







前言
经历了一次SQL优化的需求,发现联合索引并不是网上大部分讲的那样,经过自己试验+百度,算是明白了一点,小记录一波。
基础篇
定义
多个字段组合在一起形成的索引,且可以有不同的性质,目前我知道的有:普通联合索引、联合唯一索引。
联合唯一索引是在普通联合索引的基础上增加了唯一约束,即几个字段的值加起来不能有重复。
特性

用红线画出的部分先不看。
用图可以这样看:
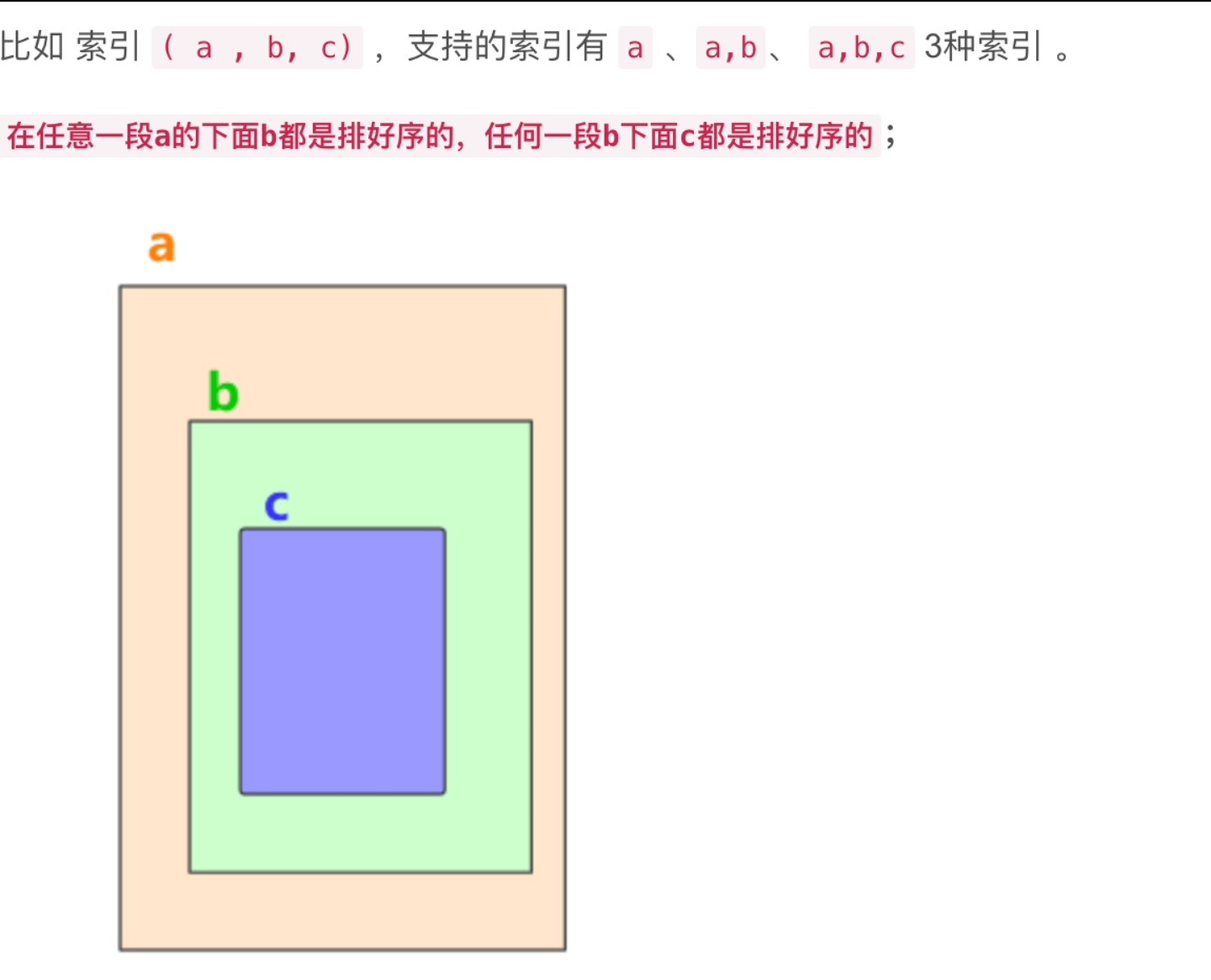
一条SQL的执行中,每个表最多只能走一个索引,用联合索引可以让多个字段都走到索引,一般来说走的字段越多越好。
改正:mysql5.1之后引入了index merge(索引合并)技术,可以让一条SQL用多个索引合并起来查询,这个后面会讲,但大部分场景用不到这个技术。
例子
假设在一个表中创建 ( a ,b ,c ) 三个列的联合索引
别处引用:
(1) select * from mytable where a=3 and b=5 and c=4;
# abc 三列都使用索引,而且都有效
(2) select * from mytable where c=4 and b=6 and a=3;
# mysql没有那么笨,不会因为书写顺序而无法识辨索引。
# where里面的条件顺序在查询之前会被mysql自动优化,效果跟上一句一样。
(3) select * from mytable where a=3 and c=7;
# a 用到索引,sql中没有使用 b列,b列中断,c没有用到索引
(4) select * from mytable where a=3 and b>7 and c=3;
# a 用到索引,b也用到索引,c没有用到。
# 因为 b是范围索引,所以b处断点,复合索引中后序的列即使出现,索引也是无效的。
(5) select * from mytable where b=3 and c=4;
# sql中没有使用a列, 所以b,c 就无法使用到索引
(6) select * from mytable where a>4 and b=7 and c=9;
# a 用到索引, a是范围索引,索引在a处中断, b、c没有使用索引
(7) select * from mytable where a=3 order by b;
# a用到了索引,b在结果排序中也用到了索引的效果。前面说过,a下面任意一段的b是排好序的
(8) select * from mytable where a=3 order by c;
