






TCP连接过程是状态的转换,促使发生状态转换的是用户调用
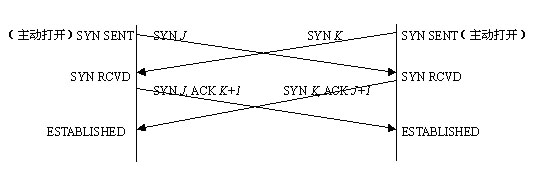
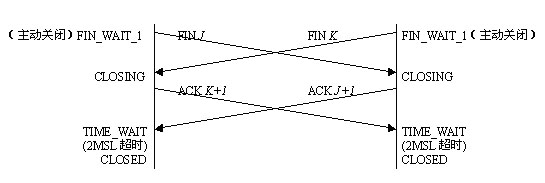
- TCP三次握手和四次握手的状态迁移
- 在任意时刻发生丢包或者重复包时,TCP/IP的处理策略
- Linux系统调用对TCP/IP可以进行哪些设置,主要针对哪些方面的优化
- TCP由RFC793、RFC1122、RFC1323、RFC2001、RFC2018以及RFC2581定义
- TCP提供可靠性保证
- TCP发送数据后,要求对方返回确认,如果没有收到确认,TCP会进行重传,数次重传失败后,TCP才会放弃
- TCP含有动态估算RTT(round-trip time)的算法,可以根据网络拥塞情况动态调整RTT,重新传等待时间就是使用RTT来确定的
- TCP通过给所发送数据的每一个字节关联一个序列号进行排序,从而处理分包非顺序到达和重复包的情况
- TCP提供流量控制。TCP总能告诉对方自己还能接收多少字节的数据(advertised window——通告窗口),防止接收缓冲区溢出。窗口随着数据的到来和从缓冲区中取走数据而动态变化。
- TCP是全双工的。所以TCP必须跟踪每个方向数据流的状态信息(如序列号和通告窗口的大小)

上面的状态迁移图,基本上把TCP三次握手和四次握手的大致流程描述的非常清楚了,下面我们用文字将上面的过程描述一遍,并对异常情况进行分析:

三次握手概述:
- 服务器主动进入LISTEN状态,监听端口
- 客户发送第一次握手请求,发送完毕后进入SYN_SEND状态,等待服务器响应
- 服务器收到第一次握手请求,向客户确认第一次请求,连带发送第二次握手请求,发送完毕后进入SYN_RECV状态,等待客户响应
- 客户收到确认和第二次握手请求,对第二次握手请求进行确认(第三次握手),发送确认完毕后,进入ESTABLISHED状态
- 服务器收到对第二次握手请求的确认之后(第三次握手),进入ESTABLISHED状态
- 至此,三次握手完成,客户-服务器完成连接的建立,开始数据通信
- 服务器通过socket()、bind()和listen()来完成CLOSED状态到LISTEN状态的转化,称为被动打开。被动打开完成之后,accept()阻塞,等待客户请求
- 客户通过connect()进行主动打开。这引起客户TCP发送一个SYN分节,用于通知服务器客户将在连接中发送数据的初始序列号(一般SYN分节不包含任何数据,只有TCP和IP的头部信息)
- 服务器以单个分节,同时对客户的SYN序列号进行确认,并发送自己的SYN序列号(此时accept()还在阻塞中)
- 客户对服务器的SYN数据进行确认。客户在收到服务器SYN并进行确认之后,connect()返回
- 服务器收到客户的确认,accept()返回
- 第一次握手丢包:默认情况下,connect()是阻塞式的,如果请求无法发送到服务器,那么connect会进行一段很长时间的等待和重试(重传次数和时间间隔我们暂且不去深究),此时我们可以使用通过设置SO_SNDTIMEO来为connect设置超时以减少connect的等待时间
- 第二次握手丢包:对于客户来说,依然是connect超时,所以处理方式和第一次握手丢包是一样的。对于服务器来说,由于收不到第三次握手请求,所以会进行等待重传,直到多次重传失败后,关闭半连接。
- 这里需要提一下的是,服务器会维护一个半连接队列,用于等待客户的第三次握手请求。当收到第三次握手请求或者多次重传失败后,服务器会将该半连接从队列中删除。(这里暂且不去深究半连接队列的等待重新策略和配置)
