






HR问题
1.自我介绍
姓名→来自于什么地方→来上海多久了→在这个行业已经多久了→从什么开始→刚开始做什么→后来又做的什么
例如:经理(如知道姓的情况下,带姓问候)您好,我这边情况大概是这样的,我叫xxx, 老家是xxx的,在这个行业大概干了有xx年,刚开始在xxx公司,xxx公司做主要负责xxx项目,主要做一些xxx测试,干了大概xx年,目前在xxx公司,负项目的测试主要负责xxx的测试,技术方面的话,目前技术方向掌握的有: 功能测试、后台接口自动化测试、性能测试、,大概的情况就是这样。
2.怎么入行的?为什么从事这个事业?
- 亲属带入行
- 经过培训入行
- 当时大学选修计算计里面的java和数据库,而且因为当时在计算机协会担任副会长职位,所以实习就跟计算机系的一起出来了,因为毕竟不是专业学计算计的所以选择了软件测试这块的工作
3.你上份工作为什么辞职?
- 换省份工作了
- 项目组位置变了
- 现在项目已经收尾,活不多,一天去了也没社么事,再待下去就荒废了,所以想换一个工作,顺便提高下自己的技能和工资待遇
4.你觉得你有什么优点?
我觉得在项目中不管是测试还是沟通都能够轻松胜任,接收能力,和适应能力感觉还是可以的
5.你觉得你有什么缺点?
感觉在工作中自己比较急性子,有的时候老是想法工作早早做完,催开发催的比较急。
6.你能适应加班吗?
加班这块我还是能适应的,因为目前还是单身,没啥顾忌的。咱这个行业都懂的,加班是家常便饭了,以前公司到项目末期赶进度连续3个月的996,也是扛下来了。这块不是太大问题,但是也要合理的休息,不能半年996,这样人的精神状态就不好了。
7.你们公司有多少人,有多少测试?有多少开发,人员结构是怎么样的?
我们公司总共的人数我是没注意,整个IT部门大概百十号人,因为有好多项目,我们组大概10来个开发,2个测试。
8.今天我们就谈到这,你有什么要问的吗?
- 我想问问我们这边测试团队大概多少人?
- 目前项目的进度是迭代还是新项目启动?
- 项目是否稳定是否做完就停止了?
9.日常的工作内容?
先看看邮件有没有新的安排(会议、新模块提测,紧急的需求,看下自动化项目有没有报错,因为开发都加班的),看下昨天提交的bug有没有修复,然后根据之前的工作安排接着进行测试(有新需求就写写用例,准备下测试数据等),晚上下班前提一下日报。
10.上家公司做什么的?你负责哪个方面?
结合项目
11.在哪读的大学?什么专业?都学了什么?
结合自身情况
12.谈谈软件测试职业发展,以及个人3-5年的打算
测试经验越多,测试能力越高。所以我的职业发展是需要时间积累的,一步步向着高级测试工程师奔去。而且我也有初步的职业规划,前3年积累测试经验,按如何做好测试工程师的要点去要求自己,不断更新自己改正自己,做好测试任务。
13.你希望的待遇为多少?
结合自身情况
功能测试
1.什么是软件测试
软件测试,就是在整个测试过程中,尽可能的多发现软件的bug(缺陷),并且各项指标达到需求规格说明书要求,比如软件的功能是否正确、软件的兼容性、易用性、可靠性、安全性、还有软件的性能是否符合要求
a.常用的浏览器有哪些: 谷歌(chrome),IE,火狐(firefox) 360
b.常见的系统有哪些: windows系统(PC端) linux系统(PC系统) unix
ios系统 安卓系统(APP系统)
2.软件测试的分类
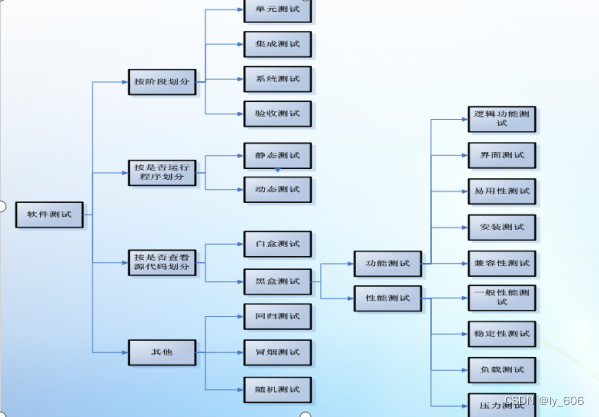
集成测试:集成测试我理解的分为两种,一种是在一个项目中,在单元测试基础上的,根据业务线把多个接口连接起来测试,就是集成测试。例外一种是跨项目集成,比如项目之间存在接口调用关系,这种我理解为多平台集成测试。
系统测试:整个软件前后台都开发完成后,对软件的 兼容性、易用性、可靠性、安全性、 还有软件的性能进行整体测试。
验收测试:测试人员测试完成后,移交给业务人员进行的UAT验收测试。
静态测试:不实际运行被测软件,而只是静态地检查程序代码、界面或文档中可能存在的错误的过程。
动态测试:实际运行被测软件,输入相应的测试数据,检查实际输出结果和预期结果是否相符的过程。
白盒测试: 查看源代码进行查找缺陷。
黑盒测试: 不需要查看源代码。
随机测试也称为猴子测试,是指测试中所有的输入数据都是随机产生成的,其目的是模拟用户的真实操作,随意向系统输入操作。
功能测试:主要检查实际软件的功能是否符合用户的需求。
功能测试又可细分为:
逻辑功能测试:检查逻辑是否正确。
界面测试:验证软件用户界面的设计是否合乎用户期望或要求。它常常包括菜单,对话框及对话框上所有按钮,文字,出错提示,帮助信息等方面的测试。
易用性测试:从软件使用的合理性和方便性等角度对软件系统进行检查,来发现软件中不方便用户使用的地方。
安装测试:是验证软件能否正常进行安装和卸载的测试。
兼容性测试:兼容性测试常见的比如 PC端,我们主要测试浏览器的兼容性,比如 谷歌,
Ie,火狐,360的兼容性。手机APP端,我们一般验证,安卓和ios系统的各个版本,是否兼容,还有安卓系统也要验证不同品牌手机的兼容性。
性能测试:主要是验证系统的性能指标是否满足需求要求。
回归测试:版本迭代过程中,上线前,就是重复执行以前测试时的测试用例,看看老的版本功能是否正确。
什么是返测: 返测是开发人员修复好bug后,对bug进行验证。
冒烟测试:是指在对一个新版本进行系统的大规模测试之前,先验证一下软件的主流程是否正常,是否具备可测性。
随机测试:是指测试中所有的输入数据都是随机生成的,其目的是模拟用户的真实操作,并发现一些边缘性的错误。
什么是Alpha测试(α测试)?
通常也叫“验证测试”:主要是指在软件开发完成以后,在软件开发环境下,开发方对要提交的软件进行全面的自我检查与验证(开发人员自测)。
开发方通过检测和提供客观证据,证实软件的实现是否满足规定的需求
什么是β测试
β测试就是我们常说的uat测试,测试人员完成测试后,移交给业务人员进行uat验收测试。
3.你们公司有几套环境
<1:我们公司环境是这样:
有开发环境,开发人员使用的,
测试环境有3套,常规版本用两套,紧急版本用一套,
还有uat测试环境,这个是业务做uat测试用的。
还有生产环境--》真正供用户使用的环境,一般出现问题,
去上边跟踪日志(权限非常小)。
<2: 这几套环境的流程?
1.开发环境下,各个开发人员开发好自己的功能后,移交到
测试环境(这个过程一般如下: 开发开发好功能,提交代码到
测试环境,重新部署测试环境)
2.测试完成后,运维人员会把最终正确的版本发布到生产环境。
<3. 常规版本和紧急版本的作用
1. 一般情况常规版本用来发布 每个月规定的版本,比如我们项目一个月有
2个版本,发布日期都是确定的,就用常规版本来测试。
2. 一般项目有紧急需求的话,或者生产出问题,我们使用紧急版本进行测试。
4.软件生命周期
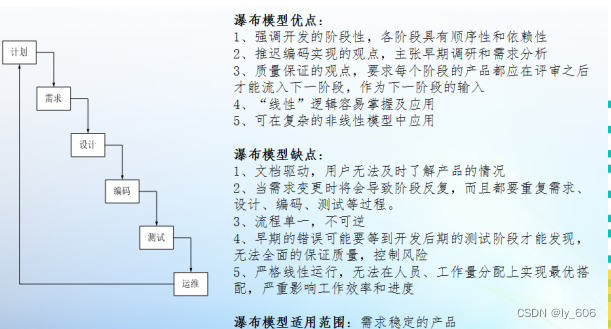
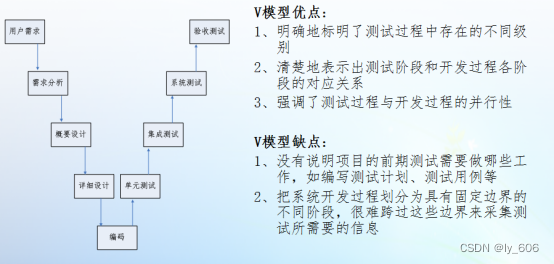
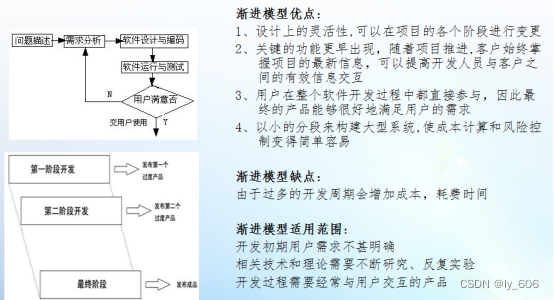
敏捷开发 对应--》敏捷测试
5.什么是敏捷测试?或者叫迭代测试?
敏捷、渐进、迭代测试就是说项目为了快速上线供客户使用,先出一个基础版本,再在
这个版本基础的上不断的进行迭代开发、测试、上线。我们公司基本上一个月有两个版本。
6.敏捷测试测试要点在哪?
敏捷测试如果迭代的速度比较快的话,一定要做好回归测试,在迭代过程中,新的功能可能在上个版本的功能上进行更改的,所以如果回归测试没有做好的话,容易漏测试点。老的功能比较容易出问题。这也是敏捷测试比较大的风险。
7.你们公司做软件测试的流程是怎么样的?
我们这边是这样的,首先需求下来以后,我们开一次需求评审会议(有开发人员,测试人员业务人员),对下个版本的需求进行评审,需求搞明白以后,我们就写测试大纲,测试大纲和测试案例,案例写完做一次案例评审(一般都是项目组内部评审),然后进入测试阶段,测试出问题提交bug跟踪bug,所有案例测试完成和回归测试完成后 ,发系统测试报告,然后移交给业务人员进行UAT测试,UAT那边测试完成后发 UAT验收报告,功能这块是这么做的。 功能测试完成后,有的项目我们还需要维护自动化脚本,如果新项目我们还需要做性能测试。
6.你是怎么做手机测试的?
其实手机测试的分析方法和pc端测试所用的测试方法基本是一样的,但手机测试需要额外的测试一些内容比如:
- 兼容性测试:a. Android、iOS各个主流版本的兼容性
b. 不同手机分辨率的兼容性
c. 弱网测试
追加问题:弱网测试怎么做的?
- 安装卸载测试
- 跨版本升级测试
- 关联性测试: 主要测试客户端与PC端的交互,客户端处理完后,PC端与客户端数据一致
7.手机app你们使用的是什么工具?
我们目前测试这一块都是用真机进行测试。
8. 什么是测试计划,谁负责写?测试计划包含哪些内容?
测试计划包含项目的测试进度、人员安排、任务分配等内容。一般测试经理编写。
9. 什么是测试大纲,谁负责写?测试大纲包含哪些内容?
测试大纲简单来说就是测试案例的简化版,正式编写测试案例之前,理出来的大体的
测试主流程。一般测试人员编写。
10. 什么是系统测试报告,谁负责写?系统测试报告包含哪些内容?
系统测试报告是测试人员测试完成之后移交UAT人员的报告,其中包含,当前版本的所有的需求点,所有需求点对应bug数量,bug是否已经修复完成等内容,如果是未修复完成的bug,要标注清楚,还需要未修复原因。测试是否通过出口标准等内容。
11. 什么是UAT验收报告,谁负责写?UAT验收报告包含哪些内容?
UAT验收报告UAT人员的测试结果报告,其中包含,测试是否通过出口标准,测试案例清单,测试缺陷清单等内容。
12. 什么是缺陷?
缺陷就是bug,比如设计的功能和需求说明书有出入、兼容性、易用性、性能不不达标等都算的上是缺陷
13. 定义缺陷的5大规则