# a 用到了索引,sql中没有使用 b列,索引中断,c处没有使用索引,在 Extra列 可以看到 filesort
(9) select * from mytable where b=3 order by a;
# 此sql中,先b,后a,导致 b=3 索引无效,排序a也索引无效。
补充:
(10) select * from mytable where c=3 and a=7;
# (3)的衍生例子,a 用到索引。原因同(2)
(11) select * from mytable where a=3 and b>=7 and c=3;
# (4)的衍生例子,但 a、b、c 都用到索引,其中b用了一半索引
# 这是写下这篇博客的主要原因,原因下面详细说。
(12) select * from mytable where a=3 and b between 2 and 5 and c=3;
# (4)的衍生例子,但 a、b、c 都用到索引
# 这是写下这篇博客的主要原因,原因下面详细说。
(13) select * from mytable where a=3 and b like 'bbb%' and c=3; —— 假设b字段临时变为varchar
# (4)的衍生例子,但 a、b、c 都用到索引
# 这是写下这篇博客的主要原因,原因下面详细说。
(14) select * from mytable where a=3 and b>7 and c=3;
# (4)的衍生例子,但 a、b 用到索引,c用到一半索引
# 这是写下这篇博客的主要原因,原因下面详细说。
(15) select * from mytable where a=3 and b in (7,8) and c=3;
# abc都用到索引,in不会中断索引匹配进阶篇
索引失效的情况
范围查询的范围过大,比如>=等范围条件的匹配数量较多,或in后面的条数较多。
联合索引时违背最左匹配原则
条件筛选中有or —— 进一步分析
面经上的各种句子:
1.有or必全有索引;
2.复合索引未用左列字段;
3.like以%开头;
4.需要类型转换;
5.where中索引列有运算;
6.where中索引列使用了函数;
7.如果mysql觉得全表扫描更快时(数据少);
在下面详细分析这几点:
联合索引时违背最左匹配原则
我们在很多地方都看到说:
最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。
甚至有些帖子还会把>=、<=也作为中断联合索引的条件写上去,但真的是这样吗?
