







我们需要用到一个叫pydub的类库,
pydub是python的高级一个音频处理库,可以让你以一种不那么蠢的方法处理音频。---开发者原话
https://github.com/jiaaro/pydub附上开发者的github地址
安装:
pip install pydub如果在pycharm中也可以这样安装:
setting----Project Interpreter----右边绿色+号
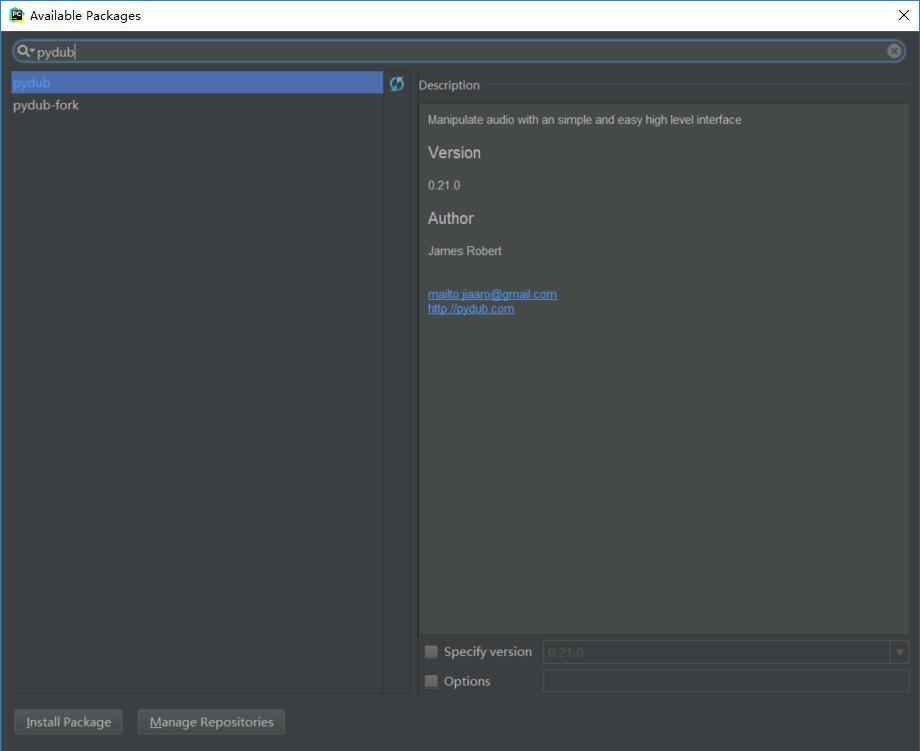
点一下install package
依赖安装:
作者在github 上说,依赖可以安装libav or ffmpeg 关于这两个东西的爱恨情仇可以自行百度
我们安装其一就行
Mac (using homebrew):
# libav
brew install libav --with-libvorbis --with-sdl --with-theora
#### OR #####
# ffmpeg
brew install ffmpeg --with-libvorbis --with-sdl2 --with-theora
Linux (using aptitude):
# libav
apt-get install libav-tools libavcodec-extra-53
#### OR #####
# ffmpeg
apt-get install ffmpeg libavcodec-extra-53
上面是MAC和Linux 的安装方法,由于我开发环境用的是windows 系统,对libac支持不大好,我采用了ffmpeg
先去ffmpeg官网下载
https://ffmpeg.zeranoe.com/builds/Linking 选择Static ,好了之后解压缩,随便解压到哪,我们配一下环境变量
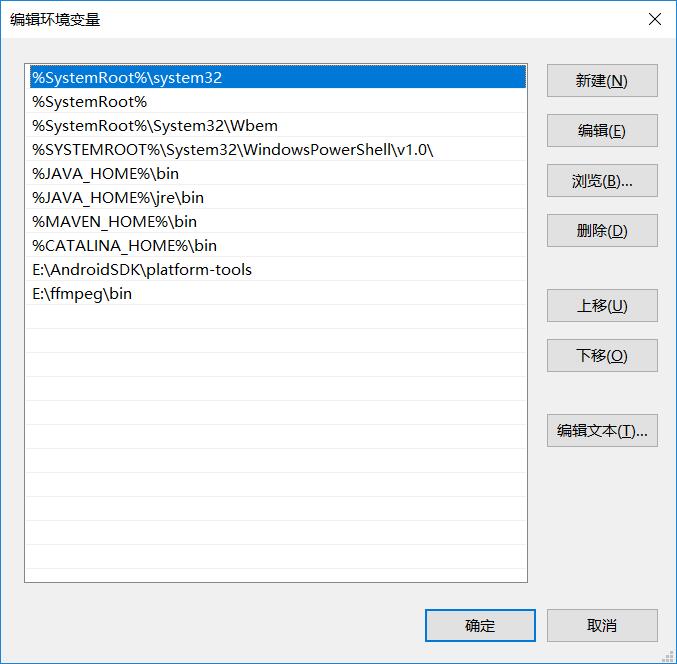
把刚刚解压的路径配到Path里面,重开IDE
注意点:开IDE时候需要选择用管理员权限运行
代码:
from pydub import AudioSegment
def trans_mp3_to_wav(filepath):
song = AudioSegment.from_mp3(filepath)
song.export("now.wav", format="wav")简单封装了一个方法,把mp3路径扔进去,就能输出一个now.wav文件。















 538
538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