- 我们经常听说的DDos攻击,就可以这个环节实现,syn flood就是一种常见的DDos攻击方式。简单来说,syn flood就是只发送第一次握手请求后,就关闭连接,将服务器的半连接队列占满,从而让正常用户无法得到服务。
- 第三次握手丢包:由于客户在发送第三次握手包后,不再等待确认,就直接进入了ESTABLISHED状态,所以一旦第三次握手失败,客户和服务器的状态就不同步了。当然,此时服务器会进行多次重发,一旦客户再次收到SYN+ACK(第二次握手请求),会再次确认。不过,如果第三次握手一直失败,则会出现,客户已经建立连接,而服务器关闭连接的情况。随后,一旦客户向服务器发送数据,则会收到一条RST回应,告诉用户连接已经重置,需要重新进行三次握手。
- RST和SIGPIPE:有过网络编程经验的人都知道在写网络通信的时候,需要屏蔽SIGPIPE信号,否则的话,一旦收到PIPE信号会导致程序异常退出。其实这个SIGPIPE就是由于write()的时候,我们自己的状态是ESTABLISHED而对方的状态不是ESTABLISHED,那么对方就会给我们一个RST回应,收到这个回应之后,系统就会自动生成一个PIPE信号。
四次握手概述:
- 客户发送FIN请求(第一次握手),通知关闭连接,然后进入FIN_WAIT1状态
- 服务器收到FIN请求后,发送ACK(第二次握手),对客户的FIN进行确认,然后进入CLOSE_WAIT状态
- 服务器进行一些收尾工作,然后主动相客户发送FIN请求(第三次握手),通知关闭连接,然后进入LAST_ACK状态
- 客户收到FIN,对FIN进行确认(第四次握手),并进入TIME_WAIT状态
- 服务器收到客户的确认,关闭连接
- 客户等待一段时间后,关闭连接
- 客户调用close()执行主动关闭,发送FIN到服务器,FIN表示不会再发送数据了
- 服务器收到FIN进行被动关闭,由TCP对FIN进行确认。FIN作为文件结束符,传递给recv()。因为收到FIN以后就意味着不会再有数据了
- 一段时间后,服务器调用close()关闭自己的socket,并发送FIN给客户,宣告自己不会再发送数据了
- 客户收到FIN后,不再确认,等待一段时间后,自行关闭自己的socket
- TCP是全双工的连接,所以关闭的过程必须是两个方向都关闭才行,这也就是为什么需要两次不同方向的FIN
- FIN并不像SYN一样,一定是一个独立的包,有时FIN会随着数据一起发送,而对方也有可能将ACK和FIN放在一个包中进行发送,这成为捎带。捎带的机制在数据传输中也会出现。
- 四次握手的过程不像三次握手一样,一定是由客户发起。虽然一般来说,是由客户发起,但是某些协议(例如HTTP)则是服务器执行主动关闭
两个WAIT:
- CLOSE_WAIT:CLOSE_WAIT的状态位于向对方确认FIN之后,向对方发送FIN之前,这段时间由于对方已经发送了FIN,也就表示不会再收到数据,但是这并不表示自己没有数据要发,毕竟只有在发送了FIN之后,才表示发送完毕。所以,CLOSE_WAIT这段时间主要的工作就是给对方发送必要的数据,对自己的数据进行收尾,所有工作结束之后,调用close(),发送FIN,等待LAST_ACK
- TIME_WAIT:存在TIME_WAIT状态有如下两个理由:
- 实现终止TCP全双工连接的可靠性:假如LAST-ACK丢失,对方重发,但是自己已经关闭连接,那么会返回一个RST包,对放会将其解释为错误,从而无法正常关闭。也就是说,TIME_WAIT的作用之一就是解决LAST-ACK可能丢包的情况,因为在有些网络不好的情况下,不得不重发LAST-ACK
- 允许老的网络分组在网络中消逝:2MSL的时间足够让所有的FIN数据在网络中消失,如果不等待,并立即开始一个新的连接,有可能出现老FIN关闭了新连接的情况,因为在IP和端口一直的情况下,很难区分一个数据包是属于哪一次连接的
