







在互联网应用的世界里,ID就像是每个数据的"身份证"。当你的系统从单体架构扩展到分布式架构时,一个看似简单的问题就出现了,如何给海量数据分配唯一ID?
这不再是简单地auto_increment就能解决的问题了!
什么是分布式ID?为什么需要它?
想象一下,你的小店生意太好了,从一家扩展到了连锁店。以前在一家店时,顾客编号从1开始自增就行。但现在多家店同时服务,如果各自从1开始编号,就会出现重复的顾客号——这就是分布式系统面临的ID问题。
分布式ID是在分布式系统中确保全局唯一的标识符。它需要满足这些关键特性:
- 全局唯一性:在整个分布式系统中不会重复
- 高性能:生成速度快
- 高可用:服务不能轻易挂掉
- 趋势递增:便于数据库存储与索引
- 信息安全:不包含敏感信息
分布式ID的经典应用场景
- 订单ID生成:每天数百万订单,每个都需要唯一标识
- 消息ID:消息队列中的消息去重、追踪
- 用户ID:新注册用户分配唯一标识
- 分库分表:数据水平拆分后的数据唯一标识
- 分布式事务:全局事务ID
六大主流分布式ID生成方案
让我们逐一解析目前最流行的几种方案,看看它们各自的优缺点。
1. UUID/GUID:简单粗暴但不够完美
Java实现UUID超级简单:
import java.util.UUID;
public class UUIDDemo {
public static void main(String[] args) {
// 生成UUID
String uuid = UUID.randomUUID().toString();
System.out.println("生成的UUID: " + uuid);
// 去掉连字符的UUID
String compactUuid = uuid.replace("-", "");
System.out.println("去掉连字符的UUID: " + compactUuid);
}
}
// 输出示例:
// 生成的UUID: c81d4e2e-bcf2-11e6-869b-7df92533d2db
// 去掉连字符的UUID: c81d4e2ebcf211e6869b7df92533d2db
优点:
- 实现简单,无需依赖外部系统
- 本地生成,速度快
- 全球唯一性基本有保障
缺点:
- 32位字符串,存储空间大
- 不易于人类阅读
- 无序性导致B+树索引效率低
- 生成的ID无业务含义
2. 数据库自增ID:简单但扩展性差
-- MySQL自增ID配置
CREATE TABLE id_generator (
id BIGINT NOT NULL AUTO_INCREMENT,
stub CHAR(1) NOT NULL DEFAULT '',
PRIMARY KEY (id),
UNIQUE KEY stub (stub)
) ENGINE=InnoDB;
-- 初始化一条记录
INSERT INTO id_generator VALUES (0, 'a');
-- 获取ID的存储过程
DELIMITER //