先说结论:
>、<、like 的%放在左边,会中断联合索引;
>=、<=、between、like的%只出现在右边,不会中断联合索引。
测试过程:
为了更详细的分析,在查询语句前不用explain了,改为explain extend,后者可以展示更详细的执行过程比如range。
>=:
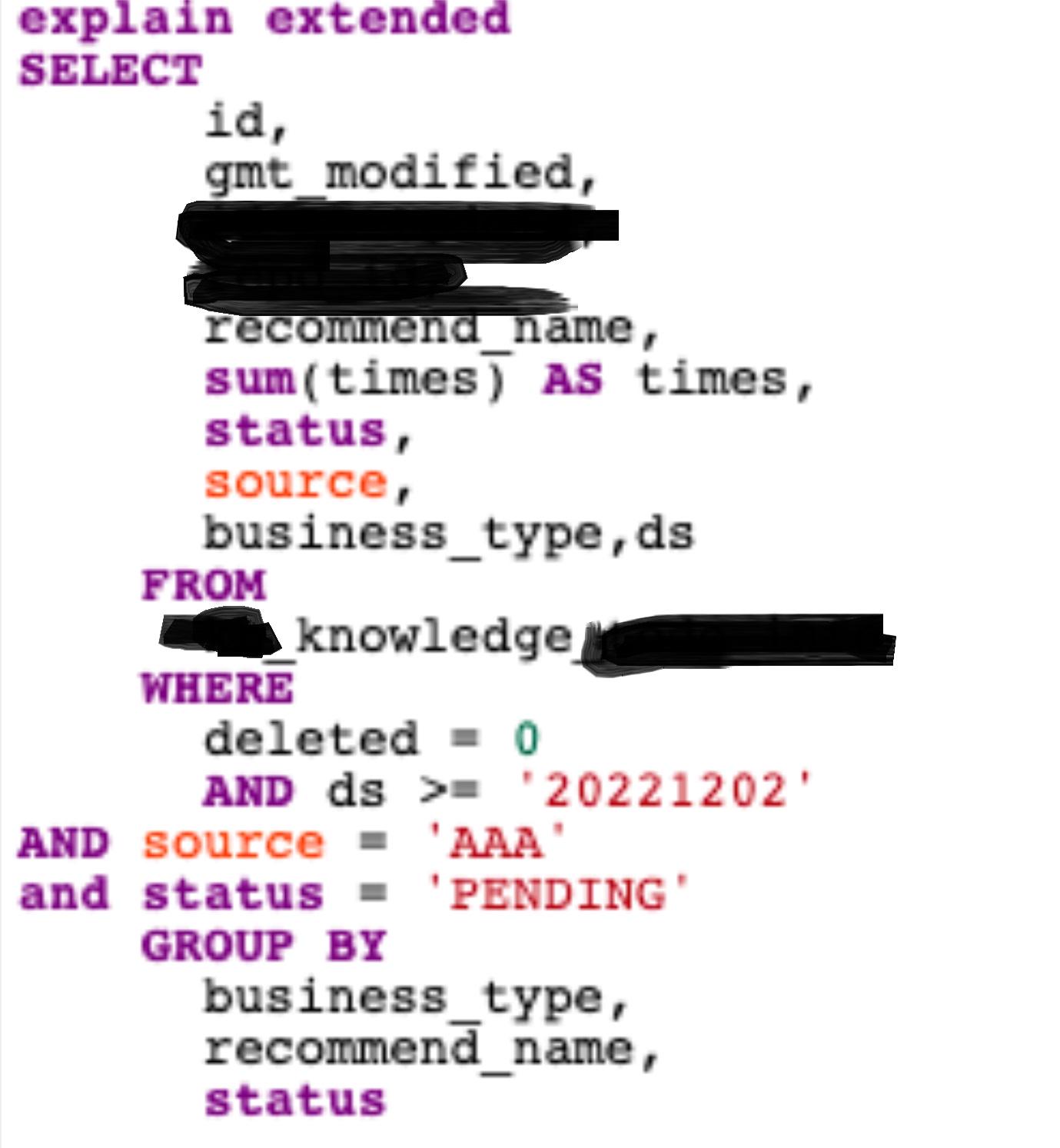


分析range:deleted、status、source字段都走了索引,ds字段走了半个。因为MIN的range里面第二个字段显示了'20221202',而MAX的显示的是MAX。正好对应了范围是[20221202,MAX)。且因为后面都走了,所以>=并没有中断索引。
>
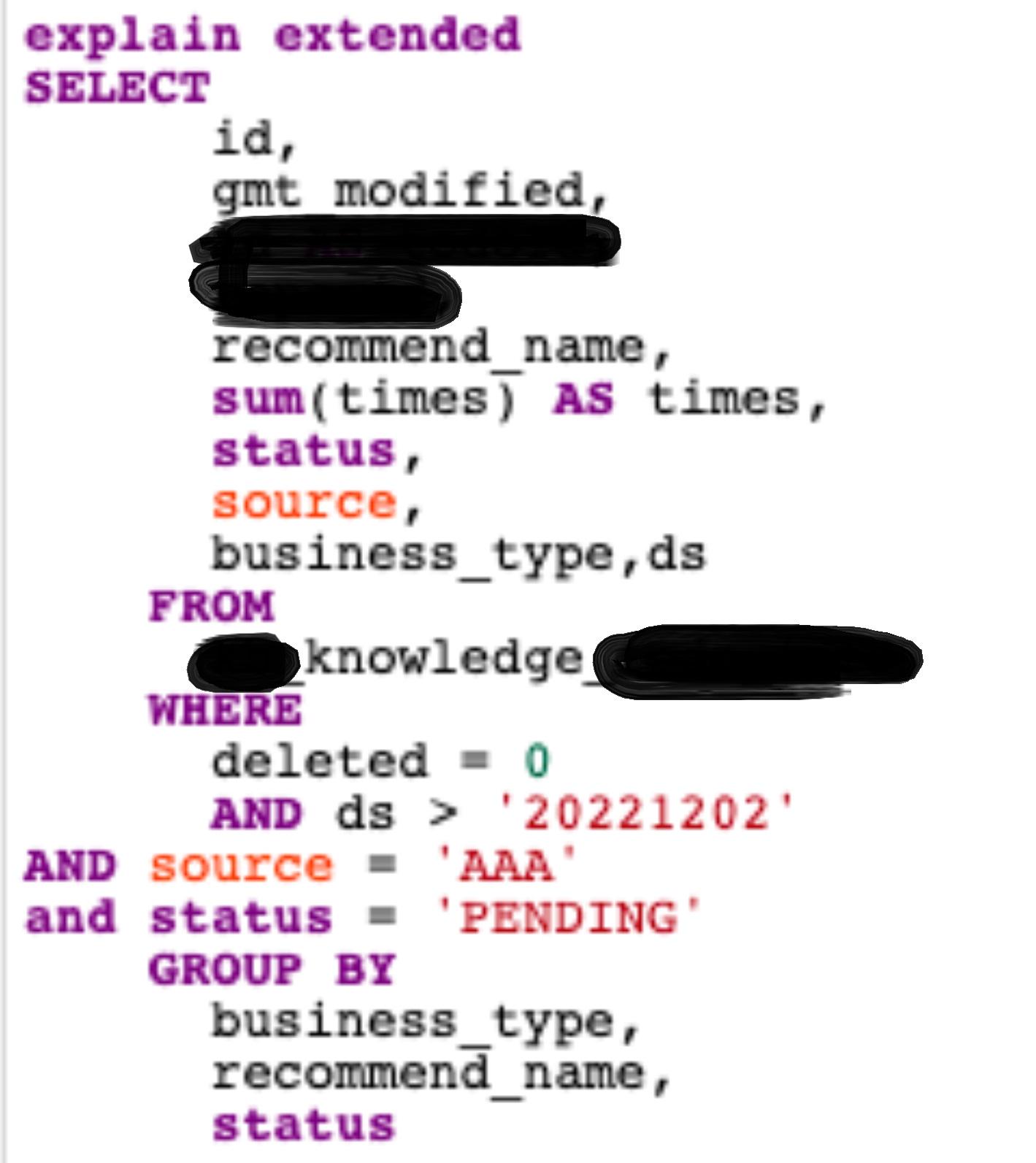


分析range:左边那一列到ds后就中断了,右边的继续往下走了,判断应该是有一部分会中断索引,另一部分不确定是不是真的没中断。
between
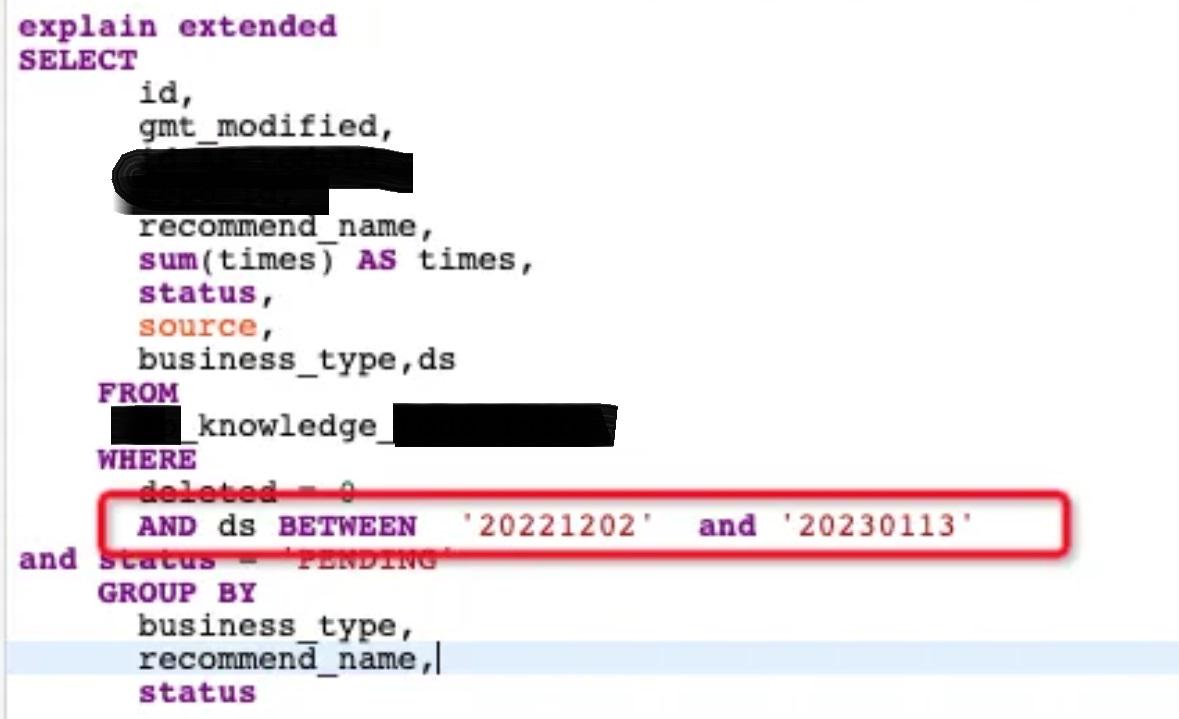

