






在阅读linux 3.10版本的socket 一节源码时,遇到了一个
rcu_dereference();
函数,于是深入了解了一下这个技术。Documentation 链接:【https://docs.kernel.org/RCU/whatisRCU.html?highlight=rcu_dereference#whatisrcu】
具体内容:
- RCU OVERVIEW
The basic idea behind RCU is to split updates into “removal” and “reclamation” phases. The removal phase removes references to data items within a data structure (possibly by replacing them with references to new versions of these data items), and can run concurrently with readers. The reason that it is safe to run the removal phase concurrently with readers is the semantics of modern CPUs guarantee that readers will see either the old or the new version of the data structure rather than a partially updated reference. The reclamation phase does the work of reclaiming (e.g., freeing) the data items removed from the data structure during the removal phase. Because reclaiming data items can disrupt any readers concurrently referencing those data items, the reclamation phase must not start until readers no longer hold references to those data items.
Splitting the update into removal and reclamation phases permits the updater to perform the removal phase immediately, and to defer the reclamation phase until all readers active during the removal phase have completed, either by blocking until they finish or by registering a callback that is invoked after they finish. Only readers that are active during the removal phase need be considered, because any reader starting after the removal phase will be unable to gain a reference to the removed data items, and therefore cannot be disrupted by the reclamation phase.
So the typical RCU update sequence goes something like the following:
a) Remove pointers to a data structure, so that subsequent readers cannot gain a reference to it.
b) Wait for all previous readers to complete their RCU read-side critical sections.
At this point, there cannot be any readers who hold references to the data structure, so it now may safely be reclaimed (e.g., kfree()d).
c) Step (b) above is the key idea underlying RCU’s deferred destruction.
The ability to wait until all readers are done allows RCU readers to use much lighter-weight synchronization, in some cases, absolutely no synchronization at all. In contrast, in more conventional lock-based schemes, readers must use heavy-weight synchronization in order to prevent an updater from deleting the data structure out from under them. This is because lock-based updaters typically update data items in place, and must therefore exclude readers. In contrast, RCU-based updaters typically take advantage of the fact that writes to single aligned pointers are atomic on modern CPUs, allowing atomic insertion, removal, and replacement of data items in a linked structure without disrupting readers. Concurrent RCU readers can then continue accessing the old versions, and can dispense with the atomic operations, memory barriers, and communications cache misses that are so expensive on present-day SMP computer systems, even in absence of lock contention.
In the three-step procedure shown above, the updater is performing both the removal and the reclamation step, but it is often helpful for an entirely different thread to do the reclamation, as is in fact the case in the Linux kernel’s directory-entry cache (dcache). Even if the same thread performs both the update step (step (a) above) and the reclamation step (step © above), it is often helpful to think of them separately. For example, RCU readers and updaters need not communicate at all, but RCU provides implicit low-overhead communication between readers and reclaimers, namely, in step (b) above.
