






前言
- 攻击互操作性(Attacking Interoperability)是 Mark & Ryan & David 发表于 2009 年的美国黑帽大会(Black Hat)上的一份研究报告,主要研究并深度探讨了关于 COM 对象的软件互操作层的安全隐患,并以实际的例子诠释互操作性攻击。Haifei Li 和 Bing Sun 在 2015 年美国黑帽大会的演讲 PPT 中也提到过此研究报告的伟大性工作,并在此基础上开展了对 OLE 嵌入式对象的研究。鉴于此报告具有一定的研究价值,故对此报告进行了翻译。以下是友情链接:
- Haifei Li & Bing Sun in Black Hat 2015 PPT:https://www.blackhat.com/docs/us-15/materials/us-15-Li-Attacking-Interoperability-An-OLE-Edition.pdf
- 攻击互通性 - 以 OLE 为例(看雪 银雁冰):https://bbs.pediy.com/thread-218941.htm
- Attacking Interoperability 研究报告原文地址:http://hustlelabs.com/stuff/bh2009_dowd_smith_dewey.pdf


内容介绍
- 近年来,客户端应用程序增加了定制的动态内容的驱动力。传统上,这个目标是通过将布局指令与脚本功能相结合的方式来实现的,脚本功能可以提供数据并以编程方式修改布局(例如 HTML 和 JavaScript)。此模型已经发展到允许嵌入对象,扩展布局属性和脚本引擎(包括在嵌入对象中使用的那些,如 Adobe 的 ActionScript)之间更精细的协作。这种新的互操作性浪潮有助于创建跨越多种技术的无缝用户体验。
- 本文旨在探讨软件互操作性层的安全隐患,特别关注几种突出的 Web 浏览器技术。我们将揭示大量未经探索的攻击面,这些攻击面是允许这种互操作性的直接结果,并讨论了可能存在于其中的独特类型的漏洞。此外,我们将探讨互操作性对主机应用程序中实现的安全功能的影响。具体来说,我们将演示这些安全功能如何经常被可插拔组件破坏,这是信任扩展到所述组件的直接结果。虽然本文主要关注当代 Web 浏览器中存在的几个互操作性层,但很多关于漏洞类和审计策略的讨论可以应用于执行某种组件间数据交换的广泛软件。此类软件的一些示例包括其他脚本语言和插件体系结构,RPC 堆栈和虚拟机。
本文的组织
- 本文分为三个部分。 首先,本文将在第1节中详细介绍攻击面的简要介绍。具体来说,将检查通用浏览器体系结构,并突出显示与攻击互操作性相关的组件。 本文的第二部分将提供技术概述,提供互操作性如何在两个流行的浏览器中工作的背景信息:Microsoft Internet Explorer(IE)和 Mozilla Firefox。 最后,第 3 节将致力于列举已识别的攻击面中出现的漏洞类别,并展示揭示这些类型问题的实用策略。 在最后一节中,将对作者发现的一些重要的现实漏洞进行检查。
第一节:攻击面
- 在深入讨论目标软件层之前,从概念层面了解攻击面是非常重要重要的。当代 Web 浏览器的高级架构如图1所示,其中包含与本白皮书相关的组件细分 。
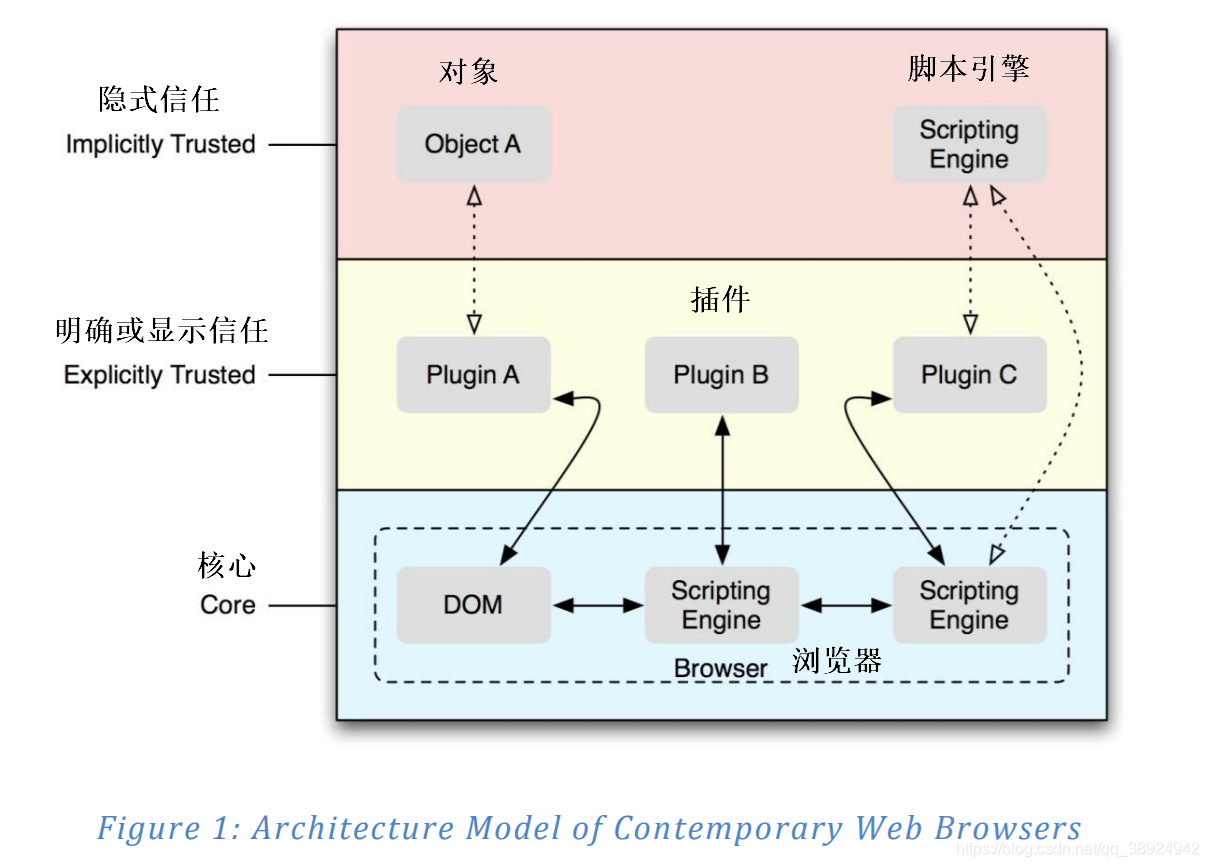
- 图1分为三个逻辑层。 第一层是浏览器核心,它包含几个组件,这些组件为插件提供了与浏览器交互的环境。首先,插件是通过脚本控制的,但在某些情况下,它们也可以直接与浏览器的文档对象模型(DOM)交互。
- 第二层代表插件本身,它们本质上是浏览器加载的对象,主要通过处理唯一的文档类型来支持其他功能。浏览器策略在浏览器环境中明确授予或拒绝信任插件; 但是它们有时会在浏览器的单独进程上下文中运行。例如,Internet Explorer 8(IE8)浏览器在 Windows Vista 或 Windows 7 上运行时在限制性“低完整性”上下文中运行,而在限制较少的“中等完整性”上下文中,多个插件会耗尽进程。此策略允许插件在浏览器中保持完全信任,但对操作系统的上下文具有较少的信任。
- 最后,存在第三层隐式受信任对象,这些对象可以加载可加载的对象以增强其自身的功能。由于浏览器显式地将信任扩展到插件(插件 X),并且插件将信任扩展到任意对象(对象 Y),因此我们可以说在浏览器和由任意对象加载的任意对象之间建立了可传递的信任关系。插件(B -> X,X -> Y ,因此 B - > Y)。我们将在本文的第二部分中展示示例,这种信任的扩展允许攻击者利用插件及其可信组件来破坏浏览器安全模型。第三层的另一个值得注意的部分是一些插件创建自己的脚本功能,在许多情况下可以用来与浏览器提供的脚本引擎或 DOM 进行交互。实际上,这种情况就是许多流行插件的情况,包括 Adobe Flash,Sun Java 和 Microsoft Silverlight 。在每种情况下,隐式地从浏览器扩展信任以允许攻击者获得对每种脚本语言提供的功能的访问。此外,可以将对象从这些脚本语言导出回浏览器中的脚本上下文。由于信任传递性,这些对象可能不仅被浏览器脚本引擎操纵,而且还被 DOM 函数和其他插件操纵,有时会产生非常意想不到的后果。
- 信任扩展不是互操作性的唯一安全成本。 从图1中可以看出,为了使每个附加组件相互交互,必须在互操作组件之间建立通信桥。这在图1中用双向箭头表示。这些通信桥本身就是一个相当大的攻击面:它是负责将数据从一个组件编组到下一个组件的代码。编组层在协作组件本机的数据结构之间隐式执行转换。由于该层在某种程度上无声地运行,因此在尝试发现安全漏洞时经常会被忽略。实际上,目前有大量文献专门用于评估浏览器中的插件对象是否存在安全问题(具有实际结果),但很少有关于检查互操作性层的信息。缺乏审查是本文试图解决的一个领域。
- 互操作性层是各种独特漏洞类别的温床,这些漏洞类别以前基本上未被探索过。由于正在执行的操作,编组基础设施通常会导致与类型混淆(由于对其类型的误解而误用数据)和对象保留(虚假引用计数问题)相关的漏洞,这些问题很少见于其他领域。一个应用程序。虽然过去偶尔会发现这些漏洞,但我们将展示目标软件中流行的 API 如何特别容易受到攻击,并将在本文第二部分提供揭示这些类型漏洞的策略。应该注意的是,虽然本文中提到的体系结构是以 Web 浏览器为中心的,但是这些类型的问题在任何软件中都是系统性的,这些软件为具有不同内部数据表示的组件之间的协作提供平台。
第二节:技术概述
- 本节概述了将用作案例研究的相关技术,以说明本文以下部分“攻击互操作性”中提出的概念。我们讨论了 Internet Explorer 的 ActiveX 控件架构,以及 Mozilla 的 NPAPI 插件架构(存在于 Firefox,Google Chrome 和其他一些非浏览器应用程序中)。我们将探讨如何在可用的通用脚本语言中表示对象,如何对它们进行编组并将其导出到插件入口点,以及如何进行 DOM 交互。 最后,我们将为 ActiveX 和 NPAPI 提供攻击面摘要,总结每种技术在所述攻击面的上下文中将扮演的角色。
2.1 微软 ActiveX 插件
- ActiveX 是一种源自微软 COM 技术的技术。它用于创建可以暴露给运行时引擎(例如 JavaScript 和 VBScript)的插件,以便为宿主应用程序提供额外的功能。了解本文第三部分将探讨的漏洞类型需要深入了解一些 COM / Automation 架构。因此,我们将在本节中概述相关技术。我们还将探索“持久对象”的概念,它是序列化的 COM 对象,可以选择嵌入到网页中。第三部分将介绍如何使用持久 COM 对象不仅可以定位各种 COM 编组组件中的漏洞,还可以在某些情况下破坏浏览器安全功能。
2.1.1 插件注册
- ActiveX 控件是 COM 对象的特化,因此在系统注册表中有一个描述相关实例化信息的条目。与任何其他 COM 对象一样,每个 ActiveX 对象都由全局唯一的类 ID(CLSID)标识,并位于 HKEY_CLASSES_ROOT\CLSID{} 的注册表中。也可以使用注册表的 HKEY_CURRENT_USER 部分基于每个用户安装对象。由于 COM 对象在整个 Windows 操作系统中如此普遍使用,因此 Internet Explorer(IE)需要一种限制允许通过 Web 浏览器启动哪些 COM 对象的方法。随着时间的推移,安全机制的语义逐渐变得更加细化,这里将简要描述。
2.1.1.1 ActiveX 插件之安全控制技术
- IE 有几种机制来确定 ActiveX 对象是否具有运行权限。控件的安全权限分为两类:初始化和脚本。初始化安全性是指是否允许基于来自持久 COM 流的数据来实例化控件(稍后将深入讨论)。脚本安全性是指是否可以通过在运行时公开的脚本 API 来操纵控件。 有关 ActiveX 安全控件的完整概述,请访问 Microsoft,网址为 http://msdn.microsoft.com/en-us/library/bb250471(VS.85).aspx ,本节中的大部分逆向工程信息都来源于这里。
a) 通过注册表进行安全控制
- 将控件标记为安全脚本(SFS)或安全初始化(SFI)的第一个也是最常见的方法是在注册表中为控件条目下添加特定子键。可以在 “Implemented Categories” 子项下添加两个值,分别标记控件 SFS 和 SFI 。这些值分别为
7DD95801-9882-11CF-9FA9-00AA006C42C4(CATID_SafeForScripting)和7DD95802- 9882-11CF-9FA9 00AA006C42C4(CATID_SafeForInitialization)。图2显示了使用这些类别的控件示例: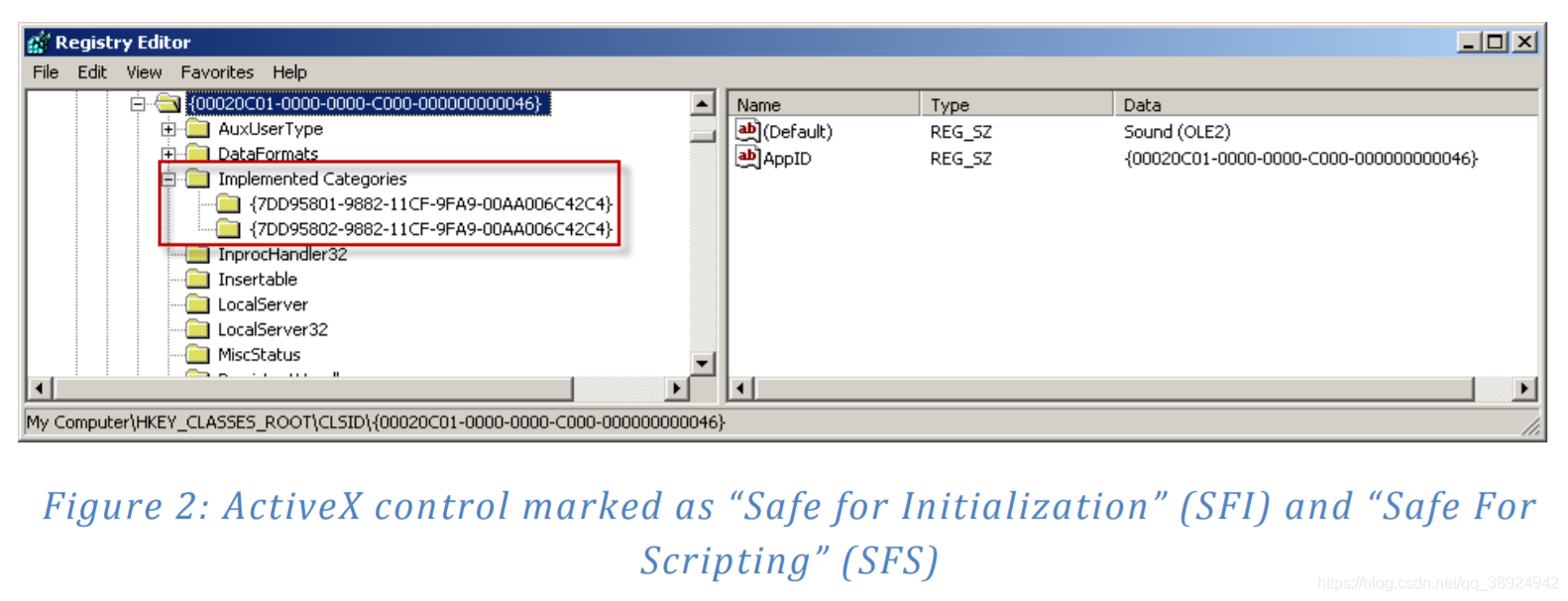
- 控件可以使用 StdComponentCategoriesMgr 对象以编程方式为这些类别注册自己。ICatRegister 接口包含 RegisterClassImplCategories() 方法,该方法可用于处理任何给定 COM 对象的类别注册信息。在内部,StdComponentCategoriesMgr 使用上述信息更新注册表。
- Internet Explorer 也使用 StdComponentCategoriesMgr 对象,但是用于枚举而不是注册。ICatInformation 接口提供了一个名为 IsClassOfCategories() 的函数,IE 可以调用该函数来确定控件是 SFS 还是 SFI 。同样,此操作在内部查询上述注册表位置以确定对象实现的控件。
b) 通过 IObjectSafety 接口进行安全控制
- 存在将控件标记为 SFS 或 SFI 的替代方法。ActiveX 控件可以通过实现 IObjectSafety 接口为这些安全限制提供支持。在这种情况下,可以通过调用 IObjectSafety::GetInterfaceSafetyOptions() 方法获得控件的安全功能,该方法具有以下原型:
