







在我们日常的Java Web开发中,无不都是使用数据库来进行数据的存储,由于一般的系统任务中通常不会存在高并发的情况,所以这样看起来并没有什么问题,可是一旦涉及大数据量的需求,比如一些商品抢购的情景,或者是主页访问量瞬间较大的时候,单一使用数据库来保存数据的系统会因为面向磁盘,磁盘读/写速度比较慢的问题而存在严重的性能弊端,一瞬间成千上万的请求到来,需要系统在极短的时间内完成成千上万次的读/写操作,这个时候往往不是数据库能够承受的,极其容易造成数据库系统瘫痪,最终导致服务宕机的严重生产问题。
NoSQL 技术
为了克服上述的问题,Java Web项目通常会引入NoSQL技术,这是一种基于内存的数据库,并且提供一定的持久化功能。
Redis和MongoDB是当前使用最广泛的NoSQL,而就Redis技术而言,它的性能十分优越,可以支持每秒十几万次的读/写操作,其性能远超数据库,并且还支持集群、分布式、主从同步等配置,原则上可以无限扩展,让更多的数据存储在内存中,更让人欣慰的是它还支持一定的事务能力,这保证了高并发的场景下数据的安全和一致性。
1.redis的简介
(1)redis是什么?
Redis本质上是一个Key-Value类型的内存数据库,很像memcached,整个数据库统加载在内存当中进行操作,定期通过异步操作把数据库数据flush到硬盘上进行保存。因为是纯内存操作,Redis的性能非常出色,每秒可以处理超过 10万次读写操作。Redis的出色之处不仅仅是性能,Redis最大的魅力是支持保存List链表和Set集合的数据结构,而且还支持对List进行各种操作,它的值可以是string,list,sets,或者是ordered sets。例如 从List两端push和pop数据,取List区间,排序等等,对Set支持各种集合的并集交集操作,此外单个value的最大限制是1GB,不像 memcached只能保存1MB的数据,因此Redis可以用来实现很多有用的功能,比方说用他的List来做FIFO双向链表,实现一个轻量级的高性 能消息队列服务,用他的Set可以做高性能的tag系统等等。另外Redis也可以对存入的Key-Value设置expire时间,因此也可以被当作一 个功能加强版的memcached来用。 Redis的主要缺点是数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,并且它没有原生的可扩展机制,不具有scale(可扩展)能力,要依赖客户端来实现分布式读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。根据Redis的官网测试报告,50个并发请求,10w次访问,写速度为11x10e4/s,读速度为8100次/s.目前使用Redis的网站有 github,Engine Yard。
(2)Redis 特点
与其它 Key-Value 缓存产品相比,Redis 有以下特点:
Redis 支持数据的持久化(包括 AOF 和 RDB 两种模式),可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用,性能与可靠性兼顾;
Redis 不是仅仅支持简单的 Key-Value类型的数据,还支持字符串、列表、集合、散列表、有序集合数据结构的存储,这一优势使 Redis 适用于更广泛的应用场景;
Redis 支持数据的备份,即 Master-Slave 模式,Master 故障时,对应的 Slave 将通过选举升主,保障可用性;
Redis 主进程是单线程工作,因此,Redis 的所有操作都是原子性的,即操作要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性;
Redis 性能优越,读的速度达110000次/s,写的速度达81000次/s。
除了上述特点,Redis 还支持Publish/Subscribe,通知,Key 老化逐出等特性。

注1:数据库事务必须具备ACID特性,ACID是Atomic原子性,Consistency一致性,Isolation隔离性,Durability持久性。
注2:数据的持久存储,尤其是海量数据的持久存储,还是需要一种关系数据库。
2.redis的下载安装
在下载redis数据库之前,将主机重置,保证环境的纯净
(1)获取安装包并解压
root@server1 ~]# tar zxf redis-5.0.3.tar.gz
[root@server1 ~]# ls
redis-5.0.3 redis-5.0.3.tar.gz
[root@server1 ~]# cd redis-5.0.3/
[root@server1 redis-5.0.3]# ls
00-RELEASENOTES COPYING Makefile redis.conf runtest-sentinel tests
BUGS deps MANIFESTO runtest sentinel.conf utils
CONTRIBUTING INSTALL README.md runtest-cluster src

(2)因为已经存在makefile,所以不需要进行编译,直接安装
[root@server1 redis-5.0.3]# yum install -y gcc
[root@server1 redis-5.0.3]# make && make install