四次握手的异常:
- 第一次握手丢包:FIN_WAIT1丢失会导致客户重传,如果多次重传失败,则客户超时关闭连接,而服务器依然保持ESTABLISHED状态。如果服务器主动发送数据,则会收到一个RST包,重置连接。设置KeepAlive道理相同,核心是要求服务器主动发数据。如果服务器永远不会主动发数据,那么就会一直保持这样一个“假连接”
- 第二次握手丢包:由于服务器第二次握手不会重发,所以即使丢包也不管,直接向对方发送FIN,此时客户执行”同时关闭“的流程(这个流程后面再说),等待TIME_WAIT时间后关闭。在客户进入TIME_WAIT之后,自己由于FIN没有相应,会重发,如果被客户TIME_WAIT收到并发送LAST-ACK,则流程正常结束,如果反复重发没有响应,那么超时关闭
- 第三次握手丢包:服务器会持续等待在LAST_ACK状态,而客户会持续等待在FIN_WAIT2状态,最后双方超时关闭
- 第四次握手丢包:客户端进入TIME_WAIT状态,等待2MSL,服务器由于收不到LAST-ACK则进行重发,如果多次重发失败,则超时关闭(这个流程和第二次握手丢包的后半段状态是一样的)
TCP的同时打开和同时关闭
主机a中一应用程序使用7777作为本地端口,并连接到主机b 8888端口做主动打开。
主机b中一应用程序使用8888作为本地端口,并连接到主机a 7777端口做主动打开。
tcp协议在遇到这种情况时,只会打开一条连接。
这个连接的建立过程需要4次数据交换,而一个典型的连接建立只需要3次交换(即3次握手)
但多数伯克利版的tcp/ip实现并不支持同时打开
同时关闭也需要有4次报文交换,与典型的关闭相同。
TCP通信中服务器处理客户端意外断开
如果TCP连接被对方正常关闭,也就是说,对方是正确地调用了closesocket(s)或者shutdown(s)的话,那么上面的Recv或Send调用就能马上返回,并且报错。这是由于close socket(s)或者shutdown(s)有个正常的关闭过程,会告诉对方“TCP连接已经关闭,你不需要再发送或者接受消息了”。
但是,如果意外断开,客户端(3g的移动设备)并没有正常关闭socket。双方并未按照协议上的四次挥手去断开连接。
那么这时候正在执行Recv或Send操作的一方就会因为没有任何连接中断的通知而一直等待下去,也就是会被长时间卡住。
像这种如果一方已经关闭或异常终止连接,而另一方却不知道,我们将这样的TCP连接称为半打开 的。
解决意外中断办法都是利用保活机制。而保活机制分又可以让底层实现也可自己实现。
1、 自己编写心跳包程序
简单的说也就是在自己的程序中加入一条线程,定时向对端发送数据包,查看是否有ACK,如果有则连接正常,没有的话则连接断开
2、 启动TCP编程里的keepAlive机制
一)双方拟定心跳(自实现)
一般由客户端发送心跳包,服务端并不回应心跳,只是定时轮询判断一下与上次的时间间隔是否超时(超时时间自己设定)。服务器并不主动发送是不想增添服务器的通信量,减少压力。
但这会出现三种情况:
情况1.
客户端由于某种网络延迟等原因很久后才发送心跳(它并没有断),这时服务器若利用自身设定的超时判断其已经断开,而后去关闭socket。若客户端有重连机制,则客户端会重新连接。若不确定这种方式是否关闭了原本正常的客户端,则在ShutDown的时候一定要选择send,表示关闭发送通道,服务器还可以接收一下,万一客户端正在发送比较重要的数据呢,是不?
情况2.
客户端很久没传心跳,确实是自身断掉了。在其重启之前,服务端已经判断出其超时,并主动close,则四次挥手成功交互。
情况3.