14.什么是缺陷报告?
当测试人员发现了一个缺陷,需要填写一份“缺陷报告”来记录这个缺陷,并通过这个缺陷报告告知开发人员所发生的问题——缺陷报告是测试人员和开发人员交流沟通的重要工具。
15. 缺陷报告包含什么?
缺陷编号
缺陷标题
缺陷的发现者
缺陷所属的模块
发现缺陷的日期
在哪个版本中发现的缺陷
测试环境(机型、系统、环境)
指派给谁进行处理
缺陷的重现执行步骤:包含执行步骤和数据
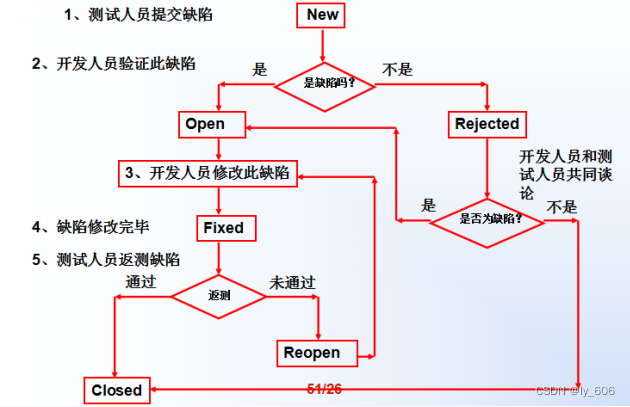
16. 缺陷的状态
新提交的缺陷——new
打开的缺陷——open
被拒绝的缺陷——rejected
已经被修改完的缺陷——fixed
重新打开的缺陷——reopen
关闭的缺陷——closed
17. 缺陷的严重程度
小的功能问题——Low
中等程度的功能问题——Medium
大的功能问题——High
非常严重的功能问题——Very High
造成死机或影响开发、测试进度的问题——Urgent
18. 修复缺陷的优先级
Low——允许在发布产品中存在
Medium——发布之前修复
High——下一个版本修复
Very High——本版本修复
Urgent——立刻修复
19.关于优先级的注意点
缺陷的严重程度和优先级并不一定成正比关系
缺陷的严重程度确定好以后,一般就不再做更改了;而优先级确定好以后,可能根据实际情况会适当调整。
不是所有已发现的缺陷都会被修复的
20. 缺陷报告的处理流程
我在工作中常用的方法有: 等价类划分、边界值、场景法、因果图、判定表法
错误猜测等方法。用的比较多的还是场景法,根据需求去分析业务流程,尽可能多的找
出多个测试点,对于非正常流程的测试点更要多去分析,因为往往项目上线后出问题,
不是正常流程出问题,而是各种非正常的情况出问题。
22.你在实际测试中遇到最麻烦的问题是什么?
需求不明确问题:
有的时候需求文档给的不明确,要多次和业务去沟通,还有的时候业务给的需求很多有问题,写测试案例,不但要理清楚需求,还要对需求进行合理性分析,需求感觉有问题需要和业务去讨论,这个花费时间是最大的,也比较麻烦。
需求变更问题:
有的时候项目时间比较紧,需求变更后,可能没有时间进行全面的回归,这时候我们需要分析,需求变更的模块可能会影响到其他哪些模块,要对这些模块进行局部回归,这些也是最麻烦的。
项目管理规范问题:
比如公共接口的更改,有的开发人员为了自己的需求把公共接口改掉后,可能这个公共接口其他平台也在用,但是其他平台测试人员并不清楚接口已经被更改掉,其他项目上线后会出问题
其他问题:
还有一些问题比较难追踪,比如开发人员日志打印太少,这个时候看日志追问题是个比较麻烦的事情。
23. 你觉得做测试最重要的是什么?
1.我觉得做测试最重要的是分析能力,对需求进行深度分析,不能遗漏测试点,常见的测试点一般的开发都能想到,主要是这些细节测试点,往往那些遗漏的测试点最容易出问题。
2.其次是具备一些开发知识,比如说做接口测试,自动化测试我们需要和开发去沟通,接口的请求方式,是基于什么协议的,知道具体的协议后,我们能够选择比较合适的工具进行测试,比如接口发布的是webservice协议,我们使用soapUI这种工具更方便测试,基于普通的http或者https协议用jmeter测试更容易测试。还有比如做一些性能、自动化测试需要具备开发的知识。
3.还有就是沟通能力,做测试需要和开发业务打交道,要能够很流畅的沟通,是做测试的基本条件。
24. 在工作中你觉得是一个bug,开发认为不是bug,怎么办?
这种问题其实大部分集中在对需求的理解不同,出了这种问题先和开发人员一起分析需求,看看需求谁理解的需求是正确的,如果说还有问题,一般都是一起和业务进行沟通来确定这块的需求。
25.需求不懂怎么办?
一般情况下,我们这边会先把需求发出来,看了之后我会把需求的问题整理出来,需求评审的时候提出来,或者在写测试案例过程中,发现一些细节不明确,就写邮件和业务去确认需求,也把开发抄上大家一起讨论
26. 给一个具体对象怎么测?比如一个水杯、一个笔、电梯等等
功能度:用水杯装水看漏不漏;水能不能被喝到
安全性:杯子有没有毒或细菌
可靠性:杯子从不同高度落下的损坏程度
可移植性:杯子在不同的地方、温度等环境下是否都可以正常使用
兼容性:杯子是否能够容纳果汁、白水、酒精、汽油等
易用性:杯子是否烫手、是否有防滑措施、是否方便饮用
疲劳测试:将杯子盛上水放24小时检查泄漏时间和情况;
外观测试
28. 如何验证数据的正确性?怎么确保你本次测试是符合预期的?
29. 你自认为测试的优势在哪里?
我的觉得自己在分析能力上要好一些,对于一个需求搞懂需求后,不仅仅测试正常的流程,还要测试各种异常流程,还有对需求一定要吃透,这个才是最重要的,还有就是责任心,我觉得测试工作一定要严谨,测试一定要有耐心还有责任心,还有就是经验,功能测试,接口测试,性能测试都做过,我觉得经验也是宝贵的财富。
30. 给你一个需求你怎么去测试?
首先先要划分模块,搞懂需求,分析每个需求的测试点,比如分析正常的流程,再分析各种异常流程,还有了解功能对应的表结构,理解和分析需求其实占了70%的时间,然后写测试案例,执行测试案例,跟踪bug,测试完成提交系统测试报告
31. 经常和开发沟通哪些问题?
对于复杂的功能,经常对一下需求,看看和开发理解的时候一致,出现问题也和开发讲一声,让他们尽快处理。
32. 你觉得测试哪些地方容易出问题?
1.功能测试方面的话,开发人员更偏向于正向的需求逻辑,往往在异常的测试点上出问题,所以我们测试要尽可能多的深刻的分析测试点。还有一些细节问题,比如登录后每个页面的session验证,这个也是我们容易忽略的。
2.接口测试的话我感觉,事务的回滚,有的时候一个业务流程可能会对好几张表的DML
操作,如果业务流程失败,我们必须进行事务回滚,把对表的操作还原回来。
3.性能测试问题比较常见的是事务响应时间过长,往往是表的数据量比较大,或者SQL写的不够好,导致缓慢。需要对数据库操作进行优化
33. 印象最深刻的bug是什么?
结合项目情况
34. 测试过程中你都经常碰到哪些问题?
经常碰到的问题最简单的就是功能逻辑有问题,代码缺少对异常流程的控制。
还有页面点击报 404 /500 等错误,500比较多,页面直接抛出各种异常,比如报Type Error 等问题。还有接口测试中,接口逻辑出现问题,事务回滚问题经常不进行处理,异常抛出不明确,各种问题感觉太多了。
35. 如果你发现是一个bug,开发人员不承认。怎么办?
这问题也是碰见过,主要就是说对一些复杂需求开发和测试理解有分歧,基本上和开发进行讨论,看到底按谁的思路来,如果说没有确定答案,找业务人员进行确认就好了。如果感觉业务人员给的答案不满意,和自己的测试经理沟通下,并且保留与开发还有业务人员的邮件往来,留个底。
36. 目进度比较急,测试不完怎么办?
这个问题经常有,有的时候版本比较赶时间,所以一定要跟开发商量好,让开发把模块的开发顺序调整下,尽量先开发影响其他模块测试进度的模块,保证我手里有活干,一般我们一个人测试好几个开发的功能,一个功能卡住,切换另外的功能进行测试,一定要和开发保持密切沟通,还有一定要催开发提高改bug的效率。如果实在是测试不完,一定要提前和测试经理沟通这个风险,比如有的bug修改起来非常麻烦,这时候可能会把某些需求砍掉,放到下个版本再上线。
37. 需求不理解怎么办?问开发吗?
我这边需求问题一般直接和业务这边进行沟通的,测试前大概和开发进行沟通看看开发和我理解的思路是否一致。
38. 怎么样才算测试完成?
测试完成后会发 系统测试报告,移交给UAT ,UAT验收完成发UAT验收报告。代表整个测试完成。
39. 你们缺陷是怎么管理的?
使用禅道项目管理工具进行管理的,可以在工具上提交,跟踪,查询BUG
40. 你们需求是怎么管理的?
在管理工具上直接下,或者在SVN下直接下,或者邮件直接发
41. 你们公司用的什么bug管理工具?
jira、testlink、禅道
42. 案例写在哪?
一般是写在excel里面,让后导入到项目管理工具里面的
43. 导入测试案例?
首先我们从禅道工具里面导出写案例的excel模版,写完以后可以再把写好的文件导入到禅道中。
44. 怎么样才是好的缺陷报告
标题简单明确,明确当前版本环境缺陷状态,缺陷所属版本,指派给谁,缺陷描述包含缺陷具体的描述和重现步骤,页面问题截图,重现步骤描述要非常清晰,最好有错误截图和后台日志错误截图。
45. 出现bug怎么去分析?定位问题是前端的问题还是后端的问题?页面上点击按钮没反应你怎么办?
1、先判断是前端还是后端的问题,我们可以用fiddler进行抓包,看看请求和响应数据,如果请求数据发送的有问题,比如发送数据少了字段,那就是前端的问题。如果抓到的请求和响应的数据都没问题,有可能是前端拿到响应结果展示在页面上的时候前端代码写的有问题。
2、如果后台报500,肯定是后端问题,我们需要重现BUG,用 tail -f 跟日志文件名
实时监控日志文件,分析日志看看是什么问题,比如出现像一些Error/Exception等,我们可以根据这些异常信息分析错误。
46. 系统上线发布后出现问题怎么办?
首先了解bug信息,判断其重要程度,重现bug,跟踪问题,找到原因,如果是测试的问题,主动承担责任并作出总结,避免下次再犯,而如果是其他的问题,比如团队协调上的问题,我们需要将此问题反馈给上级并给出好的建议,同时也要做出总结,以后可能会遇到各种各样的问题,那么作为测试,我们应该尽可能的做好多种场景的预测,防范于未然。
47. 在测试过程中比较容易忽略的测试点有哪些?
1.新的手机号码段的正则校验:如199、191、166等
2.金额问题,单位转换
3.删除操作中断
4.越过登录认证直接访问
5.客户端安装卸载测试
47.1 文件上传下载怎么去测试?
文件下载或者导出功能:
- 测试的时候我们注意一定要测试中文导出的情况,看看有没有乱码问题
- 导出的数据格式,内容和条目数都正确。
导入/上传功能:
比如有功能是上传excel文件内容的,我们需要测试
- 上传格式必须正确,不允许上传除xls和xlsx文件格式之外的其它格式。
- 文件的大小必须要有限制。
3、文件导入后的数据格式,内容和条目数都正确。
48. 你测试的时候比较难测试的有哪些?
1. 需求不明确
2.需求变更频繁
49. 测试环境怎么部署/项目发布流程?
1.测试环境部署的话比较简单,开发把项目通过git或者svn等工具提交到测试环境
服务器,然后用Jenkins进行项目构建。Jenkins中有一些触发器,比如代码更新的时候自动部署,或者设置时间自动部署,当然也可以进到手动部署。和我们把接口自动化脚本挂到Jenkins上差不多
2.项目上线这块,项目上线我们是用的是替换war包的方式,每个版本的代码都打成war包,放到服务器上进行部署。
50.你去一个新项目组怎么去测试?/如果你来我们公司的话怎么去测试?
如果是新项目组或者是新公司,我会先熟悉我们项目组和我工作有关系的人,我需要明确谁是我上级,谁做需求这一块,我负责测试的项目是哪些开发负责的。这样出问题我知道找谁。再就是熟悉公司大概的业务流程,需求,如果是迭代项目就比较容易,看看老的需求,在页面操作操作基本就OK了,如果是新项目,还是得多问多交流快速搞懂需求。
数据库
- 你知道哪些数据库?常用的数据库有哪些?
我这边在工作中常用的数据库有两种,一种是oracle,一种是mysql
2、一般你使用数据库做什么?
用数据库的话,一般就是有时候做测试需要造测试数据和验证数据库,还有做接口自动化的时候需要使用pymysql进行数据库查询验证结果,还有性能测试里边经常写一些存储过程来造数据。 有的时候,为了解决生产问题,我们会在生产环境上执行一些 plsql的存储过程脚本来修改生产数据,需要我们读懂plsql脚本,并且对脚本进行测试。数据库这块大概我在工作中就用这么多。
追加问题:
- 你是怎么造数据的?
- 自动化怎么验证结果?
- 性能测试怎么造数据?
- plsql脚本是什么?有什么作用?怎么测试plsql脚本?
3、数据库你们用的哪个版本?你们连接数据库用的是什么工具?
oracle用的是11g ,用的连接工具是 plsqldev工具,mysql以前记得用的是5.0版本,用的是navicate远程连接工具。
- plsql怎么连接数据库的?
首先需要下载解压PLSQL压缩包,进入到PLSQL\instantclient_11_2\network\admin目录下,修改tnsnames.ora文件中的ip地址和端口号,然后打开PLSQL Developer配置首选项中的主目录名和oci库,重新打开工具输入用户名和口令后,选择数据库就可以连接数据库了
- Navicate怎么连接数据库的?
下载安装工具后,打开工具选择连接,输入自定义连接名、IP地址、端口号、用户名和密码后即可连接总库,选择分库后即可使用
4、关键字语法
创建表格:
create table 表名(字段 字段类型,字段 字段类型……….);
插入数据:
Insert into 表名 values(字段的值, 字段的值);
更新(修改)操作:
Updeta 表名 set 字段=新值 where 字段=?;
删除操作:
Delete from 表名 where 字段=?;
Drop table 表名;
提交:commit
回滚:rollback
查找表格:
查整表:Select * from 表名;
查表字段:select 字段,字段 from 表名;
过滤(去除重复)功能:select distinct 字段 from表名;
查询包含某数值的数据:select * from 表名 where 字段 in(值,值);
查询不包含某数值的数据:select * from 表名 where 字段 not in(值,值);
表格排列
升序 select * from 表名 order by 字段;
降序 select * from 表名 order by 字段 desc;
大小写转换
更改为大写select upper(字段) from 表名;
更改为小写select lower(字段) from表名;
判断是否为空
select * from 表名 where字段is null
select * from 表名 where字段is not null
聚合函数
求最大值max(字段)
求最小值min(字段)
求平均值avg(字段)
求总和值sum(字段)
统计count(*)
group by 字段 按…分组
函数分组后select后面只能跟组函数或者被分组的字段
分组后过滤用having
5、Oracle数据库有哪些连接方式,他们有什么区别?
等值连接,会把多个表连接的不匹配数据过滤掉。
外连接: 使用 left join/right join/full join 进行连接。主要用来过滤出不匹配的数据的时候使用。
7、常见的数据库数据类型有哪些?
Oracle
CHAR:一个定长字符串,当位数不足自动用空格填充来达到其最大长度。如非NULL的CHAR(12)总是包含12字节信息。
VARCHAR2:目前这也是VARCHAR 的同义词。这是一个可变长字符串,与CHAR 类型不同,它不会用空格填充至最大长度。
NUMBER
DATE
CHAR和VARCHAR2的区别是什么?
CHAR是定长的,效率比较高,但是浪费空间,…
Mysql:INT ,DOUBLE ,DATE ,CHAR ,VARCHAR
8、约束是什么? 常见的约束有哪几种?
约束就是对表字段提出具体的要求,使得用户操作表的时候,必须按照一定的规则进行插入或者更改,删除数据.常见的约束有:
主键约束(PRIMARY KEY):代表该数据唯一且非空
唯一性约束(UNIQUE) :代表该数据不能重复
非空约束(NOT NULL) :代表该数据不能为空
外键约束(FOREIGN KEY) :作用在两张表中,子表不能插入父表不存在的数据,父表不能删除子表已经使用的数据。
检查约束(CHECK) :可以对字段的值进行要求。
9、什么是索引
索引能够优化sql的执行效率,我们可以在经常使用的列上加索引,优化sql的执行效率,比如在经常出现在WHERE子句的列、经常用于表连接的列、经常需要排序(ORDER BY)和分组(GROUP BY)的列上加索引。
10、索引怎么创建
CREATE INDEX 索引名称 ON 表名 (字段,字段...);
11、索引都创建在哪些列上?
经常出现在WHERE子句的列
经常用于表连接的列
该列包含许多NULL值
经常需要排序(ORDER BY)和分组(GROUP BY)的列
12、什么是视图?
视图就是把一条查询语句的结果做成了一张表,把复杂的sql查询结果作为一张表用,简化数据库操作,比如减少每次的关联。也可以对关键表做数据视图,保护原表数据。
13、视图的作用?
把复杂的sql查询结果作为一张表用,简化数据库操作,比如减少每次的关联。
也可以对关键表做数据视图,保护原表。
14、怎么去创建视图?
CREATE OR REPLACE VIEW 视图名as select zhuanye,ruxuedate from student;
15、什么是序列,有哪些作用?
序列用来产生不重复的数字,经常在不重复的字段上使用,可以实现递增。比如我们造数据的时候,需要10000个不同的用户名,我们可以用字符 拼接 序列的方式实现这个功能。
16、创建序列的关键字是什么?
语法:CREATE SEQUENCE序列名INCREMENT BY 1 START WITH 1000;
17、什么是数据库伪列?
数据库伪列的话指的不是明确定义的数据列,但是又确实存在的数据列比如:ROWID和
Rownum,ROWID:是每条数据存储的物理地址,是一个系统自动生成的唯一编号。Rownum:对查询返回的结果集合进行自动编号,从1开始递增,像我们oracle数据库使用分页就可以使用到rownum。
18、常用的伪列有哪些?
在Oracle之中存在的数据伪列:ROWNUM、ROWID。
19、伪列的作用是什么?
ROWID:是每条数据存储的物理地址,是一个系统自动生成的唯一编号。
Rownum:对查询返回的结果集合进行自动编号,从1开始递增,像我们oracle数据库使用分页就可以使用到rownum。
20、数据库分页什么怎么分的,请举个例子
Oracle:
查询工资从高到底的第5条到第10条数据
select *
from (select a.*,rownum ip --第二步伪列实体化成为一个实体字段
from (select * from emp order by sal desc) a)--第一步先排序
where ip > 4 and ip <11;--第三步对实体化的字段进行筛选
mysql:
取前5条数据
select * from table_name limit 0,5
查询第10到第15条数据
select * from table_name limit 9,6
21、To_date 和to_char 的作用?
to_char(字段,'YYYYMMDD') 时间转化为字符
to_date 字符转化为时间
22、mysql和 oracle有什么区别?
Oracle是大型数据库而Mysql是中小型数据库,两个各有优势吧。
首先两个数据库的字段类型不同像oracle使用varchar2 char number等,mysql字段类型没有varchar2,保存数字用int、double等。
还用一些功能两个使用有区别:比如做分页,oracle比较麻烦,需要使用rownum+子查询进行分页在mysql中我们用limit分页很方便。
oracle建表时,没有auto_increment,oracle要想让表的一个字段自增,要自己添加序列,插入时,把序列的值,插入进去。
接口测试协议基础
1、CS和BS的区别
1、基于浏览器访问服务器的结构,就是BS结构,BS结构对应的项目也就是我们常说的web项目,基于客户端访问,就是CS结构。BS因为是基于浏览器的,更方便使用,而CS需要安装客户端,如果软件升级,bs结构只需要升级服务器端,而CS结构需要升级客户端。BS结构相对于CS结构,速度缓慢,CS结构充分利用了客户端机器,速度更快,可实现更复杂的应用。
2、传输层协议TCP和UDP的区别
1、TCP的优点: 可靠,稳定 TCP的可靠体现在TCP在传递数据之前,会有三次握手来建立连接。TCP的缺点: 慢,效率低,占用系统资源高。
2、UDP的优点: 快,UDP比TCP稍安全 ,没有TCP的握手、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接。
3、TCP三次握手
1、第一次:客户端发送验证数据包给服务器
2、第二次:服务器端返回验证数据包数据给客户端确认连接正常。
3、第三次:客户端发送数据给服务器。
4、http和https的区别,什么是SSL
HTTPS,是基于HTTP开发的,HTTPS应用了安全套接字层(SSL)作为HTTP应用层的子层,可以对数据进行加密和压缩,更加安全。
5、HTTP请求(HTTP Request)具体有哪些内容
http 分为请求和响应,请求分为请求头和请求体,响应分为响应头和响应体,请求头用来规定响应的数据格式和发送的数据格式,请求体可以携带数据。响应包含响应头、响应体。响应头用来标识响应的状态、响应的数据格式等信息,响应体里面是服务器端返回的数据
6、get和post的区别
1、GET请求,请求的数据会附加在URL之后,以?分割URL和传输数据,多个参数用&连接,POST请求会把请求的数据放置在HTTP请求体中。
2、get请求使用在url后加?传值,而post使用 请求体传值。
3、POST的安全性比GET的高。比如进行登录操作,通过GET请求,用户名和密码都会暴露再URL上,因为登录页面有可能被浏览器缓存以及其他人查看浏览器的历史记录的原因,此时的用户名和密码就很容易被他人拿到了
7、常见的POST提交数据方式有哪些?
我们常用的数据的格式有 json格式和文本格式
8、常见的响应码有哪些?代表的是什么意思?
2开头的代表请求正常返回。
3开头的代表重定向到其它地方。
4客户端,客户端的请求一个不存在的资源,比如地址不正确,客户端未被授权,禁止访问等。
5开头的代表服务端问题。
9、什么是Http协议无状态协议?怎么解决HTTP协议无状态协议
http是一次请求一次响应,多个请求之间没有关系。像常用的session技术,
其实就是解决请求之间传值的问题,它可以把前边请求的值存起来,在后边请求中
去使用。
10、cookie 和session 的区别
1、cookie数据存放在客户的本地客户端,session数据放在服务器上。比如: 我们在访问网页版登陆某个网站的时候,登录时用户名自动进行显示,是因为浏览器把用户信息保存在了本地机器。
2、cookie不是很安全,考虑到安全应当使用session。单个cookie保存的数据不能超过4K。而session更大。
3、session 是服务器端保存客户数据,比如保存用户的登录信息,可以进行session验证。
11、什么是session验证技术?
比如用户登录支付宝网站后一定时间不进行操作 session失效,需要用户重新登录,再比如只有登录的用户才能访问登录后的页面,这个也需要session验证技术。
接口测试
- 什么是接口测试?
通俗来说就是直接调用开发人员写好的功能API进行测试。比如:开发人员写好 登录、注册等接口后,我们可以直接对接口逻辑进行测试。
2、为什么要做接口测试?接口测试的作用
1、接口测试能够尽早的介入测试,比如 开发只写好了接口,还有没有和页面进行交互,我们可以对接口的逻辑进行测试,尽早的发现问题,解决问题,降低修复bug的成本。
2、接口还应用在集成测试上,比如多个项目之间需要有接口的关联,我们需要先对接口进行联调。
3、常见的接口类型有哪些/你都测试过哪些类型的接口?
1、如果开发人员发布的是webservice服务,通过xml进行数据传输。(接口地址以?wsdl结尾都是webservice服务接口)
2、如果开发人员发布的是restful风格服务,我们可以使用普通的文本格式或者json格式进行数据传输。
4、接口测试步骤/接口是怎么测试的?
1、我们先看看接口是什么类型的服务,根据接口发布的服务不同,需要选择不同的工具进行测试,比如开发人员发布的webservice服务,我们使用soapui进行测试,如果是restful风格的服务,我们使用 jmeter 或者postman等工具进行测试。
2、根据接口文档和业务逻辑分析测试点, 编写测试案例。
3、执行测试案例,发现问题提交bug。
4、接口这块有时候还需要测试接口的性能,接口性能的话,我是用jmeter测试的,先调通脚本,再
进行一些配置,比如读取从csv或者txt读测试数据,加断言和聚合报告等,如果是非查询接口的话还需要配置jmeter连接数据库,使用jdbc request对接口进行回滚。再配置插件,得到接口整个运行过程的TPS和响应时间,我们接口跑性能的话一般一个接口跑个5分钟,看看接口有没有问题。
5、当然接口测试中,经常还有token、session鉴权(鉴定是否有访问权限)等,都需要测试。
6、有的接口还需要调用第三方接口,我们有时候还要写mockserver。总体来说看具体接口的情况,
有的时候没有接口文档,要去用fiddler抓包去测试,具体问题具体分析吧。
追加问题1:数据怎么加密?/怎么生成随机数
-
- 在需要使用加密的数据之前在建beanShell,导入相关的类,使用MD5可以进行加密,并且存在变量中
其他地方用的话使用${变量名}引用该变量