CREATE PROCEDURE `get_next_id`()
BEGIN
UPDATE id_generator SET id = LAST_INSERT_ID(id + 1);
SELECT LAST_INSERT_ID() AS next_id;
END //
DELIMITER ;
-- 调用存储过程获取ID
CALL get_next_id();
优点:
- 实现简单,依赖数据库即可
- 递增有序,对索引友好
缺点:
- 单点风险,数据库宕机则无法服务
- 并发性能有限
- 扩展性差,难以水平扩展
3. 数据库多主模式:稍好但不够优雅
设置多个数据库实例,每个实例设置不同的起始值和自增步长。
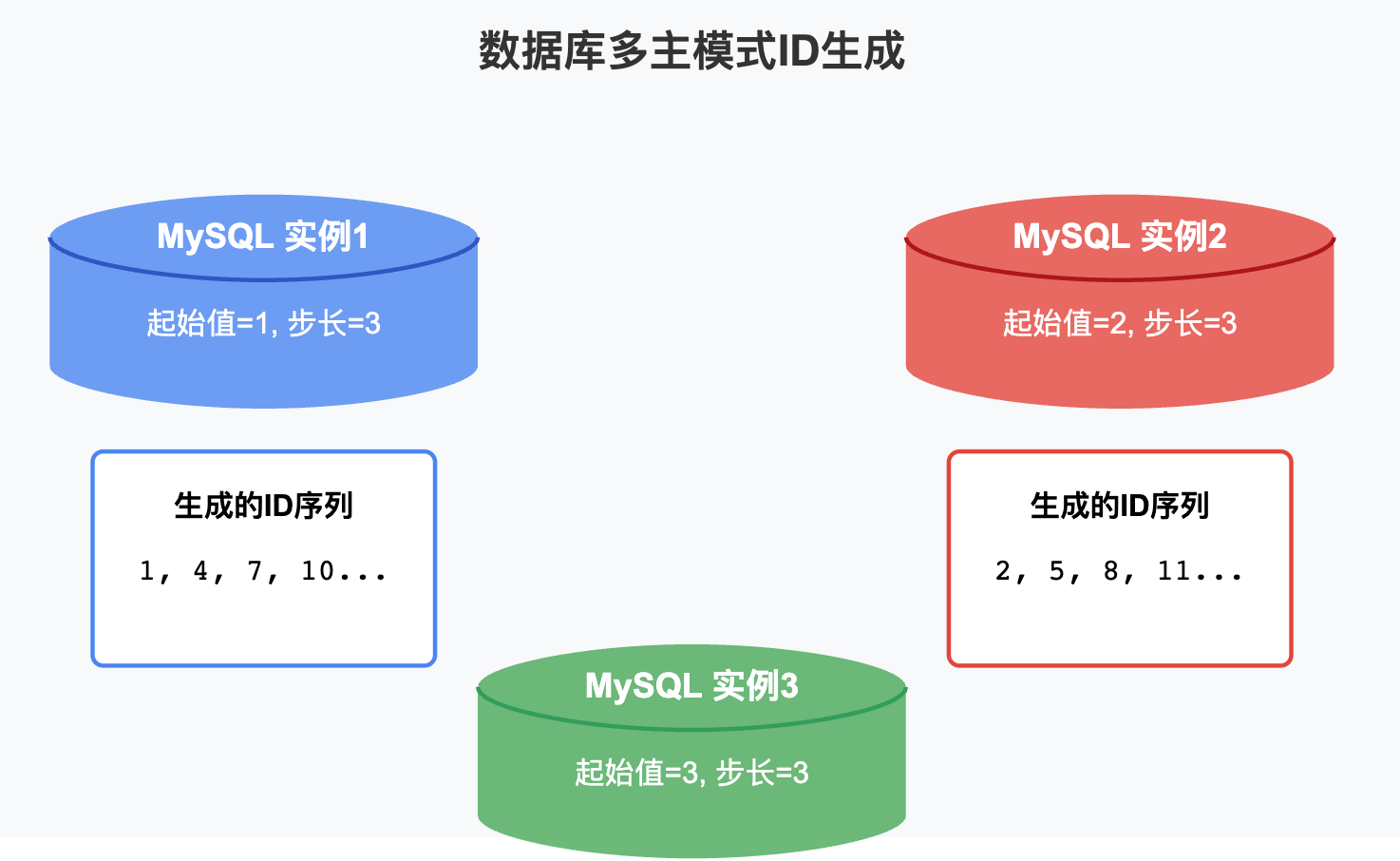
比如三台MySQL实例的配置:
- 实例1:起始值=1,步长=3,生成的ID为:1,4,7,10…
- 实例2:起始值=2,步长=3,生成的ID为:2,5,8,11…
- 实例3:起始值=3,步长=3,生成的ID为:3,6,9,12…
优点:
- 解决了单点问题
- ID有序递增
缺点:
- 扩展性有限,新增实例需要停机重新设置步长
- 数据库压力仍然存在
- 实例间的同步可能有延迟
4. Redis实现:轻量级方案
利用Redis的原子操作实现分布式ID生成:
import redis.clients.jedis.Jedis;
public class RedisIdGenerator {
private Jedis jedis;
private static final String ID_KEY = "distributed_id";
public RedisIdGenerator(String host, int port) {
this.jedis = new Jedis(host, port);
}
/**
* 获取下一个ID
*/
public long getNextId() {
return jedis.incr(ID_KEY);
}
/**
* 批量获取ID
*/
public long getBatchIds(int step) {
return jedis.incrBy(ID_KEY, step);
}
public static void main(String[] args) {
RedisIdGenerator generator = new RedisIdGenerator("localhost", 6379);
// 获取单个ID
long id = generator.getNextId();
System.out.println("获取的ID: " + id);
// 批量获取10个ID,返回最后一个ID
long lastId = generator.getBatchIds(10);
System.out.println("批量获取后的最后ID: " + lastId);
System.out.println("前面的ID分别是: " + (lastId-9) + " 到 " + (lastId-1));