客户端很久没传心跳,确实是自身断掉了。在其重启之前,服务端的轮询还未判断出其超时,在未主动close的时候该客户端已经重新连接。
这时候若客户端断开的时候发送了FIN包,则服务端将会处于CLOSE_WAIT状态;
这时候若客户端断开的时候未发送FIN包,则服务端处还是显示ESTABLISHED状态;
而新连接上来的客户端(也就是刚才断掉的重新连上来了)在服务端肯定是ESTABLISHED;这时候就有个问题,若利用轮询还未检测出上条旧连接已经超时(这很正常,timer总有个间隔吧),而在这时,客户端又重复的上演情况3,那么服务端将会出现大量的假的ESTABLISHED连接和CLOSE_WAIT连接。
最终结果就是新的其他客户端无法连接上来,但是利用netstat还是能看到一条连接已经建立,并显示ESTABLISHED,但始终无法进入程序代码。个人最初感觉导致这种情况是因为假的ESTABLISHED连接和 CLOSE_WAIT连接会占用较大的系统资源,程序无法再次创建连接(因为每次我发现这个问题的时候我只连了10个左右客户端却已经有40多条无效连接)。而最近几天测试却发现有一次程序内只连接了2,3个设备,但是有8条左右的虚连接,此时已经连接不了新客户端了。这时候我就觉得我想错了,不可能这几条连接就占用了大量连接把,如果说几十条还有可能。但是能肯定的是,这个问题的产生绝对是设备在不停的重启,而服务器这边又是简单的轮询,并不能及时处理,暂时还未能解决。
二)利用KeepAlive
其实keepalive的原理就是TCP内嵌的一个心跳包,
以服务器端为例,如果当前 server 端检测到超过一定时间(默认是 7,200,000 milliseconds ,也就是 2 个小时)没有数据传输,那么会向 client 端发送一个 keep-alive packet (该 keep-alive packet 就是 ACK和 当前 TCP 序列号减一的组合),此时 client 端应该为以下三种情况之一:
1. client 端仍然存在,网络连接状况良好。此时 client 端会返回一个 ACK 。server 端接收到 ACK 后重置计时器(复位存活定时器),在 2 小时后再发送探测。如果 2 小时内连接上有数据传输,那么在该时间基础上向后推延 2 个小时。
2. 客户端异常关闭,或是网络断开。在这两种情况下, client 端都不会响应。服务器没有收到对其发出探测的响应,并且在一定时间(系统默认为 1000 ms )后重复发送 keep-alive packet ,并且重复发送一定次数( 2000 XP 2003 系统默认为 5 次 , Vista 后的系统默认为 10 次)。
3. 客户端曾经崩溃,但已经重启。这种情况下,服务器将会收到对其存活探测的响应,但该响应是一个复位,从而引起服务器对连接的终止。对于应用程序来说,2小时的空闲时间太长。因此,我们需要手工开启Keepalive功能并设置合理的Keepalive参数。
全局设置可更改 /etc/sysctl.conf ,加上:
net.ipv4.tcp_keepalive_intvl = 20
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_keepalive_time = 60
在程序中设置如下:
- #include <netinet/in.h>
- #include <arpa/inet.h>
- #include <sys/types.h>
- #include <netinet/tcp.h>
- int keepAlive = 1; // 开启keepalive属性
- int keepIdle = 60; // 如该连接在60秒内没有任何数据往来,则进行探测
- int keepInterval = 5; // 探测时发包的时间间隔为5 秒
- int keepCount = 3; // 探测尝试的次数.如果第1次探测包就收到响应了,则后2次的不再发.