追加问题2:怎么通过jmeter获取随机数?
我们可以通过beanshell用jmeter提供的 RandomString可以生成随机数,然后把生成
的随机数存在变量中,其他地方使用的时候,我们可以用${变量名}生成。
追加问题3:带token鉴权的接口怎么测试?
接口如果带token鉴权的话,入参的时候肯定是有token的,我们需要先进行登录,
并且使用正则表达式提取器提取到token,再在其他地方去使用。
追加问题4:session鉴权怎么测试?
session鉴权的话,他是通过session来做鉴权的,原理是session能够保存数据,其他接口
被调用的时候会先验证session中的值是否正确,比如用户登录,会把用户的用户名密码存在
session中,其他接口要正常调用,必须要先进行登录,再调用其他接口。
追加问题5:fiddler怎么去抓包测试?
打开fiddler通过fiddler打开浏览器,访问我们需要获取接口的功能进行录制,我们能够分析录制下来的具体的请求,拿到关键请求的请求url和请求数据
就可以测试了。
|
|

|
|

5、你是怎么分析接口的?接口测试有哪些测试点
1: 正确的业务流程和各种可能的异常的业务流程。
2: 还有数据库的响应。
3: 再就是一些 必输字段,字段规则的校验我们也要测试。
4: 重要的接口,我们还需要测试事务的原子性,比如接口之间相互调用,或者一个事务操作多张表,有一张表操作失败,其他表的数据需要回滚。(比如一个接口对多张表进行了dml,我们将接口使用到的最后一张表表名改掉,接口执行后代码走到执行sql的时候肯定报错,这时候我们看看对前边的表的操作数据有没有回滚)
5: 如果是当前接口调用第三方接口,除了要测试事务的原子性,我们还需要测试当前接口调用第三方接口超时的情况。(测试方法: 我们自己先写挡板进行测试,测试环境调通后,我们需要第三方提供超时的测试数据,进行测试环境的联调),还有一些核心接口的性能的测试,鉴权的测试等。
6、第三方接口怎么去测试呢?接口联调测试是干什么的,怎么测试的?
案例: 登录接口、短信生成接口:
|
|

|
|

案例:mockserver
|
|

一般我们的接口内部如果调用了第三方的接口, 如果测试环境还不能进行联调, 我们需要先写挡板,进行测试,测试我们自己的接口有没有问题,等测试环境通了以后,我们需要和第三方测试人员进行联调,由第三方提供测试数据,比如 超时 情况的验证,需要第三方提供测试数据。
比如我们登录的时候有个生成短信验证码接口,内部调用了第三方的接口给客户发送短信验证码,前期接口还没有和第三方接口调通的时候,我们需要测试自己接口的话是没办法测试的,
因为第三方接口没有通。我们可以写mock server模拟第三方接口的返回,这样我们的登录接口,生成验证码接口都能测试了,后边我们第三方接口通了,我们再测试一遍就好了。
7、什么是挡板(mock)?
挡板就是和其他接口联调的时候,在没有条件调用对方接口的时候,我们可以自己写挡板返回模拟数据,测试自己的接口是否正确。
8、挡板怎么写?
挡板说白了就是模拟一些不同情况的返回数据,我们可以让开发直接在代码中改一改,让接口返回不同情况的数据,我们也可以写mock server,mockserver的话,我们可以通过python中的flask框架写,并且启动服务。让接口自动调用我们自己写的mockserver内容。我举个例子:比如我们登录的时候有个生成短信验证码接口,内部调用了第三方的接口给客户发送短信验证码,前期接口还没有和第三方接口调通的时候,我们需要测试自己接口的话是没办法测试的,我们就可以写mockserver来模拟第三方接口,然后启动mockserver后,就可以测试了。
9、mockserver具体怎么写?
第一步:导入Flack框架。
第二步:在py文件中写一个方法,并且指定和第三方接口相同的路由,在方法里边的话,我们可以模拟不同的情况,比如模拟第三方短信的时候,传一个特定的手机号,返回 手机号停机,正常的手机号,我们可以随机一个4位验证码返回出去。
第三步:用的时候要运行该py文件,Flack可以把写的接口发布成服务。这样我们要测试的接口运行的时候,调用第三方接口的时候,会自动调用到我们服务的接口。
10、事务的原子性怎么测试?
事务原子性这块没有太好的办法,以前我们的做法是临时更改测试环境的相关表结构,比如一个接口对多张表进行了dml,我们将接口使用到的最后一张表表名改掉,接口执行后代码走到执行sql的时候肯定报错,这时候我们看看对前边的表的操作数据有没有回滚,看看事务是否回退成功。测完再把表结构改过来。
11、测试接口的时候发现哪些bug? 接口经常都会有哪些 bug?
1、接口入参和出参的字段和接口文档不一致
2、 数据库信息更新不全,比如注册这种给数据库插入数据的接口,需要插入多个字段,有的时候开发人员会漏掉一两个字段。
3、业务逻辑有问题,漏掉一些细节逻辑,信息提示不够完善。
12、当一个接口出现异常时,你是如何分析异常的?
1、接口这块报500的错误的比较多,主要是看报错信息,比如什么空指针、sql语句错误、类型错误等在接口日志中能够看得到,具体问题具体分析吧。
13、没有接口文档如何做接口测试
最好是要有一个标准的文档,没有接口文档,那就需要先跟开发沟通,然后整理接口文档。
实在不行,可以通过fiddler在页面上抓包把接口请求地址和发送的数据抓出来也能测试。
追加问题: fiddler怎么抓包抓出接口的?
我们需要打开fiddler录制脚本,fiddler本身能够显示请求和响应的具体的数据。我们有了请求
有了请求数据,就可以对接口进行测试了。
wemall登录接口录制抓取:

14、接口之间关联怎么做?
接口关联来说的话,也就是一个接口的入参是另外一个接口的出参,如果是jmeter工具我们可以使用正则表达式提取器,把需要的数据提取出来,然后保存在一个变量中,在其他地方使用${}引用该变量。比如我们有些接口会使用到 token,token是登录产生的,所以我们要测试这些接口的时候,先要调用登录,把token使用正则表达式提取器保存起来,再把token作为入参调用接口。如果是postman那么需要在请求中的tests模块中设定一个全局变量,去获取响应中要提取的数据,然后在其他接口中使用{{}}进行引用即可
Jmete示例


Postman示例


15、使用soapui怎么去测试?
Soapui的接口地址有个特征,是wsdl结尾的,一般我会先把接口地址粘贴浏览器看看地址是否能够返回一个xml页面,返回就代表接口地址是通的,然后创建一个soap协议类型的项目,然后导入wsdl地址,这样soapui会自动把接口导进来。再输入参数进行测试就好了。
16、jmeter怎么去测试接口?
Jmeter的话创建线程组,创建http请求和查看结果树,然后在http请求中填写内容,如果是post请求需要把请求数据放在jmeter的parameters中或者bodyData中。填写好数据点击运行就好了,当然不同的接口我们需要做不同的操作,比如接口我们需要关联的时候用正则表达式提取器进行关联,接口性能的时候我们要使用jdbcrequest请求,有的时候还有鉴权,像session鉴权,我们每个接口都需要先调用登录再调其他接口。
17、soapui和jmeter 有什么区别?
这两个工具其实各种接口都能测试,但jmeter测试基于webservice服务的接口,需要写xml样式的请求比较烦,soapui测试基于webservice协议的接口,就非常的方便。
jmeter测试restful协议更方便功能也比较强大,比如加断言、关联、参数化等功能都非常方便,比如使用http请求默认值,可以减少工作量。
18、在jmeter中会经常使用哪些配置和功能
做接口测试时常用的功能比如说http请求、正则表达式提取器、断言、查看结果树、信息头管理器等等,事务控制器,如果是性能测试还需要去使用csv数据文件,定时器,聚合报告,jdbc连接配置,jdbc请求和一些插件的监听器等等。
19、信息头管理器主要用来做什么用
通常我们在通过Jmeter向服务器发送http请求的时候,需要对请求头进行设置,
比如发送json格式请求的时候,我们需要设置请求为josn格式。所以信息头管理器
主要的作用就是用来做请求头设置的。
20、postman怎么去测接口
打开工具后创建请求,如果是get请求,点击Params,输入参数及value,可输入多个,即时显示在URL链接上,点击send运行。如果是post请求可以选择表单提交,提交格式可以选择text,json等,会自动创建请求头,然后输入key-value值运行即可,运行后的结果在body查看,接口关联,接口断言都和其他接口有区别。
Python基础知识点
1.基本知识和工具使用
简介:Python 是一种解释型、面向对象、动态数据类型的高级程序设计语言。
特点:
1.简单。python遵循"简单、优雅、明确"的设计哲学。
2.高级。python是一种高级语言,相对于c,牺牲了性能而提升了编程人员的效率。它使得程序员可以不用关注底层细节,而把精力全部放在编程上。
3.面向对象。python既支持面向过程,也支持面向对象。
4.可扩展。可以通过c、c++语言为python编写扩充模块。
5.免费和开源。python是FLOSS(自由/开放源码软件)之一,允许自由的发布软件的备份、6.阅读和修改其源代码、将其一部分自由地用于新的自由软件中。
7.边编译边执行。python是解释型语言,边编译边执行。
8.可移植。python能运行在不同的平台上。
9.丰富的库。python拥有许多功能丰富的库。
10.可嵌入性。python可以嵌入到c、c++中,为其提供脚本功能。
常用术语:
1.IDLE:python自带的编译器
2.IDE: 集成开发环境 ,集成了编辑、编译、运行、调试、部署的软件
提高我们的开发效率。
3.常用ide: Pycharm、VScode、Jupyter notebook
2.安装配置:
Python3下载:Python 官网:Welcome to Python.org
配置环境变量:记得勾选 Add Python 3.x to PATH。
检验是否配置成功 运行cmd 输入 python -V(python 和 -V 之间有空格)
3.python的基本规范
命名规则:
1.名称只能由字母、数字、下划线、$符号组成
2.不能以数字开头
3.名称不能使用Python中的关键字。
命名规范:
a.文件名
全小写,可使用下划线
b.包
应该是简短的、小写的名字。如果下划线可以改善可读性可以加入。如mypackage。
c.模块
与包的规范同。如mymodule。
d.类
总是使用首字母大写单词串。如MyClass。内部类可以使用额外的前导下划线。
e.函数&方法
函数名应该为小写,可以用下划线风格单词以增加可读性。如:myfunction,my_example_function。
f.变量
变量名全部小写,由下划线连接各个单词。如color = WHITE,this_is_a_variable = 1
g.常量
常量名所有字母大写,由下划线连接各个单词如MAX_OVERFLOW,TOTAL。
4.基本数据类型
变量的声明和使用:
a=1
a=1;b=1
a,b,c = 1,2,3
a=b=c=1
标准数据类型:
- Number(数字): Python3 支持 int、float、bool、complex(复数)
- String(字符串): str1 = ‘xiaohua’
- List(列表): list1 = [‘xiaohua’,18,‘女‘]
- Tuple(元组): tup1 = (‘xiaohua’,18,’女’)
- Set(集合): set1 = {11,22,33,44}
- Dictionary(字典): dict01 = {'name': 'xiaohua', 'age': 18, 'sex': '女'}
Python3 的六个标准数据类型中:
- 不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
- 可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
- ·有序:List(列表)、Tuple(元组)、String(字符串);
- ·无序:Number(数字)、Dictionary(字典)、Set(集合)
注释:
# 注释1 注释单行
'''
注释多行
第三个注释
'''
"""
主要用来做文档注释
print(1) # 注释里面的内容不会运行的
"""
Pycharm注释快捷键:Ctrl+/
5.运算符
算术运算符 + - * / %(取余) //(取整)
赋值运算符 = += -= /= //= %= **=
比较运算符 > < <= >= !=(不等于) ==(相等) ,结果只能是False和True
逻辑运算符 and(全真为真) or(全假为假) not(取反)
成员运算符 in(如果在指定的序列中找到指定的值就返回True,否则返回False)
not in(如果在指定的序列中没有找到指定的值就返回True,否则返回False)
身份运算符 is 判断两个标识符是同一对象,直接对比存储地址
is not 判断两个标识符不是同一对象,直接对比存储地址
6.小整数池和大整数池
python中经常使用的一些数值定义为小整数池,小整数池的范围是[-5,256],python对这些数值已经提前创建好了内存空间,即使多次重新定义也不会在重新开辟新的空间,但是小整数池外的数值在重新定义时都会再次开辟新的空间。