(3)切换到utils目录进行server端的安装脚本
[root@server1 redis-5.0.3]# cd utils/
[root@server1 utils]# ls
build-static-symbols.tcl graphs redis-copy.rb speed-regression.tcl
cluster_fail_time.tcl hashtable redis_init_script whatisdoing.sh
corrupt_rdb.c hyperloglog redis_init_script.tpl
create-cluster install_server.sh redis-sha1.rb
generate-command-help.rb lru releasetools
[root@server1 utils]# ./install_server.sh
Welcome to the redis service installer
This script will help you easily set up a running redis server
Please select the redis port for this instance: [6379]
Selecting default: 6379
Please select the redis config file name [/etc/redis/6379.conf]
Selected default - /etc/redis/6379.conf
Please select the redis log file name [/var/log/redis_6379.log]
Selected default - /var/log/redis_6379.log
Please select the data directory for this instance [/var/lib/redis/6379]
Selected default - /var/lib/redis/6379
Please select the redis executable path [/usr/local/bin/redis-server]
Selected config:
Port : 6379
Config file : /etc/redis/6379.conf
Log file : /var/log/redis_6379.log
Data dir : /var/lib/redis/6379
Executable : /usr/local/bin/redis-server
Cli Executable : /usr/local/bin/redis-cli
Is this ok? Then press ENTER to go on or Ctrl-C to abort.
Copied /tmp/6379.conf => /etc/init.d/redis_6379
Installing service...
Successfully added to chkconfig!
Successfully added to runlevels 345!
Starting Redis server...
Installation successful!

(4)此时,6379端口已经开启,修改/etc/redis/6379.conf配置文件,并重启
[root@server1 utils]# cd /etc/init.d
[root@server1 init.d]# netstat -antlp
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 5472/redis-server 1
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 656/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 881/master
tcp 0 0 172.25.4.1:22 172.25.4.250:38284 ESTABLISHED 1019/sshd: root@pts
tcp6 0 0 :::22 :::* LISTEN 656/sshd
tcp6 0 0 ::1:25 :::* LISTEN 881/master
[root@server1 init.d]# cd ~
[root@server1 ~]# vim /etc/redis/6379.conf
70 bind 0.0.0.0

[root@server1 ~]# /etc/init.d/redis_6379 restart
Stopping ...
Redis stopped
Starting Redis server...
[root@server1 ~]# netstat -antlp
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:6379 0.0.0.0:* LISTEN 5494/redis-server 0
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 656/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 881/master
tcp 0 0 127.0.0.1:6379 127.0.0.1:60310 TIME_WAIT -
tcp 0 0 172.25.4.1:22 172.25.4.250:38284 ESTABLISHED 1019/sshd: root@pts
tcp6 0 0 :::22 :::* LISTEN 656/sshd
tcp6 0 0 ::1:25 :::* LISTEN 881/master

