







决策树裁剪有两种方式:预裁剪和后裁剪。预裁剪是在划分叶节点时进行计算,如果划分能带来泛化性能则划分,否则不划分。后裁剪是决策树完全划分完毕后,自底向上对结点进行考察,如果性能提升则合并,其训练时间比预裁剪决策树要大得多。
训练数据:
1,青绿,蜷缩,浊响,清晰,凹陷,硬滑,是
2,乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,是
3,乌黑,蜷缩,浊响,清晰,凹陷,硬滑,是
6,青绿,稍蜷,浊响,清晰,稍凹,软粘,是
7,乌黑,稍蜷,浊响,稍糊,稍凹,软粘,是
10,青绿,硬挺,清脆,清晰,平坦,软粘,否
14,浅白,稍蜷,沉闷,稍糊,凹陷,硬滑,否
15,乌黑,稍蜷,浊响,清晰,稍凹,软粘,否
16,浅白,蜷缩,浊响,模糊,平坦,硬滑,否
17,青绿,蜷缩,沉闷,稍糊,稍凹,硬滑,否
测试数据:
4,青绿,蜷缩,沉闷,清晰,凹陷,硬滑,是
5,浅白,蜷缩,浊响,清晰,凹陷,硬滑,是
8,乌黑,稍蜷,浊响,清晰,稍凹,硬滑,是
9,乌黑,稍蜷,沉闷,稍糊,稍凹,硬滑,否
11,浅白,硬挺,清脆,模糊,平坦,硬滑,否
12,浅白,蜷缩,浊响,模糊,平坦,软粘,否
13,青绿,稍蜷,浊响,稍糊,凹陷,硬滑,否
预裁剪代码:
from math import log
import operator
import treePlotter as tp
def createDataSet(filename):
dataSet=[]
fr = open(filename)
for line in fr.readlines():
lineArr = line.strip().split(',')
dataSet.append(lineArr[:]) # 添加数据
labels = ['编号','色泽','根蒂','敲声','纹理','头部','触感','好瓜']
#change to discrete values
return dataSet, labels
#计算信息熵 Ent(D)=-Σp*log2(p)
def calcShannonEnt(dataSet):
numEntries = len(dataSet) #数据总数
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1] #获取类别
if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0 #新key加入字典赋值为0
labelCounts[currentLabel] += 1 #已经存在的key,value+=1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob,2) #计算信息熵
return shannonEnt
#获取特征值数据集
# dataSet --整个数据集
# axis --数据列
# value --类别
def splitSubDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
retDataSet.append([featVec[axis],featVec[-1]])
return retDataSet
#除去划分完成的决策树数据量
def splitDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
# 计算连续变量的分类点
# def calcconplot(subDataSet)
# 计算信息增益并返回信息增益最高的列
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 #获取所有特征值数量(减1是除去最后一列分类)
baseEntropy = calcShannonEnt(dataSet) #计算基础信息熵Ent(D)
bestInfoGain = 0.0; bestFeature = []
for i in range(1,numFeatures): #遍历所有特征值
featList = [example[i] for example in dataSet]#将特征值保存在列表中
uniqueVals = set(featList) #获取特征值分类
newEntropy = 0.0 #特征值不连续
for value in uniqueVals:
subDataSet = splitSubDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy #计算信息增益
if (infoGain > bestInfoGain): #保存信息增益最高的列
bestInfoGain = infoGain
bestFeature = i
return bestFeature #返回新增增益最高的列
#特征若已经划分完,节点下的样本还没有统一取值,则需要进行投票
def majorityCnt(classList):
classCount={}
for vote in classList:
if vote not in classCount.keys():
classCount[vote]=0
classCount[vote]+=1
return max(classCount)
# 创建决策树
def createTree(dataSet,labels,validateData):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]#当所有类都相同则不在分类
if len(dataSet[0]) == 1: #没有更多特征值时不再分类
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet) #选取信息增益最大的特征值
bestFeatLabel = labels[bestFeat] #获取特征值列头名
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues) # 获取特征值分类
beforeCorrect = undivideCorrect(classList,validateData)
afterCorrect = divideCorrect(dataSet,uniqueVals,bestFeat,validateData)
if(beforeCorrect>afterCorrect):
return majorityCnt(classList)
myTree = {bestFeatLabel:{}}
del(labels[bestFeat]) # 删除已经建立节点的特征值