大整数池:
大整数池,意思是我们在使用一些工具进行开发python的时候,这些工具又对整数池的范围做了放大,比如我们用的pyChram就是这样。无论是小整数池还是大整数池,都是避免了常用数据的频繁销毁和创建,从而提高效率。
7.数字Number
Python 数字数据类型用于存储数值。
Python 支持三种不同的数值类型:
- 整型(Int) - 通常被称为是整型或整数,是正或负整数,不带小数点。Python3 整型是没有限制大小的,可以当作 Long 类型使用,所以 Python3 没有 Python2 的 Long 类型。
- 浮点型(float) - 浮点型由整数部分与小数部分组成,浮点型也可以使用科学计数法表示(2.5e2 = 2.5 x 102 = 250)
- 复数( (complex)) - 复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型。
Python数字类型转换:
- int(x) 将x转换为一个整数。
- float(x) 将x转换到一个浮点数。
- complex(x) 将x转换到一个复数,实数部分为 x,虚数部分为 0。
- complex(x, y) 将 x 和 y 转换到一个复数,实数部分为 x,虚数部分为 y。x 和 y 是数字表达式。
8.字符串str
1.字符串是 Python 中最常用的数据类型。我们可以使用引号( ' 或 " )来创建字符串。
2.Python 访问子字符串,可以使用方括号 [] 来截取字符串,字符串的截取的语法格式如下:
变量[头下标:尾下标]
索引值以 0 为开始值,-1 为从末尾的开始位置。
3. 在需要在字符中使用特殊字符时,python 用反斜杠 \ 转义字符。
a.\n 换行
b.\t 横向制表符
c.\r 回车
字符串前+r/R 取消转义
- 填充方式:
a.'小花来自{},年龄{},{}来上海工作' .format('北京', 18, '2020年') # 填充的值数量要和{}数量对应
b.'小花来自{},年龄{},{}来上海工作,目前年薪{:.2f}万' .format('北京', 18, '2020年', 12.777777)
c.'小花来自{0},年龄{1},{1}年来上海工作' .format('北京', 18) # 这里 ’北京‘是0号位置 18是1号位置
d. '小花来自{a},年龄{b},{b}年来上海工作' .format(a='北京', b=18)
e. # %s代表字符串类型 %d代表整数 %f代表浮点数,默认保留6位小数
"小花来自%s,年龄%d,%d年来上海工作,目前收入%f万" % ('北京', 18, 2020, 12.77777777777)
9.列表
序列是 Python 中最基本的数据结构。
序列中的每个值都有对应的位置值,称之为索引,第一个索引是 0,第二个索引是 1,依此类推。
切片:变量[头下标:尾下标]
索引也可以从尾部开始,最后一个元素的索引为 -1,往前一位为 -2,以此类推。
常用api:
append() 向列表尾部添加元素
insert(index) 通过下标指定位置插入元素,整个列表也是单个元素
extend() 添加多个元素, 合并列表 ,无法指定位置,直接在尾部添加
remove() 根据元素值进行删除
pop(index) 通过指定下标删除
clear() 清空元素
del 删除对象 :使用del 在python中 del
index() 查找值对应下标位置
count() 查找元素出现的次数
copy() 复制列表
sort() 升序,必须是纯数字或者纯字符
reverse() 颠倒
len() 求列表长度
in / not in
# in(如果在指定的序列中找到指定的值就返回True,否则返回False)
# not in(如果在指定的序列中没有找到指定的值就返回True,否则返回False)
max() 返回列表中最大值
min() 返回列表中最小值
sum() 求和
列表+ 和 * 的操作和字符串相同,+号用来组合列表 *号用来重复列表
10.元组
Python 的元组与列表类似都是有序的,不同之处在于元组的元素不能修改。
创建空元组:tup1=()
序列中的每个值都有对应的位置值,称之为索引,第一个索引是 0,第二个索引是 1,依此类推。
切片:变量[头下标:尾下标]
索引也可以从尾部开始,最后一个元素的索引为 -1,往前一位为 -2,以此类推。
常用api:
count(),统计元素出现的次数
index(),查找元素下标
元组和其它序列一样都可以使用 +/*/len()/in/not
in/max()/min().................
元组不能修改,但是可以拼接
元组中的可变类型是可以修改的
del 删除对象 :使用del 在python中 del
11.集合
集合(set)是一个无序的不重复元素序列。
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
常用api:
集合添加元素 add()
添加多个元素 update()
remove() # 不存在时会报错
discard() # 不存在时不会报错
clear() 清空元素
del 删除集合
集合中的内容不能重复
交集intersection和并集(union)
函数 len()/in/not in/max()/min().................
12.字典
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值 key=>value 对用冒号 : 分割,每个对之间用逗号(,)分割,整个字典包括在花括号 {} 中 ,键必须是唯一的,但值则不必。
值可以取任何数据类型,但键必须是不可变的,如字符串,数字。
常见操作:
通过key获取value:dict1[key];dict1.get(key)
增加单个键值对:dict1[key] = ‘xiaohua’
增加多个键值对:增加多个键值对
修改value值:dict1[key] = ‘xiaohuahua’
根据key,删除value:dict01.pop('name')
清空:dict01.clear()
定义一个空字典:dict1 = dict();dict1 = {}
字典在存储过程中,如果已经有存在的key,新的值会覆盖已经存在的值
获取所有的key,所有的value,所有的键值对:
dict01.keys()
dict01.values()
dict01.items()
13.条件判断
条件判断分为单分支语句、双分支和多分支语句
1.单分支语句语法:
if 条件:
语句块
如果条件成立则执行语句块,反之则不执行语句块
tianqi = input('请输入天气:')
if tianqi == '好':
print('可以晒被子了!')
2.双分支语句语法:
if 条件1:
语句块1
else:
语句块2
如果条件1成立则执行语句块1,其它情况执行语句块2
tianqi = input('请输入天气:')
if tianqi == '好':
print('可以晒被子了!')
else:
print('继续睡觉吧!')
3.多分支条件判断
语法:
if 条件1:
语句块1
elif 条件2:
语句块2
elif 条件3:
语句块3
.....
[else:
语句块4]
sal = int(input('请输入:'))
if 0 < sal < 30000:
print('贫困家庭')
elif 30000 <= sal < 80000:
print('低收入家庭')
elif 80000 <= sal < 300000:
print('小康家庭')
elif 300000 <= sal <= 1000000:
print('中高收入家庭')
elif sal > 1000000:
print('高收入家庭')
else:
print('乞丐')
14.分支嵌套
分支嵌套
语法:
if 条件1:
if 条件2:
语句块2
else:
语句块3
else:
语句块2
code1 = input('兄台,西北玄天一片云,来接下一句:')
if code1 == '乌鸦落在凤凰群':
code2 = input('满车都是英雄汉,来接下一句:')
if code2 == '哪是君来哪是臣':
print('欢迎光临本山寨!')
else:
print('你到底什么人?')
else:
print('哪来回哪去!')
print('下次再来对你不客气!')
15.while循环
while循环语法:
while 条件:
语句块
当条件成立时执行语句块
year = 1
while year <= 2021:
if (year % 4 == 0 and year % 100 != 0) or year % 400 == 0:
print('{}是闰年!'.format(year))
year += 1
1.死循环
常见死循环:
=======案例1:
i=1
while i<= 100:
print(i)
2.while循环使用else语句: 在while...else,当循环判定条件为false时执行else语句块
i = 1
while i <= 10:
print(i)
i += 1
continue
else: # 循环执行完成后,执行else下的代码
print('循环结束')
3.终止整个循环:break
4.跳过本次循环使用continue
i = 0
while i <= 10:
i += 1
if i == 5:
# break # 打印结果: 1,2,3,4 当i=5的时候整个循环终止
continue
print(i) #
16.for 循环
for 变量 in 可迭代数据(str/list/tuple/range()):
循环体
for i in range(0, 5): # 每循环一次,把0-4的数字给 i
print(i) # 打印出:0-4 [0,5)
# range():通常配合for循环使用,生成一个指定范围内的整数队列,每次给for循环的变量重新赋值(自增或自减)
count = 0
for i in range(1, 2022):
if (i % 4 == 0 and i % 100 != 0) or i % 400 == 0:
count += 1
print('一共有{}个闰年'.format(count))
print(count, i) # 490 2021
print('====' * 50)
for 循环嵌套
# 打印九九乘法口诀
for i in range(1, 10):
for j in range(0, i):
print('{}*{}={} '.format(j + 1, i, i * (j + 1)), end='')
print()
冒泡排序:
lst = [15, 20, 7, 22, 30]
for i in range(len(lst) - 1):
for j in range(len(lst) - 1):
if lst[j] > lst[j + 1]:
temp = lst[j]
lst[j] = lst[j + 1]
lst[j + 1] = temp
17.组包/拆包
组包/装包: 通俗的讲,组包就是把多个数据装在一个元组中。
拆包/解包: 把一组数据进行拆分,比如 列表/字典/元组等拆分成单个数据。
# 自动组包:
num = 1, 2, 3
print(num) # (1, 2, 3) 将多个数据组装成一个元组。
# 自动拆包:
my_list = ['xiaohua', 18, '15821212121'] # len(my_list) 3
name, age, phone_num = my_list
# 在打印过程中,如果变量的前边加 * 号,代表拆包
print(*my_list) #
# 注意: 在拆包的过程中,我们可以利用*将多个变量的值存在一个列表中,该*表示组包
names = ('小花', '小王', '小张', '小李', '小龙')
name1, *name = names
18.函数
函数:函数是可以重复使用的一段代码。(比如: print() 、id()、type())
函数的定义规则:
def 函数名([参数1,参数2,...参数n])
函数体(用来写具体的功能)
[return] 代表结束该函数并且返回数据
def add3(a, b, c): # 声明一个函数 名称为 add2,有三个入参,调用该函数时必须传入三个值
return a + b + c # return 代表结束该方法,并且返回 a + b + c 的值
函数的参数定义: 1、必须参数(位置参数) 2、默认参数 3、不定长参数(可变参数) 4、 关键字参数
def test(x, y=5, *args, **kwargs):
print('x的值为{},y的值为{},args的值为{},kwargs的值为{}'.format(x, y, args, kwargs))

作用域: 为了编写可维护代码,我们把很多代码,放在不同的区域中。
模块: 一个py文件称为一个模块。
# 知识点1、变量的作用域:变量分为全局变量(定义在模块中,任何地方都能使用)和局部变量(定义在函数中,只有该函数内有效)
a = 100 # 全局变量,定义在模块中
# 知识点2、global,可以在函数内定义全局变量,只有该函数运行后,该变量才会起作用。
c =100
def fun02():
global c # 声明 c 为全局变量
c = 200
# 知识点3:函数嵌套
def fun03():
a = 10
def fun04():
print('内部函数')
fun04() # 调用 fun04函数
print(a)