(5)查看进程并进行测试:
[root@server1 ~]#ps ax
5494 ? Ssl 0:00 /usr/local/bin/redis-server 0.0.0.0:6379
[root@server1 ~]# redis-cli
127.0.0.1:6379> set name westos
OK
127.0.0.1:6379> get name
"westos"
127.0.0.1:6379> del name
(integer) 1
127.0.0.1:6379> get name
(nil)
3.redis的主从复制同步
在 Redis 复制的基础上,使用和配置主从复制非常简单,能使得从 Redis 服务器(下文称 slave)能精确得复制主 Redis 服务器(下文称 master)的内容。每次当 slave 和 master 之间的连接断开时, slave 会自动重连到 master 上,并且无论这期间 master 发生了什么, slave 都将尝试让自身成为 master 的精确副本。
这个系统的运行依靠三个主要的机制:
- 当一个 master 实例和一个 slave 实例连接正常时, master 会发送一连串的命令流来保持对 slave 的更新,以便于将自身数据集的改变复制给 slave :包括客户端的写入、key 的过期或被逐出等等。
- 当 master 和 slave 之间的连接断开之后,因为网络问题、或者是主从意识到连接超时, slave 重新连接上 master 并会尝试进行部分重同步:这意味着它会尝试只获取在断开连接期间内丢失的命令流。
- 当无法进行部分重同步时, slave 会请求进行全量重同步。这会涉及到一个更复杂的过程,例如 master 需要创建所有数据的快照,将之发送给 slave ,之后在数据集更改时持续发送命令流到 slave 。
Redis使用默认的异步复制,其特点是低延迟和高性能,是绝大多数 Redis 用例的自然复制模式。但是,从 Redis 服务器会异步地确认其从主 Redis 服务器周期接收到的数据量。
客户端可以使用 WAIT 命令来请求同步复制某些特定的数据。但是,WAIT 命令只能确保在其他 Redis 实例中有指定数量的已确认的副本:在故障转移期间,由于不同原因的故障转移或是由于 Redis 持久性的实际配置,故障转移期间确认的写入操作可能仍然会丢失。
接下来的是一些关于 Redis 复制的非常重要的事实:
- Redis 使用异步复制,slave 和 master 之间异步地确认处理的数据量
- 一个 master 可以拥有多个 slave
- slave 可以接受其他 slave 的连接。除了多个 slave 可以连接到同一个 master 之外, slave 之间也可以像层叠状的结构(cascading-like structure)连接到其他 slave 。自 Redis 4.0 起,所有的 sub-slave 将会从 master 收到完全一样的复制流。
- Redis 复制在 master 侧是非阻塞的。这意味着 master 在一个或多个 slave 进行初次同步或者是部分重同步时,可以继续处理查询请求。
- 复制在 slave 侧大部分也是非阻塞的。当 slave 进行初次同步时,它可以使用旧数据集处理查询请求,假设你在 redis.conf 中配置了让 Redis 这样做的话。否则,你可以配置如果复制流断开, Redis slave 会返回一个 error 给客户端。但是,在初次同步之后,旧数据集必须被删除,同时加载新的数据集。 slave 在这个短暂的时间窗口内(如果数据集很大,会持续较长时间),会阻塞到来的连接请求。自 Redis 4.0 开始,可以配置 Redis 使删除旧数据集的操作在另一个不同的线程中进行,但是,加载新数据集的操作依然需要在主线程中进行并且会阻塞 slave 。
- 复制既可以被用在可伸缩性,以便只读查询可以有多个 slave 进行(例如 O(N) 复杂度的慢操作可以被下放到 slave ),或者仅用于数据安全。
- 可以使用复制来避免 master 将全部数据集写入磁盘造成的开销:一种典型的技术是配置你的 master Redis.conf 以避免对磁盘进行持久化,然后连接一个 slave ,其配置为不定期保存或是启用 AOF。但是,这个设置必须小心处理,因为重新启动的 master 程序将从一个空数据集开始:如果一个 slave 试图与它同步,那么这个 slave 也会被清空。
(1)开启另外一台虚拟机,设置和2中的一致:
[root@server2 ~]# tar zxf redis-5.0.3.tar.gz ##安装包的解压
[root@server2 redis-5.0.3]# yum install gcc && make && make install
[root@server2 redis-5.0.3]# cd utils/
[root@server2 utils]# ls
build-static-symbols.tcl graphs redis-copy.rb speed-regression.tcl
cluster_fail_time.tcl hashtable redis_init_script whatisdoing.sh
corrupt_rdb.c hyperloglog redis_init_script.tpl
create-cluster install_server.sh redis-sha1.rb
generate-command-help.rb lru releasetools
[root@server2 utils]# ./install_server.sh
Welcome to the redis service installer
This script will help you easily set up a running redis server
Please select the redis port for this instance: [6379]
Selecting default: 6379
Please select the redis config file name [/etc/redis/6379.conf]
Selected default - /etc/redis/6379.conf
Please select the redis log file name [/var/log/redis_6379.log]
Selected default - /var/log/redis_6379.log
Please select the data directory for this instance [/var/lib/redis/6379]
Selected default - /var/lib/redis/6379
Please select the redis executable path [/usr/local/bin/redis-server]
Selected config:
Port : 6379
Config file : /etc/redis/6379.conf
Log file : /var/log/redis_6379.log
Data dir : /var/lib/redis/6379
Executable : /usr/local/bin/redis-server
Cli Executable : /usr/local/bin/redis-cli
Is this ok? Then press ENTER to go on or Ctrl-C to abort.
Copied /tmp/6379.conf => /etc/init.d/redis_6379
Installing service...
Successfully added to chkconfig!
Successfully added to runlevels 345!
Starting Redis server...
Installation successful!