}
}
优点:
- 实现简单,速度快
- Redis单线程,避免并发问题
- 可以通过集群提高可用性
缺点:
- Redis宕机会影响服务
- ID单调递增,可能暴露业务信息
- 需要额外维护Redis服务
5. 雪花算法(Snowflake):Twitter的大杀器
雪花算法是分布式ID生成的经典算法,由Twitter开源。它通过巧妙的位运算,将64位长整型数据划分为不同部分:

雪花算法Java实现:
public class SnowflakeIdGenerator {
// 开始时间截 (2023-01-01)
private final long twepoch = 1672531200000L;
// 机器ID所占位数
private final long workerIdBits = 5L;
// 数据中心ID所占位数
private final long datacenterIdBits = 5L;
// 支持的最大机器ID,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数)
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
// 支持的最大数据中心ID,结果是31
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
// 序列在ID中占的位数
private final long sequenceBits = 12L;
// 机器ID向左移12位
private final long workerIdShift = sequenceBits;
// 数据中心ID向左移17位(12+5)
private final long datacenterIdShift = sequenceBits + workerIdBits;
// 时间截向左移22位(5+5+12)
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
// 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095)
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
// 工作机器ID(0~31)
private long workerId;
// 数据中心ID(0~31)
private long datacenterId;
// 毫秒内序列(0~4095)
private long sequence = 0L;
// 上次生成ID的时间截
private long lastTimestamp = -1L;
/**
* 构造函数
* @param workerId 工作机器ID (0~31)
* @param datacenterId 数据中心ID (0~31)
*/