# 知识点4: nonlocal # 用来修改外部嵌套函数的作用域的值,nonlocal只能写在嵌套函数中。
def fun05():
a = 10
def fun06():
nonlocal a # 代表该a 为外层函数的 a
a = 20 # 变量a 的值被 20覆盖
fun06() # 调用 fun04函数
print(a) # 20
函数传递值的方式: 值传递、引用传递
值传递: 传递的是变量的值而非变量本身,被传递的变量的值不会被改变
引用传递: 传递的是变量本身,被传递的变量的值会被改变
注意:
1、可变类型(list/dict/set为可变类型)用的是 引用传递
2、不可变类型(number/str/tuple)用的是 值传递
值传递:
def fun1(a): #10
a += 1
print(a) # 11
a = 10
fun1(a) # 值传递 调用fun1方法并且把 a的值 10传送给fun1的b
print(a) # 10
引用传递:
def fun2(lst):
lst.append(3)
print(lst) # [1, 2, 4, 3]
lst = [1, 2, 4]
fun2(lst) # 引用传递: 传递的是 lst变量本身
print(lst) # [1, 2, 4, 3]
使用 lambda 能够实现简单的函数
语法: lambda[arg1,arg2,...]:函数体
fun4 = lambda a, b: a % b # 入参为 a和b,函数体为 a%b
print(fun4(2, 2))
内置函数:python自带的函数
# 常用的内置函数: set/range/len/type/id/print/input/sum/min/max
# 高级内置函数
eval(): 能够识别python 字符串中的 python表达式,并且进行运算
exec()可以识别字符串相对复杂的表达式
filter() 自定义过滤,filter用来过滤序列,过滤掉不符合条件的元素,返回由符合条件元素
map() 会把列表中的每个内容执行,将结果放到另外一个列表,放的是判定的结果
zip() 聚合打包
isinstance() 判断数据类型
19.模块导入
导入单个:import 模块名
导入单个模块下部分内容: from 模块名 import 函数名1,函数名2….
导入多个:import 模块名1,模块名2
导入模块中所有代码: from 模块名 import *
导入模块会存在被导入模块的执行结果。
# 如何规避这个问题:在被导入模块中的 测试代码前 添加 if __name__ = '__main__': 这样就不会在被导入的时候执行
20.通过流操作文件:读和写
1、文件内容读取
第一步: 打开文件 (注意在路径中,有绝对路径[一般从根目录的路径比如: D:\xx\yy..]和相对路径[相对于当前文件的路径])
fr = open(r'./Test.txt', 'r', encoding='utf8') # 打开 当前目录下的Test.txt文件,并且进行读取操作(r代表读取),以utf8的编码格式进行识别
第二步: 文件内容读取
result = fr.read() # 读取文件中所有内容
result = fr.readline() # 读取首行内容
result = fr.readlines() # 读取所有内容,但是会把每一行内容读取到列表中
fr.close()
2、文件的写入
fw = open(r'./Test.txt', 'w', encoding='utf8') # 创建流,指向Test.txt文件,并且以utf8的格式进行解析和写入。
fw.write('小花!!!!!')
fw.write('\n小李!!!!!')
# fw.flush() # 刷新缓存区内容到文件()
fw.close() # 先刷新缓存区内容到文件,并且关闭流
3、传统方式的读和写:好处,不用手动的刷新或者关闭
with open(r'./Test.txt', 'r', encoding='utf8') as fr:
print(fr.read())
with open(r'./Test.txt', 'w', encoding='utf8') as fw:
fw.write('Hello')
21.错误和异常
错误: 不能通过解释器的编译,这种叫做错误
异常: 编译通过,运行出现问题叫异常
# 1、常见的错误:
# print(1 # SyntaxError 语法错误
# print(1) # IndentationError 缩进错误
# 2、常见的异常:
# print(10 / 0) # ZeroDivisionError 除0异常
# print('1' + 1) # TypeError 类型错误
22.异常的处理
try:
语句块1
except 异常类型1:
语句块2
except 异常类型2:
语句块3
...
[else]: else为可选内容,如果没有异常,则执行else中的内容
[finally]: finally为可选内容,不管有没有异常都要执行
执行try中语句块1,如果语句块1出现了 异常类型1则执行语句块2
"""同时处理多种异常"""
num = input('请输入整数:')
try:
result = 10 / int(num) # ZeroDivisionError ValueError
print(result)
except (ValueError, ZeroDivisionError): # 处理 非整数的情况,除数为0的情况
print('请输入正确的数据!')
"""万能处理异常方式"""
num = input('请输入整数:')
try:
result = 10 / int(num) # ZeroDivisionError ValueError
print(result)
except Exception as e: # 如果出现 异常,执行 except下的代码
print('请输入正确的数据!',e)# e代表报错的信息
23.面向对象
知识点1: 面向对象: 面向对象是一个编程思想(一切皆对象)。
知识点2: 类和对象
类: 具有相同特征的一类事物的描述
比如订单,所有的订单都应该有如下功能
静态的内容: 商品编号,商品价格,商品数量,商品信息
动态的内容: 加入商品,删除商品,修改数量
我们可以把订单抽象成(把现实中的订单转换为代码的描述)一个类。
对象: 对象是类的一个具体的实例。(比如 小王订单/小李的订单/)
类和对象的关系: 一个类有无数个对象。
知识点3:类的构成
类中包含属性和方法:
属性: 把静态的内容抽象出来,并且使用变量进行声明(类中的变量就是属性)。
方法: 把动态的内容抽象出来, 并且使用函数进行声明(类中的函数就是方法)。
知识点4:self 代表当前对象
知识点5:类名的命名规范: 所有单词的首字母大写(驼峰式命名),比如:XingGuangStudnet
定义一个类,并且声明 属性和方法 ,创建该类的对象,并且为该对象的属性赋值,再调用该对象的方法。
# 创建类
class Cat:
color = ''
name = ''
def eat(self, food):
print(food, '很好吃!')
# 创建对象
cat1 = Cat()
cat2 = Cat()
# 为对象的属性赋值
cat1.color = '粉色'
cat1.name = 'kitty'
# 对象可以调用类的 方法
cat1.eat('小鱼')
cat1.eat('猫粮')
知识点: 类的属性分为: 类属性和实例属性
1、类属性声明在类体中,类属性是每个对象共有的属性,类属性可以通过 类名.属性名直接访问
2、实例属性,在创建对象之后声明的属性,该属性是某个对象独有的属性,只能通过对象去调用
3、私有属性,如果属性前有__,代表私有属性,只能在该类中使用
class Emp:
emp_name = '' # 类属性
emp_sal = 0 # 类属性
__emp_age = 0 # 如果属性前有__,代表私有属性,只能在该类中使用
# 计算年薪
def year_sal(self):
return self.emp_sal * 12
# 计算请假天数的扣款
def kou_sal(self, day):
return self.emp_sal / 22 * day
print(__emp_age) # 该属性只能在当前类中访问
Emp.emp_sal = 1000 # 类属性可以通过类名直接访问,我们就可以在类的外边修改属性的值
emp03 = Emp()
emp03.comm = 2000 # comm为实例属性,属于emp03对象独有的属性,只能通过emp03来调用
实例方法:最少需要包一个self参数,用于绑定调用此方法的实例对象,实例方法:不能使用 类名.方法名直接调用 (推荐使用实例对象调用)
类方法:用修饰器 @classmethod 来标识其为类方法,对于类方法,第一个参数必须是类对象,一般以cls 作为第一个参数,可以通过类本身和实例对象去访问,推荐使用 类名.方法名 直接调用
静态方法:用修饰器 @staticmethod 来标识其为静态方法,静态方法没有self、cls这样的特殊参数,静态方法无法调用任何类属性和类方法,推荐使用 类名.方法名 调用
class Emp:
emp_no = '' # 类属性
emp_name = '' # 类属性
emp_sal = 200 # 类属性
__emp_age = 0 # 如果属性前有__,代表私有属性,只能在该类中使用
# 计算年薪
def year_sal(self): # 实例方法特点:必须要第一个参数默认传self ,绑定调用方法的实例对象
return self.emp_sal * 12
@classmethod
def kou_sal(cls): # 类方法:第一个参数代表类本身
return cls.emp_sal / 10
@staticmethod
def showtime(): # 静态方法: 没有self、cls这样的特殊参数,无法使用类的属性和方法
# print(emp_no) 会报错,静态方法无法使用类的属性和方法
return time.strftime("%H:%M:%S", time.localtime())
构造方法: 方法名为: __init__ 会在创建类的时候自动执行,利用该特性,我们可以在创建实例对象的同时做一些操作
一般写一个类,如果不声明 __init__ 时会自动使用默认的,默认构造方法一般不显示,如果声明了__init__方法,会覆盖默认的
注意不能同时有两个 __init__ 方法
class Emp:
def __init__(self): #在创建Emp类的实例对象时,python会自动调用Emp类中的__init__()函数,我们重写了以后,会自动完成我们预期的操作
print("构造函数(方法),在创建对象时调用")

魔法方法:
python中的魔法方法:就是可以给你的类添加魔力的特殊方法
如果你实现了这些方法中的某一个,那么这个方法就会在特殊的情况下被python调用
你可以定义自己想要的行为,这一切都是自动发生的,他们经常是两个下划线包围来命名的
比如: __init__\ __new__ \ __del__ \ __len__ \ __eq__等等,魔法函数的功能是很强大的
简单的说就是你重写魔法方法后,在进行某些操作时,会自动调用这些方法
魔法方法功能十分强大,使用时需要十分谨慎
class T1:
def __del__(self): # 重写覆盖了T1类的 __del__() 方法 在销毁实例对象时触发调用,打印'该对象被销毁'
print('该对象被销毁')
print("python的垃圾回收机制执行到这里了")
t2 = T1()
del t2 # 该对象被销毁
24.继承
继承: 子类继承父类(超类、基类),子类就能够使用父类的属性和方法。 子类又叫派生类
继承的好处: 减少代码冗余、提高重用性(子类一旦继承一个父类就可以使用父类所有的属性和方法)
Java中是单继承、python是多继承
继承的语法: 在声明类的时候在类名之后使用(父类1,父类2,...)
class class1:
pass
class class2:
pass
class class3(class1): # class3 类继承了 class1
pass
class class4(class1, class2): # class4 类继承了 class1,class2
pass
方法重写/方法覆盖:子类继承父类,子类和父类有相同的方法。
class Animal:
def walk(self):
print('父类的walk方法')
def say(self):
print('%s 正在咆哮')
class Dog(Animal): # Dog类继承 Animal类
def walk(self):
print('子类的walk方法')
aml01 = Animal()
aml01.walk() # 调用父类的walk方法
dog01 = Dog()
dog01.walk() # 子类的walk方法
super(Dog, dog01).walk() # 子类对象调用父类的walk方法
1、父类如果有 __init__方法, 子类创建对象时,必须调用父类的__init__方法
2、父类如果有 __init__方法,子类也有__init__方法,这时候 子类的__init__方法中,必须调用父类的__init__方法。
格式 父类类名.__init__(入参1,入参2,...) 例如: Animal.__init__(self, country, name, age)
class Cat(Animal): # Dog类继承 Animal类
def __init__(self, color, country, name, age):
self.color = color
Animal.__init__(self, country, name, age) # 调用父类的__init__方法
1、菱形继承、钻石继承
2、在多继承的情况下,子类会先在自己类中去找需要的内容,找不到去 父类中去找。
该顺序按照 __mro__提供的顺序去找。
class A(object):
def test(self):
class B(A):
pass
class C(A):
pass
class D(B, C):
pass
dd = D()
dd.test() # 查找顺序 D B C A O
print(D.__mro__)
1、我们可以使用raise自己触发异常 raise [Exception [, args [, traceback]]]
2、自定义异常:
实际的工程项目中,我们有时候需要定义一个区别于系统的异常类,还好python提供了一个可以自己定义异常类的方法,我们来看下面的代码:
num = int(input('请输入0-100的整数'))
if not 0 <= num <= 100:
raise NotValidNumber("用户输入了无效的数字!")
elif 0 <= num <= 60:
print('不及格')
25.封装
第一层面的封装:把属性和方法组合成一个类,就是简单的封装
第二层面的封装:类中把某些属性和方法隐藏起来(或者说定义为私有的),只在类的内部使用、外部无法访问,或留下少量的函数供外部访问
我们可以使用装饰器:property (property 是属性,表示可以通过类实例直接访问) 和 setter (代表设置属性的值)
class Stu2:
def __init__(self, name, age, sex):
self.__name = name
self.__age = age
self.__sex = sex
@property
def name(self):
return self.__name
@name.setter
def name(self, name):
self.__name = name
five = Stu2('尊龙', 30, '男')
five.name = '小亮' # 实际上还是通过 property和setter 方法去赋值
Python基础面试问题
1.你会开发语言吗?Python这块掌握的怎么样?
语言的话我这块主要用的用的python这一块比较多,自动化这块我们就是使用python这块做的。
2、Python的深拷贝和浅拷贝你知道吗?
python为我们提供了两个拷贝内容的方式,比如我们拷贝一个列表的时候,
浅拷贝 使用的方法是: copy.copy()方法,浅拷贝的话,对象中可变对象中有元素发生变化,
拷贝得到的对象也会变化
深拷贝 使用的方法是: copy.deepcopy(),当原容器对象中可变对象中有元素发生变化,
拷贝得到的对象 不会发生变化
3、列表和字典有什么区别?
(1)列表存储数据是单个数据进行存储,字典是以key-value形式来存储。
(2)获取元素的方式不同,列表通下标获取,字典通过键获取。
(3)数据结构和算法不同,字典是hash算法,搜索的速度特别快。
4、列表和元组有什么不同
(1)列表和元组都是有序的,都可以存放任意数据类型的数据
(2)列表是可变类型,元组是不可变类型
(3)声明列表用[],声明元组用()
5、什么是切片?
Python中有序的这些数据类型,比如:列表、元组、字符串都可以通过下标进行切片,使用切片我们可以得到这些数据中我们想要的一部分内容,语法是: 变量名称[头下表:未下标]
6、常见的排序算法?
我知道的有冒泡排序、选择排序、插入排序,平常不怎么用,就记得冒泡排序这一块,冒泡排序大概的思路的话,举个例子,比如一个列表的长度为5,要进行从小到大排序,我们内循环每次相邻两个值进行比较,如果前边的值比后边的大就进行交换,这样内循环每循环一次,能够确定一个值的位置,外循环循环4次,这样整个列表就排序好了。
7、冒泡排序
lst = [15, 20, 7, 22, 30]
for i in range(len(lst) - 1):
for j in range(len(lst) - 1):
if lst[j] > lst[j + 1]:
lst[j],lst[j+1] = lst[j+1],lst[j]
8、九九乘法口诀表
for i in range(1, 10):
for j in range(0, i):
print('{}*{}={} '.format(j + 1, i, i * (j + 1)), end='')
print()
9、将“hello_new_world”按“_”符进行切割。
print('hello_new_world'.split('_')) # ['hello', 'new', 'world']
10、python的第三方模块/标准库有哪些?
标准库:
time (获取时间)
random (获取随机数)
unittest(测试框架)
os(跟操作系统相关的库,可以处理文件路径及信息)
flask(接口发布服务使用,写mock server的时候使用)
json(处理json格式)
logging(配置日志使用)
第三方库/模块:
requests(模拟发送请求)
openpyxl(读取excel)
ddt(参数化数据使用)
HTMLTestRunner(测试报告使用)
pymysql(连接mysql数据库)
11、常用的内置函数有哪些?
https://docs.python.org/zh-cn/3/library/functions.html
|
|

id() input() str() int() len() max() min()
eval(): 用来识别字符串中的python表达式,比如我们自动化的时候读取,
excel中的数据,默认读进来是字符串格式,我们可以永eval()将数据转换为字典格式。
zip()可以聚合打包,我们可以把两个列表打包成字典。
12、python的pass语句的作用是?
占位符,当方法没有内容时,防止出现语法错误。这样保证在开发代码的时候因为
格式问题报错
13、可变类型和不可变类型的区别
python中常见的可以变类型,比如:列表、字典、集合
数据的内容可以更改。
不可变类型: 数据的内容不可以更改,比如:数字、字符串、元组
14、什么是组包和拆包:
组包/装包: 通俗的讲,组包就是把多个数据装在一个变量中。
拆包/解包: 把一组数据进行拆分,比如 列表/字典/元组等拆分成单个数据。
比如我们把多个散列的值赋值给一个变量,python会自动将这些散列的值组包成一个
元组,如果我们给可迭代对象(字符串/元组/列表等)前边加 * 号,该对象就被拆分成多个
散列的数据,这个是拆包。
15、global 和nonlocal
global,可以在函数内定义全局变量,nonlocal在函数嵌套的时候可以修改外部嵌套函数的作用域的值
16、值传递和引用传递:
值传递: 传递的是变量的值而非变量本身,被传递的变量的值不会被改变
引用传递: 传递的是变量本身,被传递的变量的值会被改变
在python里边
1、可变类型(list/dict/set为可变类型)用的是 引用传递
2、不可变类型(number/str/tuple)用的是 值传递
17、lambda
能够实现简单的函数,格式是:lambda[arg1,arg2,...]:函数体
fun4 = lambda a, b: a % b # 入参为 a和b,函数体为 a%b
18、python函数中入参有哪些格式?
1、必须参数(位置参数) :入参按照位置传递,在调用时入参的元素个数必须相同
2、默认参数 :我们可以在声明方法的时候给入参设置默认值
3、不定长参数(可变参数) :可以保存0-N个入参,一般使用 *args,调用该方法时如果传入多个入参,会自动组包为一个 元组。
4、 关键字参数:关键字参数: 用来接收 key-value格式的入参,一般使用**kwargs保存为一个字典
多种参数混合的使用必须按照顺序放,不然报错。
|
|