HRESULT IObjectSafety::GetInterfaceSafetyOptions(
REFIID riid,
DWORD *pdwSupportedOptions,
DWORD *pdwEnabledOptions
);
- IE 将调用此函数以确定支持的安全选项集。如果界面似乎支持安全选项,则 IE 将使用它希望对象强制执行的选项调用 IObjectSafety 接口的 SetInterfaceSafetyOptions() 方法。SetInterfaceSafetyOptions 具有以下原型:
HRESULT IObjectSafety::SetInterfaceSafetyOptions(
REFIID riid,
DWORD dwOptionSetMask,
DWORD dwEnabledOptions
);
- 如果 SetInterfaceSafetyOptions() 成功返回,则应用程序可以使用 COM 对象,知道该对象打算使用所请求的安全选项。此 API 在 COM 类别上的附加值是控件可以提供更精细的控制方式,因为它可以根据在 riid 参数中指定的接口 ID 为不同的接口指定不同的安全设置以及方法调用。此外,IObjectSafety 接口可以执行本机代码,以确定创建对象的应用程序是否可以安全地执行此操作。此类功能的一个具体示例是 Microsoft 提供的 SiteLock 模板代码。此模板代码允许程序员将 ActiveX 控件限制为预定的 URL 列表。
c) 通过 ActiveX 中的 Killbits 值进行安全控制
- IE 还实现了对标准安全功能的覆盖,允许管理员专门禁止在浏览器中实例化所选控件。这是通过在
HKEY_LOCAL_MACHINE\Software\Microsoft\Internet Explorer\ActiveX Compatibility注册表位置添加一个子项来实现的。添加的子项必须具有相关控件的 CLSID,并包含 DWORD 值 “Compatibility Flags”,其中设置了 “killbit”(值0x400)。图3显示了使用 killbit 集的控件示例: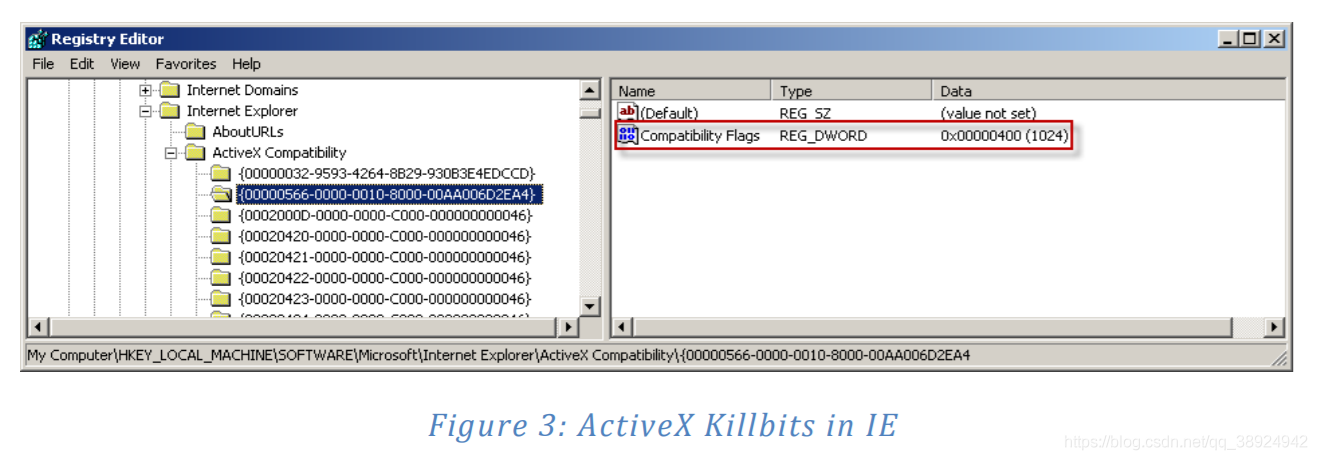
- 当应用程序希望确定是否设置了 killbit 时,它将调用 CompatFlagsFromClsid() 函数,该函数从 urlmon.dll 导出。 CompatFlagsFromClsid() 具有以下原型:
HRESULTCompatFlagsFromClsid(
CLSID *pclsid,
LPDWORD pdwCompatFlags,
LPDWORD pdwMiscStatusFlags
);
- 当应用程序调用此函数时,它将传入它感兴趣的 COM 对象的 CLSID,以及两个 DWORD 指针,其值将等于成功返回函数时对象的兼容性和其他 OLE 标志。然后,应用程序将测试是否设置 0x400 位以确定控件是否具有 killbit 设置。
- 如果设置了 Killbit,则注册表中可能会出现一个条目,表示备用类 ID。此替代类 ID 将用于代替 Internet Explorer 中的原始类 ID。图4显示了使用备用类 ID 的类 ID 的注册表项。处理图4中的控件时,Internet Explorer 将透明地将类 ID 为
{41B23C28-488E-4E5C-ACE2-BB0BBABE99E8}的 COM 对象的请求转换为类 ID{52A2AAAE-085D-4187-97EA-8C30DB990436}。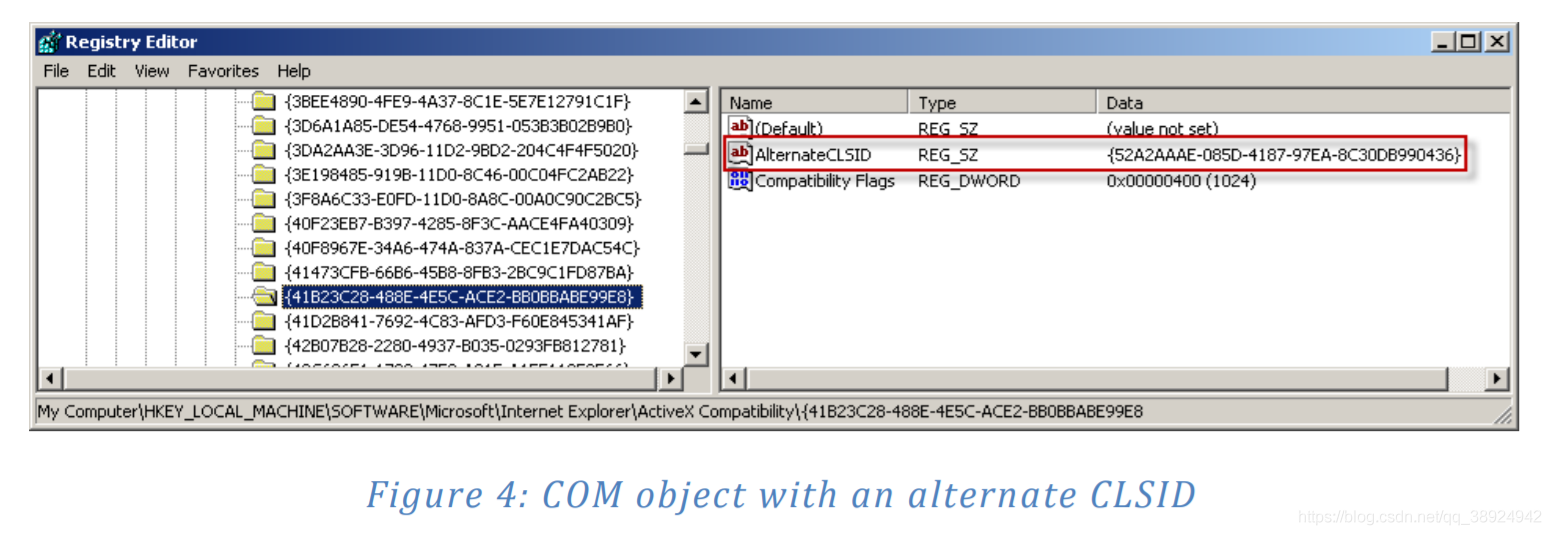
d) 通过 Preapproved List 或 ActiveX Opt-In 选择性的添加控件
- Microsoft 在 Internet Explorer 7 中引入了一项名为 ActiveX Opt-In 的功能。ActiveX Opt-In 旨在通过在允许网页实例化以前未在 Internet Explorer 中加载的对象或用户未通过 Internet Explorer 安装的对象之前提示用户来减少浏览器的攻击面。图5显示了注册表的相关区域:
HKEY_LOCAL_MACHINE\Software\Microsoft\Windows\CurrentVersion\Ext\PreApproved。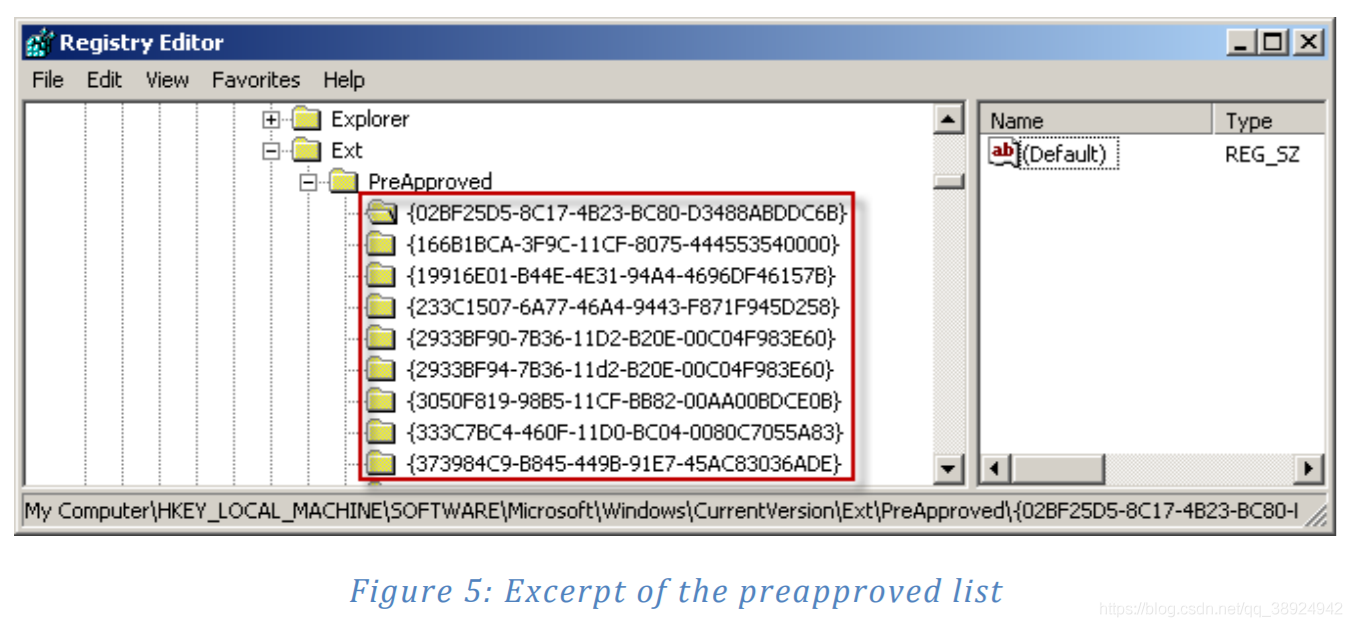
- 在 Windows 的基本安装中,预先批准的列表上已有许多控件。但是,有更多的安全脚本或初始化的控件没有出现在此列表中。此功能使得更有可能在此列表中找到控件中的缺陷,而不是其他控件中的缺陷。
e) 通过 ActiveX Per - User 将 Killbits 扩展为域控制
- IE8 引入了一系列与安全浏览相关的附加安全功能,包括对 ActiveX 的一些改进。在添加这些功能之前,可以在每台计算机上配置可配置的控制权限。新功能将每台机器的 killbit 扩展到每用户级别的粒度,并通过允许基于用户和域的 Opt-In 功能扩展 ActiveX opt-in。
- 传统上,killbits 已被用于有效地禁止整个控制系统的实例化。在许多用户的系统上的单个用户需要使用特定控件但没有其他人需要它的情况下,此模型存在问题。微软通过引入,扩展了 killbits 注册表项
HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Ext\Settings\{CLSID},其中 CLSID 是要限制的 ActiveX 控件的类 ID。通过将此键的 Flags 值设置为 “1”,将限制单个用户的控件。图6显示了在注册表的这个区域中禁用的表格数据控件: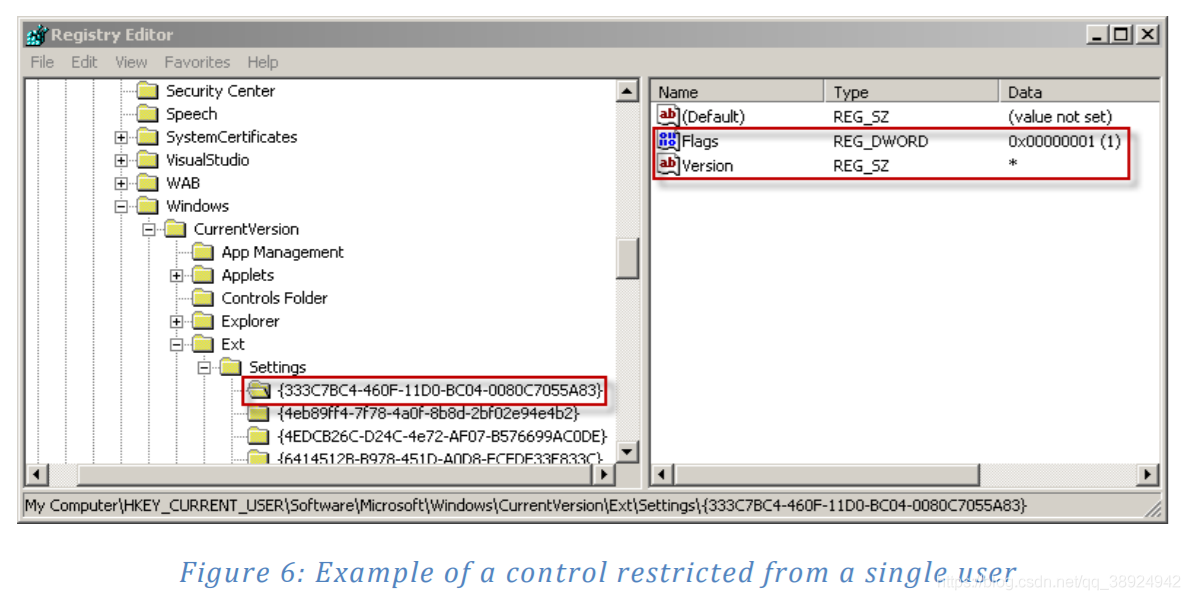
- 将 ActiveX 控件限制到某些域允许用户对 ActiveX 安全性进行更精细的控制。最初,SiteLock 是唯一允许域限制的方法,最终用户无法对其进行配置。通过将特定允许域的密钥添加到
HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Ext\Stats\{CLSID}\iexplore\Allowe dDomains,可以在注册表中管理此新的每域限制。可以使用名称 “*” 在此处添加所有域的密钥,而不是特定域。 - 每个域选择加入控件通过要求用户在不熟悉的域的上下文中运行之前批准使用 ActiveX 控件来减少攻击面。实际上,这需要攻击者将恶意 Web 内容插入受信任的域,以便偷偷地利用 ActiveX 控件。图7显示了配置为在
microsoft.com域内运行而没有提示的表格数据控件:
f) 基于 IE 图形界面设置安全控制
- 除了提供限制功能外,Microsoft 还通过添加一个界面来增强Internet Explorer UI,该界面允许用户轻松配置ActiveX 控件权限,而无需修改注册表。图8显示了如何访问 Add-on Manager 界面,图9显示了如何在未经许可的情况下查找允许在浏览器中运行的 DLL:
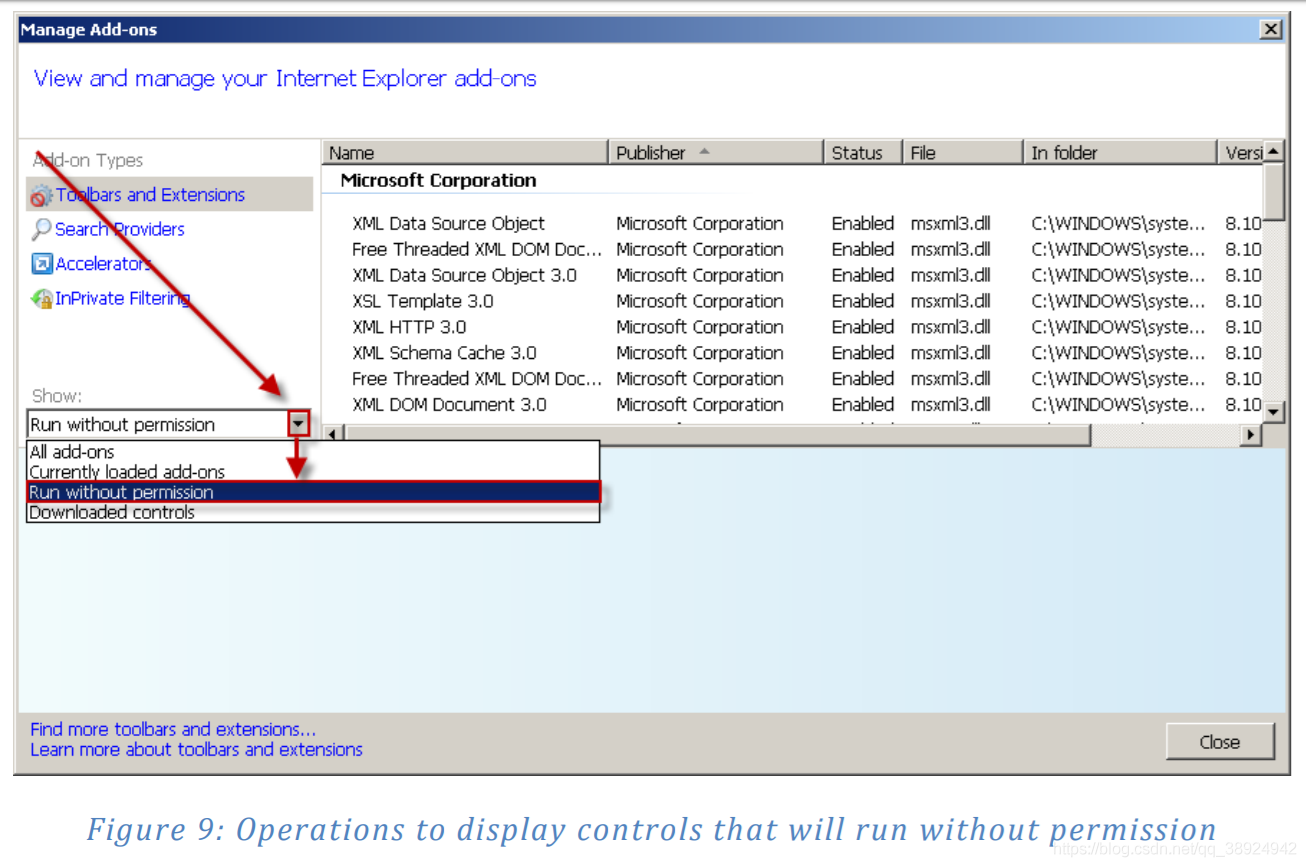
g) ActiveX Safety Wrap-Up
- ActiveX 有许多方法可以限制哪些控件可以加载,以及如何在给定的上下文中对它们执行操作。一个原因很可能是,随着应用程序的互操作性增加,攻击者也有机会。在这个前提下,ActiveX 安全性以攻击 - 响应的方式发展,并导致安全体系结构有些破碎。在后面的部分中,我们将展示允许绕过这些限制的攻击,主要是因为 Microsoft 以特殊方式向浏览器添加安全功能,而不是从一开始就建立了强大的安全架构。
2.1.2 COM 概述
- COM 是一种架构标准,它要求对象的语言无关表示,并促进这些对象之间的交互。Microsoft 使用 COM 作为其许多主要技术的基本构建块。它在旗舰 Windows 操作系统中非常普遍,并且还被许多其他外围产品广泛使用,例如 Internet Explorer 和 Office。在标题为 Variants 的第一部分中,我们将讨论 COM 用于通信的基本的,语言不可知的数据类型以及用于操作它们的 API。将探索 variant,以便为读者提供本文所关注的漏洞类型的更多背景信息。以下 variant 是一个名为 COM Automation 的部分,它讨论了可以很容易地暴露给脚本运行时环境的 COM 对象子集,统称为 ActiveX 控件。最后,在标题为 COM 持久性概述的部分中,我们将讨论持久性的概念 - 序列化 COM 对象的当前状态并随后在以后复活该对象的能力。将在潜在的恶意环境中探索持久性的使用,其中序列化对象可能源自不受信任的源(例如恶意网页或办公文档)。
2.1.2.1 Variants 数据结构
- VARIANTS 是整个 Windows 平台中用于以标准化格式表示任意数据类型的关键数据结构之一。特别是,它们是 COM 的组成部分,用于在两个或多个通信对象之间交换数据。VARIANT 数据结构相对简单 - 它由类型和值组成,并在 Windows SDK 中的 OAIdl.h 中定义,如下所示:
struct __tagVARIANT
{
VARTYPE vt;
WORD wReserved1;
WORD wReserved2;
WORD wReserved3;
union
{
BYTE bVal;
SHORT iVal;
FLOAT fltVal;
DOUBLE dblVal;
VARIANT_BOOL boolVal;
… more elements …
BSTR bstrVal;
IUnknown *punkVal;
IDispatch *pdispVal;
SAFEARRAY *parray;
VARIANT_BOOL *pboolVal;
_VARIANT_BOOL *pbool;
SCODE *pscode;
CY *pcyVal;
DATE *pdate;
BSTR *pbstrVal;
VARIANT *pvarVal;
PVOID byref;
} __VARIANT_NAME_1;
} ;
- VARIANT 包含的值可以是各种不同类型之一,因此只有在 vt 成员给定上下文时才有意义,这表示类型。 VARIANT 可以表示相当多的基本类型。一些较常见的如表10所示:
- 从表10中可以看出,除了各种 COM 接口类型(如 IUnknown 和 IDispatch 接口)之外,所有基本数据类型都可以表示为 variant 。此外,通过使用 IRecordInfo COM 接口支持用户定义的类型。此接口提供定义自定义对象大小和 marshallers 的函数,以便可以表示任意数据结构。列出的类型仅是所有受支持的 VARIANT 类型的子集。可以在 Windows SDK 中的 wtypes.h 中找到所有可用类型的完整列表。