public SnowflakeIdGenerator(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("Worker ID不能大于%d或小于0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("Datacenter ID不能大于%d或小于0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
/**
* 获取下一个ID (线程安全)
* @return SnowflakeId
*/
public synchronized long nextId() {
long timestamp = timeGen();
// 如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过,这个时候应当抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("时钟回退。拒绝生成ID,%d毫秒内拒绝生成ID", lastTimestamp - timestamp));
}
// 如果是同一时间生成的,则进行毫秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
// 毫秒内序列溢出
if (sequence == 0) {
// 阻塞到下一个毫秒,获得新的时间戳
timestamp = tilNextMillis(lastTimestamp);
}
}
// 时间戳改变,毫秒内序列重置
else {
sequence = 0L;
}
// 上次生成ID的时间截
lastTimestamp = timestamp;
// 移位并通过或运算拼到一起组成64位的ID
return ((timestamp - twepoch) << timestampLeftShift) |
(datacenterId << datacenterIdShift) |
(workerId << workerIdShift) |
sequence;
}
/**
* 阻塞到下一个毫秒,直到获得新的时间戳
* @param lastTimestamp 上次生成ID的时间截
* @return 当前时间戳
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
/**
* 返回以毫秒为单位的当前时间
* @return 当前时间(毫秒)
*/
protected long timeGen() {
return System.currentTimeMillis();
}
/**
* 测试
*/
public static void main(String[] args) {
SnowflakeIdGenerator idGenerator = new SnowflakeIdGenerator(0, 0);
// 生成10个ID进行测试
for (int i = 0; i < 10; i++) {
long id = idGenerator.nextId();
System.out.println(id);