19、*args和**kwargs的作用
他们两个在函数中作为入参声明的话,*args代表不定长参数 :可以接收用户传入的多个入参,会自动组包为一个 元组。**kwargs作为入参的话,代表关键字参数,可以保存接收多个以key-value形式保存的入参。会自动将多组数据保存为一个字典。
20、装饰器是什么
装饰器是为已经存在的函数或者对象添加额外的功能。
21、你都用过哪些装饰器
@classmethod 来标识其为类方法
@staticmethod 来表示其为静态方法
@ddt 和@data,结合自动化的时候可以参数化测试数据。
@property可以将方法转换为属性的方式进行访问
22、什么是魔法方法:
python有一些特殊的方法,这些方法就会在特殊的情况下被python调用。比如构造方法__init__,就是在创建类对象的时候自动被调用。我们可以利用这个规则,在__init__方法中干一些事情,比如封装mysql操作,每次都要创建conn对象和cursour对象,我们可以在__init__方法中把这两个对象的创建过程写进去,这样每次只要创建这个类的对象,创建的这个对象就自动有了conn属性和cursor属性。还有很多魔法方法比如: __init__ \ __del__ \ __len__ \ __eq__等等。
23、python构造方法
方法名为: __init__ 会在创建类的时候自动执行,利用该特性,我们可以在创建实例对象的同时做一些操作
24、 如何判断是函数还是方法
通常来说类中的函数为方法,类外面声明def为函数
25、什么是Python面向对象呢?
面向对象我理解的还是 一切都是对象,比如我们在封装 pymysql读取excel的时候,
,会把这些文件看成一个对象(wk = openpyxl.load_workbook())进行解析,
在做接口自动化的时候,会把http请求看成一个对象,所以一切皆为对象。
26、python怎么定义一个函数,怎么定义一个类?
def 函数名:函数体
class 类名:属性,方法
27、什么是继承
继承是面向对象编程的一个重要的方式,通过继承,子类就可以使用父类的功能。python支持多继承,一个类可以继承多个父类。
28、方法重写/方法覆盖:
子类继承父类,子类和父类有相同的方法。
29、菱形继承是什么?
如果一个类继承多个父类,而这些父类又有很多的父类,这时候继承顺序就比较复杂,菱形继承就是在这些父类中搜索内容的时候的一个顺序规则。我们可以打印__mro__属性的值来查看继承顺序。
30、进程、线程有什么区别?
进程想要执行任务就需要依赖线程。一个程序至少有一个进程,一个进程可以包含多个线程,比如启动qq等程序的时候,
|
|

qq会以多进程的方式运行。
31、什么是线程同步和异步:
同步就是顺序执行,执行完一个再执行下一个,需要等待。异步就是彼此独立,在等待某事件的过程中继续做自己的事,不需要等待这一事件完成后再工作。一般的接口都是同步顺序执行的,但是有
的接口做了异步处理,比如支付宝转账,有的时候你转账后发现短信提示的速度,和支付宝
提示几乎同时完成,像这种功能,其实这个支付接口内部是做了异步处理,短信发送采取的是
异步请求,这样效率会更高。
============================================================
32、什么是多线程?(了解)
多线程就是一个任务可以由多个线程同时运行,这样提高执行效率。
python中可以使用threading实现多线程,用threading.thread()可以创建
多个线程,启动线程用 线程名.start()启动。
|
|

python高级/自动化
1、python怎么引入第三方模块/库?
- 使用pip install 跟库名的方式引入。
- 如果速度比较慢,我们可以临时更换源进行引入,像清华的源速度就比较快。
(语法: pip install -i 清华大学镜像源地址 )
- 也可以修改配置文件永久更换源。
|
|

(在c盘用户下建立pip目录创建pip.ini文件,声明一下使用镜像源的服务器地址和主机名称)
2、删除库怎么删除?
在pyChram设置中,也可以安装和删除库,进入pyChram的设置选项,可以找到我们
安装的库,点击减号就可以删除。

3、怎样用python怎么操作数据库?
上个项目是通过第三方库pymysql连接的,还有其他的mysql链接库或是链接oracle库的API也都大同小异。
第一步:先导入pymysql包。
第二步:根据连接先建一个连接对象,再通过连接对象获取游标对象,通过游标对象
提供的execute()方法可以执行sql语句。
最后:关闭游标,关闭连接。因为做自动化频繁的需要操作数据库,所以mysql操作的
话都封装成了工具,需要操作mysql的时候,调用封装好的方法就行。
4、pymysql常用的功能有哪些功能?
pymysql的作用就是对数据库进行增删改查,比如查询:
查询提供了三种方法查询:
fetchone() :获取结果集中单条数据
fetchmany():获取结果集中多条数据
fetchall():获取结果集中所有的数据
增删改用的方法是一样的:执行单条语句用excute(),执行多条用excutemany()
5、操作数据库我们是怎么封装的?
数据库封装的话我们根据我们实际的需求进行封装,比如我们做自动化的时候要频繁
的初始化测试数据,所以我们把增删改封装成一个方法,查询一般我们在自动化中验证接口
调用完成后数据在不在数据库中,所以我们封装了一个查询条目数的方法,还有查询
数据,关闭游标和连接,我们都进行了单独的封装。
如果我们从代码的角度来讲的话,我们先封装数据库连接和游标的创建,因为不管做什么操作
连接对象和游标对象我们都需要创建,所以封装这两个功能的时候可以把他们封装在__init__方法
中,我们先从配置文件中读取到连接数据库的数据,比如主机ip地址、端口号、用户名、密码等
读进来以后创建连接对象和游标对象。
像增删改的封装的话,方法的入参我们可以让用户传入sql语句和元组,传进去后,我们执行sql语句,并且使用元组中的占位符数据,执行完成后提交
,返回条目数,其他封装思路也是大同小异。
|
|

6、什么是flask框架?
flask 框架介绍: 该框架为后端服务框架,能够部署服务,比如接口测试的时候,第三方接口调不通,我们可以使用它去写mockserver。
7、flask怎么用?
第一步:先用pip install安装flask框架。
第二步:模块中导入flask,并且创建服务对象,第三步,在我们写的接口上指定路由,并且运行该服务。这样我们的接口就可以通过http请求来调用了。
|
|

8、什么是requests?接口自动化怎么去调用接口的?
requests是一个第三方模块,他能够帮我们模拟http请求,从而进行自动化接口测试。
requests像常用的get/post请求,请求数据为json格式,这些都能够模拟。
9、具体怎么去调用的?
我们在代码中导入requests包,
1、如果是get请求,那么我们就使用requests.get方法跟url的方式调用接口,接口会返回响应结果。
2、如果是post请求,我们使用requests.post方法调用接口,并且要把请求数据写成一个字典
格式一起发送。
如果是json请求,我们还有要添加请求头,并且需要导入json包,把字典转为json格式发送过去。
|
|

|
|

10、自动化过程中,接口之间有关联怎么办?
我们以前做的项目所有接口入参都是有token的,我们可以先调用登录接口,登录接口返回后
我们把响应数据转换为json格式,再通过key获取value。获取到token的值后把它保存在变量中,
供后边的接口去使用。
|
|

11、在Python中unittest是什么?
unittest是Python自带的单元测试框架。它能够帮我们很好的管理和运行测试案例,我们接口自动化用的就是unittest,我们可以通过配置testRunner,指定我们需要运行测试案例,并且在unittest的基础上再导入一个支持html格式的结果报告。这样整个测试项目运行后,会运行整个测试包下的所有测试内容,并且能够得到一个漂亮的结果报告。
12、unittest主要有哪些内容?
unittest它有4个核心概念:
第一个是testcase(测试案例),我们需要继承unittest.TestCase类,并且所有的测试方法以
test开头,表示这是一个测试方法。
第二个是testsuite:用来把需要一起执行的测试用例集中放到一块执行。我们可以添加整个类到测试套件中,也可以添加整个python包到测试案例中。
第三个是testrunner:用来运行测试套件的。
第四个是测试夹具,我们可以在整个测试类之前或者之后,整个测试方法之前或者之后指定做
一些事情,比如我们自动化代码,我们可以在整个测试类之前创建数据库对象,整个测试
类之后关闭db对象,这样我们省去了频繁创建和关闭数据库对象的麻烦。
13、测试夹具都有哪些方法?
|
|

14、怎么得到 Html类型的结果报告?
1、下载HTMLTestRunnerNew文件存放在 python安装目录的Lib下
2、在代码中 import 该模块就可以使用了。
15、unittest常用的断言有哪些?
判定两个值是否相等用assertEqual(a,b)
判定不相等的话用:assertNotEqual(a,b)
断言结果为True:assertTrue(x)
断言结果为False:assertFalse(x)
assertIs(a,b) # 判断是否为同一个对象 a is b
assertIn(a,b) # 判断b是否包含a a in b
还有其他一些断言,我常用的就这几种。
16、什么是ddt?
ddt 可以参数化测试数据,把不同的数据进行参数化,做到代码逻辑和测试数据分离
比如我们做自动化的时候,从excle中读取测试数据后,可以通过ddt循环执行测试方法。
17、ddt怎么用?
我们先安装ddt,再
1、将测试类使用@ddt进行标记
2、将需要循环使用测试数据的测试方法,用@data进行标记。
18、你们的数据源有哪些?
我们测试数据是放在excel中的,通过工具类读取excel数据,读取到代码中,然后使用ddt
循环执行测试方法。
19、你们读取excel的工具是怎么封装的
先导入openpyxl这个包,这个包是第三方提供的,能够操作excel,然后方法的设计
大概是这样的,方法的入参是 文件名、sheet页的名字,开始行,开始列。
拿到文件sheet页以后,先读取第一行数据,因为第一行数据是表头,然后再把需要读取
的测试数据进行循环和第一行表头通过 zip进行打包,打包后转换成对象,把这些对象存放
在一个列表中,并且返回。这样我们就能把excel中的数据读到代码中。
|
|

20、为什么使用日志?日志怎么用?
python自带了logging模块,我们通过logging模块可以为自动化添加日志,
日志是为了在代码出错的时候,能够通过日志定位到具体哪个接口的哪条测试案例出错了。
比如我们自动化代码是要 使用异常处理的,代码一旦出问题,直接记录日志,方便定位。
21、日志常用的级别
日志的级别应该有8中,常用的日志的级别有4种,
debug:记录详细信息,主要用来调试
info:记录正确情况下,重要的日志
warning:记录警告信息
error: 记录错误信息
22、日志怎么封装的?
第一步:导入logging
第二步:创建日志对象
第三步:我们要指定日志的级别和输出方向,一般我们就打两种日志,
一个是info用来记录信息,一个是error级别专门用来记录错误日志。
第四步:返回 logger对象封装完以后,其他模块要使用做日志处理的话,
直接可以导入该logger对象记录日志
|
|

23.你们自动化测试是怎么做的?
其实做自动化我觉得最重要的是先能够充分熟悉我们要测试的接口,尤其要搞清楚接口操作了哪些表,有的接口是要做数据回滚的,所以这个很重要。
然后我们搭建自动化测试环境,我们公司使用的框架是unittest+pymsql+requests+logging
,python自动化框架是好搭建的,因为所有依赖的第三方库,直接使用pip install直接可以安装。我这边使用的框架目录大概是这样的:
它有几个核心包比如:
comms包(存放工具类,比如我们经常用的 db工具类、操作excel的工具类、日志工具类
还有根据项目情况自己封装的工具类[比如token的获取],都存放在该目录下)
testCases包(用来存放测试用例)
reports(用来存放测试报告)
conf包用来存放配置文件,比如数据库的连接的ip地址端口号等就存放在这个目录下。
datas包用来存放测试数据,我们把写好的excel文件可以放在这个包下。
logs包用来存放产生的日志文件。
整个项目运行的时候,会从datas包下读取测试数据,运行testCases中的测试案例。
运行完成后,日志会自动写在logs目录下,生成的结果报告会存放在reports下。
整个项目开发完成后,我们提交到svn上,再把项目挂在jenkins上配置下邮件发送和定时任务
这样实现每天凌晨自动执行,并且发送结果报告到邮件中,大概就是这样。
当然自动化的一些细节我们也要做处理:比如验证的时候,我们接口不仅要比对响应结果,还要看数据库的数据是否正确。还有要做数据回滚,因为有的接口如果不做数据初始化的话,接口第一次能够调用成功,第二次就会报错,比如注册接口,每次运行完都要从数据库把数据清掉。
24、你们自动化项目的代码结构是什么样子?
它有几个核心包比如:
comms包(存放工具类,比如我们经常用的 db工具类、操作excel的工具类、日志工具类
还有根据项目情况自己封装的工具类[比如token的获取],都存放在该目录下)
testCases包(用来存放测试用例)
reports(用来存放测试报告)
conf包用来存放配置文件,比如数据库的连接的ip地址端口号等就存放在这个目录下。
datas包用来存放测试数据,我们把写好的excel文件可以放在这个包下。
logs包用来存放产生的日志文件。
整个项目运行的时候,会从datas包下读取测试数据,运行testCases中的测试案例。
运行完成后,日志会自动写在logs目录下,生成的结果报告会存放在reports下。
25、自动化过程中,你都遇到过哪些问题,你是怎么解决的?
让我印象最深刻的是unittest在使用循环执行代码的时候不会显示测试标题,一个接口运行几十条案例执行后,没有测试标题显示,只显示1234567这种编号,这样造成代码在开发的时候,经常
很难定位问题,所以在网上找了很多资料,最后找到一个办法,我们可以修改ddt源码,把标题显
示在结果报告中。
追加问题:你是怎么改的?
我记得是在ddt中改一个变量的值,把测试案例的测试标题赋值给这个变量,
问题就解决了。
|
|

26、自动化有动态数据/变化的数据怎么办?
动态的数据的话,我们登录接口就有,像我们登录的时候的token值,每次都不一样,
我们在测试案例中使用 #token#,当代码读取到测试案例中包含 #token#的时候我们
可以对它进行替换就好了。
27. 常见的自动化失败的原因?
1)、开发修改了代码没通知到测试人员修改case;
2)、使用的测试数据出问题了。因为有的接口,用的是固定的数据库的数据,
这种情况下一旦数据库数据被动过,导致读取数据读不到报错。
所以我们做自动化的原则是:能造数据测试,就造数据测试,不能造从数据库中捞数据测试。
再不行再使用固定的测试数据。还有写代码必须要有详细的log日志,不然像这种问题出了以后
没有日志非常难定位。
28、你们数据回滚是怎么做的?
这个做自动化的时候还是蛮重要的,因为但凡接口对数据做了增删改,接口在第二次运行的时候
就会出问题,所以自动化这块我们初始化测试数据有三种方式:
1、第一种是 造数据测试,测试完成后把数据清除掉。比如说注册这种,我们每次注册完成后,把数据从数据库中清除掉。
2、第二种是 使用固定数据,我们把接口需要用的数据写在配置文件中,接口调用的时候,可以从这个文件中去读。
3、第三种是 从数据库中捞数据,每次从数据库中查询合适的数据并且随机一条数据出来,用这条数据进行测试,这种适合查询接口。
主要还是根据接口的情况,能造数据就造数据测试,因为这样不依赖于其他地方。像查询接口有的时候造数据因为表之间关联太复杂,我们可以在数据库中捞一条数据进行测试。
29、你负责项目的接口自动化覆盖率?
我一直跟的xx项目,统计出常用的接口有100个左右,这些接口我们是优先全覆盖了,然后根据组长安排的工作进度推进。
30、 你们自动化脚本的通过率是多少?
这个说不准,如果没有什么异常情况,自动化脚本都是100%运行通过;如果异常情况比较多,比如出现测试环境不稳定,或者开发修改了代码没通知到测试人员及时修改case,又或者开发引入了新的问题等等,通过率可能80%都不到。
31、你曾经都写过多少自动化测试接口?
这个具体没有算过。但是只要有时间,模块稳定的功能都会写。就拿上个项目来说,自动化接口大概写了将近有70-80个这样子吧。
32、你都写过哪些接口的自动化?
根据项目来
33、你的python水平很一般啊?(遇到这种否定你的问题,一定不能虚!)
我现在掌握的python知识,做接口自动化测试是可以的,代码的封装,调用这些都没问题;我一般是会做,但不是很会用文字描述出来,我也注意到这点,现在也在加强提升自己的总结能力。
PS---重点强调:凡是遇到被面试官否定的,都要想办法怼回去,输也要输得精彩些,但是,怼回去的时候,要注意语气,要有礼有节,不卑不亢。
34、 如何提高自动化的执行速度?
如果需要提升自动化的执行效率的话,我们可以考虑多线程这块,但我们以前做的项目都没有做多线程,这个跟我们的测试框架有关系,但这个问题也不大,因为我们自动化项目都是在凌晨以后运行,所以对这块没有太高的要求。
35、多线程这块你会做吗?
我们以前做的项目都没有做多线程,这个跟我们的测试框架有关系,但这个问题也不大,因为我们自动化项目都是在凌晨以后运行,所以对这块没有太高的要求。
36、做自动化做了多久?
一直都在做,通常只要有时间,模块稳定的功能都会写。断断续续的做了一年多了。
37、你认为什么样的项目适合做自动化?
从长远角度来看,没有不适合做自动化的项目,只有不适合做自动化的阶段。比如周期长,版本多,业务稳定的项目都适合。
38、怎么生成HTML报告?
使用了HTMLTestRunner第三方工具包来实现的,这个包是在网上down下来的,放在python目录
下,在自动化代码中使用它就可以了。(怎么使用:运行方式使用HtmlTestRunner就好了)
|
|

