










1,题目要求
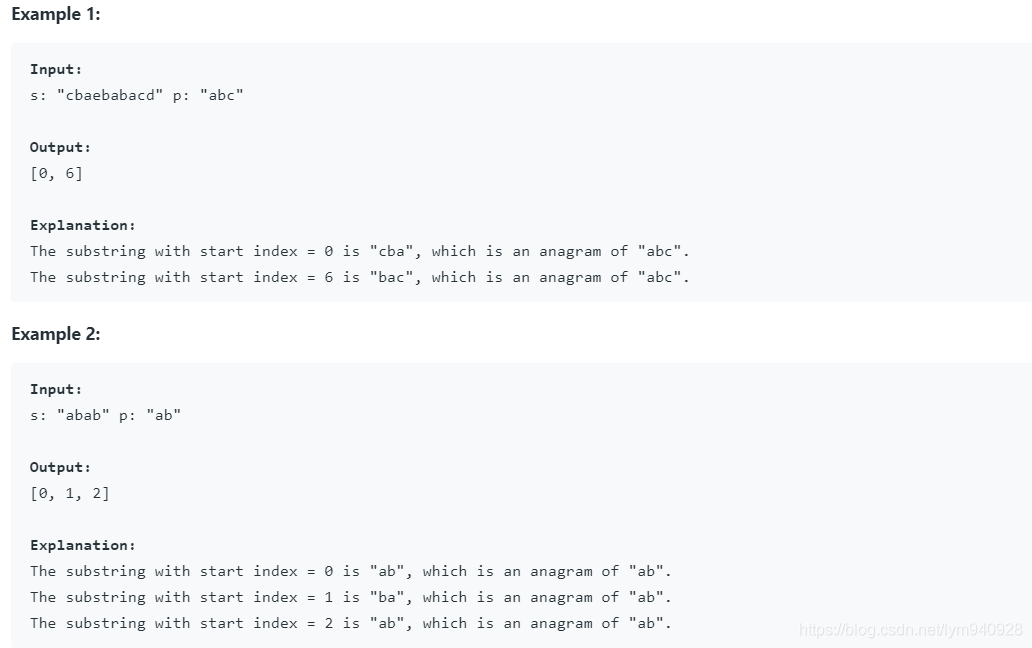
Given a string s and a non-empty string p, find all the start indices of p’s anagrams in s.
Strings consists of lowercase English letters only and the length of both strings s and p will not be larger than 20,100.
The order of output does not matter.
给定一个字符串s和一个非空字符串p,找到s中p的anagrams的所有起始索引。
字符串仅由小写英文字母组成,字符串s和p的长度不会大于20,100。
输出顺序无关紧要。
2,题目思路
对于这道题,首先给定两个字符串,其中一个字符串p类似于一个模板,判断第一个字符串s中有多少个字符和p中相同的单词,返回它们的索引值。
这道题的难点有两个:
- 对两个单词的字符是否相等进行判断。
- 滑动窗口。
对于第一个问题,一个比较常见到的思路,就是利用Hash表来进行。即将第二个单词p作为模板,把其中每个出现的字符统计一下。
而统计hash表也有两种方式:
- 直接定义长度为26的hash,利用c - 'a’的方式映射到0-26上;
- 定义一个长度为256的hash,让c的ASCII值作为索引。
这样,在遍历两个单词时,初始化Hash后,再找到一共需要判断的字符的个数——也就是p的长度。
遍历完一次,就可以判断两个单词的单词是否相同了。
对于第二个问题,滑动窗口。一般的解决办法是定义窗口的左右边界通过right++,到达窗口大小极限、left++的方式来实现窗口的滑动。
3,代码实现
int x = []() {
ios_base::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
return 0;
}();
class Solution {
public:
vector<int> findAnagrams(string s, string p) {
vector<int> res = {};
if(s.empty() || p.empty())
return res;
//ASCII作为索引
vector<int> hash (256, 0);
//初始化hash模板
for(auto c : p)
hash[c]++;
//需要判断的总长度
int sLen = s.size();
//模板的长度,也就是需要判断的字符个数
int count = p.size();
int left = 0;
int right = 0;
while(right < sLen){
//如果值大于1,说明此时s[right]对应的字符在模板还有可对应的。
//于是,count也要减一,说明找到了对应的
//如果值为0,说明此时模板中已经没有可以与此事s[right]对应的字符了
if(hash[s[right]] >= 1)
count--;
//该字符在模板中已经使用了,因此需要减一;
//窗口向右移动一步
hash[s[right]]--;
right++;
//如果count变为了0,说明在规定的长度中找到了对应的单词
//因此,将s中对应单词的开始索引、也就是left加入到res中
if(count == 0)
res.push_back(left);
//因为如果我们要向右滑动窗口,因此,此时最左边的字符就不会考虑
//但是最左边的字符我们是已经经过了判断的,对hash表做了修改的
//因此,我们需要对已经改变的hash表进行还原
//之所以要进行hash[s[left]] >= 0的判断是因为,如果left对应的字符时出现在p中的,
//那么,当时在计算count就会进行减1操作,
//但是,我们此时已经滑动了窗口了,该字符已经不被考虑了
//因此,我们需要对count进行一次还原
//经过观察我们可以看到,其实和right的操作是一种镜像操作
if(right - left == p.size()){
if(hash[s[left]] >= 0)
count++;
hash[s[left]]++;
left++;
}
}
return res;
}
};














 359
359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