System.out.println(Long.toBinaryString(id)); // 查看二进制表示
}
}
}
优点:
- 高性能,无网络依赖,理论QPS约为409.6万/秒
- ID趋势递增,对索引友好
- 包含时间戳,可以粗略排序
- 可以通过调整位数分配应对不同场景
缺点:
- 依赖系统时钟,时钟回拨会导致ID重复
- 机器ID需要手动配置,扩容麻烦
- 雪崩效应:时间回拨时所有ID生成全部失败
6. 百度UidGenerator:雪花算法的升级版
百度优化了雪花算法,主要改进:
- 使用二进制的位操作取代十进制运算
- 使用RingBuffer提高并发性能
- 提供workerId的动态分配策略
UidGenerator配置示例:
import com.baidu.fsg.uid.impl.CachedUidGenerator;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class UidGeneratorConfig {
/**
* 创建CachedUidGenerator Bean
*/
@Bean
public CachedUidGenerator cachedUidGenerator() {
CachedUidGenerator cachedUidGenerator = new CachedUidGenerator();
// 设置workerId分配策略
cachedUidGenerator.setWorkerIdAssigner(workerIdAssigner());
// 设置时间位数
cachedUidGenerator.setTimeBits(29);
// 设置workerId位数
cachedUidGenerator.setWorkerBits(21);
// 设置序列号位数
cachedUidGenerator.setSeqBits(13);
// 设置epochStr,时间基点
cachedUidGenerator.setEpochStr("2023-01-01");
// RingBuffer配置
// 环形缓冲区大小,必须是2的幂
cachedUidGenerator.setBoostPower(3);
// 指定RingBuffer中可用于生成ID的最大阈值
cachedUidGenerator.setPaddingFactor(50);
// 拒绝策略:当环形缓冲区满时的拒绝策略
cachedUidGenerator.setRejectedPutBufferHandler(new RejectedPutBufferHandler() {
@Override
public void rejectPutBuffer(RingBuffer ringBuffer, long uid) {
// 自定义拒绝策略
logger.warn("Buffer is full, reject put buffer for uid: {}", uid);
}
});
// 拒绝策略:当环形缓冲区为空时的拒绝策略