39、如果系统有验证码,怎么做自动化?
1)、去掉验证码。
2)、设置万能验证码。
40、 在编辑python代码的时候遇到bug怎么解决
1.通过print()进行调试,看看哪里出了问题
2.打断点 Debug单步调试
41、我们编写自动化测试的过程通过什么保存配置数据
通过properties文件或是ini文件,我们用的比较多的是ini文件
41、介绍一下你在这个项目中是如何使用 Jenkins 的
jenkins配置的话,在jenkins中新建项目,然后在源码管理下配置 源码的svn或者git地址,再提供用户名密码。其实这样已经配置好了,项目已经能通过 jenkins进行运行部署。
但是如果需要把项目的运行结果发送邮件的话,还需要配置邮箱插件,html类型的结果报告也需要配置插件,插件配置好,设置好的话就能发送html类型的结果报告,还能将运行的结果自动发送邮件。
42、自动化结果报告都有哪些内容?
我们自动化结果报告使用的是HTMLTestRunner报告,进入报告后先是展示整个测试都测试哪些测试套件,每个测试套件执行的总体通过率是多少,还有每个模块执行了哪些测试方法,每个测试方法是否执行成功,如果报错会有报错信息展示。
|
|

43、邮件报告都有哪些内容?
|
|

44、jenkins的定时任务怎么配置?
在项目的配置中选择构建触发器中的 定时构建,并且配置日程表。
日程表的配置规则是这样的: 我们需要配置5个位置,这5个位置
分别代表分钟、小时、一个月的第几天、第几个月、一周的第几天。我们根据需要进行配置就好了,像我们自动化配置都是在凌晨去运行,比如 H 2 * * * 就代表凌晨两点运行。
45、邮箱配置怎么配?发出来的邮件都有哪些内容?
邮箱配置的话,需要先安装一个jenkins插件(editable Email notifycation插件),需要先在系统配置- 全局配置 中配置 邮箱提醒,还有在具体项目中进行配置,主要配置的内容有:发送邮箱的服务器名称、邮箱服务器端口号、发送邮件类型选html/text类型,还有收件人、发送邮箱的格式模版,标题等等,还有发送邮箱的触发器,选择Always,表示 项目只要运行就发送邮件。
46、怎么给多个人发邮件?
给多个人发邮件,在填写收件人的时候多个邮箱地址用 逗号隔开就行。
46、svn是什么?在工作中干什么用?
Svn是一个文件管理工具,我们在工作中可以管理代码和需求文档。
47、Svn的基本操作有哪些?
1、初始化本地仓库:使用 check out
2、提交代码 commit
3、更新本地代码 update
4、查看文件日志等
48、怎么把python代码提交到svn?
直接在项目目录下点击右键选择commit提交代码
性能测试
1、性能测试概述
性能测试是对软件的性能进行测试,保证在一定并发量下,功能正常,性能符合指标。

2、性能测试流程
1、提取业务线:
例如京东,我们需要测试如下功能:
1、登录 2、商品浏览3、订单浏览4、查看购物车5、加入购物车6、注册7、搜索、下单、注册等等。
我们需要将这些功能梳理成业务线。
第一条: 进入首页--->登录-->搜索-->浏览--->加入购物车-->退出。
第二条: 进入首页--->登录-->查看购物车-->退出
第三条: 进入首页--->登录-->查看订单-->退出
第四条: 进入首页--->注册
2、根据业务线录制脚本
1、PC端录制脚本方式1: 通过bodboy进行录制,并导出.jmx文件。
badboy录制是比较简单的,进入到badboy后建立testsuite后建立test,再打开需要录制的网页
每操作一次建立一个step,badboy会把操作过的步骤的请求和响应数据录制下来。最后把录制好的脚本使用导出就可以了。badboy导出的脚本是.jmx文件,是jmeter可以识别的。
2、PC录制脚本方式2: 通过fiddler进行录制,并导出.jmx文件。
fiddler录制脚本本身是不支持导出jmeter文件的,我们需要单独在网上下载个插件,存放在fiddler安装目录中,这样就能够支持导出jmeter文件,录制的时候,我们需要对fiddler做一些设置,比如开启https请求,开启过滤,设置完成后在fiddler中打开我们需要录制的网页,并且进行录制。最后导出为.jmx文件。
3、fiddler录制和badboy录制的区别在哪?
- 首先我觉得fiddler是比较强大的,因为它录制了所有的请求和响应,badboy呢,它在于更好用,能自动把一些比如图片的这些请求全部过滤掉只保留核心请求。
- fiddler录制脚本最大的好处是能够看到具体的请求和响应的数据,我们可以通过这些数据调试我们的脚本,而badboy录制的脚本一旦出问题,只能靠经验去调试。
- fiddler录制最好清空浏览器缓存,否则录入脚本不全。
4、录制脚本经常会出现哪些问题?
脚本录制的话问题碰见过不少,不管是什么工具录制好的脚本都需要改一改,比如
badboy录制好的脚本的请求数据经常只有value值而没有key值,这种需要我们删除掉,
还有badboy录制好的脚本默认是选择的自动重定向,我们需要在jmeter选择跟随重定向,这样重定向的请求才会发送出去,不然脚本会报错。
- 手机app录制脚本怎么录制的?
手机app录制的话跟pc端差不多,需要手机和pc端在一个网段中才能录制,需要我们先在fiddler中设置,开启https请求,开启允许远程连接,还有需要设置个端口默认端口号是8888,再在手机中设置网络代理为pc端的网址,这样在手机操作app,fiddler就能自动录制脚本了。

3、修改脚本增强脚本
1、断言: 用来判定响应结果是否正确
查看订单流程增加断言:

1.1、断言怎么做的?
jmeter断言的话新建一个响应断言,在断言中我们可以选择包含、匹配关键字来实现对响应结果的断言。
2、参数化: 用来使用测试数据
查看订单流程增加参数化(由于京东登录用户不能重复登录,所以模拟多用户进行订单访问时需要进行参数化,否则多个用户同时使用1个用户进行订单访问会报错)。
我们模拟 zhangsan/1234567 和 lisi/123456789 同时进行订单访问操作:
- 步骤一、准备测试数据:
新建txt,写测试数据不能有多余的空格不能有换行。

- 步骤二:新建插件引入数据到脚本中

在脚本中使用数据:

设置脚本使用两个用户同时运行该脚本,代码运行正确。


2.1参数化怎么做的?
参数化的话需要先准备测试数据,存放在txt或者csv文件中,然后在jmeter中创建
csv data set config插件,在里边填写数据的地址,数据存放的变量名,数据是否允许循环,
数据使用完成后是否停止等内容,配置好以后请求中就可以使用${变量名}使用这些测试数据。
- 关联:某些请求会使用到前边请求的请求或者响应数据
3.1关联怎么做:请求之间关联是有的时候后边的请求会使用到前边的请求,我们需要使用正则表达式提取器,把数据提取出来,存放在变量中。后边用的时候使用${}引用变量的值就可以了。
4、加入事务和思考时间
4.1什么是事务?
在性能测试中,我们可以把用户对网站的一次操作作为一次事务,比如点击登录按钮(包含3个子请求)、提交注册信息、页面切换等等。
4.2什么是思考时间?
在真实性能测试场景中,真实用户并不是一直在进行速度很快的操作,每做一次操作,用户需要消耗一定的时间,比如登录成功后,用户可能在3秒左右才对页面进行再次操作。 这种时间叫作思考时间。我们的脚本中必须加入思考时间,这样更能模拟客户的真实操作。
4.3怎么配置事务和思考时间:
新建事务控制器,将同一操作的请求放在事务控制器下,比如创建一个事务控制器,
起名为 登录,我们可以把登录相关的请求放在该事务控制器下,这样的操作可以很方
便的统计出事务响应时间。

- 思考时间我们加在每个事务最后一条请求下,可以使用固定计时器或者高斯计时器。

4、准备测试环境和测试数据,并且给被测试服务器安装监控插件
1、准备测试数据
当有些地方数据不能重复,我们需要准备一些测试数据进行循环使用,数据准备好进行参数化,可以将准备好的数据运用在脚本中。
2、监控插件安装及配置
当脚本在运行过程中,我们需要监控服务器的指标,如cpu、内存、硬盘容量、网络、等等。这时候我们需要在服务器端安装插件。
怎么安装插件:网上下载一个jmeter插件管理的jar包,存放在jmeter的lib目录下,重新启动jmeter后我们在jmeter中勾选我们需要安装的插件,jmeter就会将需要的插件进行安装。
4、安装服务器端
解压 serveragent包,进行如下操作:

5、配置监控,获取服务器cpu、内存、磁盘信息、事务响应时间等信息。
6、运行脚本得到结果报告:
跑出图1:吞吐量,每秒处理事物数:

跑出图2事务随时间的响应时间:

跑出图3:服务器硬件资源:

跑出图4:聚合报告(问题聚合报告都有哪些内容?)

怎么安装监控插件/怎么监控服务器:
安装监控插件,需要先看看有几台服务器,在各个服务器上安装serveragent,并且启动它。
这个监控默认的端口是4444,它会自动收集服务器数据。我们在jmeter中创建监控,配置服务器的ip地址、4444端口号也要填进去,选择需要监控的内容比如cup、内存、网络、磁盘等,这样脚本运行后,会自动收集服务器信息,并且生成图表。
5、性能测试策略
当所有的脚本准备完成后,这时候我们需要进行测试,我们需要一定的策略。
知识储备:
1、测试计划设置
一个测试计划下可以同时运行多个线程组。

2、线程组设置

1、在取样器错误后要执行的动作:
- 继续:出现错误继续运行
- start next thread loop 出错后继续下一次循环
- 停止当前线程:比如50个线程,1个线程停止,则停止该线程,剩下49线程运行。
- stop test now 如果线程失败,停止场景。
2、线程属性
- ramp_up period : 所有线程在多长时间内加载完成。
- 50个线程ramp_upperiod = 10;表示加载5个线程并且运行。
- 循环次数:请求重复次数。
- delay thread creation util needed 勾选后,虚拟用户在需要的时候才进行加载。
如果50个虚拟用户,ramp_up period = 10 勾选后每秒加载5个并且运行,用的时 候才加载,勾不勾选不影响结果。
- 调度器:设置何时才能执行:启动时间 结束时间 持续时间(会覆盖结束时间)。
3、参数化策略

三:参数化设置:
Filename:文件名,指保存数据文件位置,可以相对或者绝对路径(比如:D:\ceshi.Txt)
File encoding: csv文件编码,可以不填。
allow quoted date: 是否允许完成的参数里边有分隔符出现。
recycle on eof: 到了文件尾处,是否循环读取参数,选项:true和false。
Stop thread on EOF:到了文件尾处,是否停止线程,选项:true和false。
参数化策略
jimeter 中的参数化有两种:
1、允许数据重复,选项recycle on eof选择ture;
2、不允许重复,选项recycle on eof选择false。
基准测试:
基准测试用来做大规模测试前验证各个脚本是否正确,大概的事务相应时间。一般使用单用户跑多次(5-10),建议使用2个用户进行运行,能够检查到参数化数据是否正确。
例如:

压力测试/配置测试
压力测试:对测试场景进行不同的并发数测试,检查哪些配置有问题,比如数据库连接数,并且得出哪些请求并存在错误,超时等问题,告诉开发,进行调优。压力测试可以单场景进行专项压力测试,也可以多场景进行压力测试,需要采取逐步加压的方式发现问题。
压力测试需要采取如下ThreadGoup进行场景设计(需要安装插件)

多场景稳定性测试:
多场景稳定性测试在最后测试用来模拟真实项目运行情况,把所有业务线脚本放在一个测试计划中,并且运行,对系统进行>12小时的测试,各项指标正常。查看各个指标如服务器CPU、内存、磁盘容量等还有 TPS是否稳定。
6、性能测试常见问题和定位优化
1、问题怎么定位?
一般情况下,在做压力测试的过程中我们会看监控面板,如果有某些事务的相应时间过长,或者报错。我们可以根据报错的信息,找到对应的接口url,把接口发给开发,一起看看怎么问题。
2、常见问题有哪些?怎么去优化?(一般情况下,我们负责定位哪条url有问题,开发负责优化代码)
1、数据库问题最多,比如数据库sql语句缓慢,数据库死锁问题。
并发访问量下,sql执行缓慢导致的,看下具体哪个表被锁住,然后对操作的这个表的sql进行优化,如加索引,更改sql语句的写法,数据库调整缓存区大小等)
2.接口调用超时和报错(解决方案:通过统计找出具体的接口,然后对代码和sql语句进行优化)
3、中间件连接数过小(数据库连接数让开发设置中间件在线数量)
4、服务器内存溢出,cpu使用率过高,磁盘日志写满。
2、你是怎么做性能测试的?
1、首先要熟悉需求这一块,看看要测试哪些业务线,再就是对业务线脚本进行开发。
2、我这边常用的是通过 badboy或者fiddler 先录制脚本然后导入到jmeter中。导入后对脚本进行修改增强,比如有的需要做参数化,有的地方需要关联,还有需要加断言,并且划分事务控制加一些思考时间。
3、脚本配置好了以后,要准备测试环境和测试数据并且给服务器安装监控插件,准备好以后进行压力测试发现问题发给开发进行优化,基本优化完成后还最后跑跑稳定性测试,看看是否稳定。没问题就出结果报告,把不能并发量的监控报告截图发邮件。
3、手机性能测试是怎么做的?
手机测试和PC端测试其实流程是一样的,不过手机性能测试需要使用 fiddler抓包录制脚本,再导入到PC端进行测试。其他的和PC端性能测试流程是一样的。再把性能测试流程说一遍。
4、你们项目中跑的并发量是多少?
我们多场景稳定性测试 在脚本中加入思考时间的情况下,跑的并发量是400用户。这个项目是新项目/重构项目,并发量是业务根据预估访问量进行计算的。
追加问题:怎么算的知道吗?
详细的算法忘记了,大概的算法是:根据日PV量,和业务访问比例,通过高峰期一小时的PV量算出TPS,再根据TPS和思考时间算出总的并发用户量,然后把总的并发访问量按业务访问比例进行分配。
他有很多公式:
1、先根据日PV量(日PV量 = 日事务处理量)算出TPS 36000 ,10
TPS = PV量/3600秒*1小时 (高峰期一小时的事务量/3600秒)
2、再根据TPS、事务规定的响应时间、思考时间 、还有2 8原则算出并发访问量
并发访问数 =(系统要求响应时间+事务的思考时间)* TPS*8/2
5、你负责哪些内容?
是这样的,我们做性能测试有两个开发,一个运维做支持的,我这边负责性能测试脚本开发、各种场景设计,还有每次跑的结果报告分析,还有出结果报告。
6、结果报告中有哪些内容?
1、先是项目简介,再是项目软件环境配置(例如springmvc+mybatis)、再是项目硬件环境配置数据库web服务器台数和配置(两台 linuxSE版本红帽5)、服务器台数(两台)。
2、下来是软件测试场景和并发数,以及对应的结果贴图,比如各个服务器CPU、内存
网络等、还有TPS、响应时间图等。
7、追加问题:你都测试了哪些场景?
主要是不同并发数下压力测试场景、还有稳定性测试场景。
8、什么是压力机
压力机是模拟请求的机器,一般小的项目,我们使用自己的电脑模拟就够了。
但是项目并发量大的情况下,我们需要好点的配置机器作为压力机。公司提供专门的压力机,
我们需要把代码部署在压力机上,运行我们的场景。(服务器版本 windows server2000,部署的时候先装jdk(v1.8),再装jmeter,就可以了)
9、你们监控是怎么监控的?
我们监控服务器这块使用的是jmeter插件进行监控,需要在服务器端和客户端分别安装监控插件,运行脚本的时候先启动插件(插件解压后有个文件startAgent.sh文件在linux中执行它就行),再运行脚本。这样就能收集服务器信息。
各个服务器CPU、内存网络等、还有TPS、响应时间等。
10、jmeter怎么模拟同时并发?jmeter怎么模拟秒杀这种压力测试
我们需要在请求之前设置集合点:让所有请求在集合点进行集合
比如:我集合点设置为50,那么不满足50个请求的时候,这些请求都会集合在一起,处于等待状态,当达到50的时候,就一起执行。从而达到并发的效果。Jmeter中可以通过同步定时器来完成。


11、接口性能测试怎么做的?