- setsockopt(rs, SOL_SOCKET, SO_KEEPALIVE, (void *)&keepAlive, sizeof(keepAlive));
- setsockopt(rs, SOL_TCP, TCP_KEEPIDLE, (void*)&keepIdle, sizeof(keepIdle));
- setsockopt(rs, SOL_TCP, TCP_KEEPINTVL, (void *)&keepInterval, sizeof(keepInterval));
- setsockopt(rs, SOL_TCP, TCP_KEEPCNT, (void *)&keepCount, sizeof(keepCount));
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <sys/types.h>
#include <netinet/tcp.h>
int keepAlive = 1; // 开启keepalive属性
int keepIdle = 60; // 如该连接在60秒内没有任何数据往来,则进行探测
int keepInterval = 5; // 探测时发包的时间间隔为5 秒
int keepCount = 3; // 探测尝试的次数.如果第1次探测包就收到响应了,则后2次的不再发.
setsockopt(rs, SOL_SOCKET, SO_KEEPALIVE, (void *)&keepAlive, sizeof(keepAlive));
setsockopt(rs, SOL_TCP, TCP_KEEPIDLE, (void*)&keepIdle, sizeof(keepIdle));
setsockopt(rs, SOL_TCP, TCP_KEEPINTVL, (void *)&keepInterval, sizeof(keepInterval));
setsockopt(rs, SOL_TCP, TCP_KEEPCNT, (void *)&keepCount, sizeof(keepCount)); 在程序中表现为,当tcp检测到对端socket不再可用时(不能发出探测包,或探测包没有收到ACK的响应包),select会返回socket可读,并且在recv时返回-1,同时置上errno为ETIMEDOUT.
实际编程中,又一次发现终端作为客户端和服务器进行TCP连接时,需要建立4条,但有时建立4条,有时建立3条链路。最终原因是服务器在上层信令指示有终端要连接时,
才启动tcp服务端的监听,导致客户端发起连接时,服务端有可能还没完成监听,从而无法建立连接。另外sippipe信号一定要屏蔽,否则会导致程序崩溃。
优化Linux下的内核TCP参数以提高系统性能
内核的优化跟服务器的优化一样,应本着稳定安全的原则。下面以Squid服务器为例来说明,待客户端与服务器端建立TCP/IP连接后就会关闭Socket,服务器端连接的端口状态也就变为TIME_WAIT了。那是不是所有执行主动关闭的Socket都会进入TIME_WAIT状态呢?有没有什么情况可使主动关闭的Socket直接进入CLOSED状态呢?答案是主动关闭的一方在发送最后一个ACK后就会进入TIME_WAIT状态,并停留2MSL(报文最大生存)时间,这是TCP/IP必不可少的,也就是说这一点是“解决”不了的。
TCP/IP设计者如此设计,主要原因有两个:
防止上一次连接中的包迷路后重新出现,影响新的连接(经过2MSL时间后,上一次连接中所有重复的包都会消失)。
为了可靠地关闭TCP连接。主动关闭方发送的最后一个ACK(FIN)有可能会丢失,如果丢失,被动方会重新发送FIN,这时如果主动方处于 CLOSED状态,就会响应 RST而不是ACK。所以主动方要处于TIME_WAIT状态,而不能是CLOSED状态。另外,TIME_WAIT 并不会占用很大的资源,除非受到攻击。
在Squid服务器中可输入如下命令查看当前连接统计数:
netstat -n | awk'/^tcp/ {++S[$NF]} END{for(a in S) print a, S[a]}'
命令显示结果如下所示:
LAST_ACK 14
SYN_RECV 348
ESTABLISHED 70
FIN_WAIT1 229
FIN_WAIT2 30
CLOSING 33
TIME_WAIT 18122
命令中的含义分别如下。
CLOSED:无活动的或正在进行的连接。
LISTEN:服务器正在等待进入呼叫。
SYN_RECV:一个连接请求已经到达,等待确认。
SYN_SENT:应用已经开始,打开一个连接。
ESTABLISHED:正常数据传输状态。
FIN_WAIT1:应用说它已经完成。
FIN_WAIT2:另一边已同意释放。
ITMED_WAIT:等待所有分组死掉。
CLOSING:两边尝试同时关闭。
TIME_WAIT:另一边已初始化一个释放。
LAST_ACK:等待所有分组死掉。
