







1. 重构字符串

(1)奇偶交叉插入
参照 169. 多数元素 和 229. 求众数 II 的解题思路,先求出出现次数最多的字符,然后再判断是否可以使得两相邻的字符不同
(1)如果要使得两相邻的字符不同,那么出现次数最多的那个数的数量必须满足下面条件,如下图所示,比如下面的a是出现次数最多的
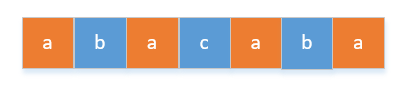
这个时候a的数量已经达到了临界值,如果再多一个 a ,那么至少有两个 a 是相邻的。所以这里出现次数最多的那个字符数量的临界值是threshold = (length + 1) >> 1(其中 length 是字符串的长度)
如果能使得两相邻的字符不同,我们可以先把出现次数最多的那个字符放到新字符串下标为偶数的位置上,放完之后在用其他的字符填充字符串剩下的位置。
注意 这里能不能先把出现次数最多的字符放到字符串下标为奇数的位置呢,当然是不可以的。比如我们上面举的例子abacaba本来是可以满足的,如果放到下标为奇数的位置,最后一个 a 就没法放了,除非放到最前面,那又变成了放到下标为偶数的位置了。

具体流程:
- 1.转为数组,统计s中每个字符出现的次数
- 2.找到出现次数最多的那个次数(注意出现次数最多不能超过(length + 1) / 2)
- 3.如果出现次数最多的那个字符的数量大于阈值,说明他不能使得两相邻的字符不同,直接返回空字符串即可
- 4.如果可以使得两相邻的字符不同,我们随便返回一个结果,res就是返回
- 注意:
- 我们需要先把出现次数最多的字符存储在数组下标为偶数的位置上(不能放奇数位置上,会出错)
- 然后再把剩下的字符存储在其他位置上
class Solution {
public String reorganizeString(String S) {
//把字符串S转化为字符数组
char[] str = S.toCharArray();
//记录每个字符出现的次数
int[] strCount = new int[26];
//字符串的长度
int len = S.length();
//统计每个字符出现的次数
for (int i = 0; i < len; i++) {
strCount[str[i] - 'a']++;
}
int max = 0, alphabet = 0, maxLen = (len + 1) >> 1;
//找出出现次数最多的那个字符
for (int i = 0; i < strCount.length; i++) {
if (strCount[i] > max) {
max = strCount[i];
alphabet = i;
//如果出现次数最多的那个字符的数量大于阈值,说明他不能使得
// 两相邻的字符不同,直接返回空字符串即可
if (max > maxLen)
return "";
}
}
//到这一步说明他可以使得两相邻的字符不同,我们随便返回一个结果,res就是返回
//结果的数组形式,最后会再转化为字符串的
char[] res = new char[len];
int index = 0;
//先把出现次数最多的字符存储在数组下标为偶数的位置上
while (strCount[alphabet]-- > 0) {
res[index] = (char) (alphabet + 'a');
index += 2;
}
//然后再把剩下的字符存储在其他位置上
for (int i = 0; i < strCount.length; i++) {
while (strCount[i]-- > 0) {
if (index >= res.length) {
index = 1;
}
res[index] = (char) (i + 'a');
index += 2;
}
}
return new String(res);
}
}
















 1829
1829











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