- 除了基本 variant 类型之外,还有几个修饰符,当与基本类型结合使用时,会更改
__VARIANT_NAME_1联合中包含的内容的含义。修饰符不能单独使用; 它们专门为基本类型提供附加上下文。它们通过将修饰符值(或多个值)与基本类型的值组合使用。表11总结了它们各自的含义:
- 从表中可以看出,基本类型都低于 0x0FFF,修饰符是大于 0x0FFF 的单比特值。因此,通过使用简单的位掩码操作使用修饰符扩充基本类型,形成了新的复杂类型。例如,包含字符串数组的 VARIANT 将具有类型 VT_ARRAY | VT_BSTR,值成员将指向 SAFEARRAY,其中每个成员都是 BSTR。(稍后将更深入地检查SAFEARRAY)VARIANT 可以通过具有类型 VT_BYREF | VT_I4 来表示指向有符号整数的指针 VT_BYREF 修饰符也可以与其他修饰符一起使用,因此 VARIANT 可以具有类型(VT_BYREF | VT_ARRAY |VT_BSTR)。在这种情况下,value 成员将指向 SAFEARRAY 指针,其成员都是 BSTR 类型。
a) Safe Arrays 类型
- 数组是 COM 使用的常见数据结构,存在于包含 vt 字段中的 VT_ARRAY 修饰符的 VARIANT 中。在这种情况下,SAFEARRAY 用于封装相同数据类型的一系列元素,并且可以通过 SafeArray API 进行操作,以安全地访问阵列成员,而无需担心与阵列访问相关的边界和其他管理问题。尽管它们最常用于表示仅具有单个维度的阵列,但 SAFEARRAY 也能够表示具有可能不同尺寸大小的多维阵列(通常称为“锯齿状阵列”)。SAFEARRAY 结构定义在 Windows SDK 的 OAIdl.h 中定义,如下所示:
typedef struct tagSAFEARRAY
{
USHORT cDims;
USHORT fFeatures;
ULONG cbElements;
ULONG cLocks;
PVOID pvData;
SAFEARRAYBOUND rgsabound[ 1 ];
} SAFEARRAY;
- SAFEARRAY 中包含的元素大小为 cbElements,并且连续存储在内存区域中,由 pvData 成员指向。 SAFEARRAYBOUND 结构数组跟在内存中的 SAFEARRAY 描述符之后,每个 SAFEARRAYBOUND 结构描述数组的单个维度。SAFEARRAYBOUND 结构构造如下:
typedef struct tagSAFEARRAYBOUND
{
ULONG cElements;
LONG lLbound;
} SAFEARRAYBOUND;
- 简单地说,lLbound 成员指示所描述维度的下限,cElements 成员指示该维度中存在多少成员。
- SAFEARRAY API 相对广泛,因此我们将考虑操作这些结构所需的最常见的API函数。前两个函数用于初始化和销毁,并且是彼此的补充:
(1) SAFEARRAY *SafeArrayCreate(VARTYPE vt, UINT cDims, SAFEARRAYBOUND *rgsabound);
(2) HRESULT SafeArrayDestroy(SAFEARRAY * psa);
- 这些函数分别用于创建和销毁数组。创建数组时,将指定每个数组成员的数据类型,以及数组的维数。这些属性都是不可变的; 创建后无法修改 SAFEARRAY 的类型和维数。
- 有两种不同的方式来访问数组中的数据。第一种方法是获取指向所有元素所在的内存的指针,并使用以下函数完成:
(1) HRESULT SafeArrayAccessData(SAFEARRAY * psa, void HUGEP** ppvData);
(2) HRESULT SafeArrayUnaccessData(SAFEARRAY * psa);
- 当访问循环中的元素时,这通常是首选方法,格式如下:
BSTR*pString;
if(FAILED(SafeArrayAccessData(psa, &pString))
return -1;
for(i = 0; i < psa->rgsabound[0].cElements; i++)
{
… operate on string …
}
SafeArrayUnaccessData(psa);
- 访问数据的第二种方法是使用以下函数访问单个元素:
(1) SafeArrayGetElement(SAFEARRAY * psa, LONG * rgIndices, void * pv);
(2) SafeArrayPutElement(SAFEARRAY * psa, LONG * rgIndices, void * pv);
- 这些函数中的每一个都采用一系列索引,并将返回或存储有问题的特定值。请注意,在内部,两个函数都验证提供的索引的有效性,以确保每个数组访问都在边界内。
- 最后,我们应该提到 SAFEARRAY 具有锁定机制以确保对阵列数据的独占线程访问,由以下两个函数访问:
(1) HRESULT SafeArrayLock(SAFEARRAY * psa);
(2) HRESULT SafeArrayUnlock(SAFEARRAY * psa);
b) VARIANT 和 VARIANTARG 类型
- 许多 VARIANT API 函数采用 VARIANT 或 VARIANTARG。Microsoft 文档表明,这两个值之间的区别在于 VARIANT 总是包含直接值(即,它们不能具有修饰符 VT_BYREF),而 VARIANTARG 可以。实际上,您将在 VARIANT API 的讨论中进一步注意到大多数 Variant * 函数都采用 VARIANTARG。实际上,尽管文档另有说明,但这些结构实际上是等效的并且可以互换使用。此外,使用它们时不会生成编译器错误(有关其所谓区别的 Microsoft 文档,请访问 http://msdn.microsoft.com/en-us/library/ms221627.aspx )。
c) VARIANT API 函数
- 用于操作 VARIANT 的 API 非常广泛,但是只有少数功能与本文的目的相关,本节将对它们进行讨论。
c - 1) Variant 的初始化和销毁
- 使用 VariantInit() 函数初始化 VARIANT,该函数具有以下原型:
HRESULTVariantInit(VARIANTARG *pvarg);
- 除了将 VARIANT 的类型成员 vt 设置为 VT_EMPTY 之外,此函数不执行任何操作,指示 VARIANT 不保留任何值。 稍后使用互易函数 VariantClear() 清理 VARIANT :
HRESULTVariantClear(VARIANTARG *pvarg);
- VariantClear() 函数还将清除 vt 成员,以及释放与VARIANT相关的任何数据。例如,如果 VARIANT 包含 IDispatch 或 IUnknown 接口(分别键入 VT_DISPATCH 或 VT_UNKNOWN),则 VariantClear() 将释放该接口。如果 VARIANT 是一个字符串(VT_BSTR),它将被取消分配,依此类推。
c - 2) 操纵 Variant
- 可以使用 API 在 VARIANT 上执行的两种主要操作类型是转换和复制。VarXXFromYY() 形式有多种特定的转换函数,其中 XX 是目标 VARIANT 类型,YY 是源类型。还有用于在任何两种 VARIANT 类型之间进行转换的通用函数,如下所示。
(1) HRESULT VariantChangeType(VARIANTARG *pvargDest, VARIANTARG *pvargSrc, unsigned short wFlags, VARTYPE vt);
(2) HRESULT VariantChangeTypeEx(VARIANTARG *pvargDest, VARIANTARG *pvargSrc, LCID lcid, unsigned short wFlags, VARTYPE vt);
- 这两个函数执行的任务基本相同 - 将 pvargSrc 转换为 vt 指定的类型,并将结果放在 pvargDest 中。 这些功能将在本文第3节中进一步深入探讨。
- 值得一提的其他函数是那些负责将 VARIANT 值从一个 VARIANT 复制到另一个 VARIANT 的函数:
(1) HRESULT VariantCopy(VARIANTARG *pvargDest, VARIANTARG *pvargSrc);
(2) HRESULT VariantCopyInd(VARIANTARG *pvargDest, VARIANTARG *pvargSrc);
- 这些函数既清除目标 VARIANT,又复制源 VARIANT 。他们做了很深的副本; 也就是说,如果复制了 COM 接口,则引用计数会递增,依此类推。这两个函数之间的区别在于 VariantCopyInd() 将遵循副本的间接引用(即,如果 VARIANT 具有 VT_BYREF 修饰符,则该值将被解除引用然后被修改),而 VariantCopy() 则不会。VariantCopyInd() 也是递归的; 如果收到具有类型(VT_BYREF | VT_VARIANT)的 VARIANT,则将进一步检查目标 VARIANT。如果它也是(VT_BYREF | VT_VARIANT),则发出错误信号。 如果它具有 VT_BYREF 修饰符但不是 VT_VARIANT,则此 VARIANT 将再次传递给 VariantCopyInd(),从而检索存储的值。
2.1.2.2 COM 自动化
- 如前所述,COM Automation 有助于将可插入组件集成到脚本环境中。这主要通过创建实现一个或两个自动化接口的对象来实现:IDispatch 和 IDispatchEx。IDispatch 接口公开了旨在实现以下指令的函数:
1. Allow an object to be self-publishing – ie. Advertise its properties and methods
允许对象自我发布 - 即公开其属性和方法
2. Allow methods to be called or properties to be manipulated by name, rather than direct VTable memory manipulation.
允许通过名称调用方法或属性,而不是直接VTable内存操作
3. Provide a unified marshalling interface for objects being passed to methods or properties, as well as objects being returned to the scripting host.