分析range:ds后面的字段没有中断索引,且ds字段最小值和最大值都被定义了,很不错。
like
右like:
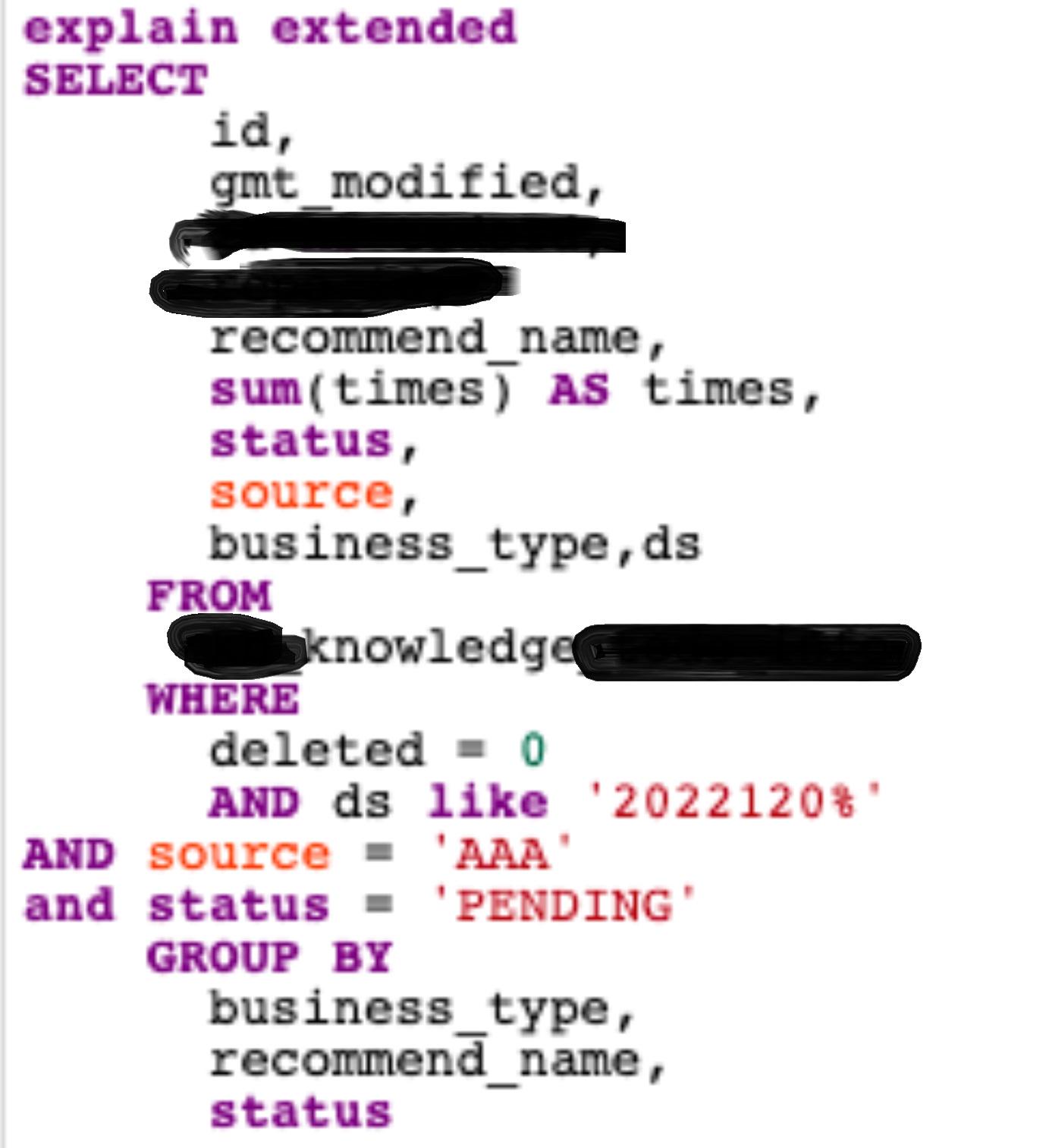


分析range:索引没有中断,ds那个字段有几个空格表示模糊匹配。(顺便试了一下like concat,结果一样)
左like:
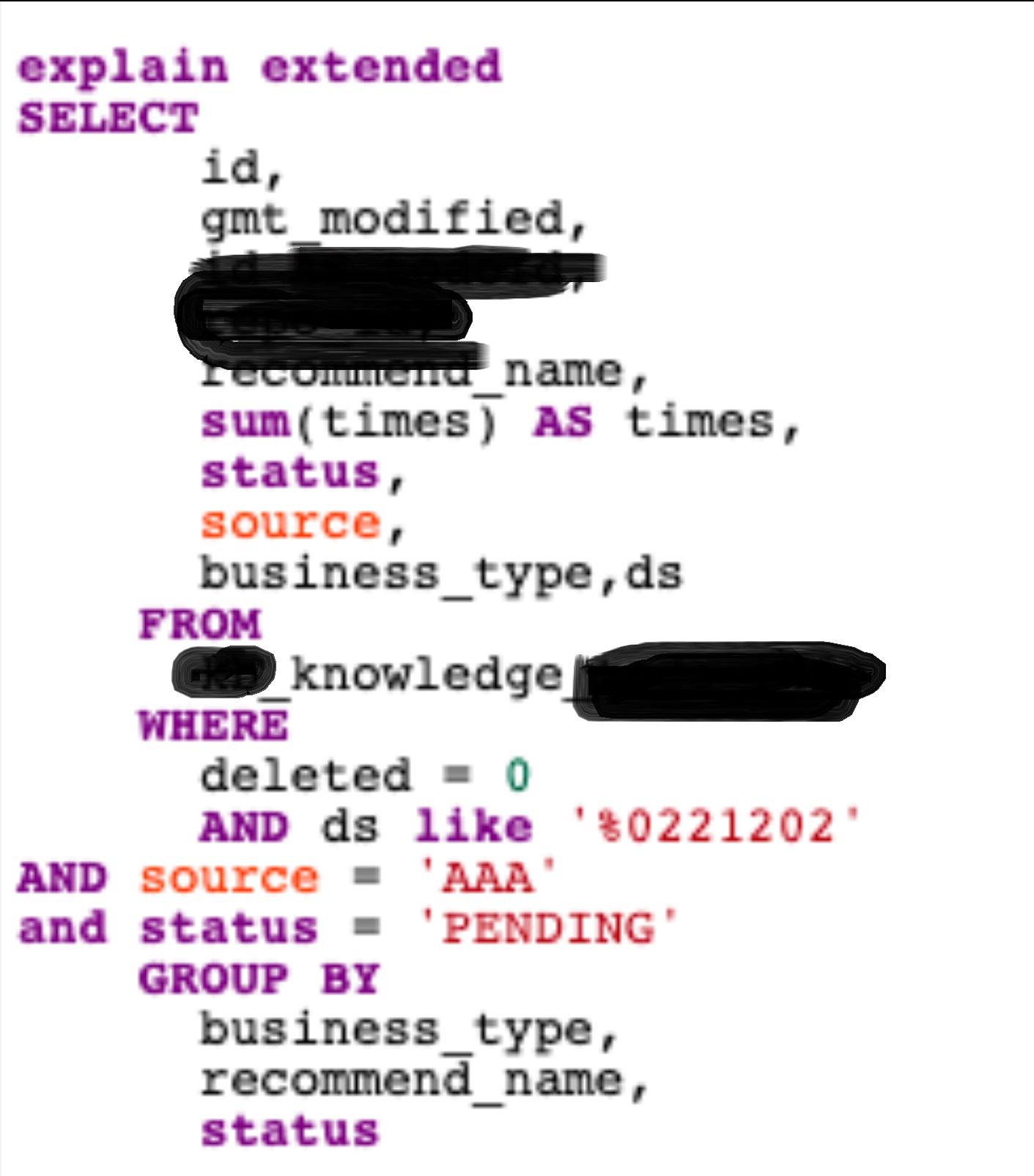

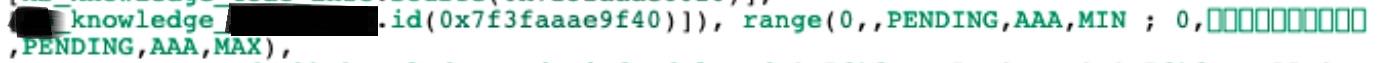
分析range:看不懂了。。但应该是不太好的。
!=
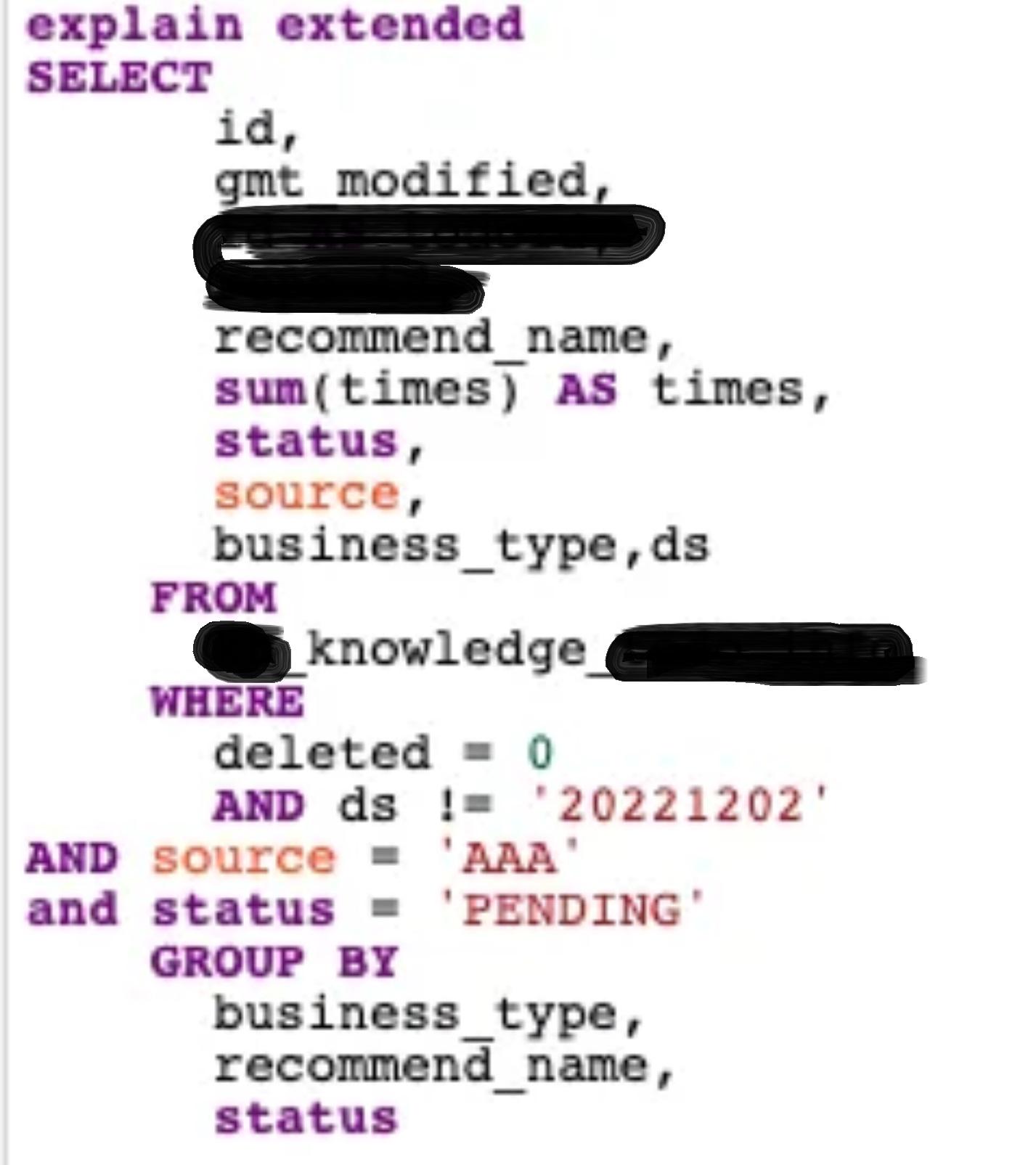
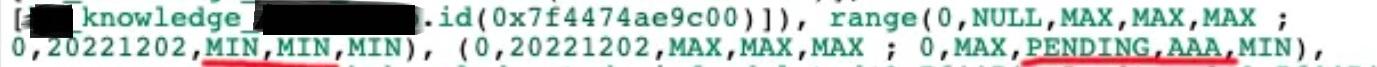
分析range:看起来是以'20221202'为分界分成了两部分,且大部分都没有走索引。
分析原因:
待补充。。。
条件筛选中有or
or的两边是不同表时,一定不走索引
几个or之间期望用到同一个索引时,必须都满足该索引。例如:
联合索引(a,b,c)
select * from table where a = 1 and b = 2 or b = 3,走不到索引,因为or右边没有走到索引。
select * from table where a = 1 and b = 2 or (a = 3 and b = 4 and c = 5),ab两个字段会走到索引,因为or左边用了ab,右边用了abc,取交集。
index merge(索引合并)的情况。
根据官方介绍,索引合并可以分为三种算法
经过自己的测试和理解,交集访问算法的意思应该是几个or条件之间的数据可能存在交集,比如:
where a = 1 or b = 2;而联合访问算法是不可能存在交集,比如:where a = 1 and b =2 or a =3 and b = 4; 排序联合则是在上一种的基础上增加了范围查询。
当mysql认为有其他执行方案的效率优于使用索引合并时,也许会不使用索引合并。
实操如下:
表knowledge_info表有两个唯一索引,分别是(deleted,a,b,c),(deleted,a,d,e),还有本身自带的主键索引。
交集访问算法
where id = 1 or deleted = 2 or (deleted = 3 and d = 3)
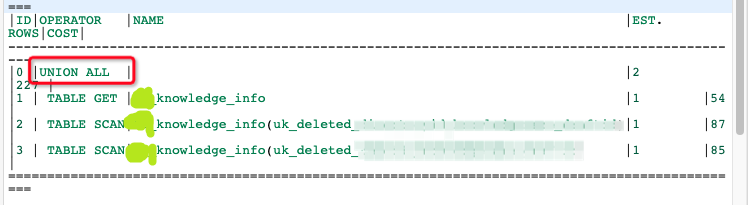
发现同一张表用到了三个索引,三个索引的range是分开的:
1.
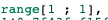
2.

3.

联合访问算法
where deleted = 3 and a > 3 or deleted = 4 and a = 3
(这里我用等于或范围查询的执行计划是一样的,只要能走到索引就行)
自己测试的执行计划中并没有出现Using union,也可能是我使用的不是原生mysql的原因。

但看详细range时,发现唯一索引的range有两个

也可能是查询优化器觉得不需要索引合并。
where id > 1 and id < 10 or id = 16