(2)从库配置文件的修改
[root@server2 utils]# vim /etc/redis/6379.conf
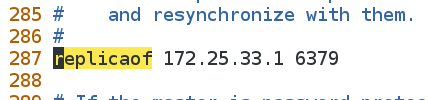
70 bind 0.0.0.0
287 replicaof 172.25.33.1 6379
[root@server2 utils]# /etc/init.d/redis_6379 restart
Stopping ...
Redis stopped
Starting Redis server...
[root@server2 utils]# netstat -antlp
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:6379 0.0.0.0:* LISTEN 5447/redis-server 0
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 671/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 885/master
tcp 0 0 127.0.0.1:6379 127.0.0.1:54018 TIME_WAIT -
tcp 0 0 172.25.4.2:22 172.25.4.250:45928 ESTABLISHED 1029/sshd: root@pts
tcp 0 0 172.25.4.2:40452 172.25.4.1:6379 ESTABLISHED 5447/redis-server 0
tcp6 0 0 :::22 :::* LISTEN 671/sshd
tcp6 0 0 ::1:25 :::* LISTEN 885/master


(3)主从配置完毕,进行测试:
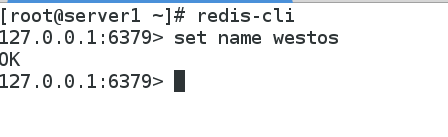
[root@server1 ~]# redis-cli
127.0.0.1:6379> set name westos
OK
127.0.0.1:6379>
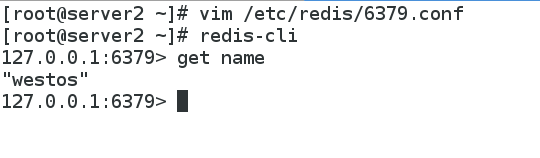
[root@server2 utils]# redis-cli
127.0.0.1:6379> get name ##同步成功!!
"westos"
127.0.0.1:6379>
4.redis的高可用–sentinel
(1)redis的sentinel系统

(2)在这里,我们先来谈一下主观下线和客观下线,在之后的配置中,会涉及到这两个概念
- 主观下线(Subjectively Down, 简称 SDOWN)指的是单个 Sentinel 实例对服务器做出的下线判断。
- 客观下线(Objectively Down, 简称 ODOWN)指的是多个 Sentinel 实例在对同一个服务器做出 SDOWN 判断, 并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后, 得出的服务器下线判断。 (一个 Sentinel 可以通过向另一个 Sentinel 发送 SENTINEL is-master-down-by-addr 命令来询问对方是否认为给定的服务器已下线。)
如果一个服务器没有在 master-down-after-milliseconds 选项所指定的时间内, 对向它发送 PING 命令的 Sentinel 返回一个有效回复(valid reply), 那么 Sentinel 就会将这个服务器标记为主观下线。
服务器对 PING 命令的有效回复可以是以下三种回复的其中一种:
返回 +PONG 。
返回 -LOADING 错误。
返回 -MASTERDOWN 错误。
如果服务器返回除以上三种回复之外的其他回复, 又或者在指定时间内没有回复 PING 命令, 那么 Sentinel 认为服务器返回的回复无效(non-valid)。
注意, 一个服务器必须在 master-down-after-milliseconds 毫秒内, 一直返回无效回复才会被 Sentinel 标记为主观下线。
举个例子, 如果 master-down-after-milliseconds 选项的值为 30000 毫秒(30 秒), 那么只要服务器能在每 29 秒之内返回至少一次有效回复, 这个服务器就仍然会被认为是处于正常状态的。
从主观下线状态切换到客观下线状态并没有使用严格的法定人数算法(strong quorum algorithm), 而是使用了流言协议: 如果 Sentinel 在给定的时间范围内, 从其他 Sentinel 那里接收到了足够数量的主服务器下线报告, 那么 Sentinel 就会将主服务器的状态从主观下线改变为客观下线。 如果之后其他 Sentinel 不再报告主服务器已下线, 那么客观下线状态就会被移除。
客观下线条件只适用于主服务器: 对于任何其他类型的 Redis 实例, Sentinel 在将它们判断为下线前不需要进行协商, 所以从服务器或者其他 Sentinel 永远不会达到客观下线条件。
只要一个 Sentinel 发现某个主服务器进入了客观下线状态, 这个 Sentinel 就可能会被其他 Sentinel 推选出, 并对失效的主服务器执行自动故障迁移操作。
(3)sential的配置:使用三台虚拟机搭建sentinel系统,目前为止,存在两个redis主机,新开启一台虚拟机
server1 172.25.33.1
server2 172.25.33.2
server3 172.25.33.3 ##server3的配置和3中从数据库介绍的配置一样,不再赘述
(4)配置 Sentinel
[root@server1 redis-5.0.3]# cp sentinel.conf /etc/redis
[root@server1 redis]# vim sentinel.conf
protected-mode no ##安全模式关闭,该参数为禁止外网访问
sentinel monitor mymaster 172.25.33.1 6379 2
sentinel down-after-milliseconds mymaster 10000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000
sentinel deny-scripts-reconfig yes
sentinel monitor mymaster 172.25.33.1 6379 2 指示 Sentinel 去监视一个名为 mymaster 的主服务器, 这个主服务器的 IP 地址为 127.0.0.1 , 端口号为 6379 , 而将这个主服务器判断为失效至少需要 2 个 Sentinel 同意 (只要同意 Sentinel 的数量不达标,自动故障迁移就不会执行)。
不过要注意, 无论你设置要多少个 Sentinel 同意才能判断一个服务器失效, 一个 Sentinel 都需要获得系统中多数(majority) Sentinel 的支持, 才能发起一次自动故障迁移, 并预留一个给定的配置纪元 (configuration Epoch ,一个配置纪元就是一个新主服务器配置的版本号)。
换句话说, 在只有少数(minority) Sentinel 进程正常运作的情况下, Sentinel 是不能执行自动故障迁移的。
down-after-milliseconds 选项指定了 Sentinel 认为服务器已经断线所需的毫秒数。
如果服务器在给定的毫秒数之内, 没有返回 Sentinel 发送的 PING 命令的回复, 或者返回一个错误, 那么 Sentinel 将这个服务器标记为主观下线(subjectively down,简称 SDOWN )。
不过只有一个 Sentinel 将服务器标记为主观下线并不一定会引起服务器的自动故障迁移: 只有在足够数量的 Sentinel 都将一个服务器标记为主观下线之后, 服务器才会被标记为客观下线(objectively down, 简称 ODOWN ), 这时自动故障迁移才会执行。将服务器标记为客观下线所需的 Sentinel 数量由对主服务器的配置决定。
parallel-syncs 选项指定了在执行故障转移时, 最多可以有多少个从服务器同时对新的主服务器进行同步, 这个数字越小, 完成故障转移所需的时间就越长。