为传递给方法或属性的对象提供统一的编组接口,如以及返回脚本主机的对象
- 通过实现 IDispatch,对象可以在运行时由主机应用程序加载,并随后进行操作,而主机不必知道有关对象的任何编译时详细信息。此功能对于需要可扩展性的脚本接口特别有用。
- IDispatch 接口派生自 IUnknown(均在 MSDN 上记录),添加了四种方法,如下所示:
/*** IDispatch methods ***/
HRESULT (STDMETHODCALLTYPE *GetTypeInfoCount)(
IDispatch* This,
UINT* pctinfo);
HRESULT (STDMETHODCALLTYPE *GetTypeInfo)(
IDispatch* This,
UINT iTInfo,
LCID lcid,
ITypeInfo** ppTInfo);
HRESULT (STDMETHODCALLTYPE *GetIDsOfNames)(
IDispatch* This,
REFIID riid,
LPOLESTR* rgszNames,
UINT cNames,
LCID lcid,
DISPID* rgDispId);
HRESULT (STDMETHODCALLTYPE *Invoke)(
IDispatch* This,
DISPID dispIdMember,
REFIID riid,
LCID lcid,
WORD wFlags,
DISPPARAMS* pDispParams,
VARIANT* pVarResult,
EXCEPINFO* pExcepInfo,
UINT* puArgErr);
- 如果应用程序想要调用任何方法或修改对象公开的任何属性,则首先需要确定与其要调用的方法关联的调度 ID。要确定此信息,应用程序首先需要调用 GetIdsOfNames() 。返回值是一个整数,它映射到将通过 Invoke() 方法执行的实际方法。Invoke() 方法将要执行的成员的 ID,方法的参数以及有关语言环境等的一些其他信息作为参数。传递给 Invoke() 的 wFlags 参数定义了调度 ID 是引用由对象公开的方法还是应该获取或设置的属性值。将要执行的方法的参数在 DISPPARAMS 结构中传递。DISPPARAMS 结构定义如下:
typedef struct FARSTRUCT tagDISPPARAMS{
VARIANTARG FAR* rgvarg; // Array of arguments(参数数组)
DISPID FAR* rgdispidNamedArgs; // Dispatch IDs of named arguments(已命名参数的调度ID)
Unsigned int cArgs; // Number of arguments(个数参数)
Unsigned int cNamedArgs; // Number of named arguments(命名参数的数目)
} DISPPARAMS;
- 如您所见,此结构将参数传递给 VARIANT 数组中的方法(有关更多详细信息,请参阅有关 VARIANT 的部分)。必须通过被调用的方法对此数组进行解组。 在某些情况下,考虑到阵列中可能存在的某些 VARIANT 类型的复杂性,这可能是一项艰巨的任务。
- IDispatch 接口对于创建行为不可变的自动化对象非常有用 - 必须在编译时知道属性和方法,并且它们不会更改。但是,在某些情况下,需要具有可在运行时修改其行为的对象,并且 IDispatchEx 接口扩展 IDispatch 以允许此附加功能。使用 IDispatchEx 对象,可以在运行时添加或删除属性或方法。这是更动态的后期绑定语言(例如脚本语言 JavaScript)通常需要的功能。
- IDispatchEx 也派生自 IUnknown 接口,添加了以下八种方法:
HRESULTDeleteMemberByDispID(
DISPID id);
HRESULT DeleteMemberByName(
BSTR bstrName,
DWORD grfdex);
HRESULT GetDispID(
BSTR bstrName,
DWORD grfdex,
DISPID *pid);
HRESULT GetMemberName(
DISPID id,
BSTR *pbstrName);
HRESULT GetMemberProperties(
DISPID id,
DWORD grfdexFetch,
DWORD *pgrfdex);
HRESULT GetNameSpaceParent(
IUnknown **ppunk);
HRESULT GetNextDispID(
DWORD grfdex,
DISPID id,
DISPID *pid);
HRESULT InvokeEx(
DISPID id,
LCID lcid,
WORD wFlags,
DISPARAMS *pdp,
VARIANT *pVarRes,
EXCEPINFO *pei,
IServiceProvider *pspCaller);
- 虽然检索调度 ID 的方式存在一些差异,但 IDispatchEx 的主要更改是允许创建和删除对象属性和方法。例如,GetDispID() 与 GetIdsOfNames() 的不同之处在于,它可以被告知为新属性或方法创建新名称和分派 ID。此外,您还可以看到添加了 DeleteMemberByName() 和 DeleteMemberByDispID() 方法。在扩展 IDispatchEx 接口的 ActiveX 控件中,可以通过 JavaScript 对访问成员进行动态创建和删除。
- 有趣的是,JavaScript(用于 Internet Explorer)本身是使用 Microsoft 脚本引擎公开的经过修改 IDispatchEx 接口实现的。从概念上讲,这种实现是有意义的,因为 JavaScript 需要能够创建对象并添加和删除所有成员,而不需要任何先入为主的概念。 因此,例如,当 JavaScript 创建一个新对象时:
Obj= new Object();
- Internet Explorer 将首先调用 Obj 的 GetDispID() 方法 - 确保将 fdexNameEnsure 标志设置为创建成员。然后它将调用自己的内部版本的 Invoke() 来调用 Object() 方法。然后,调用 Invoke() 返回的值将分配给 Obj 成员。
2.1.2.3 COM 持久性概述
- COM 提供了两个主要接口来操作对象的持久性数据。第一个接口 IStream 表示用于存储单个对象的持久数据的数据流。它支持标准文件操作,包括使用接口方法进行读取,写入和搜索。IStream 接口从流的使用者抽象出底层存储细节。此抽象允许 COM 对象实现序列化功能,而无需明确了解底层后备存储。该抽象在图12中可视地描绘:
- 当程序或 COM 对象需要多个对象的持久性时,使用第二个接口 IStorage 。 IStorage 表示一个存储文件,它可以使用唯一名称在单个文件中保存逻辑上独立的二进制流,以标识每个流。此外,存储文件可以包含逻辑上独立的从属存储文件,也可以通过唯一名称访问,从而允许在需要时进行递归。IStorage 接口提供的方法允许程序员访问每个组成流和从属存储文件。图13描绘了典型存储文件的示例:
- 除了 IStream 和 IStorage 之外,还有几个其他接口可用于操作 COM 持久性数据,具体取决于包含数据的介质。以下是可以存储持久对象数据的接口列表:
(1) IMoniker
(2) IFile
(3) IPropertyBag
(4) IPropertyBag2
- COM 对象通过实现几个众所周知的持久性接口之一来支持序列化。这些持久性接口中的每一个都是 IPersist 接口的特化,具有以下定义:
MIDL_INTERFACE("0000010c-0000-0000-C000-000000000046")
IPersist : public IUnknown
{
public:
virtual HRESULT STDMETHODCALLTYPE GetClassID(
/* [out] */ __RPC__out CLSID *pClassID) = 0;
}
- IPersist 的每个子类都有名为 Load() 和 Save() 的方法,它们分别对数据进行序列化和恢复。这些子类之间的区别是保存持久数据的接口类型。表14列出了持久性接口以及每个相应接口用于保存数据的参数类型。图15直观地描述了这些接口的继承层次结构:
- 当主机程序希望序列化对象时,它将查询该对象以获得持久性接口。如果成功,应用程序将调用 Save() 方法,将指针传递给之前讨论的存储接口之一( IStream、IStorage、IFile 等)。稍后,当主机程序希望从持久状态恢复对象时,它将再次检索对象的持久性接口,并调用 Load() 方法。从持久性数据中恢复的对象应该等同于先前保存的对象。

a) 在 ATL 中实现 COM 持久性
- COM 对象的开发人员可以自由地实现自己的持久性接口。如果这些开发人员选择为接口编写自己的代码,他们将通过以任意格式读取和写入数据来操纵存储持久性数据的接口。但是,大多数开发人员选择使用 Microsoft ATL 中提供的模板类,当有模板代码时,可以避免实现这些接口所需的额外工作。Microsoft ATL 的第 9 版具有以下持久性接口的模板类:
(1) `IPersist`
(2) `IPersistPropertyBag`
(3) `IPersistStorage`
(4) `IPersistStreamInit`
- 模板代码要求程序员定义一系列属性,称为属性映射,持久性接口将使用该属性作为用于序列化和恢复相关对象的样板。此属性映射是一个终止的结构数组,列出了必须序列化和恢复的控件的属性,并且应该足够明确,以保证对象一旦序列化,将等同于从数据中恢复的对象。 ATL 的第9版包括各种宏,以帮助程序员定义这些属性并包括来自以下列表的宏:
(1) BEGIN_PROPERTY_MAP
(2) BEGIN_PROP_MAP
(3) PROP_ENTRY
(4) PROP_ENTRY_EX
(5) PROP_ENTRY_TYPE
(6) PROP_ENTRY_TYPE_EX
(7) PROP_PAGE
(8) PROP_DATA_ENTRY
(9) END_PROPERTY_MAP
(10) END_PROP_MAP
- 前面提到的每个宏函数都采用各种参数,并使用它们来定义
ATL_PROPMAP_ENTRY结构。以下代码是从 ATL 版本 9 中获取的结构定义:
struct ATL_PROPMAP_ENTRY
{
LPCOLESTR szDesc;
DISPID dispid;
const CLSID* pclsidPropPage;
const IID* piidDispatch;
DWORD dwOffsetData;
DWORD dwSizeData;
VARTYPE vt;
};
ATL_PROPMAP_ENTRY结构中的元素对于理解非常重要,并在表16中进行了总结:
- 用于定义属性的宏函数使用提供给函数的参数来设置某些 ATL_PROPMAP_ENTRY 元素,并将其他元素设置为默认状态。根据具有非默认值的元素,负责持久性操作的模板代码在序列化和恢复数据时将使用略有不同的策略。 BEGIN_PROPERTY_MAP 和 BEGIN_PROP_MAP 都将包含开始定义结构的代码; 但是,前者将自动在属性映射中包含 X 和 Y 位置信息。 END_PROP_MAP 和 END_PROPERTY_MAP 是宏函数,包括终止 ATL_PROPMAP_ENTRY 元素并结束结构定义。在 BEGIN_PROPERTY_MAP 或 BEGIN_PROP_MAP 和 END_PROP_MAP 或 END_PROPERTY_MAP 之间是 ATL_PROPMAP_ENTRY 实例,它们描述 COM 对象的属性。
- PROP_ENTRY 和 PROP_ENTRY_EX 都使用属性的名称,显示 ID 和可用于设置属性的属性页来定义属性。 PROP_ENTRY_TYPE 和 PROP_ENTRY_TYPE_EX 定义与 PROP_ENTRY 和 PROP_ENTRY_EX 相同的信息;但是,它们还需要在处理属性时预期的显式 variant 类型。 “_EX” 后缀表示宏函数还需要在设置时使用显式调度接口 ID 获得属性的价值。 PROP_DATA_ENTRY 宏需要该属性的唯一字符串标识符,将用于存储该属性的类成员的名称,以及该属性所需的 variant 类型。在内部,PROP_DATA_ENTRY 宏使用 offsetof 和 sizeof 结构在 ATL_PROPMAP_ENTRY 结构中显式定义 dwOffsetData 和 dwSizeData。 PROP_PAGE 用于指定提供 GUI 界面的 COM 类 ID,该 GUI 界面可以操纵对象的属性。
- 为了帮助说明在 C 代码中使用属性映射以及如何从持久状态读取属性,我们将简要介绍一个名为 HelloCom 的 COM 对象示例。 HelloCom 是一个简单的 ActiveX 控件,可以存储一个人的名字和姓氏。属性将具有以下名称:
(1) NameFirst
(2) NameLast
- 以下 C++ 代码段显示了与实现持久性相关的 HelloCom 控件的部分代码:
class HelloCom:
public IPersistStreamInitImpl<HelloCom>,
public IPersistStorageImpl<HelloCom>,
public IPersistPropertyBagImpl<HelloCom>,
{
public:
BEGIN_PROP_MAP(HelloCom)
PROP_DATA_ENTRY("_cx", m_sizeExtent.cx, VT_UI4)
PROP_DATA_ENTRY("_cy", m_sizeExtent.cy, VT_UI4)
PROP_ENTRY("NameFirst", 1, CLSID_HelloComCtrl)
PROP_ENTRY_TYPE("NameLast", 2, CLSID_HelloComCtrl, VT_BSTR)
END_PROP_MAP()
};
- 如果应用程序正在从二进制流加载持久性数据,则应用程序将查询 IPersistStreamInit 接口,并将接收指向 IPersistStreamInitImpl 模板类的 vtable 。接下来,应用程序将调用 Load() 方法,传入将用于读取持久性数据的 IStream 对象。在流中的任何序列化数据之前,存储版本号以便处理向后兼容性问题。因此,流中的前四个字节将是用于编译控件的 ATL 版本的小端表示。在 Visual Studio 2008 中,此值为 0x00000900。 只要该值小于或等于用于编译控件的 ATL 的版本,就可以恢复处理,否则会发出错误信号。
- 在处理版本控制信息之后,可以从流中检索属性本身。在这种情况下,流中版本号后面的字节将是 _cx 和 _cy 元素的两个 4 字节 little-endian 表示。由于这些元素是使用 PROP_DATA_ENTRY 宏声明的,因此这些 32 位值将直接写入 m_sizeExtent.cx 和 m_sizeExtent.cy 值所在的类中的内存偏移量。
- 遵循这些值,我们将遇到 NameFirst 的序列化表示。由于 NameFirst 是使用不包含数据类型的 PROP_ENTRY() 宏在属性映射中声明的,因此需要从流中检索类型信息。因此,流中的前两个字节将是无符号的 16 位值 0x0008,表示 variant 类型 VT_BSTR。接下来将是一个无符号的 32 位值,指定字符串的长度。如果名称是 “Example”,那么指定大小的这个 32 位整数的值将等于 0x10; 七个 2 字节字符加上一个终止空值。接下来的值将是表示名称的字符,后跟终止的 16 位值 0x0000。接下来的 NameLast 与 NameFirst 相同,除了流中不存在 16 位 variant 类型说明符,因为使用 PROP_ENTRY_TYPE() 宏在属性映射中显式声明了类型。
- 表 17 显示了前面段落中描述的流的示例,其中十六进制值表示流中的值,偏移量表示流中值的位置,以及如何解释值的描述:

b) Internet Explorer 中的 COM 持久性
- Microsoft Internet Explorer 在为ActiveX对象的属性赋值时使用持久性。Internet Explorer 使用的六个主要接口(按优先顺序排列)是 IPersistPropertyBag,IPersistMoniker,IPersistFileIPersistStreamInit,IPersistStream 和 IPersistStorage。浏览器将尝试按顺序检索每个持久性接口的接口指针,直到成功,或者没有找到接口,此时操作失败。
- 第一个也是最熟悉的持久性接口是 IPersistPropertyBag。IPersistPropertyBag 专门设计用于允许将持久对象嵌入 HTML 中。举例来说,以下 HTML 代码将 Microsoft Media Player 嵌入到网页中
<OBJECT id="VIDEO" CLASSID="CLSID:6BF52A52-394A-11d3-B153-00C04F79FAA6" >
<PARAM NAME="URL" VALUE="MyVideo.wmv">
<PARAM NAME="enabled" VALUE="True">
<PARAM NAME="AutoStart" VALUE="False">
<PARAM name="PlayCount" value="3">
<PARAM name="Volume" value="50">
<PARAM NAME="balance" VALUE="0">
<PARAM NAME="Rate" VALUE="1.0">
<PARAM NAME="Mute" VALUE="False">
<PARAM NAME="fullScreen" VALUE="False">
<PARAM name="uiMode" value="full">
</OBJECT>
- 标记内出现的 标记表示 COM 对象的属性名称和持久值。当 Internet Explorer 分析网页并遇到这些 PARAM 标记时,它首先创建一个 PropertyBag 类并查询 IPropertyBag 接口。接下来,它将解析 PARAM html 标记的名称和值参数,并在 IPropertyBag 接口上调用 Write() 方法,提供其已解析的属性的名称和字符串表示形式。一旦 Internet Explorer 将所有 PARAM 标记加载到属性包中,它将查询 IPersistPropertyBag 接口的 COM 对象(在上面的示例中为 Media Player 对象)。然后, Internet Explorer 将调用 IPersistPropertyBag 接口的 Load() 方法,并传递 PropertyBag 从 HTML 解析。然后,COM 对象的 Load() 方法将属性从字符串表示转换为对象的首选表示,然后将转换后的表示保存在 COM 对象中。当遇到上述 HTML 时,Internet Explorer 使用此策略从持久状态恢复对象。
- 当使用对象的 innerHTML 属性时,最常遇到恢复操作(序列化)。请考虑以下 JavaScript 代码,在与上述 HTML 相同的网页中使用:
<script language="JavaScript">
alert(VIDEO.innerHTML);
</script>
- 处理完之前的 JavaScript 后,网页将通过带有 HTML 格式文本的消息框提醒用户,类似于以下示例:
<PARAM NAME="URL" VALUE="./MyVideo.wmv">
<PARAM NAME="rate" VALUE="1">
<PARAM NAME="balance" VALUE="0">
<PARAM NAME="currentPosition" VALUE="0">
<PARAM NAME="defaultFrame" VALUE="">
<PARAM NAME="playCount" VALUE="3">
<PARAM NAME="autoStart" VALUE="0">
<PARAM NAME="_cx" VALUE="6482">
<PARAM NAME="_cy" VALUE="6350">
- 当 Internet Explorer 使用 PropertyBag 序列化对象时,它首先创建 PropertyBag 类的实例。接下来,它查询要为 IPersistPropertyBag 接口保留的对象。检索接口后, Internet Explorer 将调用 Save() 方法,并传递 PropertyBag 类实例。最后,Internet Explorer 会将 PropertyBag 类序列化为与 HTML 标准兼容的格式。
- 将持久性数据插入 Internet Explorer 控件的第二种不太常见的方法是通过使用 OBJECT 标签的 data 参数。 这种持久性的一个例子是如下 HTML 所示。
<OBJECT
id="VIDEO"
CLASSID="CLSID:6BF52A52-394A-11d3-B153-00C04F79FAA6"
data="./persistence_data"
type="application/x-oleobject"
/ >
- 在上面的示例中,不是使用 PARAM 标记,而是通过 object 标记的 data 参数传递持久性数据。当 Internet Explorer 遇到此格式的对象标记时,它遵循复杂的策略从序列化数据中恢复对象。
- Internet Explorer 将首先检查 data 参数中指定的文件名,以查看文件扩展名是否等于 “.ica” , "stm”或 “.ods” 。如果扩展名是其中之一,则它会创建一个 IStream ,它可以从提供的文件 URL 中读取二进制数据。然后,Internet Explorer 将创建在文件的前 16 个字节中指定的对象的实例,或者,如果这 16 个字节为零,则在对象标记中创建 CLASSID 参数并查询 IPersistStream 接口。如果成功检索到接口, Internet Explorer 将调用接口的 Load() 方法,并传入 IStream。接下来,COM 对象将解析流并将二进制数据转换为每个属性的首选表示形式。完成这些操作后,Internet Explorer 将完全拥有恢复的 COM 对象。
- 如果文件名与其中一个众所周知的扩展名不匹配,Internet Explorer 会做一些额外的工作来确定用于 COM 对象的持久性接口的类型和相应的持久性数据。首先, Internet Explorer 将在 COM 对象中查询 IPersistFile 接口。如果成功检索到接口,它将调用 COM 对象接口的 Load() 方法,并传入文件路径。然后, COM 对象负责打开文件并解析数据。