cachedUidGenerator.setRejectedTakeBufferHandler(new RejectedTakeBufferHandler() {
@Override
public void rejectTakeBuffer(RingBuffer ringBuffer) {
// 自定义拒绝策略
logger.warn("Buffer is empty, reject take buffer");
}
});
return cachedUidGenerator;
}
/**
* 创建WorkerIdAssigner Bean
*/
@Bean
public DisposableWorkerIdAssigner workerIdAssigner() {
return new DisposableWorkerIdAssigner();
}
}
优点:
- 高性能:RingBuffer提供了疯狂的吞吐量
- 实现了workerId的动态分配
- 应对时钟回拨有策略
- 自定义位数分配策略,灵活适配不同业务场景
缺点:
- 需要依赖数据库存储workerId
- 代码实现复杂度较高
- 需要理解RingBuffer机制
7. 滴滴Tinyid:区间ID段模式
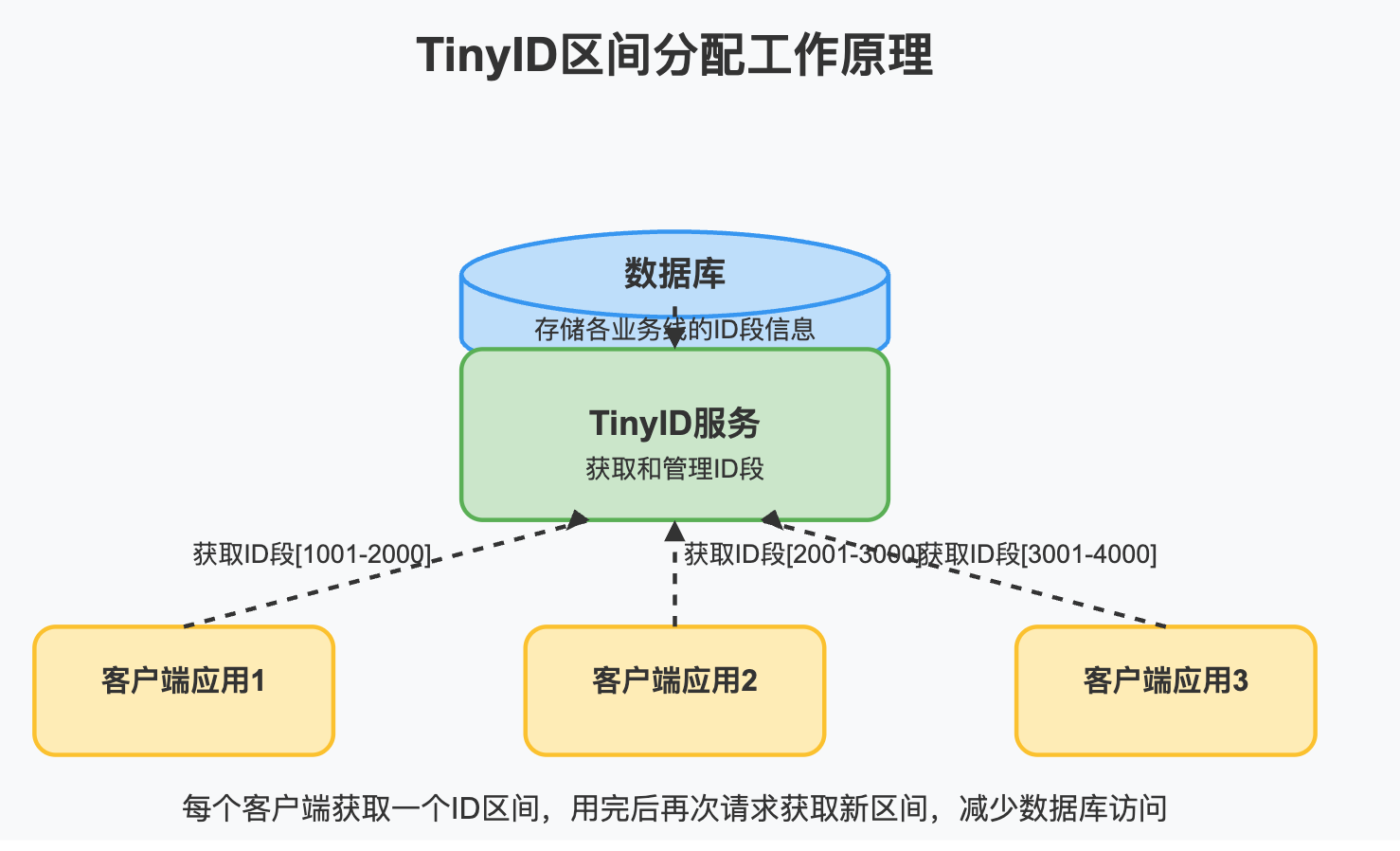
优点:
- 每次获取一段ID,减少数据库/服务访问
- 双buffer设计,在当前号段用尽前异步加载下一批
- 简单易懂,实现难度低
缺点:
- ID不包含额外信息
- 重启服务后可能会有ID跳跃
- 数据库仍是瓶颈
如何选择最适合你的分布式ID方案?
选择分布式ID生成方案需要考虑以下几个因素:
- 系统规模:小型系统可以使用Redis或数据库自增;大型系统考虑雪花算法或百度UidGenerator
- 性能要求:高并发场景建议使用雪花算法或百度UidGenerator;低并发场景可以使用UUID或数据库自增
- 可读性:需要人类理解的ID不要用UUID
- 实现复杂度:团队技术能力有限时,选择简单方案
- 业务特点:是否需要包含业务信息
这里给出一个简单的决策流程图:
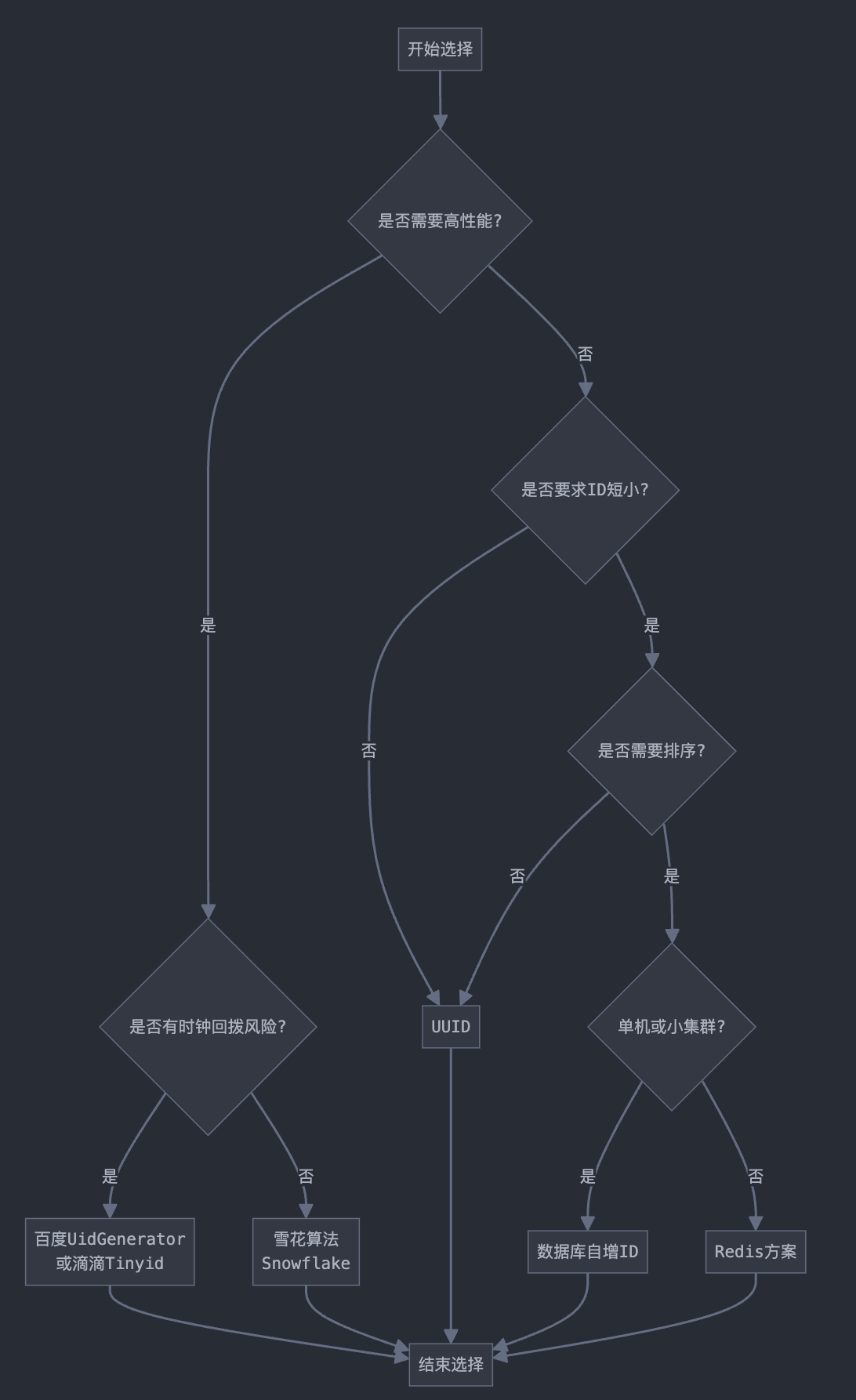
分布式ID在面试中的常见问题
作为一名Java架构师,你需要掌握以下关于分布式ID的面试问题:
-
为什么不能用UUID作为分布式ID?
答:UUID虽然简单,但存在主键过长、无序性导致B+树索引效率低、无业务含义等缺点。 -
雪花算法的组成部分是什么?如何解决时钟回拨问题?
答:雪花算法由1位符号位、41位时间戳、10位工作机器ID和12位序列号组成。解决时钟回拨可以通过记录最后时间戳,发现小于上次时间时拒绝服务或等待时钟追上。 -
如何保证分布式ID的单调递增?
答:可以通过时间戳+序列号的方式,或使用数据库自增特性,或Redis的incr操作等保证递增。 -
分布式ID生成需要考虑哪些因素?
答:全局唯一性、高性能、高可用、趋势递增、信息安全等。 -
百度UidGenerator的优势是什么?