接口性能测试的话,我们在jmeter中先建立该请求,并且让接口能正确跑通,跑通后
为接口增加断言。接口测试查询接口还好,因为从数据库中捞数据,使用已经存在的数据就可以了
,不需要回滚,但是有的接口会对数据库的数据进行增删改,所以我们需要对数据进行回滚,举个例子比如注册这种接口,它会给数据库插入数据,第二次再使用相同的数据进行注册,脚本就会报错,所以我们需要在jmeter中配置jdbc操作数据库,把注册后的数据清除掉。
12、jmeter怎么操作数据库?
我举个例子,比如jmeter连接mysql数据库,需要先下载个mysql驱动包,放在jmeter/lib目录下,
再在测试计划中导入该jar包。还要添加一个jdbc配置插件,配置所使用数据库的IP地址、用户名、密码、端口号。配置好以后,我们就可以使用了,用的话直接建一个jdbc request写sql语句就好了。
1、下载对应数据库的jdbc驱动jar包:mysql-connector-java-5.1.44-bin.jar
拷贝到jmeter/lib目录下
2、在测试计划中导入该jar包



3、选择测试计划-右键添加配置元件-JDBC Connection Configuration,填写数据库信息


4、添加jdbc request

13、jmeter你都用过哪些功能?
平常我们使用jmeter或者postman做接口测试,jmeter也用来做性能测试。
14、jmeter插件都用过哪些:
经常用到的有:
- http请求
- 请求信息头管理器
- cookie管理器
- csv data set config
- 断言
- 正则表达式提取器
- jdbc请求
- 集合点
- 定时器
- 事务控制器
- 查看结果树、聚合报告等
- 还有一些做性能需要安装的插件 :
监控服务器插件、TPS插件、事务响应时间的插件
15、fiddler用来模拟弱网测试:
首先,打开Fiddler后,需要每次勾选模拟调制解调器速度的选项,再打开fiddler的配置文件,在里边更改所需要模拟的上传和下载速度。这块需要进行一个换算改下配置文件的参数值,fiddler默认的是以1KB使用多少秒来模拟弱网的,我们要换算成每秒的上传和下载的速度。比如换算下来模拟1秒上传下载50KB,我们填写延时时间为20。
具体步骤:第一步:打开Fiddler,Rules->Performance->勾选 Simulate Modem Speeds(模拟调制解调器速度)

第二步:Rules—>Cutomize Rules打开CustomRules.js 文档

在文件中搜索关键字SimulateModem


让我们来分析一下这几行代码:首先来判断m_SimulateModem是否为true,也就是是否设置了弱网模式。如果为弱网模式。则分析代码oSession[“request-trickle-delay”] = “300”; 注释的也很明白,Delay sends by 300ms per KB uploaded.上传1KB需要300ms,转化一下上传速度:1Kb/0.3s = 10/3(KB/s)如果你想设置上传的速度为50KB/s,你则需要设置Delay 时间为 20ms同样的方法,也可以限制下载的速度,调整oSession[“response-trickle-delay”]即可。
Linux/Unix操作系统介绍:
1、linux系统的特点:
Linux/unix系统优点:稳定、安全 24*365运行(我们用的版本是centos7)
- 远程连接工具xshell介绍和使用
Xshell是一个远程连接和操作linux系统的工具:我们需要做如下配置:


- 使用xshell连不上服务器怎么办?
注意如果我们使用xshell命令连接不上服务器,那么我们应该学习两个命令,来检查下基本的网络是否正常。
(1)、命令1: ping 服务器地址 比如 ping 192.168.0.103
该命令可以检查是否能够正常和192.168.0.103 地址的主机通讯,如果不能通讯那么肯定是连接不上的。
(2)、命令2:ifconfig和ipconfig
怎么查看服务器的IP地址呢?我们可以在linux系统中使用 ifconfig命令查看linux的主机IP地址。Windows查看用ipconfig


如果网络能够ping通,那么我们需要检查自己的用户名、密码是否正确。
4、显示当前用户信息:who am i:

5、查看当前系统版本

6、进入目录 cd
cd .. 代表进入上级目录
cd 代表进入当前用户的家目录(注意:root用户的家目录在 /root,其它用户的家目录都在/home下)
cd ~ 代表进入当前目录的家目录 ~就代表当前目录的家目录

7、查看当前日期 date

8、创建目录:mkdir 目录名称

9、创建文件:touch 文件名

10、mv 重命名 和 移动(剪切)
注意:
重命名语法: mv 文件名 新文件名
移动语法: mv 文件名 路径

11、cp 复制文件和目录
复制文件到当前目录下: cp 原文件名称 新文件名称
复制文件到指定的目录下:cp 原文件名称 目标目录/【新文件名称】

复制目录到当前目录下: cp -a原目录名称 新目录名称
复制目录到指定的目录下:cp -a原目录名称 目标目录/【新目录名称】

12、使用find命令通过文件名搜索内容:
Windows如下操作:

Linux命令:find 搜索位置 -name 搜索名称

13、使用tar命令压缩和解压
压缩文件:tar -cvf 压缩后文件名 被压缩文件1 被压缩文件2 ...
解压到当前目录:tar -xvf 压缩文件名
解压到指定目录:tar -xvf 压缩文件名 –C 地址

14、使用zip命令解压和压缩
压缩文件:zip 压缩包名称 被压缩文件1 被压缩文件2 …
解压到当前目录:unzip zip格式压缩包
解压到指定目录 unzip zip格式压缩包 –d 路径

15:查看文件内容
1、通过vi工具或者vim工具打开和操作文件
Vi工具的三种模式: 1.普通模式 2.编辑模式 3. 底行模式
Vi工具操作步骤:
<1: 打开文件使用 vim 文件名 例: vim 1.txt
<2: 要编辑我们可以按 i 进入 插入模式.
<3: 编辑完成后,先按 ESC键,退出底行模式,
如果需要保存(:w),退出(:q), 强制退出(:q!) 保存并退出(:x或者 :wq)
<4: 查找内容,按esc 输入 ?+查找关键字来进行搜索
按n 向上查找,按N向下查找.
案例:
步骤1:通过vi打开一个文件:


步骤2:按 i进入编辑模式,左下角会显示为INSERT,这时候可以编辑文件

步骤3:编辑完成后,按esc键,并且输入: ,进入底行模式输入wq指令后敲回车,可以保存数据并退出

2、通过 cat命令查看文件内容
cat 命令会把文件内容打印在面板上。适合内容较少的文件。

3、通过more 文件名 查看一个长文件的内容
按Space键:显示文本的下一屏内容。
按Enter键:只显示文本的下一行内容。
4、通过less 文件名查看文件的内容
less file1 适合查看长度较长的文件,并且可以使用使用 ?xxx 搜索文件中 xxx的内容,使用 n进行向上查找 N进行向下查找.

5、查看文件的前n行和最后n行:head –n tail –n (n代表行数)

16、动态查看日志: tail –f 日志文件
不管是做功能测试,还是接口测试,我们可以通过日志文件去分析bug,定位问题。
一种方式直接通过vi去查看日志文件,找到日志文件对应的问题。
但是这种方式有个不好的地方,在于日志文件内容过多,我们不能很好的把bug对应的日志找出来。所以我们可以通过动态监控日志,并且重现bug, 新刷出来的日志,就是bug对应的日志。
我们可以先查看/root/my_application/my_interface这个目录下的set_logger01.py文件的内容,我们可以看出一旦该文件执行,就会往info.log文件中写日志。

那么我们可以动态监控info.log文件,再执行set_logger01.py文件,看看动态日志的刷新效果:
第一步:使用tail –f info.log 监控该文件:

第二步:模拟另外一个用户执行set_logger01.py文件:

第三步:我们回头再去查看日志文件 info.log

这样我们通过动态监控文件 info.log就能得到 执行python文件对应的日志,同样的道理,
我们以后在工作中,如果某个功能或者接口出现bug,我们需要根据日志定位问题,我们可以动态的监控日志文件,并且重现bug,这样日志文件中新刷出来的日志,就是bug对应的日志,我们可以根据这个日志去分析问题,定位bug。
17、搜索文件内容grep:
语法:grep 关键字 地址/文件名 在 地址 下的文件 中查找关键字
注意: grep过滤的文件的内容,会把包含该内容的行打印在面板中。

18、查看进程、过滤进程、杀死进程
进程的查看有两个命令:
top命令动态查看进程

ps 显示瞬间进程状态 ps –aux

如果我们想查看mysql对应的进程,我们可以使用如下命令进行过滤:
ps –aux | grep mysql
注意:该命令先执行ps –aux 然后将执行的结果通过 |(代表管道) 给后边的命令使用,
而后边的grep mysql 意思是过滤出包含mysql的行。所以得到如下的结果:

如果我们需要杀死进程,我们可以通过 kill -9 pid 命令杀死进程。

19、linux下查看端口号占用情况、查看端口号对应的应用、关闭该端口号对应的进程。
1、查看所有端口占用情况:netstat -ntlp

2、查找mysql对应的端口号、3306端口被占用的情况,我们就可以通过过滤拿到:

3、如果要杀死3306端口对应的进程我们可以通过 kill -9 25937杀死进程。
20、chmod和chown命令:
更改文件的访问权限:chmod,更改文件的所属用户和组:chown
1、如何更改文件访问权限:
首先我们要明白,在linux系统中可以有很多的用户和组,每个用户属于不同的组,这样我们可以更好的管理权限:

ls -l命令可以查看当前目录下的文件的全部信息:

更改用户的权限我们可以通过 4 2 1 进行更改:
比如我们想更改 当前组为 可读可写,那么我们就可以使用:
chmod 464 1.txt

如果想更改所有人都是可读可写可执行使用chmod 777 1.txt

总结:chmod 三位数字 文件 就能更改权限(
第一位数字代表当前用户权限
第二位数字代表当前组权限
第三位数字代表其它人的权限)
2、如何更改文件的所属用户和组:chown
比如我们更改1.txt文件的所属的用户为 tom,所属的组为 gp1
语法: chown 新用户名:新组名 文件名

20:了解远程拷贝文件(从一台服务器拷贝内容到另外一台):
1:从本地复制到远程
scp -r 本地目录 远程机器用户@远程机器地址:远程机器目录
比如: scp -r /opt/test root@192.168.2.105:/opt
2: 从 远程 复制到 本地
scp -r 远程机器用户@远程机器地址:远程机器目录 本地目录
比如: scp -r root@192.168.2.105:/root/dir /opt/
21、常见面试问题:
1、你们用的linux系统是什么版本? centos7版本
2、你们是怎么操作linux系统的?
我们操作linux系统的话,用的是远程连接工具xshell,通过xshell远程连接linux系统,
主要就是看看linux相关的日志,通过日志分析bug。
3、linux服务器连不上怎么办?
如果连接不上的话,先看看网络能不能和服务器联通,我们可以使用ping命令去检查,
看看能不能ping通服务器。如果ping不通那就是网络问题,或者服务器挂掉了,如果能
ping通,说明网络没有问题,那我们看看是不是自己连接的时候填写的IP地址、用户名、密码不对。
4、ifconfig 和 ipconfig的区别?
windows下查看ip地址用ipconfig ,linux下使用ifconfig
5、系统版本怎么查看 cat /etc/redhat-release
6、你是怎么分析日志的?
首先的话用工具远程连接linux服务器
查看历史问题,我们可以直接通过vi或者less等命令打开日志查看搜索对应的日志(怎么搜索:我们可以在vi/less使用关键字搜索,在命令行模式下打个?+上关键字比如 ERROR EXCEPTION 日期等)。
如果是在测试过程中,出现bug需要通过日志定位bug,我们可以使用tail -f 命令动态监控该日志文件,再次操作页面或者调接口重现bug,这样新刷出来的日志就是我们bug对应的日志。
追加问题 :那具体是怎么分析的?
具体就是看看日志内容,有没有异常,哪块地方报了异常,像我们日志中都有接口名称,异常名称,根据这些具体问题具体分析。
都见过哪些异常?:
typeEroor 类型错误、Null point Exception (空指针异常)、还有很多,类型异常、像我们自动化日志中:断言异常、数据读取不到会报 empty suite等等。
plsql面试问题
1、什么是plsql:
Plsql是一门脚本语言,它能够更好的操作oracle数据库,比如我们做性能可以使用plslq批量造数据,还有我们生产数据如果出问题,我们可以通过plsql脚本对生产数据做修改,还有很多批处理的功能都是通过存储过程+定时任务的方式实现的。
2、plsql怎么批量造数据?
我们使用匿名存储过程来造数据 ,大概结构是:
Declare bengin end这样的结构,declare后边我们可以定义变量, bengin和end之间我们可以写造数据的逻辑,我们需要写循环+insert语句这样就可以实现批量造数据。
追加问题:那批量造数据有的值是变化的怎么办?
我举个例子吧,比如做性能测试需要10000的用户,每个用户的手机号
不能重复,我们可以在declare中声明一个变量用来代表手机号,再循环的时候每次给该变量的值+1这样造出的手机号就都不一样了。
3、什么是dml脚本测试?
在生产环境下,往往需要修改错误的生产数据,所以开始需要进DML脚本修改数据,在测试环境下测试脚本有没有问题,再在生产环境执行该脚本。
4、怎么去测试dml脚本?
<1: 先查看逻辑是否正常,修改范围是否正确,不能扩大或者
缩小。
<2: 造出符合脚本的数据,运行脚本,查看脚本执行结果是否正确。
比如:我们做的…功能,生产出问题,有一部分数据是错误的数据,我们使用plsql去修改数据。
5、什么是批处理?
批处理就是批量处理数据,比如我们在很多网站上注册,第二天有客服打电话过来,这其实就是一个批处理数据,它每天凌晨把前一天的数据通过到客服系统,然后客服人员拿到数据后可以联系注册者。
6、批处理怎么测试?
我们要先在plsql工具中找到我们批处理任务对应的存储过程,找到后右键选择测试,填入需要的入参,点击运行,看看结果是否正确。
比如; 我们项目中的批处理任务 xxx,会每天同步数据,测试的时候我们需要先造一部分符合条件的数据,再运行存储过程,看看存储过程跑完后,数据加工是否正确。

7、什么是游标?
游标关键字是 cursor,用来存储一个结果集的,比如我们批量处理数据的时候可以使用游标先把数据抓出来,再对结果集进行循环处理,游标分为 显式游标和隐式游标:隐式游标,不需要手动进行 打开游标关闭游标的。















 643
643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