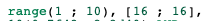
一样也是索引名没有展现,但range变为两个。
排序联合访问算法
和联合访问算法类似,只是关系有范围查询。上面的例子其实算是排序的算法,但存的图有限就一起用了。测试的时候没发现什么不同。
创建索引的思路
联合索引的优先级大于普通索引,因为联合索引可以合并多个字段,且复用率高。
联合唯一索引的优先级大于普通联合索引(业务允许的情况下),因为唯一索引的速度更快,且有些时候可以作为数据唯一性的兜底判断,且可以配合on duplicate key update技术实现新增或更新。
经常作为查询条件;或经常被作为join连接字段;或经常用作分组、排序;或如果某个重要的SQL语句的查询的字段有限,可以把查询的字段都增加索引以避免回表查询。
索引字段需要有区分度,比如如果字段是性别,值只有男、女,那么这个字段就不适合作为索引,或者说不能只依靠这个索引来搜索。
最近就出现了类似的问题,线上表只有1.6w条数据,查询速度却达到了秒级。就是因为索引失效导致了全表扫描。
那张表是数据挖掘信息表,索引是deleted(删除标识)、ds(业务日期,8位)、status(状态)。业务逻辑是前端展示前30天的挖掘数据,设计时没有考虑到删除过期数据的必要性,导致线上表所有数据的deleted值都是0。然后ds因为是>=-30天,范围也较大;status在没有选筛选条件时无值,即便选了也没区分度,大部分的状态都是PENDING。就导致MySQL用全表扫描来执行了。
后来的解决是,先执行脚本把30天以前的deleted值都改为id;然后代码中在接收消息插入数据的地方判断是否有新的过期数据,对其删除;再然后联合索引增加一个字段值。性能提升了几十倍。
总结
有时执行计划显示走了索引且耗时短,实际改完后测试的并没有短,甚至可能耗时更长了,只能说索引这部分应该是有点玄学在的。
但基本的一些知识基本还是固定的,只是索引合并那块我实在不想看到了,以后如果有机会接触到再说吧。















 8641
8641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