[root@server1 redis]# vim sentinel.conf ##将该配置文件传到其余两台主机
[root@server1 redis]# scp sentinel.conf server2:/etc/redis
The authenticity of host 'server2 (172.25.4.2)' can't be established.
ECDSA key fingerprint is 1d:83:8a:69:a6:d1:81:26:7b:cd:66:d0:39:c5:99:00.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'server2,172.25.4.2' (ECDSA) to the list of known hosts.
root@server2's password:
sentinel.conf 100% 9709 9.5KB/s 00:00
[root@server1 redis]# scp sentinel.conf server3:/etc/redis
The authenticity of host 'server3 (172.25.4.3)' can't be established.
ECDSA key fingerprint is 88:df:a8:14:f6:46:fc:f7:ad:59:76:30:9a:3b:87:a7.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'server3,172.25.4.3' (ECDSA) to the list of known hosts.
root@server3's password:
sentinel.conf 100% 9709 9.5K
(5)启动 Sentinel
对于 redis-sentinel 程序, 你可以用以下命令来启动 Sentinel 系统:
对于 redis-server 程序, 你可以用以下命令来启动一个运行在 Sentinel 模式下的 Redis 服务器:
redis-server /path/to/sentinel.conf --sentinel
两种方法都可以启动一个 Sentinel 实例。
启动 Sentinel 实例必须指定相应的配置文件, 系统会使用配置文件来保存 Sentinel 的当前状态, 并在 Sentinel 重启时通过载入配置文件来进行状态还原。
如果启动 Sentinel 时没有指定相应的配置文件, 或者指定的配置文件不可写(not writable), 那么 Sentinel 会拒绝启动。
[root@server1 redis]# redis-server /etc/redis/sentinel.conf --sentinel
[root@server2 redis]# redis-server /etc/redis/sentinel.conf --sentinel
[root@server3 redis]# redis-server /etc/redis/sentinel.conf --sentinel