RCU(Read-Copy Update)目的是提高遍历读取数据的效率,为了达到目的使用RCU机制读取数据的时候不对链表进行耗时的加锁操作。这样在同一时间可以有多个线程同时读取该链表,并且允许一个线程对链表进行修改(修改的时候,需要加锁)。RCU适用于需要频繁的读取数据,而相应修改数据并不多的情景,例如在文件系统中,经常需要查找定位目录,而对目录的修改相对来说并不多,这就是RCU发挥作用的最佳场景。顾名思义就是“读,拷贝更新”,再直白点是“随意读,但更新数据的时候,需要先复制一份副本,在副本上完成修改,再一次性地替换旧数据”。这是 Linux 内核实现的一种针对“读多写少”的共享数据的同步机制。
RCU既允许多个读者同时访问被保护的数据,又允许多个读者和多个写者同时访问被保护的数据(注意:是否可以有多个写者并行访问取决于写者之间使用的同步机制),读者没有任何同步开销,而写者的同步开销则取决于使用的写者间同步机制。但RCU不能替代rwlock,因为如果写比较多时,对读者的性能提高不能弥补写者导致的损失。
读者在访问被RCU保护的共享数据期间不能被阻塞,这是RCU机制得以实现的一个基本前提,也就说当读者在引用被RCU保护的共享数据期间,读者所在的CPU不能发生上下文切换,spinlock和rwlock都需要这样的前提。写者在访问被RCU保护的共享数据时不需要和读者竞争任何锁,只有在有多于一个写者的情况下需要获得某种锁以与其他写者同步。
写者修改数据前首先拷贝一个被修改元素的副本,然后在副本上进行修改,修改完毕后它向垃圾回收器注册一个回调函数以便在适当的时机执行真正的修改操作。等待适当时机的这一时期称为grace period,而CPU发生了上下文切换称为经历一个quiescent state,grace period就是所有CPU都经历一次quiescent state所需要的等待的时间。垃圾收集器就是在grace period之后调用写者注册的回调函数来完成真正的数据修改或数据释放操作的。
RCU 对于链表的处理很高效。
主要的几个API接口:
rcu_read_lock()
rcu_read_unlock()
创建rcu 读着临界区
synchronize_rcu() / call_rcu()
挂起写者,等待读者都退出后释放老的数据值;
rcu_assign_pointer()
写者使用改函数来为一个被RCU保护的指针分配一个新的值;
rcu_dereference()
读者调用来获得一个被RCU保护的指针
/* `p` 指向一块受 RCU 保护的共享数据 */
/* reader */
rcu_read_lock();
p1 = rcu_dereference(p);
if (p1 != NULL) {
printk("%d\n", p1->field);
}
rcu_read_unlock();
/* free the memory */
p2 = p;
if (p2 != NULL) {
p = NULL;
synchronize_rcu();
kfree(p2);
}
这里指向了一个临界区,p是被RCU保护的。
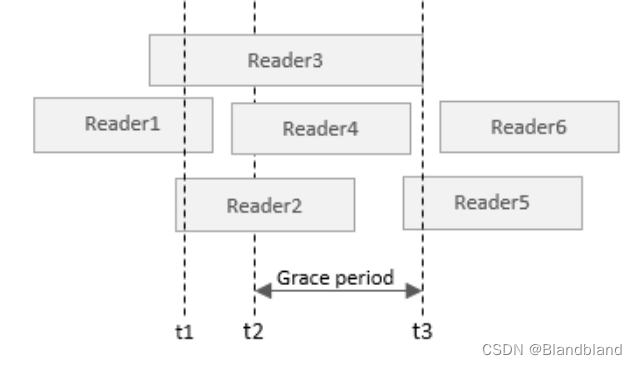
如果多个Reader指向了p,例如Reader1,2,3均获得了读取权限。当t2时刻,执行到p=NULL时,synchronize_rcu()就会阻塞,直到t3,这时候才会释放p2。
下面看一下源码:
#define __rcu_assign_pointer(p, v, space) \
({ \
smp_wmb(); \
(p) = (typeof(*v) __force space *)(v); \
})
这里smp_wmb() 就是增加了一个内存屏障 ,保存内存屏障之间的指令一定会先于内存屏障后的指令被执行。
#define __rcu_dereference_check(p, c, space) \
({ \
typeof(*p) *_________p1 = (typeof(*p)*__force )ACCESS_ONCE(p); \
rcu_lockdep_assert(c, "suspicious rcu_dereference_check()" \
" usage"); \
rcu_dereference_sparse(p, space); \
smp_read_barrier_depends(); \
((typeof(*p) __force __kernel *)(_________p1)); \
})
第 3 行:声明指针 _p1 = p;
第 7 行:smp_read_barrier_depends();
第 8 行:返回 _p1;
static inline void synchronize_rcu(void)
{
synchronize_sched();
}















 5233
5233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