- 如果对象不支持 IPersistFile 接口,Internet Explorer 将使用数据值中的 URL,并创建一个 IStream 对象。接下来,它将在 COM 对象中查询 IPersistStreamInit 接口。 如果此操作成功,则 Internet Explorer 将调用 IPersistStreamInit 接口的 load() 方法,并传入 IStream 对象。如果 COM 对象不支持 IPersistStreamInit 接口,则它将尝试在对象中查询 IPersistStream 接口。如果对象实现此接口,则 Internet Explorer 将调用 IPersistStream 接口的 Load() 方法,并传入 IStream 对象。如果这些操作成功,则 COM 对象的 IPersistStreamInit 或 IPersistStream 接口负责从给定的持久性数据中恢复属性。
- 如果 COM 对象未实现 IPersistStreamInit 或 IPersistStream ,或者 Load() 方法返回失败,则 Internet Explorer 将尝试通过从 OLE32 调用 StgOpenStorage 将 URL 作为复合 OLE 文档加载。如果 StgOpenStorage 返回成功值,则 Internet Explorer 将在 COM 对象中查询 IPersistStorage 接口。如果 COM 对象确实实现了 IPersistStorage 接口,则 Internet Explorer 将调用接口的 Load() 方法,并传入 IStorage 对象。从这里开始, COM 对象也有责任解析 IStorage 对象中包含的数据。
2.1.3 攻击面
- COM的攻击面可以分为三个方面。 这些方面如下:
(1) 浏览器中的对象公开的方法
(2) COM对象的序列化
(3) Web浏览器组件之间的编组值
- 第一个攻击面实际上是之前已被多次解决的表面。 实际上,有很多针对ActiveX控件的演讲,以及为自动模糊测试暴露的漏洞方法而开发的工具。 (对于感兴趣的读者,最近发布了一篇关于来自 CERT 的Will Dormann 和 Dan Plakosh 编写的关于 ActiveX 模糊测试的论文,并提供了一个模糊测试工具,可在 http://www.cert.org/archive/pdf/dranzer.pdf 上找到。 另一个流行的 ActiveX 模糊器 AxMan 由 HD Moore 发布,可从 http://www.metasploit.com/users/hdm/tools/axman/. 获得)。
- COM 对象的序列化(也称为持久性)是另一个在安全问题上未被充分探索的领域。 我们将在第3节中广泛地研究持久性的安全性含义,讨论反序列化问题,由于持久对象而输入混淆漏洞,以及可以过对象实例化破坏的信任边界。
- 最后,在第3节中,我们将在安全性的上下文中检查编组代码。 这是另一个在很大程度上尚未开发的主要攻击面,很可能是由于它的隐含性质。 充斥着利用有时不直观的 API 来以抽象方式跟踪内存分配,对象使用和类型转换,编组代码可能非常难以编写。 我们打算讨论在执行某种程度的编组时经常出现的问题类型。 我们将考虑流行的 API 和接口,以及更广泛的关于编组代码中比其他任何地方更常见的问题类别的说法。
2.2 NPAPI 插件
- Netscape 插件应用程序编程接口(NPAPI)是许多当代Web浏览器采用的首选插件架构,包括 Mozilla Firefox , Google Chrome , Apple Safari 和 Opera。该体系结构提供了一个简单的模型,用于创建插件,通过定义的 API 调用向 Web 浏览器公开功能。尽管 NPAPI 在其原始版本中受到某种程度的限制,但随着时间的推移,主要的修订允许创建插件,这些插件不仅可以处理嵌入在网页中的专用对象,还可以使用托管脚本语言(如 JavaScript)将它们暴露给脚本控件。这主要是由于2004年几家公司(Mozilla,Apple,Macromedia,Opera和Sun)的共同努力,通过添加所谓的 NPRuntime 来扩展 NPAPI , NPRuntime 提供了一个跨平台标准,用于将对象暴露给浏览器 DOM。本节旨在提供有关如何利用 NPAPI 的技术细节;特别关注 NPRuntime 组件,因为该组件是最相关的功能,将在本文的以下部分中讨论
2.2.1 NPAPI 插件注册
- 在深入研究 NPAPI 的细节之前,我们将简要探讨插件注册到浏览器的过程。这些知识是能够枚举给定安装的攻击面所必需的。
- 插件是最简单级别的共享库,它们在浏览器中注册,旨在处理专用对象类型。注册时,插件处理的对象以 MIME 类型,文件扩展名或两者的组合形式指定。插件注册并与 MIME 类型/扩展相关联的方式因浏览器和平台而异。本节考虑 Mozilla Firefox 的 Windows 安装,但在其他环境中可以使用类似的过程。
- 插件以两种方式之一注册到 Firefox 浏览器。
1.它们被复制到浏览器的 plugins 目录中(通常是C:\Program Files\Mozilla Firefox\plugins)
2.将一个密钥添加到注册表以指示插件的位置和其他细节(在HKEY_LOCAL_MACHINE\Software\MozillaPlugins或HKEY_CURRENT_USER\Software\MozillaPlugins中)。插件所需的各个子项的结构记录在https://developer.mozilla.org/en/Plugins/The_First_Install_Problem中)
- 有关给定插件的关联 MIME 类型和文件扩展名的信息位于已编译 DLL 中的版本信息中。 MIME 类型在一系列管道分隔(’|’) MIME 标识符中指定,如下所示:
MIMEType: mime/type-1|mime/type-2|mime/type-3
- 同样,文件扩展名也按管道分隔列表组织,如下所示:
FileExtents: ext1|ext2|ext3
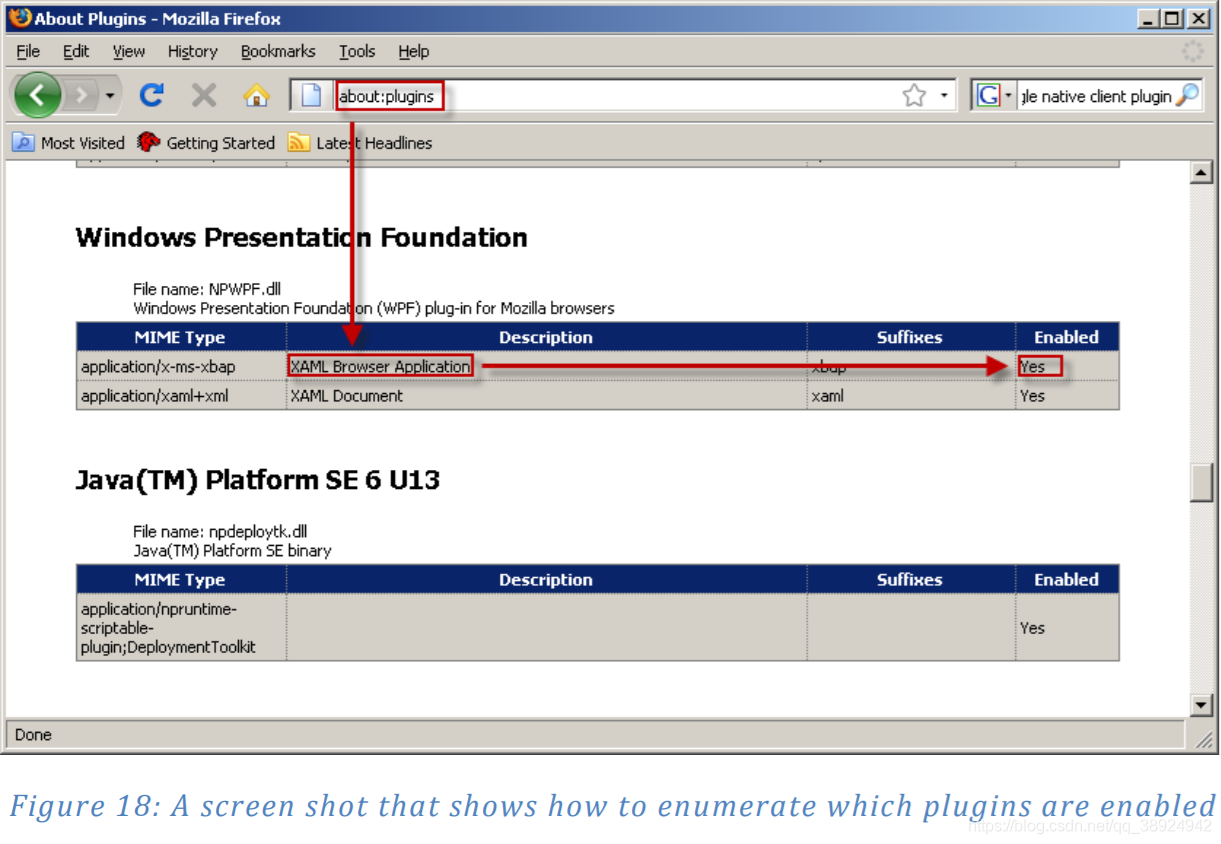
- 能够检查给定 Firefox 安装的可用插件的快速方法是简单地浏览到关于: plugins 的 URL,其提供可用安装插件的列表以及与每个插件相关联的 MIME 类型和文件扩展名:
2.2.2 NPAPI 和插件初始化
- NPAPI 大致分为两组功能:浏览器端功能和插件端功能。浏览器端函数表示浏览器导出到插件的 API。此浏览器端 API 包含在名为 NPNetscapeFuncs 的结构中,该结构在 NPAPI SDK 的 npupp.h 中定义(作为 Gecko SDK 的一部分提供:https://developer.mozilla.org/En/Gecko_SDK ),并显示在下面:
typedef struct _NPNetscapeFuncs {
uint16 size;
uint16 version;
NPN_GetURLUPP geturl;
NPN_PostURLUPP posturl;
NPN_RequestReadUPP requestread;
NPN_NewStreamUPP newstream;
NPN_WriteUPP write;
NPN_DestroyStreamUPP destroystream;
NPN_StatusUPP status;
NPN_UserAgentUPP uagent;
NPN_MemAllocUPP memalloc;
NPN_MemFreeUPP memfree;
NPN_MemFlushUPP memflush;
NPN_ReloadPluginsUPP reloadplugins;
NPN_GetJavaEnvUPP getJavaEnv;
NPN_GetJavaPeerUPP getJavaPeer;
NPN_GetURLNotifyUPP geturlnotify;
NPN_PostURLNotifyUPP posturlnotify;
NPN_GetValueUPP getvalue;
NPN_SetValueUPP setvalue;
NPN_InvalidateRectUPP invalidaterect;
NPN_InvalidateRegionUPP invalidateregion;
NPN_ForceRedrawUPP forceredraw;
NPN_GetStringIdentifierUPP getstringidentifier;
NPN_GetStringIdentifiersUPP getstringidentifiers;
NPN_GetIntIdentifierUPP getintidentifier;
NPN_IdentifierIsStringUPP identifierisstring;
NPN_UTF8FromIdentifierUPP utf8fromidentifier;
NPN_IntFromIdentifierUPP intfromidentifier;
NPN_CreateObjectUPP createobject;
NPN_RetainObjectUPP retainobject;
NPN_ReleaseObjectUPP releaseobject;
NPN_InvokeUPP invoke;
NPN_InvokeDefaultUPP invokeDefault;
NPN_EvaluateUPP evaluate;
NPN_GetPropertyUPP getproperty;
NPN_SetPropertyUPP setproperty;
NPN_RemovePropertyUPP removeproperty;
NPN_HasPropertyUPP hasproperty;
NPN_HasMethodUPP hasmethod;
NPN_ReleaseVariantValueUPP releasevariantvalue;
NPN_SetExceptionUPP setexception;
NPN_PushPopupsEnabledStateUPP pushpopupsenabledstate;
NPN_PopPopupsEnabledStateUPP poppopupsenabledstate;
} NPNetscapeFuncs;
- 当插件最初加载到内存中时,通过调用插件需要导出的函数 NP_Initialize() 来初始化它。 NPNetscapeFuncs 结构作为浏览器的第一个参数传递给此函数,从而将其 API 暴露给插件。读者应该注意, size 和 version 元素中的信息允许对 API 进行扩展,这确实具有已投入使用。SDK 鼓励使用前缀 NPN_* 作为浏览器端功能(Netscape Plugin:Navigator),因此本文的其余部分将引用使用该约定的回调。
- 插件端函数是插件实现的函数,共同用于定义插件的功能。插件端函数包含在 NPPluginFuncs 结构中,该结构也在 npupp.h 中定义,并显示:
typedef struct _NPPluginFuncs {
uint16 size;
uint16 version;
NPP_NewUPP newp;
NPP_DestroyUPP destroy;
NPP_SetWindowUPP setwindow;
NPP_NewStreamUPP newstream;
NPP_DestroyStreamUPP destroystream;
NPP_StreamAsFileUPP asfile;
NPP_WriteReadyUPP writeready;
NPP_WriteUPP write;
NPP_PrintUPP print;
NPP_HandleEventUPP event;
NPP_URLNotifyUPP urlnotify;
JRIGlobalRef javaClass;
NPP_GetValueUPP getvalue;
NPP_SetValueUPP setvalue;
} NPPluginFuncs;
- 插件需要发布 NP_GetEntryPoints() 函数,该函数使用 NPPluginFuncs 结构在插件初始化时将插件信息传递给浏览器。浏览器调用 NP_GetEntryPoints,将指针传递给可以保存 NPPluginFuncs 结构的内存位置。 反过来,NP_GetEntryPoints 使用插件的信息填充结构。按照惯例,插件函数名称以 NPP_*(Netscape Plugin:Plugin)为前缀,我们将在本文中尝试遵循此约定。
2.2.3 NPAPI 插件初始化和销毁
- NPAPI 插件有两个级别的初始化 - 我们已经看到的第一个是浏览器加载插件时执行的一次性初始化。如前所述,此加载是通过调用导出函数 NP_Initialize() 来实现的。还有实例初始化,每次插件实例化时都会发生。例如,如果在同一页面上的两个不同的 标签中使用相同的插件,则将执行一次性加载初始化,然后进行两次实例初始化。实例初始化由插件的 NPP_New() 函数执行,该函数定义如下:
NPErrorNPP_New(
NPMIMEType pluginType,
NPP instance, uint16 mode,
int16 argc,
char *argn[],
char *argv[],
NPSavedData *saved
);
- 这个函数有很多参数可以为插件提供实例信息以帮助初始化过程。pluginType 参数表示与此插件实例关联的 MIME 类型。许多插件注册了几种 MIME 类型,因此该参数允许每个实例区分它应该处理的 MIME 类型。第二个参数 instance 是一个指向插件对象实例的指针,该插件对象有一个 pdata 成员,插件可以用它来保存特定于当前插件实例的任何私有数据。插件通常用于在此处保存 C++ 对象。下一个参数是一个 mode 参数,它可以取值 NP_EMBED(1)来表示对象嵌入在网页中,如果插件表示整页对象,则取 NP_FULL(2)。接下来的三个参数与提供给对象的 值(或 标记中的属性,如果使用它而不是 )相关。argc 参数表示 argn 和 argv 数组中提供的参数数量。两个字符串数组 argn 和 argv 的元素计数等于 argc 参数,并分别指定参数名称和值。最后,保存的参数可用于访问由插件的先前实例使用 NPP_Destroy() 保存的数据,这是我们将暂时探索的函数。
- 通过相对的函数 NPP_Destroy() 进行销毁操作,其具有以下定义:
NPErrorNPP_Destroy(NPP instance, NPSavedData **saved);
- 该函数只需要一个实例指针和一个 NPSavedData **,它可以用来保存下一个插件实例的信息,如前所述。
2.2.4 流(Streams)
- 流也与典型 NPAPI 插件的攻击面非常相关。由 NPStream 数据结构表示的流对象表示从浏览器发送到插件的不透明数据流,反之亦然。插件实例可以处理多个流,但每个流特定于该插件实例; 他们无法分享。
- 通过调用插件端函数 NPP_NewStream() 将新流从浏览器发送到插件,该函数具有以下原型:
NPErrorNPP_NewStream(
NPP instance,
NPMIMEType type,
NPStream *stream,
NPBool
seekable,
uint16 *stype
);
- 大多数这些参数都是不言自明的,除了 stype 参数,插件填充为以下值之一:
NP_NORMAL(1) - 流数据在拉出时传送。 这是默认的操作模式。
NP_ASFILEONLY(2) - 首先将数据本地保存在临时文件中
NP_ASFILE(3) - 数据与NP_NORMAL一样正常传送,但也保存到临时文件
NP_SEEK(4) - 流数据可以随机访问而不是顺序访问。
- 当文件与插件实例关联时(例如 Adobe Flash 插件的 SWF 文件),或者当插件通过调用 NPN_GetURL() , NPN_GetURLNotify() , NPN_PostURL() 请求流时,流将传递到插件, 或 NPN_PostURLNotify() 函数。
- 稍后通过调用 NPP_DestroyStream() 函数来销毁流。 该函数具有以下原型:
NPErrorNPP_DestroyStream(
NPP instance,
NPStream *stream,
NPReason reason
);
- 处理流数据发生在 NPP_Write() 或 NPP_AsFile() 中,具体取决于相关流是分别 NP_NORMAL / NP_ASFILE 还是 NP_ASFILEONLY 流。使用流数据的机制超出了本文的范围,将不再进一步讨论。
2.2.5 NPRuntime 基础知识
- NPRuntime 是 NPAPI 的补充,它提供了一个统一的接口,允许插件将可编写脚本的对象暴露给 DOM。在引入 NPRuntime 之前,还有其他方法允许将插件暴露给 Java 和脚本桥 - LiveConnect 和 XPCOM。这两种技术虽然仍在某种程度上得到支持,但被认为已被弃用,超出了本文的范围
- 希望提供脚本功能的插件通过使用 NPP_GetValue() 函数来实现。实质上,浏览器使用此功能来查询插件以获取许多众所周知的属性。 它有以下原型:
NPErrorNPP_GetValue(
NPP instance,
NPPVariable variable,
void *ret_value
);
- 变量参数指示要从插件检索的信息类。诸如插件的名称,描述或实例窗口的句柄之类的信息是可以检索的可能属性。引入 NPRuntime 组件时,会将一个变量添加到可查询的可能变量的枚举中 - 即 NPPVpluginScriptableNPObject,其数值为 15。当查询此值时,插件可以选择返回指向封装插件脚本功能的 NPObject 的指针。(稍后将更详细地探讨此对象)这是通过在 ret_value 参数中放置指向 NPObject 的指针来实现的。当 NPPVpluginScriptableNPObject 发生查询时,ret_value 参数实际上被解释为 NPObject **。没有任何脚本功能的插件只需在调用 NPP_GetValue() 时将返回错误,并将变量参数设置为 NPPVpluginScriptableNPObject 。
2.2.5.1 可编写脚本的对象
- 如前所述,通过使用 NPObject 结构公开对象,这些结构在 npruntime.h 中定义如下:
struct NPObject {
NPClass *_class;
uint32_t referenceCount;
/*
* 这里可以通过NPObject的类型分配额外的空间
* Additional space may be allocated here by types of NPObjects
*/
};
- 可以从封装的 NPClass 对象访问实际功能,该对象也在 npruntime.h 中定义,如下所示:
struct NPClass
{
uint32_t structVersion;
NPAllocateFunctionPtr allocate;
NPDeallocateFunctionPtr deallocate;
NPInvalidateFunctionPtr invalidate;
NPHasMethodFunctionPtr hasMethod;
NPInvokeFunctionPtr invoke;
NPInvokeDefaultFunctionPtr invokeDefault;
NPHasPropertyFunctionPtr hasProperty;
NPGetPropertyFunctionPtr getProperty;
NPSetPropertyFunctionPtr setProperty;
NPRemovePropertyFunctionPtr removeProperty;
NPEnumerationFunctionPtr enumerate;
NPConstructFunctionPtr construct;
};
- 这些函数中的每一个都实现了 JavaScript 对象操作的重要功能,该 API 的相关部分将在下面讨论。
a) NPRuntime 之对象初始化和销毁
- 首先,我们将考虑初始化。 通常,通过定义具有所有相关函数的 NPClass 结构,然后调用浏览器函数来创建可编写脚本的对象。NPN_CreateObject() 数具有以下原型:
NPObject*NPN_CreateObject(
NPP npp,
NPClass *aClass
- 可以看出,NPN_CreateObject() 将实例指针作为其第一个参数(稍后我们将探讨),并将指向 NPClass 结构的指针作为其第二个参数。 它只是在 NPClass 对象周围创建一个 NPObject 包装器并返回它。如果 NPClass 对象定义了 allocate() 回调,那么将调用它来为 PN_CreateObject() 函数返回的 NPObject 结构分配内存。此分配回调功能允许开发人员分配条件空间,以在包装 PObject 的结构中保存有关该对象的任何特定于上下文的信息。标准技术是将对象表示为 C++ 类,如下所示:
// MyObject derives from NPObject –
// It will be exposed as a scriptable object
class MyObject : public NPObject
{
public:
// Definition of the objects behaviors
static NPClass myObjectClass =
{
NP_CLASS_STRUCT_VERSION,
Allocate,
Deallocate,
Invalidate,
HasMethod,
Invoke,
InvokeDefault,
HasProperty,
GetProperty,
SetProperty,
};
// Call this function from NPP_GetValue() to retrieve the
// scriptable object
// It will create an NPObject wrapping the myObjectClass NPClass
// It will also call Allocate() to allocate the NPObject
static MyObject *Create(NPP npp)
{
MyObject *object;
object = reinterpret_cast<MyObject *> (NPN_CreateObject(npp, &myObjectClass));
}
// The Allocate() function creates an instance of MyObject,
// so we can initialize any private variables for MyObject etc..