(6)查看主库server1的信息,可以看到现在server1主机是主库,server2和server3是两个从主机
[root@server1 ~]# redis-cli
127.0.0.1:6379> info

(7)将server1的服务停止,观察sentinel系统能否选举出新的master,选举过程如下:
[root@server1 ~]# /etc/init.d/redis_6379 stop



(8)可以看到,现在server3变为主库,查看server3状态
[root@server1 ~]# redis-cli -h server3
server3:6379> info

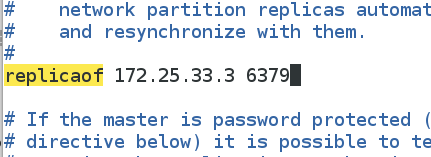
[root@server1 ~]# vim /etc/redis/6379.conf ##将server1作为从库加入系统
287 replicaof 172.25.4.3 6349
[root@server1 ~]# /etc/init.d/redis_6379 restart
/var/run/redis_6379.pid does not exist, process is not running
Starting Redis server...
[root@server1 ~]# redis-cli -h server3
server3:6379> info ##再次查看server3信息
server3:6379> get name
"westos" ##信息没有丢失

5.redis的集群的部署实现
(1)Redis集群介绍
Redis 集群是一个提供在多个Redis间节点间共享数据的程序集。Redis集群并不支持处理多个keys的命令,因为这需要在不同的节点间移动数据,从而达不到像Redis那样的性能,在高负载的情况下可能会导致不可预料的错误.Redis 集群通过分区来提供一定程度的可用性,在实际环境中当某个节点宕机或者不可达的情况下继续处理命令. Redis 集群的优势:
- 自动分割数据到不同的节点上。
- 整个集群的部分节点失败或者不可达的情况下能够继续处理命令。
(2)Redis 集群的数据分片
Redis 集群没有使用一致性hash, 而是引入了 哈希槽的概念.
Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽.集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么:
节点 A 包含 0 到 5500号哈希槽.
节点 B 包含5501 到 11000 号哈希槽.
节点 C 包含11001 到 16384号哈希槽.
这种结构很容易添加或者删除节点. 比如如果我想新添加个节点D, 我需要从节点 A, B, C中得部分槽到D上. 如果我想移除节点A,需要将A中的槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可. 由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态.
(3)Redis 集群的主从复制模型
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,每个节点都会有N-1个复制品.
在我们例子中具有A,B,C三个节点的集群,在没有复制模型的情况下,如果节点B失败了,那么整个集群就会以为缺少5501-11000这个范围的槽而不可用.
然而如果在集群创建的时候(或者过一段时间)我们为每个节点添加一个从节点A1,B1,C1,那么整个集群便有三个master节点和三个slave节点组成,这样在节点B失败后,集群便会选举B1为新的主节点继续服务,整个集群便不会因为槽找不到而不可用了。不过当B和B1 都失败后,集群是不可用的.
(4)Redis 一致性保证
Redis 并不能保证数据的强一致性. 这意味这在实际中集群在特定的条件下可能会丢失写操作.
第一个原因是因为集群是用了异步复制. 写操作过程:
客户端向主节点B写入一条命令.
主节点B向客户端回复命令状态.
主节点将写操作复制给它的从节点 B1, B2 和 B3.
主节点对命令的复制工作发生在返回命令回复之后, 因为如果每次处理命令请求都需要等待复制操作完成的话, 那么主节点处理命令请求的速度将极大地降低 —— 我们必须在性能和一致性之间做出权衡。 注意:Redis 集群可能会在将来提供同步写的方法。 Redis 集群另外一种可能会丢失命令的情况是集群出现了网络分区, 并且一个客户端与至少包括一个主节点在内的少数实例被孤立。
举个例子 假设集群包含 A 、 B 、 C 、 A1 、 B1 、 C1 六个节点, 其中 A 、B 、C 为主节点, A1 、B1 、C1 为A,B,C的从节点, 还有一个客户端 Z1 假设集群中发生网络分区,那么集群可能会分为两方,大部分的一方包含节点 A 、C 、A1 、B1 和 C1 ,小部分的一方则包含节点 B 和客户端 Z1 .
Z1仍然能够向主节点B中写入, 如果网络分区发生时间较短,那么集群将会继续正常运作,如果分区的时间足够让大部分的一方将B1选举为新的master,那么Z1写入B中得数据便丢失了.
注意, 在网络分裂出现期间, 客户端 Z1 可以向主节点 B 发送写命令的最大时间是有限制的, 这一时间限制称为节点超时时间(node timeout), 是 Redis 集群的一个重要的配置选项:
(5)搭建并使用Redis集群
搭建集群的第一件事情我们需要一些运行在 集群模式的Redis实例. 这意味这集群并不是由一些普通的Redis实例组成的,集群模式需要通过配置启用,开启集群模式后的Redis实例便可以使用集群特有的命令和特性了.
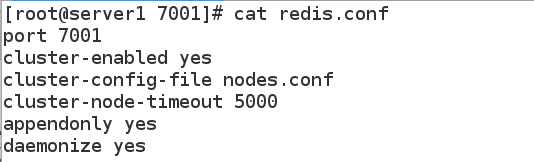
下面是一个最少选项的集群的配置文件:
port 7000
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
文件中的 cluster-enabled 选项用于开实例的集群模式, 而 cluster-conf-file 选项则设定了保存节点配置文件的路径, 默认值为 nodes.conf.节点配置文件无须人为修改, 它由 Redis 集群在启动时创建, 并在有需要时自动进行更新。
要让集群正常运作至少需要三个主节点,不过在刚开始试用集群功能时, 强烈建议使用六个节点: 其中三个为主节点, 而其余三个则是各个主节点的从节点。
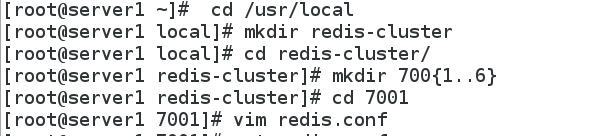
<5.1>首先, 让我们进入一个新目录, 并创建六个以端口号为名字的子目录, 稍后我们在将每个目录中运行一个 Redis 实例: 命令如下:
mkdir cluster-test
cd cluster-test
mkdir 7001 7002 7003 7004 7005 7006
在文件夹 7001 至 7006 中, 各创建一个 redis.conf 文件, 文件的内容可以使用上面的示例配置文件, 但记得将配置中的端口号从 7001 改为与文件夹名字相同的号码。