也就是说,这条命令可以把当前系统的网络连接状态分类汇总。
在Linux下高并发的Squid服务器中,TCP TIME_WAIT套接字的数量经常可达到两三万,服务器很容易就会被拖死。不过,可以通过修改Linux内核参数来减少Squid服务器的TIME_WAIT套接字数量,命令如下:
vim/etc/sysctl.conf
然后,增加以下参数:
net.ipv4.tcp_fin_timeout= 30
net.ipv4.tcp_keepalive_time= 1200
net.ipv4.tcp_syncookies= 1
net.ipv4.tcp_tw_reuse= 1
net.ipv4.tcp_tw_recycle= 1
net.ipv4.ip_local_port_range= 10000 65000
net.ipv4.tcp_max_syn_backlog= 8192
net.ipv4.tcp_max_tw_buckets= 5000
以下将简单说明上面各个参数的含义:
net.ipv4.tcp_syncookies=1表示开启SYN Cookies。当出现SYN等待队列溢出时,启用Cookie来处理,可防范少量的SYN攻击。该参数默认为0,表示关闭。
net.ipv4.tcp_tw_reuse=1表示开启重用,即允许将TIME-WAIT套接字重新用于新的TCP连接。该参数默认为0,表示关闭。
net.ipv4.tcp_tw_recycle=1表示开启TCP连接中TIME-WAIT套接字的快速回收,该参数默认为0,表示关闭。
net.ipv4.tcp_fin_timeout=30表示如果套接字由本端要求关闭,那么这个参数将决定它保持在FIN-WAIT-2状态的时间。
net.ipv4.tcp_keepalive_time=1200表示当Keepalived启用时,TCP发送Keepalived消息的频度改为20分钟,默认值是2小时。
net.ipv4.ip_local_port_range=10 000 65 000表示CentOS系统向外连接的端口范围。其默认值很小,这里改为10 000到65 000。建议不要将这里的最低值设得太低,否则可能会占用正常的端口。
net.ipv4.tcp_max_syn_backlog=8192表示SYN队列的长度,默认值为1024,此处加大队列长度为8192,可以容纳更多等待连接的网络连接数。
net.ipv4.tcp_max_tw_buckets=5000表示系统同时保持TIME_WAIT套接字的最大数量,如果超过这个数字,TIME_WAIT套接字将立刻被清除并打印警告信息,默认值为180 000,此处改为5000。对于Apache、Nginx等服务器,前面介绍的几个参数已经可以很好地减少TIME_WAIT套接字的数量,但是对于Squid来说,效果却不大,有了此参数就可以控制TIME_WAIT套接字的最大数量,避免Squid服务器被大量的TIME_WAIT套接字拖死。
执行以下命令使内核配置立马生效:
/sbin/sysctl –p
如果是用于Apache或Nginx等Web服务器,则只需要更改以下几项即可:
net.ipv4.tcp_syncookies=1
net.ipv4.tcp_tw_reuse=1
net.ipv4.tcp_tw_recycle= 1
net.ipv4.ip_local_port_range= 10000 65000
执行以下命令使内核配置立马生效:
/sbin/sysctl –p
如果是Postfix邮件服务器,则建议内核优化方案如下:
net.ipv4.tcp_fin_timeout= 30
net.ipv4.tcp_keepalive_time= 300
net.ipv4.tcp_tw_reuse= 1
net.ipv4.tcp_tw_recycle= 1
net.ipv4.ip_local_port_range= 10000 65000
kernel.shmmax =134217728
执行以下命令使内核配置立马生效:
/sbin/sysctl –p
当然这些都只是最基本的更改,大家还可以根据自己的需求来更改内核的设置,比如我们的线上机器在高并发的情况下,经常会出现“TCP: too many orpharned sockets”的报错尽量也要本着服务器稳定的最高原则。如果服务器不稳定的话,一切工作和努力就都会白费。如果以上优化仍无法满足工作要求,则有可能需要定制你的服务器内核或升级服务器硬件。
参考:
http://blog.csdn.net/bzfys/article/details/73733917
http://blog.csdn.net/bzfys/article/details/73733953















 222
222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