// Note that the Allocate() function needs to be static
static NPObject *Allocate(NPP npp, NPClass *class)
{
return new MyObject(npp);
}
.. other methods ..
};
- 创建对象的另一个值得注意的细节是 NPObject 结构的引用计数成员将被初始化为 1,并且每次将对象传递给浏览器端函数 NPN_RetainObject() 时,成员将递增,其定义如下:
NPObject*NPN_RetainObject(
NPObject *obj
;
- 对于 Microsoft COM 对象,此函数可以被视为 AddRef() 的模拟。
- 当不再需要某个对象时,将调用浏览器端函数 NPN_ReleaseObject(),该函数用于 NPN_CreateObject() 的倒数运算。引用计数变量递减,如果它达到0,则将取消分配对象。如果正在释放的 NPObject 中指向的 NPClass 结构包含 deallocate() 回调,则将用于销毁该对象。否则,默认系统分配器将释放内存。
b) NPRuntime 之对象行为
- 对象最重要的特征是它暴露的行为。对象可以公开两种不同类型的属性:属性和方法。已定义属性是可以设置或检索的对象的属性。它在脚本中被操作,就像你期望任何其他 DOM 对象的属性一样:
Plugin.property = setVal; // set the property 设置属性
retVal = Plugin.property; // retrieve the property 检索属性
delete Plugin.property; // remove the property 删除属性
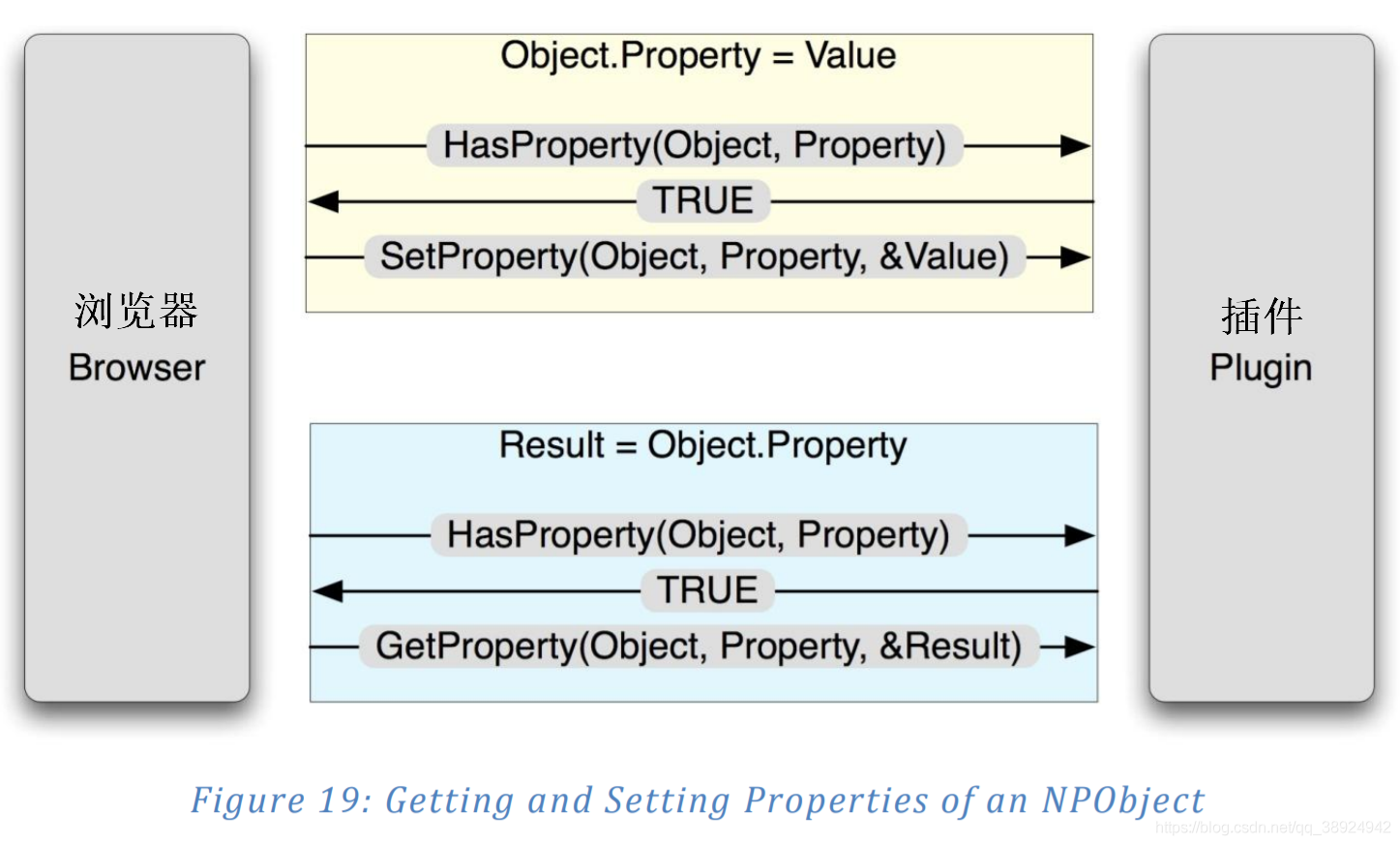
- 在内部,在脚本中执行任何这些操作将导致从定义对象的 NPClass 对象调用四个定义的属性相关函数中的两个:
boolHasProperty(NPObject *obj, NPIdentifer name)
bool GetProperty(NPObject *obj, NPIdentifier name, NPVariant *result)
bool SetProperty(NPObject *obj, NPIdentifier name, NPVariant *value)
bool RemoveProperty(NPObject *obj, NPIdentifier name)
- 无论是设置还是检索属性,浏览器采取的第一个操作是检查属性是否受支持,这是通过使用将被操作的属性的名称调用 HasProperty() 方法来完成的。NPIdentifier 数据类型用于解析属性或方法,并包含名称的哈希值而不是名称的值。如果不支持请求的名称,则会向脚本运行时返回错误。假设 HasProperty() 成功,则调用 GetProperty() 或 SetProperty(),具体取决于是检索还是设置。在检索的情况下,指向属性值的指针放在 GetProperty() 的 result 参数中,该参数将被脚本运行时解释为返回值(前一个脚本示例中的 retVal)。相反,在设置属性时,value 参数将被解释为属性设置为的值(上一个脚本示例中的 setVal)。最后,可以使用上面提到的删除语法删除属性。实际上,很少实现此功能。请注意,作为所有这些函数的第一个参数传递的 obj 参数是指向对象本身的指针。设置和获取属性的过程如图19所示:
- 使用 NPClass 结构中定义的三个方法,以与属性操作类似的方式实现方法调用:
boolHasMethod(
NPObject *obj,
NPIdentifier name
)
bool Invoke(
NPObject *obj,
NPIdentifier name,
const NPVariant *args,
uint32_t argCount,
NPVariant *result
)
bool InvokeDefault(
NPObject *obj,
const NPVariant *args,
uint32_t argCount,
NPVariant *result
)
- 与属性一样,当调用方法时,浏览器首先调用 HasMethod() 以查看插件是否已定义给定方法。假设此调用成功,则调用 Invoke() 函数。 Invoke() 函数获取在 name 参数中调用的方法名称,后跟一个参数数组,后跟一个指示参数数组大小的计数,最后一个指向将包含结果的变量的指针 调用。插件对象是使用 InvokeDefault() 函数执行就好像它是一个方法,就像在下面的 JavaScript 代码片段中一样:
var pluginobj= document.getElementById(“plugin”);
var result = pluginobj(args);
c) NPRuntime 之参数传递
- 正如我们在上一节中看到的,对象可以根据脚本主机可用的属性和方法来定义行为。在这两种情况下,参数都作为 NPVariants 传入和传出 NPAPI 入口点。NPVariants 基本上是一个不透明的数据结构,用于表示可以从脚本引擎(如 JavaScript)轻松导入或导出的不同变量。NPVariant 结构定义如下:
typedef struct _NPVariant {
NPVariantType type;
union {
bool boolValue;
int32_t intValue;
double doubleValue;
NPString stringValue;
NPObject *objectValue;
} value;
} NPVariant;
- 可以看出,该结构是一种非常简单的类型/联合结构,非常类似于 Microsoft Windows 平台上普遍存在的 VARIANT 数据结构。这里的所有数据类型都是基本类型或 NPObject(之前讨论过),但有一个例外 - NPString 值,定义如下:
typedef char NPUTF8;
typedef struct _NPString {
const NPUTF8 *utf8characters;
uint32_t utf8length;
} NPString;
- 联合中包含的值由 NPVariant 的类型定义,该类型定义为以下之一:
typedef enum {
PVariantType_Void,
NPVariantType_Null,
NPVariantType_Bool,
NPVariantType_Int32,
NPVariantType_Double,
NPVariantType_String,
NPVariantType_Object
} NPVariantType;
- NPAPI 提供了许多用于操作 NPVariant 数据结构的标准化宏。这些宏在 npruntime.h 中定义,分为三类。第一个类别用于测试 NPVariant 的类型,其格式为:NPVARIANT_IS_XXX(),其中 XXX 是要检查的对象类型:
#define NPVARIANT_IS_VOID(_v) ((_v).type == NPVariantType_Void)
#define NPVARIANT_IS_NULL(_v) ((_v).type == NPVariantType_Null)
#define NPVARIANT_IS_BOOLEAN(_v) ((_v).type == NPVariantType_Bool)
#define NPVARIANT_IS_INT32(_v) ((_v).type == NPVariantType_Int32)
#define NPVARIANT_IS_DOUBLE(_v) ((_v).type == NPVariantType_Double)
#define NPVARIANT_IS_STRING(_v) ((_v).type == NPVariantType_String)
#define NPVARIANT_IS_OBJECT(_v) ((_v).type == NPVariantType_Object)
- 例如,可以使用 NPVARIANT_IS_STRING() 宏来测试特定 variant 是否为字符串。第二类是从 NPVariant 中提取值,宏名称的形式为 NPVARIANT_TO_XXX():
#define NPVARIANT_TO_BOOLEAN(_v) ((_v).value.boolValue)
#define NPVARIANT_TO_INT32(_v) ((_v).value.intValue)
#define NPVARIANT_TO_DOUBLE(_v) ((_v).value.doubleValue)
#define NPVARIANT_TO_STRING(_v) ((_v).value.stringValue)
#define NPVARIANT_TO_OBJECT(_v) ((_v).value.objectValue)
- 最后,有一些宏用于将数据存储到 NPVariant 变量中。 这些宏的格式 XXX_TO_NPVARIANT()。最后一个类别主要用于为 GetProperty() ,Invoke() 和 InvokeDefault() 函数填充结果 NPVariant。
d) NPRuntime 之编组和类型解析
- 那么,脚本主机如何将数据传入插件和从插件传递数据? 答案是,需要编组层来解释脚本主机中的对象,并将它们转换为插件可以理解的类型,反之亦然。显然,该层是依赖于实现的,并且因浏览器而异。本节将简要概述 Mozilla Firefox 编组层,以便于 JavaScript 和可编写脚本的对象之间的通信
- NPRuntime 插件所需的转换实际上非常简单,因为在大多数情况下,NPObject 类型精确映射到本机支持的 JavaScript。编组操作都包含在 Firefox 源代码树的单个文件中:
mozilla/modules/plugin/base/src/nsJSNPRuntime.cpp。为了实现将 JavaScript 变量转换为 NPVariants 的两个主要目标,反之亦然,采用对象代理方法,这将在下面讨论。 - 在设置属性或调用方法时,传递给插件的 JavaScript 对象需要转换为 NPVariants 。对于基本类型,此转换是将 JavaScript 中的文字值移植到 NPVariant 结构中的简单过程:
if (JSVAL_IS_PRIMITIVE(val)) {
if (val == JSVAL_VOID) {
VOID_TO_NPVARIANT(*variant);
} else if (JSVAL_IS_NULL(val)) {
NULL_TO_NPVARIANT(*variant);
} else if (JSVAL_IS_BOOLEAN(val)) {
BOOLEAN_TO_NPVARIANT(JSVAL_TO_BOOLEAN(val), *variant);
} else if (JSVAL_IS_INT(val)) {
INT32_TO_NPVARIANT(JSVAL_TO_INT(val), *variant);
} else if (JSVAL_IS_DOUBLE(val)) {
OUBLE_TO_NPVARIANT(*JSVAL_TO_DOUBLE(val), *variant);
- 处理此转换的代码位于 JSValToNPVariant() 中。 在字符串的情况下,需要做一些额外的工作来处理 UTF-8 转换:
} else if (JSVAL_IS_STRING(val)) {
JSString *jsstr = JSVAL_TO_STRING(val);
nsDependentString str((PRUnichar*)::JS_GetStringChars(jsstr),
::JS_GetStringLength(jsstr));
PRUint32 len;
char *p = ToNewUTF8String(str, &len);
if (!p) {
return false;
}
STRINGN_TO_NPVARIANT(p, len, *variant);
- 最后,还有 JavaScript 对象。 当这些作为参数传递时,会创建一个包装 JavaScript 对象的 NPObject 结构。包装器对象的功能在 NPClass 结构 sJSObjWrapperClass 中定义,该结构包含将请求代理到 JavaScript 引擎的方法。 例如,如果在包装器对象上调用 NPP_GetProperty(),它将检索被包装的 JavaScript 对象的实例,并允许 JavaScript 引擎在内部处理特定内容。该过程如图20所示。
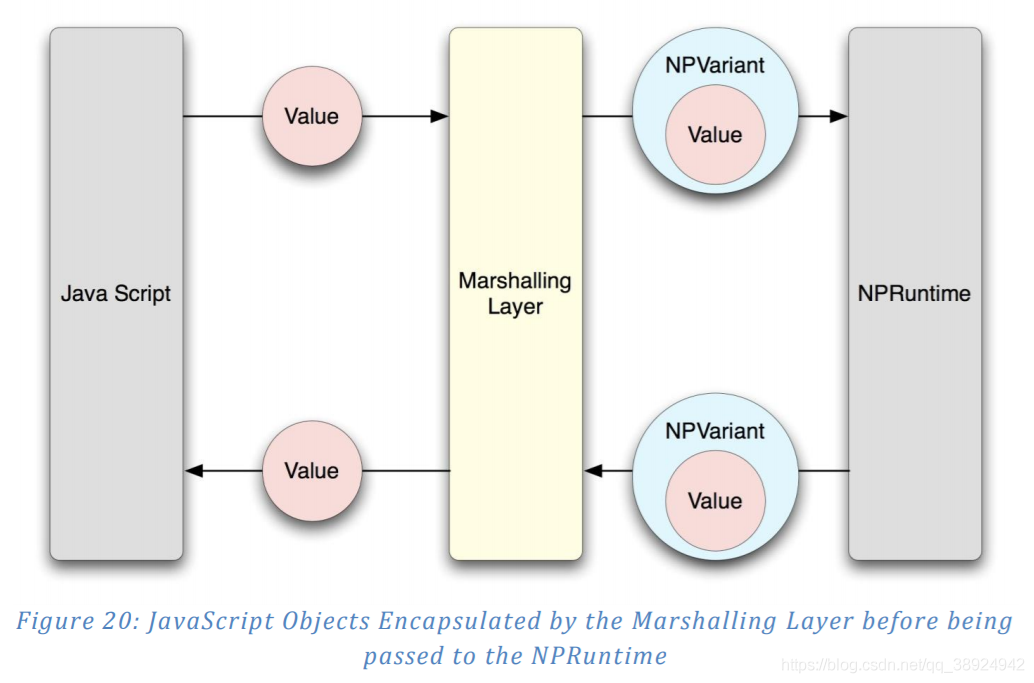
- 类似地,当对象从 NPVariants 转换回 JavaScript 时,NPVariantToJSVal() 函数会将立即值复制回 JavaScript 对象,或者创建一个代理调用 NPObject 公开的功能的 JavaScript 对象。此代理类使用 sNPObjectJSWrapperClass 结构实现。
2.2.6 攻击面
- 在 NPAPI 的背景下,攻击面可以分为大致三个关键区域,即:
(1) 标准插件入口点
(2) 入口指向暴露的可编写脚本的对象,以及
(3) 在浏览器本身内编组图层
- 标准插件入口点可以概括为 “ Netscape 插件” 结构(即 NPP_ * 函数)公开的入口点。我们已经检查了标准入口点的相对较大的攻击面,特别是通过 NPP_New() 向插件实例提供参数,或者在 URL 流中检索的数据(当收到 NP_NORMAL 流时,这些数据主要由 NPP_Write() 函数处理,以及收到 NP_ASFILEONLY 流时的 NPP_StreamAsFile())。虽然这是一个有点大的攻击面,但它也是大多数安全研究在此之前所关注的明确的攻击面。因此,本文不会涉及这些切入点,除非它们为将要讨论的互操作性攻击提供一些上下文。
- 可脚本化对象暴露的入口点可能是过去几乎没有处理过的最广泛的攻击面。实现对象的脚本交互的函数将是最明显的攻击向量,例如给定 NPObject 的 Invoke(),InvokeDefault() 、GetProperty() 和 SetProperty()。我们还必须在此攻击面中考虑互操作性的不太明显的入口点 - 主要是插件使用 NPN_GetProperty() 函数访问 DOM 层次结构的位置。
- 最后,每个实现 NPAPI 运行时的浏览器都必须提供一些编组层,用于将对象从脚本语言运行时转换为 NPVariants,反之亦然。此绑定层还为攻击者提供了大量机会,以便发现漏洞。
第三节:对互操作性的攻击
- 旨在实现互操作性的架构很难实现。开发代码时必须避免一系列新问题,因此,这种情况会给攻击者带来破坏系统安全性的新机会。以下小节将列举在通过互操作性层管理数据时特别出现的漏洞类。
正在讨论的课程是:
1. Object Retention vulnerabilities. 对象保留漏洞
2. Type Confusion vulnerabilities. 键入Confusion漏洞
3. Transitive Trust vulnerabilities. 传递信任漏洞
- 在类型混淆和传递信任类中提供的研究显着扩展了这些术语的任何先前使用 - 在一定程度上保证将它们视为新的漏洞类。当然,在数据编组的上下文中也存在标准类型的漏洞,例如整数宽度问题和缓冲区溢出,但本文不会讨论这些漏洞,因为它们已被充分理解,并且已有大量文献充分阐明了这些漏洞话题。
3.1 互操作性攻击 I:对象保留漏洞
- 在内聚模块之间传递的数据可以是简单的文字值(例如 ntegers 或 Booleans),也可以是复杂的数据结构(例如 COM 对象)。对于后一种情况,运行时必须有一个方法来管理对象的生命周期。管理对象生命周期的一般策略是使用引用计数原语。这样的策略将对象的消费者的责任放在他们需要时以及完成它时的信号。接下来,如果消费者无法正确报告对象使用情况,则存在内存管理漏洞的潜在机会。一般来说,对象生命周期的错误管理发生在两种情况下:
1.在需要时不保留对对象的引用,因此存在过早释放内存的风险
2.在需要时不释放对象的引用,导致内存泄漏以及潜在的可利用场景(稍后讨论)
- 本节将描述这两种代码结构通常如何在两种不同的 realworld 插件体系结构中显示。读者应该注意,本节中易受攻击的代码构造很可能在插件对象和编组层本身中找到,因为这些接口通常需要保留对对象的引用并在强制过程中执行转换时生成新对象。
3.1.1 Microsoft 对象保留漏洞