<5.2> 在每个目录下,执行以下命令,在每个标签页中打开一个实例:
cd 7001
../redis-server ./redis.conf

<5.3>搭建集群:现在我们已经有了六个正在运行中的 Redis 实例, 接下来我们需要使用这些实例来创建集群, 并为每个节点编写配置文件。
通过使用 Redis 集群命令行工具 redis-trib , 编写节点配置文件的工作可以非常容易地完成: redis-trib 位于 Redis 源码的 src 文件夹中, 它是一个 Ruby 程序, 这个程序通过向实例发送特殊命令来完成创建新集群, 检查集群, 或者对集群进行重新分片(reshared)等工作。
redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1
这个命令在这里用于创建一个新的集群, 选项–replicas 1 表示我们希望为集群中的每个主节点创建一个从节点。
之后跟着的其他参数则是这个集群实例的地址列表,3个master3个slave redis-trib 会打印出一份预想中的配置给你看, 如果你觉得没问题的话, 就可以输入 yes , redis-trib 就会将这份配置应用到集群当中,让各个节点开始互相通讯,最后可以得到如下信息:
[OK] All 16384 slots covered
这表示集群中的 16384 个槽都有至少一个主节点在处理, 集群运作正常。


可以看到在集群中,7001-7003示例为主节点,7006、7004、7002分别为对应的从节点。
<5.4>连接7001节点,输入数据,可以看到数据被定位到7002节点,在任意节点都可以看到数据
redis-cli -c -p 7001