答:性能更高(RingBuffer)、解决了时钟回拨、提供workerId动态分配、可自定义各部分位数。
项目实战:构建高可用分布式ID服务
如果需要在实际项目中使用,我推荐使用Spring Boot封装一个基于雪花算法的分布式ID服务,并提供HTTP接口供其他服务调用:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.stereotype.Service;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.annotation.PostConstruct;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
@SpringBootApplication
public class DistributedIdApplication {
public static void main(String[] args) {
SpringApplication.run(DistributedIdApplication.class, args);
}
}
@Configuration
class IdGeneratorConfig {
@Value("${snowflake.datacenter-id:1}")
private long datacenterId;
@Value("${snowflake.worker-id:1}")
private long workerId;
@Bean
public SnowflakeIdGenerator snowflakeIdGenerator() {
return new SnowflakeIdGenerator(workerId, datacenterId);
}
}
@Service
class IdService {
@Autowired
private SnowflakeIdGenerator snowflakeIdGenerator;
// 获取单个ID
public long getId() {
return snowflakeIdGenerator.nextId();
}
// 批量获取ID
public List<Long> getBatchIds(int size) {
List<Long> ids = new ArrayList<>(size);
for (int i = 0; i < size; i++) {
ids.add(snowflakeIdGenerator.nextId());
}
return ids;
}
}
@RestController
class IdController {
@Autowired
private IdService idService;
@GetMapping("/id")
public Result<Long> getId() {
return new Result<>(200, "success", idService.getId());
}
@GetMapping("/id/batch/{size}")
public Result<List<Long>> getBatchIds(@PathVariable int size) {
// 限制一次最多获取1000个
if (size <= 0 || size > 1000) {
return new Result<>(400, "批量获取ID数量需在1-1000之间", null);
}
return new Result<>(200, "success", idService.getBatchIds(size));
}
}
// 统一响应结果
class Result<T> {
private int code;
private String message;
private T data;
public Result(int code, String message, T data) {
this.code = code;
this.message = message;
this.data = data;
}
// getter和setter省略
public int getCode() { return code; }
public void setCode(int code) { this.code = code; }
public String getMessage() { return message; }
public void setMessage(String message) { this.message = message; }
public T getData() { return data; }
public void setData(T data) { this.data = data; }
}
/**
* 雪花算法实现类 - 这里直接使用前面定义的SnowflakeIdGenerator类
*/
class SnowflakeIdGenerator {
// 上面已经提供过详细代码,这里不再重复
// ...
// 添加健康检查方法
public boolean isHealthy() {
long id1 = nextId();
long id2 = nextId();
return id1 < id2; // 确保生成的ID是递增的
}
}
如何确保高可用?
在生产环境中,分布式ID生成服务往往是整个系统的基础组件,它的稳定性直接影响整体系统。以下是提高可用性的几个关键点:
- 多机房部署:在多个数据中心部署ID生成服务
- 服务监控:实时监控服务状态、QPS等关键指标
- 合理分配workerId:避免冲突,可以使用Zookeeper管理
- 处理时钟回拨:增加回拨检测和恢复机制
- 批量获取策略:允许客户端一次获取多个ID,减轻服务压力
- 降级策略:例如在特殊情况下降级为UUID
实际应用时的扩展思考
当我们将分布式ID生成用于实际项目时,还可以考虑以下扩展:
- 业务ID拓展:在高位增加业务类型,例如订单系统可以嵌入"交易类型"
- 分段缓存机制:提前生成一批ID并缓存,避免生成ID成为瓶颈
- 号段预留:为未来可能的系统变更预留ID空间
- 多级缓存:客户端缓存+服务端缓存,减少网络请求
- 分区表支持:结合分表键自动路由
总结
分布式ID方案比较:
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| UUID | 实现简单,无需外部依赖 | ID过长,无序,索引效率低 | 对性能要求不高,无需排序 |
| 数据库自增ID | 实现简单,有序递增 | 单点风险,扩展性差 | 小型系统,数据量不大 |
| 数据库多主模式 | 解决单点问题,有序 | 扩展性有限,步长固定 | 中小型系统 |
| Redis | 实现简单,性能高 | 依赖Redis可用性 | 中型系统,有Redis基础设施 |
| 雪花算法 | 性能高,无外部依赖,包含时间信息 | 时钟回拨问题,手动配置workerId | 大型分布式系统 |
| 百度UidGenerator | 超高性能,解决回拨问题 | 实现复杂,依赖数据库 | 超大型分布式系统 |
| 滴滴Tinyid | 实现简单,批量获取 | 依赖数据库 | 对可用性要求较高的系统 |
选择最适合项目情况的方案才是最好的方案。在实际应用中,可以基于业务特点进行定制化。
作为初学者,建议先从理解雪花算法开始,它是大多数互联网公司分布式ID方案的基础,也是面试的高频考点。掌握了雪花算法,再去了解其他方案就容易多了。
希望这篇文章能帮助你从零开始,全面掌握分布式ID生成这一重要技术!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