- Microsoft 插件体系结构广泛使用 COM 对象和 VARIANT 来定义和传递浏览器中各个组件之间的对象。实际上,JavaScript 对象在语言运行时本身表示为 COM 对象,而 VBScript 对象表示为 VARIANT。通过调用对象的 IDispatch::Invoke() 方法来访问 ActiveX 对象公开的方法或属性,该方法将参数作为 VARIANT 数组接收到目标函数。(请注意,对于 ActiveX 控件,属性实际上是作为一对方法调用公开的,其名称格式为 get_XXX() 和 put_XXX(),其中 XXX 是属性的名称。这两个函数分别检索和设置属性) VARIANT 中包含的对象实际上可以是任何类型和值,但最常见的是它们是基本类型(如整数或字符串)或表示复杂对象的 COM 接口。由于 JavaScript 在内部将对象表示为 IDispatch(或更准确地说, IDispatchEx)COM 接口,因此 VT_DISPATCH VARIANT 将是在浏览器上下文中传递给典型控件的最常见的基于 COM 的 VARIANT 。
- COM 对象保持内部引用计数,并由 IUnknown::AddRef() 和 IUnknown::Release() 方法在外部进行操作,这些方法分别递增和递减引用计数。一旦引用计数达到 0,对象将从内存中删除自己。 ActiveX 控件中的对象保留错误是对象引用计数错误管理的结果。本节描述开发人员在处理生命周期大于单个函数调用范围的对象时所犯的典型错误。
3.1.1.2 ActiveX 对象保留攻击 I:没有保留
- 控件在对象保留方面可能犯的最明显的错误是忽略添加它想要保留的 COM 对象的引用计数。当 ActiveX 函数将 COM 对象作为参数时,编组层已经在接收到的对象上调用了 IUnknown::AddRef() ,以确保它不会被竞争线程删除。 但是, marshaller 还会在插件函数返回后释放该口。因此,希望保留超出方法范围的 COM 对象实例的插件对象必须在方法返回之前调用 IUnknown::AddRef() 函数。 调用 IUnknown::QueryInterface() 也足够了,因为这个函数也会(或者至少应该)为对象调用 IUnknown::AddRef()。未能调用这些函数中的任何一个都可能导致潜在的过时指针漏洞。下面的代码显示了这样一个问题的一个例子:
HRESULT CMyObject::put_MyProperty(IDispatch *pCallback)
{
m_pCallback = pCallback;
return S_OK;
}
HRESULT CMyObject::get_MyProperty(IDispatch **out)
{
if(out == NULL || *out == NULL || m_pCallback == NULL)
return E_INVALIDARG;
*out = m_pCallback;
return S_OK;
}
- 此代码中的 put_MyProperty() 函数存储一个 IDispatch 指针,稍后可以使用 get_MyProperty() 函数由客户端应用程序检索该指针。 但是,由于从不使用 AddRef(),因此无法保证在客户端回读属性时 pCallback 函数仍然存在。如果删除了对该对象的每个其他引用,则将取消分配该对象,使 m_pCallback 指向过时的内存。
a) VARIANT 浅拷贝
- 当复制 VARIANT 对象时,通常使用 VariantCopy() 完成,但在许多情况下也只使用简单的 memcpy()。 VariantCopy() 是首选方法,因为它将执行对象感知复制 - 如果要复制的 VARIANT 是字符串,它将复制内存。如果要复制的对象是对象,则会添加引用计数。 相比之下,memcpy() 显然执行浅拷贝 - 如果 VARIANT 包含任何类型的复杂对象,例如 IDispatch,则将复制和使用指向该对象的指针,而不添加对该对象的附加引用。如果保留此重复 VARIANT 的结果,则如果释放该对象的每个其他实例,则可以删除指向的对象。以下代码演示了此易受攻击的构造:
HRESULT CMyObject::put_MyProperty(VARIANT src)
{
HRESULT hr;
memcpy((void *)&m_MyProperty, (void *)&src, sizeof(VARIANT));
return S_OK;
}
HRESULT CMyObject::get_MyProperty(VARIANT *out)
{
HRESULT hr;
if(out == NULL)
return E_FAIL;
VariantInit(out);
memcpy(out, (void *)&m_MyProperty, sizeof(VARIANT));
return S_OK;
}
- 攻击还有一个更微妙的变化 - 这次使用 VariantCopy()。在某些方面,VariantCopy() 也可以被认为是浅拷贝操作,因为任何具有 VT_BYREF 修饰符的 VARIANT 都不会被深度复制; 只是指针将被复制。请考虑以下代码:
HRESULT CMyObject::put_MyProperty(VARIANT src)
{
HRESULT hr;
VariantInit(&m_MyProperty);
hr = VariantCopy(&m_MyProperty, &src);
if(FAILED(hr))
return hr;
return S_OK;
}
HRESULT CMyObject::get_MyProperty(VARIANT *out)
{
HRESULT hr;
if(out == NULL)
return E_FAIL;
VariantInit(out);
hr = VariantCopy(out, &m_MyProperty);
if(FAILED(hr))
return hr;
return S_OK;
}
- 此示例显示了一个示例 ActiveX 属性,它只接受 VARIANT 并将其存储,并可选择将其返回给用户。此代码的问题是使用 VariantCopy() 而不是 VariantCopyInd()。如果提供具有类型(VT_BYREF | VT_DISPATCH)的 VARIANT,则执行简单的指针复制。如果随后删除了指向的 VT_DISPATCH 对象,则会留下指向不再存在的 IDispatch 对象的 VARIANT。如果随后尝试获取此属性,则用户将检索带有过时指针的 VARIANT,从而导致内存损坏。
b) The ActiveX Marshaller
- 为了了解对象作为参数传递给 ActiveX 控件时发生的事件的确切语义,您需要特别注意目标函数所期望的类型。当 ActiveX 函数期望 VARIANT 作为参数时,编组代码不会执行任何类型的深层复制 - 它既不使用 VariantCopy() 也不使用 VariantCopyInd()。因此,如果接收 VARIANT 包含超出方法范围操作的 COM 接口,则接收 VARIANT 会特别危险。此外,如果 ActiveX 函数允许将 COM 对象的间接指针作为参数 - 即(VT_BYREF | VT_DISPATCH)或等效参数,则被引用的对象将使其引用计数由 marshaller 递增(并在函数返回时释放)。因此,如果将 VARIANT 值传递给类型为(VT_BYREF | VT_DISPATCH)的 ActiveX 控件,则如果函数采用 VARIANT,则不会增加其引用计数,但如果函数采用 IDispatch **,则其引用计数会增加(甚至是 IDispatch *)。该算法有点违反直觉,这增加了错误发生的可能性。
3.1.1.2 ActiveX 对象保留攻击 II:释放失败
- 未能释放对象基本上构成内存泄漏。当通过 IUnknown::AddRef() 或 IUnknown::QueryInterface() 引用 COM 接口时会发生这些故障,并且稍后在不调用相应的 IUnknown::Release() 函数的情况下将其丢弃。触发以这种方式操作的代码路径可以允许攻击者消耗任意数量的内存,但更有用的是无限次地增加对象的引用计数。在32位机器上,通过执行易受攻击的代码路径 0xFFFFFFFF 次数,可以在对象的触发器中触发整数溢出引用计数。在此之后,对 IUnknown::Release() 的任何调用都将导致对象被释放,这又会导致过时的指针问题。下代码基于我们之前使用的示例; 但是,它已被修改以证明无法释放对象的问题:
HRESULT CMyObject::put_MyProperty(IDispatch *pCallback)
{
if(pCallback == NULL)
return E_INVALIDARG;
pCallback->AddRef();
m_pCallback = pCallback;
return S_OK;
}
HRESULT CMyObject::get_MyProperty(IDispatch **out)
{
if(out == NULL || *out == NULL || m_pCallback == NULL)
return E_INVALIDARG;
*out = m_pCallback;
return S_OK;
}
- 此示例在设置时正确添加对新回调对象的引用。但是,m_pCallback 中保存的先前值(如果存在)将被覆盖而不会被释放。因此,攻击者可以多次设置此属性,并最终在引用计数变量中触发整数溢出。让我们尝试在以下示例中修复它:
HRESULT CMyObject::put_MyProperty(IDispatch *pCallback)
{
if(pCallback == NULL)
return E_INVALIDARG;
pCallback->AddRef();
if(m_pCallback != NULL)
m_pCallback->Release();
m_pCallback = pCallback;
return S_OK;
}
HRESULT CMyObject::get_MyProperty(IDispatch **out)
{
if(out == NULL || *out == NULL || m_pCallback == NULL)
return E_INVALIDARG;
*out = m_pCallback;
return S_OK;
}
- 上面的示例添加了一个 Release() 调用来正确释放以前保存的任何对象,因此不会发生内存泄漏。精明的读者会注意到这段代码实际上仍然存在陈旧的指针问题。get_MyProperty() 函数不会向正在分发回脚本引擎的接口添加引用。如果插件只保留对该接口的引用,并且插件将其释放,则可能会出现问题。请考虑以下 JavaScript 代码段:
axObject.MyProperty = new Object();
var x = axObject.MyProperty();
axObject.MyProperty = new Object();
- 此JavaScript代码会导致执行以下操作:
1. put_MyProperty保留对我们创建的对象的唯一引用。
2. 'x'变量接收IDispatch指针,但它只有一个副本
3. 设置MyProperty会导致旧对象被删除,即使'x'仍然指向它!
3.1.2 Mozilla 对象保留漏洞
- 与 COM 体系结构相比,NPAPI 具有更简单的对象编组模型。如本文的技术概述部分所述, JavaScript 对象不能直接传递给插件,而是以 NPAPI(NPObject)理解的对象格式包装。回想一下, NPObject 结构有一个引用计数,它由 NPN_RetainObject() 和 NPN_ReleaseObject() 操纵。基于 NPAPI 的浏览器中的对象保留漏洞源于对这两个函数的误用,如下所述:
3.1.2.1 NPAPI 对象保留攻击 I:没有保留
- 与 ActiveX 控件一样,NPAPI 模块需要维护对作为输入参数接收的对象的引用,只要这些对象将被存储很长一段时间。如技术概述中所述,NPObjects 由编组层创建以包装 JavaScript 对象。如果过去某个特定的 JavaScript 对象已被 NPObject 包装,那么将重用相同的 NPObject。 此外,插件可以使用 NPN_CreateObject() 创建 NPObject,然后可以在某个时刻将其传递给用户。在任何一种情况下,如果插件需要维护指向对象的指针,则需要调用 NPN_RetainObject(),将指向相关 NPObject 的指针作为参数传递。如果不这样做,可能会导致插件中存在潜在的过时指针漏洞。 以下代码是使用 NPAPI API 的对象保留漏洞的示例:
boolSetProperty(NPObject *obj, NPIdentifier name, const NPVariant *variant)
{
if(name == kTestIdent)
{
if(!NPVARIANT_IS_OBJECT(*variant))
return false;
gTestObject = NPVARIANT_TO_OBJECT(*variant);
return true;
}
return false;
}
bool GetProperty(NPObject *obj, NPIdentifier name, NPVariant *result)
{
VOID_TO_NPVARIANT(*result)
if(name == kTestIdent)
{
if(!NPVARIANT_IS_OBJECT(*result))
return false;
if(gTestObject == NULL)
NULL_TO_NPVARIANT(*result);
else
OBJECT_TO_NPVARIANT(*result, gTestObject);
return true;
}
return false;
}
- 可以看出,SetProperty() 方法保留了指向对象的指针,但无法调用 NPN_RetainObject()。
恶意用户可以通过执行以下步骤来利用此问题:
1. Create an object of some kind 创建某种对象
2. Set the vulnerable property using that object 使用该对象设置易受攻击的属性
3. Delete the object 删除对象
4. Get the vulnerable property 再次获取属性
3.1.2.2 NPAPI 对象保留攻击 II:发布失败
- 与 ActiveX 控件一样,NPAPI 中也可能出现发布失败问题。当使用 NPN_RetainObject() 保留对象但使用 NPN_ReleaseObject() 从未释放时,会发生这种情况。同样,通过多次触发此代码路径,将有可能溢出引用计数器,从而可能导致过时的指针问题。以下代码是前一个示例的略微修改版本,用于演示此问题:
boolSetProperty(NPObject *obj, NPIdentifier name, const NPVariant *variant)
{
if(name == kTestIdent)
{
if(!NPVARIANT_IS_OBJECT(*variant))
return false;
gTestObject = NPN_RetainObject(NPVARIANT_TO_OBJECT(*variant));
return true;
}
return false;
}
- 在上面的代码中,正在从用户检索的对象上正确调用 NPN_RetainObject()。但是,请注意,永远不会检查 gTestObject 以查看它是否先前已设置过。 之前存储在此处的任何 NPObject 都不会被释放,因此代码包含引用计数泄漏。攻击者可以使用以下步骤利用此机会:
1. Create an NPObject, either by wrapping one particular JavaScript object or by using another
NPObject created by the plugin
通过包装一个特定的JavaScript对象或创建一个NPObject 或通过使用插件创建的另一个 NPObject
2. Create a second reference to the same object by assigning it to more than one variable in
JavaScript (let’s call them objX and objY).
通过将其分配给JavaScript中的多个变量(让我们称之为objX和objY),创建对同一对象的第二个引用
3. Call SetProperty() 0xFFFFFFFF times to take the reference count of the NPObject from 2 to 1
(due to the integer overflow)
调用SetProperty() 0xFFFFFFFF次,将NPObject的引用计数从2增加到1 (由于整数溢出)
4. Delete one of the variables, say, objX. This will take the reference count to 0 and destroy the
NPObject.