[root@server1 7006]# redis-cli --cluster check 127.0.0.1:7001 ##可以使用该命令查看整体状态信息
127.0.0.1:7001 (1de258d1...) -> 0 keys | 5461 slots | 1 slaves.
127.0.0.1:7003 (d2cedfa9...) -> 0 keys | 5461 slots | 1 slaves.
127.0.0.1:7002 (5fd65eca...) -> 1 keys | 5462 slots | 1 slaves.
[OK] 1 keys in 3 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 127.0.0.1:7001)
M: 1de258d17bf4f36f65d9aecd2a1f1a12271de4c4 127.0.0.1:7001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: d2cedfa9c4ae290d15a0a90adff934df8369184e 127.0.0.1:7003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: 5fd65ecac9d85c85b74f6580c1de0998c27790e8 127.0.0.1:7002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: a6d89b2a1f6c9f5123a522974dddc6464c54f309 127.0.0.1:7004
slots: (0 slots) slave
replicates 5fd65ecac9d85c85b74f6580c1de0998c27790e8
S: b77a4f44dbb5fa0105f1aa9f88f580694d1624af 127.0.0.1:7005
slots: (0 slots) slave
replicates d2cedfa9c4ae290d15a0a90adff934df8369184e
S: 8915d405a5ed2d6dc06f4e89e67c7d7ef94fcb7b 127.0.0.1:7006
slots: (0 slots) slave
replicates 1de258d17bf4f36f65d9aecd2a1f1a12271de4c4
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
<5.5> 将7002节点down掉,可以看到7004接替了7002,变为了主节点,当将7004节点也down掉后,会导致集群不可用
[root@server1 7006]# redis-cli -p 7002
127.0.0.1:7002> SHUTDOWN
not connected> exit
[root@server1 7006]# redis-cli --cluster check 127.0.0.1:7001
Could not connect to Redis at 127.0.0.1:7002: Connection refused
127.0.0.1:7001 (1de258d1...) -> 0 keys | 5461 slots | 1 slaves.
127.0.0.1:7003 (d2cedfa9...) -> 0 keys | 5461 slots | 1 slaves.
127.0.0.1:7004 (a6d89b2a...) -> 1 keys | 5462 slots | 0 slaves.
[OK] 1 keys in 3 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 127.0.0.1:7001)
M: 1de258d17bf4f36f65d9aecd2a1f1a12271de4c4 127.0.0.1:7001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: d2cedfa9c4ae290d15a0a90adff934df8369184e 127.0.0.1:7003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: a6d89b2a1f6c9f5123a522974dddc6464c54f309 127.0.0.1:7004
slots:[5461-10922] (5462 slots) master
S: b77a4f44dbb5fa0105f1aa9f88f580694d1624af 127.0.0.1:7005
slots: (0 slots) slave
replicates d2cedfa9c4ae290d15a0a90adff934df8369184e
S: 8915d405a5ed2d6dc06f4e89e67c7d7ef94fcb7b 127.0.0.1:7006
slots: (0 slots) slave
replicates 1de258d17bf4f36f65d9aecd2a1f1a12271de4c4
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.


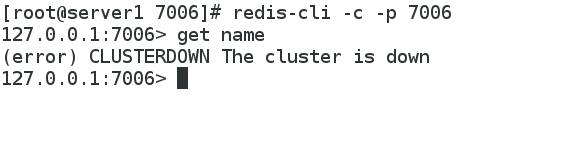
##将7004也down掉
[root@server1 7006]# redis-cli -p 7004 shutdown
[root@server1 7006]# redis-cli --cluster check 127.0.0.1:7001
Could not connect to Redis at 127.0.0.1:7002: Connection refused
Could not connect to Redis at 127.0.0.1:7004: Connection refused
127.0.0.1:7001 (1de258d1...) -> 0 keys | 5461 slots | 1 slaves.
127.0.0.1:7003 (d2cedfa9...) -> 0 keys | 5461 slots | 1 slaves.
[OK] 0 keys in 2 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 127.0.0.1:7001)
M: 1de258d17bf4f36f65d9aecd2a1f1a12271de4c4 127.0.0.1:7001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: d2cedfa9c4ae290d15a0a90adff934df8369184e 127.0.0.1:7003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: b77a4f44dbb5fa0105f1aa9f88f580694d1624af 127.0.0.1:7005
slots: (0 slots) slave
replicates d2cedfa9c4ae290d15a0a90adff934df8369184e
S: 8915d405a5ed2d6dc06f4e89e67c7d7ef94fcb7b 127.0.0.1:7006
slots: (0 slots) slave
replicates 1de258d17bf4f36f65d9aecd2a1f1a12271de4c4
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[ERR] Not all 16384 slots are covered by nodes.

<5.6> 重新将7002 7004节点进行启动,可以看到集群重新可以使用,7004为主节点,7002为从节点了,数据并没丢失,请求定向到7004节点上



备注:
可以使用脚本一次性全部建立6个节点
cd /root/redis-5.0.0/utils/create-cluster
./create-cluster start ##则可以看到6个节点全部开启,通过ps ax查看进程
./create-cluster create 创建集群,选择yes
./create-cluster clean 将节点全部清掉















 379
379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