for value in uniqueVals:
subLabels = labels[:] # 复制出建立节点外的所有特征值
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels,splitDataSet(validateData, bestFeat, value)) #建立子节点
return myTree
# 不裁剪正确率
def undivideCorrect(classList,validateData):
good = splitSubDataSet(validateData, len(validateData[0]) - 1, max(classList)) # 获取正确个数的个数
beforeCorrect = len(good) / len(validateData) # 正确率
return beforeCorrect
# 裁剪正确率
def divideCorrect(dataSet,uniqueVals,bestFeat,validateData):
good = 0
for value in uniqueVals: # 遍历所有分类节点
featList = [feat[-1] for feat in splitDataSet(dataSet, bestFeat, value)] # 从训练集中判断是属于好瓜还是坏瓜
templList = splitSubDataSet(validateData, bestFeat, value) # 从测试集中获取包含特征值数目
goodList = []
if(len(templList)>0):
goodList = splitSubDataSet(templList, len(templList[0]) - 1, max(featList)) # 获取正确个数的个数
good +=len(goodList)
return good / len(validateData) # 正确率
# 决策树进行分类
def classify(inputTree,featLabels,testVec):
firstStr = list(inputTree.keys())[0] # 获取第一个节点
secondDict = inputTree[firstStr] # 获取剩余节点
featIndex = featLabels.index(firstStr)
key = testVec[featIndex] # 获取测试数据分支
valueOfFeat = secondDict[key] # 进入分支
if isinstance(valueOfFeat, dict):
classLabel = classify(valueOfFeat, featLabels, testVec)
else: classLabel = valueOfFeat
return classLabel
if __name__ == '__main__':
myData,label = createDataSet('TrainingData.txt')
validateData,vlabel = createDataSet('ValidateData.txt')
mytree = createTree(myData,label,validateData)
tp.createPlot(mytree)
未裁剪与预裁剪结果对比:
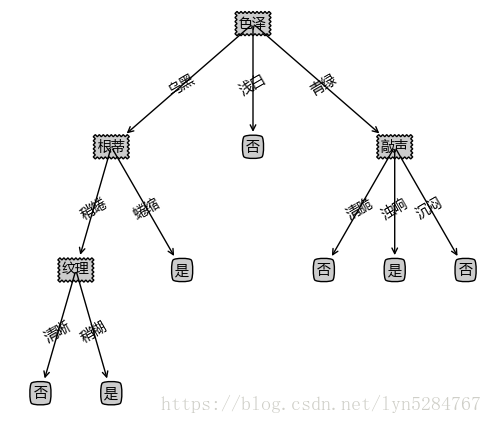
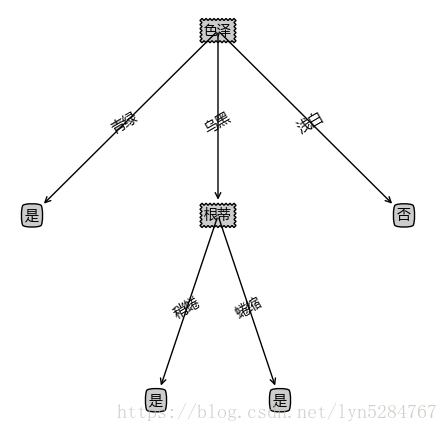
后裁剪代码:
from math import log
import operator
import treePlotter as tp
def createDataSet(filename):
dataSet=[]
fr = open(filename)
for line in fr.readlines():
lineArr = line.strip().split(',')
dataSet.append(lineArr[:]) # 添加数据
labels = ['编号','色泽','根蒂','敲声','纹理','头部','触感','好瓜']
#change to discrete values
return dataSet, labels
#计算信息熵 Ent(D)=-Σp*log2(p)
def calcShannonEnt(dataSet):
numEntries = len(dataSet) #数据总数
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1] #获取类别
if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0 #新key加入字典赋值为0
labelCounts[currentLabel] += 1 #已经存在的key,value+=1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob,2) #计算信息熵
return shannonEnt
#获取特征值数据集
# dataSet --整个数据集
# axis --数据列
# value --类别
def splitSubDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
retDataSet.append([featVec[axis],featVec[-1]])
return retDataSet
#除去划分完成的决策树数据量
def splitDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
# 计算信息增益并返回信息增益最高的列
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 #获取所有特征值数量(减1是除去最后一列分类)
baseEntropy = calcShannonEnt(dataSet) #计算基础信息熵Ent(D)
bestInfoGain = 0.0; bestFeature = []
for i in range(1,numFeatures): #遍历所有特征值
featList = [example[i] for example in dataSet]#将特征值保存在列表中
uniqueVals = set(featList) #获取特征值分类
newEntropy = 0.0 #特征值不连续
for value in uniqueVals:
subDataSet = splitSubDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy #计算信息增益
if (infoGain > bestInfoGain): #保存信息增益最高的列
bestInfoGain = infoGain
bestFeature = i
return bestFeature #返回新增增益最高的列
#特征若已经划分完,节点下的样本还没有统一取值,则需要进行投票
def majorityCnt(classList):
classCount={}
for vote in classList:
if vote not in classCount.keys():
classCount[vote]=0
classCount[vote]+=1
return max(classCount)
# 创建决策树
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]#当所有类都相同则不在分类
if len(dataSet[0]) == 1: #没有更多特征值时不再分类
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet) #选取信息增益最大的特征值
bestFeatLabel = labels[bestFeat] #获取特征值列头名
myTree = {bestFeatLabel:{}}
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues) # 获取特征值分类
del(labels[bestFeat]) # 删除已经建立节点的特征值
for value in uniqueVals:
subLabels = labels[:] # 复制出建立节点外的所有特征值
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels) #建立子节点
return myTree
def postPruning(inputTree,dataSet,validateData,label):
firstStr = list(inputTree.keys())[0]
secondDict = inputTree[firstStr]
classList = [example[-1] for example in dataSet]
featkey = firstStr
labelIndex = label.index(featkey)
temp_labels = label.copy()
del (label[labelIndex])
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
if type(dataSet[0][labelIndex]).__name__ == 'str':
inputTree[firstStr][key] = postPruning(secondDict[key], splitDataSet(dataSet, labelIndex, key),
splitDataSet(validateData, labelIndex, key),label.copy())
else:
inputTree[firstStr][key] = postPruning(secondDict[key], splitDataSet(dataSet, labelIndex, key),
splitDataSet(validateData, labelIndex,key), label.copy())
beforeCorrect = undivideCorrect(classList, validateData)
afterCorrect = divideCorrect(dataSet, secondDict.keys(), labelIndex, validateData)
if (beforeCorrect > afterCorrect):
return majorityCnt(classList)
return inputTree
# 不裁剪正确率
def undivideCorrect(classList,validateData):
good = splitSubDataSet(validateData, len(validateData[0]) - 1, max(classList)) # 获取正确个数的个数
beforeCorrect = len(good) / len(validateData) # 正确率
return beforeCorrect
# 裁剪正确率
def divideCorrect(dataSet,uniqueVals,bestFeat,validateData):
good = 0
for value in uniqueVals: # 遍历所有分类节点
featList = [feat[-1] for feat in splitDataSet(dataSet, bestFeat, value)] # 从训练集中判断是属于好瓜还是坏瓜
templList = splitSubDataSet(validateData, bestFeat, value) # 从测试集中获取包含特征值数目
goodList = []
if(len(templList)>0):
goodList = splitSubDataSet(templList, len(templList[0]) - 1, max(featList)) # 获取正确个数的个数
good +=len(goodList)
return good / len(validateData) # 正确率
if __name__ == '__main__':
myData,label = createDataSet('TrainingData.txt')
validateData,vlabel = createDataSet('ValidateData.txt')
tmplabel = label.copy()
mytree = createTree(myData,tmplabel)
postPruning(mytree,myData,validateData,label)
tp.createPlot(mytree)
结果:
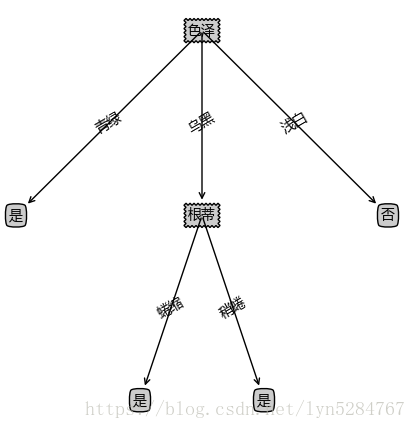














 143
143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









