








motivation:
1、以前的方法在处理每种模态中语义实体之间的长期交互方面存在困难。RIS需要捕捉这种交互,因为语言表达通常涉及到复杂的实体之间的关系,以精确地指出目标区域。在这方面,cnn和rnn由于其基本构建模块的局部性而受到限制。
2、现有模型难以对两种模态之间复杂的相互作用进行建模。它们通过拼接-卷积运算聚合视觉和语言特征,它无法足够灵活有效地处理大量的各种RIS场景。
idea:
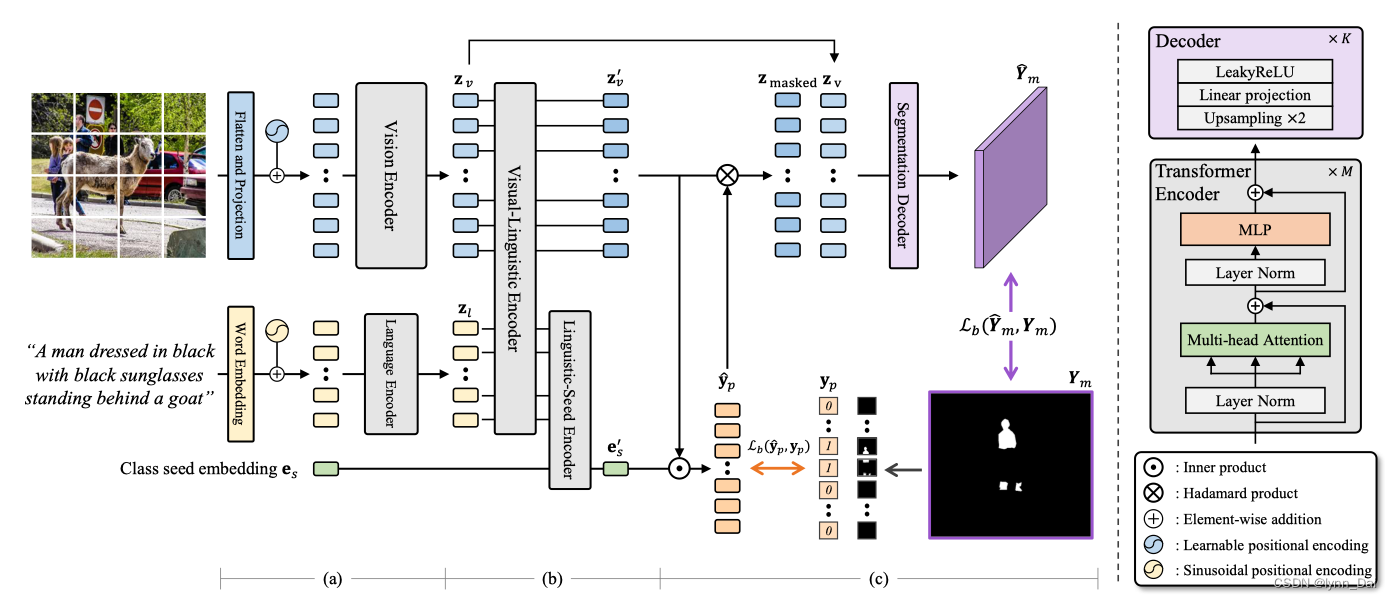
1、ReSTR通过transformer提取视觉和语言特征。视觉编码器和语言编码器分别以一组不重叠的图像块和一组文字嵌入块作为输入,提取它们的特征,同时考虑它们在每个模态内的长期相互作用。通过对两种模态都使用transformer,作者利用了从特征提取开始就获取全局上下文和统一两种模式的网络拓扑的优势。
2、自注意编码器将视觉和语言特征聚合成一个贴片式多模态特征。融合编码器以类种子嵌入作为另一个输入。融合编码器将类种子嵌入自适应转换为语言表达式中描述的目标实体的分类器。
3、多模态融合编码器的输出,即分片多模态特征和自适应分类器,作为输入,输入到分割解码器。解码器以粗到细的方式计算最终的分割映射。首先将自适应分类器作为一个分类器应用于每个多模态特征,检测每个图像补丁是否包含目标实体的一部分。然后通过一系列上采样和线性层将粗略的patch级预测转换为像素级分割图。
contribution:
- 是第一个用于RIS的无卷积架构。 它捕获视觉和语言模式之间的远程交互,并通过transformer统一两种不同模式的网络拓扑。
- 为了对两种模态的精细理解进行编码,设计了带有类种子嵌入的多模态融合编码器,该编码器被转换为用于RIS的自适应分类器。














 1249
1249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









