭的,检查是否有可用资源来执行命令(第5步) 。
-
线程油/请求队列/信号量是否占满,如果命令依赖服务的专有线程池和请求队列,或者信号量(不使用线程池的时候)已经被占满,那么 Hystrix也不会执行命令,而是转接到 fallbalk处理逻辑(第8步)。
-
Hystrix会根据我们编写的方法来决定采取什么样的方式去请求依赖服务。HystrixCommand.run(): 返回一个单一的结果, 或者抛出异常。HystrixObservableCommand.construct(): 返回一 个Observable对象来发射多个结果,或通过onError发送错误通知。
-
Hytrix会将“成功"、“失败”、“拒绝"、 “超时“等信息报告给断路器,而断路器会维护一 组计数器来统计这些数据, 断路器会使用这些统计数据来决定是否要将断路器打开,来对某个依赖服务的请求进行“熔断/短路"。
-
当命令执行失败的时候,Hystrix 会进入fallback尝试回退处理,我们通常也称该操作为 “服务降级"。而能够引起服务降级处理的情况有下面几种:第4步:当前命令处于 “熔断/短路“状态。断路器是打开的时候。第5步:当前命令的线程池、请求队列或者信号量被占满的时候,第6步: HystrixObservableCommand.construct() 或HystrixCommand.run()抛出异常的时候。
-
当Hytrix命令执行成功之后,它会将处理结果直接返回或是L以observable 的形式返回。
tips:如果我们没有为命令实现降级逻辑或者在降级处理逻辑中抛出了异常,Hytrix 依然会返回一个Observable对象,但是它不会发射任何结果数据。 而是通过 onError方法通知命令立即中断请求,并通过onError()方法将引起命令失败的异常发送给调用者。
Hystrix服务监控:
HystrixDashboard

2,使用HystrixDashboard:
1,创建项目:
名字: cloud_hystrixdashboard_9001
2,pom文件
<dependencies>
<!--新增hystrix dashboard-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
3,配置文件

4,主启动类

5,修改所有pay模块(8001,8002,8003…)
他们都添加一个pom依赖:

之前的pom文件中都添加过了,这个是springboot的监控组件
6,启动9001即可
访问: localhost:9001/hystrix
7,注意,此时仅仅是可以访问HystrixDashboard,并不代表已经监控了8001,8002
如果要监控,还需要配置:(8001为例)
8001的主启动类添加:

@Bean
public ServletRegistrationBean getServlet(){
HystrixMetricsStreamServlet streamServlet = new HystrixMetricsStreamServlet();
ServletRegistrationBean registrationBean = new ServletRegistrationBean(streamServlet);
registrationBean.setLoadOnStartup(1);
registrationBean.addUrlMappings("/hystrix.stream");
registrationBean.setName("HystrixMetricsStreamServlet");
return registrationBean;
}
其他8002,8003都是一样的
8,到此,可以启动服务
启动7001,8001,9001
然后在web界面,指定9001要监控8001:




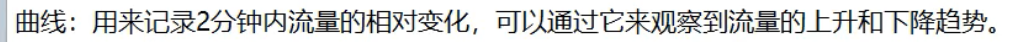

















 374
374











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