删除其中一个变量,比如objX。 这将引用计数为0并销毁NPObject
5. objY will now contain a stale NPObject reference
objY现在将包含一个陈旧的NPObject引用
- 有关引用计数的具体示例是浏览器和平台特定的。但是,这些类型的问题是互操作性复杂性的症状。通常,允许通过引用传递值并允许维护这些引用的互操作性体系结构将经常遇到此问题。因此,对象保留是寻求在提供互操作性的应用程序中查找漏洞的攻击者的肥沃目标。
3.2 互操作性攻击 II:类型混淆漏洞
- 顾名思义,类型混淆漏洞是当一种数据类型被误认为另一种数据类型时发生的漏洞。它们通常是联合数据类型管理不善的结果,但也可能源于类型通配符,并导致攻击者能够从目标应用程序读取敏感数据(即信息泄漏),或者实现意外执行。类型混淆漏洞出现在负责解码以语言无关格式表示的任意类型的复杂对象的软件组件中的可能性更高。这种可能性更高的原因在于,当代码的预期效果是在人为和基本类型之间进行转换时,编译器的错误检查会变得无能为力。漏洞类普遍存在的一些情况包括:
(1) 从持久存储(例如文件)反序列化对象
(2) 从联网应用程序(例如ASN.1编码对象)反序列化对象
(3) 语言绑定层负责在两种语言之间编组数据,这两种语言的本机表示不同
- 本节介绍类型混淆漏洞,它们是如何发生的,以及它们对应用程序安全性的影响。还将讨论用于查找此类漏洞的审计,使用一些流行的 API 作为案例研究,以及作者发现的漏洞的真实世界示例。
3.2.1 基础知识:输入通配符
- 从根本上说,类型混淆漏洞是由一段代码产生的,该代码在存储区域类型的错误假设下对存储区域执行操作。例如,以下代码:
int ReadFromConnection(int sock)
{
unsigned char *Data;
int total_size;
int msg_size;
total_size = 1024;
Data = (unsigned char *)malloc(total_size);
msg_size = recv(sock, &Data, total_size, 0);
return(1);
}
- recv 函数希望能够将 total_size 字节写入 Data 指定的内存区域。但是,在此示例中,代码错误地引用了参数的类型 - 它将指针传递给指向可以容纳 total_size 字节的内存区域的指针。在32位机器上,存储区只能容纳4个字节的数据,导致堆栈溢出。编译器将允许发生此错误,因为 recv 函数指定参数2应为 void * 类型,该类型指定函数将接受指向任何类型的内存的指针,包括指向指针的指针。
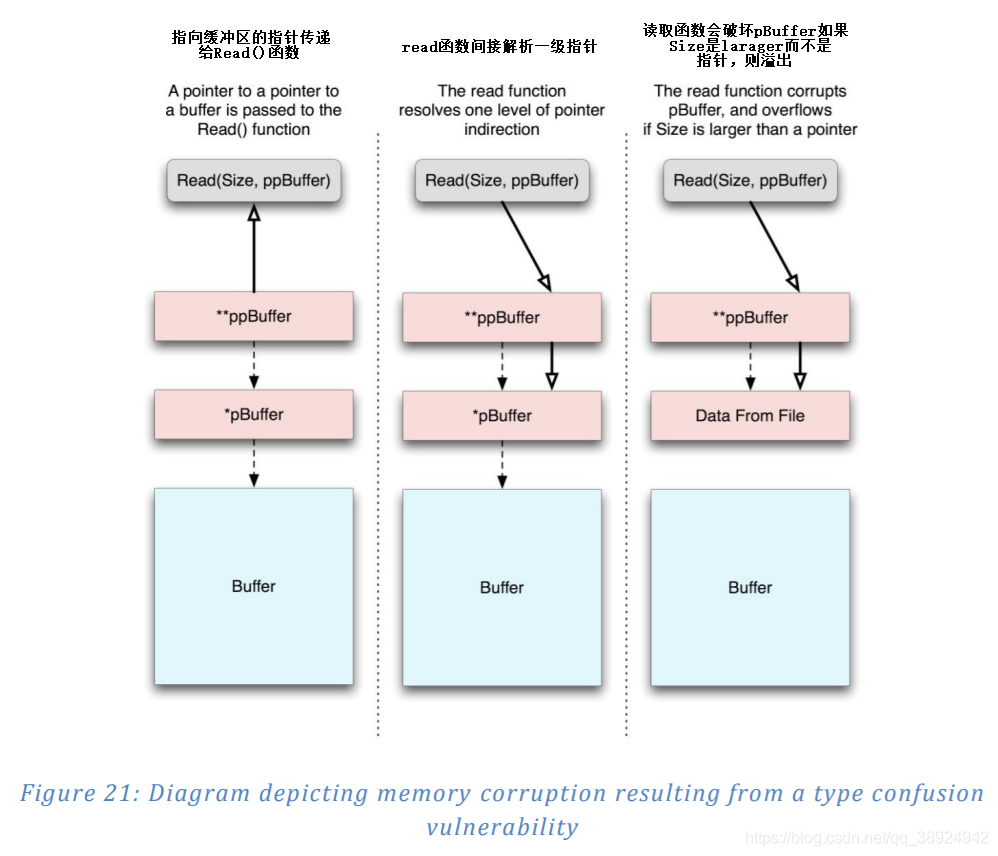
- 其中一位作者(Ryan Smith)在微软内部版本的 ATL 中发现了这种类型的漏洞。从持久流中读取类(VT_ARRAY | VT_UI1)的 VARIANT 时会触发有问题的代码。 以下代码粗略表示易受攻击的功能:
inline HRESULT CComVariant::ReadFromStream(IStream *pStream)
{
…
hr = pStream->Read(&vtRead, sizeof(VARTYPE), NULL);
…
switch(vtRead)
{
case VT_ARRAY|VT_UI1:
SAFEARRAYBOUND rgsaInBounds;
SAFEARRAYBOUND rgsaBounds;
SAFEARRAY *saBytes;
void *pvData;
hr=pStream->Read(&saInBounds, sizeof(saInBounds), NULL);
if(hr<0||hr==1)
return(hr);
rgsaBounds.cElements = rgsaInBounds.cElements;
rgsaBounds.lLbound = 0;
saBytes = SafeArrayCreate(VT_UI1, 1, rgsaBounds);
if(saBytes == NULL)
return(E_OUTOFMEMORY);
hr = SafeArrayAccessData(saBytes, &pvData);
if(hr < ERROR_SUCCESS)
return(hr);
hr=pStream->Read(&pvData, rgsaInBounds.cElements, NULL);
...
}
}
- 上面的代码从 IStream 读取数据,错误地将指针传递给指向目标缓冲区的指针,而不是指向目标缓冲区的指针(也就是说,它传递 &pvData 作为缓冲区参数而不是 pvData)。在 32 位系统上,如果读取的数据量大于 4 个字节,则会发生堆栈损坏。该过程在图21中可视地描绘。鉴于此代码已经存在了很长时间并且已经分布在大量 COM 组件中,很明显类型混淆错误(例如前面的示例)很少受到关注,并且非常微妙。
- 作者评论:在编写此漏洞的示例代码时,作者不小心将错误的值写入 pStream-> Read() 的参数 - 另一种类型的混淆错误! 当在同行评审中发现时,另一位作者纠正了它,提出了不同但同样错误的价值观! 我想这段代码从来都不是安全的。
3.2.2 基础知识:构造 Union
- 正如引言中所提到的,大多数类型的混淆漏洞主要是由于滥用联合数据类型而引起的。 在 C 和 C++ 中,union 数据类型类似于 struct 数据类型 - 它由许多不同名称和类型的成员组成,每个成员都可以单独引用。但是,与 struct 类型不同,union 成员都占用内存中的相同位置,从而使它们的用法互斥。因此,这些类型的存在错误地引用无效的并集的成员的可能性,例如在以下示例中:
struct VariantType
{
union {
char *string_member;
int int_member;
};
};
int Respond(int clientSock, struct VariantType *pVar);
int HandleNetworkMsg(int clientSock);
int Respond(int clientSock, struct VariantType *pVar)
{
int len;
int sentLen;
if(pVar == NULL)
return(0);
len = strlen(pVar->string_member);
sentLen = send(clientSock, pVar->string_member, len+1, 0);
if(sentLen != len+1)
return(0);
return(1);
}
int HandleNetworkMsg(int clientSock)
{
struct VariantType myData;
char inBuf[1024];
int msgSize;
int respCode;
memset(inBuf, 0x00, sizeof(inBuf));
msgSize = recv(clientSock, inBuf, sizeof(inBuf), 0);
if(msgSize < sizeof(int))
return(0);
memcpy(&myData.int_member, inBuf, sizeof(int)); // *
respCode = Respond(clientSock, &myData);
return(respCode);
}
- 从这里可以看出,整数存储在并集 - 即 int_member 中。 随后,访问 string_member 变量,其类型为 char * 。 显然,将整数视为字符串是无效的。 此代码构造将导致存储在 int_member 中的整数被错误地解释为 char *,从而导致应用程序作用于攻击者选择的内存的任意部分,就像它是一个字符串一样。编译器允许此代码在没有警告的情况下进行编译,因为联合类型旨在便于使用不同的基本数据类型访问内存部分,并为程序员提供动力以跟踪哪个联合成员适合在任何给定时访问点。
- 当然,在上面的例子中看到的代码构造在实际的代码中很少发生。但是,当 Union 被指定为值时,Union 的使用者如何知道联合中包含哪些数据类型的数据?答案是他们没有; 没有内在的语言设施确定此信息。 相反,程序员必须外在地指出联合中包含的数据类型。程序员通常利用下面的数据结构来完成这项任务。
struct VariantType
{
unsigned long TypeValueBits;
union {
char *str_member;
int *pint_member;
class *class_member;
unsigned long ulong_member;
};
};
- 此结构具有类型成员 TypeValueBits ,它指示联合中包含的数据类型。实际上,整个 Windows 中普遍存在的 VARIANT 数据类型正是这种格式,稍后将重新讨论。类型混淆漏洞的本质是要么将指示哪个联合成员适合访问的成员与联合中包含的内容进行去同步,要么找到错误解释类型字段的代码。
3.2.3 Microsoft Type 混淆漏洞:VARIANTs
- 正如我们之前在本文的技术概述中看到的那样,VARIANT 数据结构在 Microsoft 代码中被广泛使用,作为表示各种数据类型的标准化,语言无关的方法。用于操作 VARIANT 数据结构的 API 已在本文的概述部分中介绍。我们现在将探讨如何直接或通过定义良好的 API 对 VARIANT 结构的错误管理导致许多微妙的类型混淆场景。
3.2.3.1 VARIANT 类型混淆攻击 I:Permissive 属性映射
- 如前所述, Microsoft 的 ATL 通过为一组接口分发模板代码,帮助开发人员快速开发 COM 组件。 Microsoft 以抽象方式编写了模板代码,允许模板代码在各种情况下使用; 但是,利用一些可用的代码也会产生微妙的后果。具体而言,开发人员使用属性映射指定 COM 对象属性的方式具有一些微妙的细微差别,可能会导致攻击者执行类型混淆攻击的机会。
- 请考虑 Microsoft ATL 版本9中可用的以下宏,这些宏可用于指定属性映射中的各个属性:
struct ATL_PROPMAP_ENTRY
{
LPCOLESTR szDesc;
DISPID dispid;
const CLSID* pclsidPropPage;
const IID* piidDispatch;
DWORD dwOffsetData;
DWORD dwSizeData;
VARTYPE vt;
};
#define PROP_DATA_ENTRY(szDesc, member, vt) \
{OLESTR(szDesc), 0, &CLSID_NULL, NULL, offsetof(_PropMapClass, member), sizeof(((_PropMapClass*)0)->member), vt},
#define PROP_ENTRY(szDesc, dispid, clsid) \
{OLESTR(szDesc), dispid, &clsid, &__uuidof(IDispatch),0, 0, VT_EMPTY},
#define PROP_ENTRY_EX(szDesc, dispid, clsid, iidDispatch) \
{OLESTR(szDesc), dispid, &clsid, &iidDispatch, 0, 0, VT_EMPTY},
#define PROP_ENTRY_TYPE(szDesc, dispid, clsid, vt) \
{OLESTR(szDesc), dispid, &clsid, &__uuidof(IDispatch), 0, 0, vt},
#define PROP_ENTRY_TYPE_EX(szDesc, dispid, clsid, iidDispatch, vt) \
{OLESTR(szDesc), dispid, &clsid, &iidDispatch, 0, 0, vt},
- 值得注意的是,PROP_ENTRY 和 PROP_ENTRY_EX 都不需要参数来指定 VARIANT 类型。回想一下我们之前关于持久性的讨论,当使用这些函数时,持久性流将包含两个字节,用于标识序列化数据之前的序列化类型。一旦被描述的成员被反序列化,ATL 代码将调用属性映射指定的 IDispatch 接口的 put 属性方法,以便将数据写入 COM 对象。总之,利用这些宏提供了一种机会,可以将任何类型的 VARIANT 提供给 IDispatch 接口的 put 方法,而不必强制强制转换为特定的数据类型。如果开发人员没有考虑 put 方法可能提供任意 VARIANT 类型,那么使用这种类型的属性声明可能会导致类型混淆问题。在 Internet Explorer 中未使用的对象中更有可能发现此类漏洞,或者在实现 IDispatch 的接口中,这些接口在属性映射中指定,但无法从 Internet Explorer 访问。
- 开发人员也可以选择使用 PROP_DATA_ENTRY() 而不是 PROP_ENTRY() 。PROP_DATA_ENTRY 宏是唯一的,因为该属性的数据不会被 IDispatch 接口过滤。相反,它直接写入保存属性数据的类内存中的偏移量。如果提供给宏的变量类型是 VT_EMPTY,则持久性代码将读取类中属性可用的字节数。解压缩 PROP_DATA_ENTRY 属性与 PROP_ENTRY 宏的过程如图22所示:
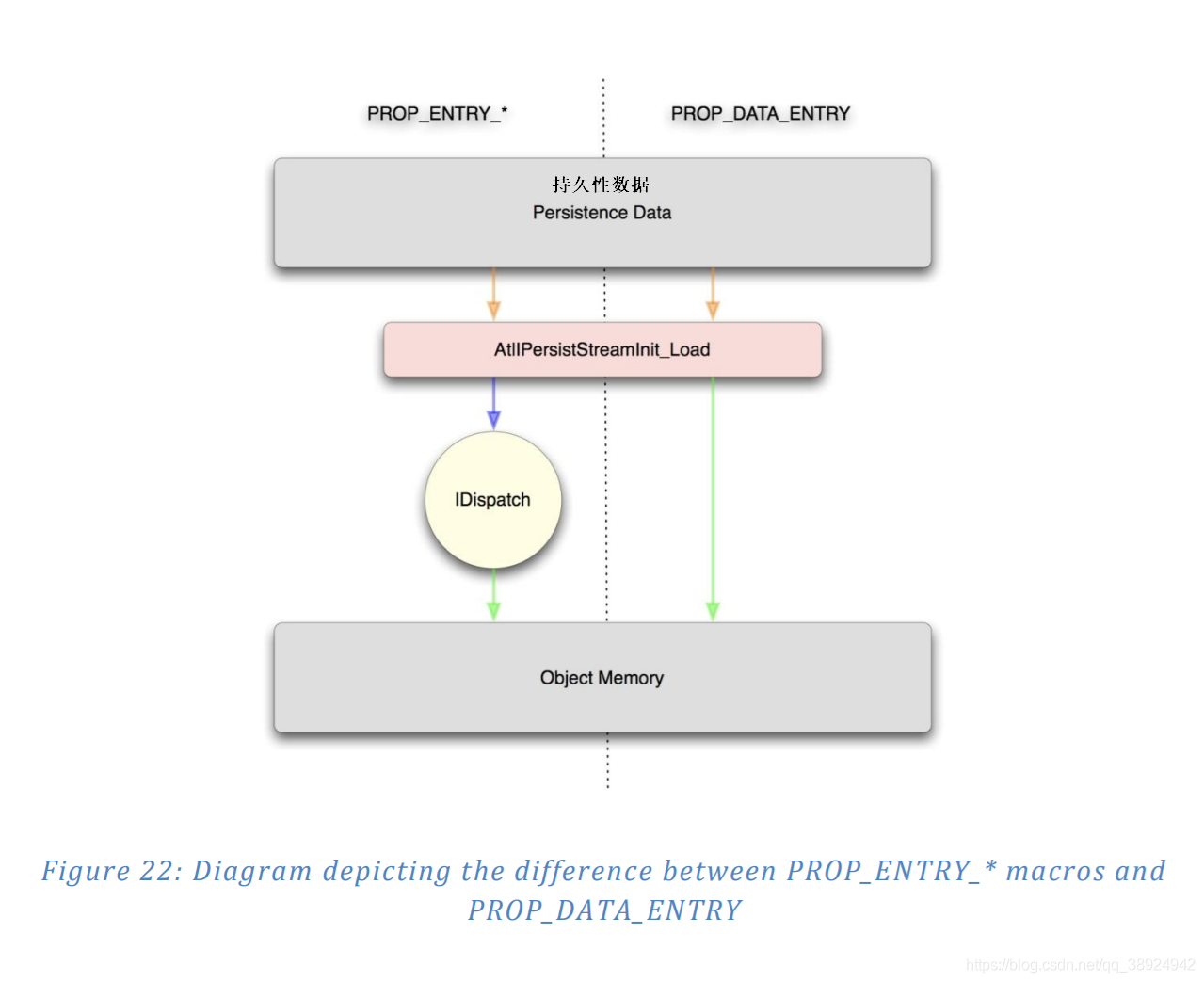
- 因此,使用 PROP_DATA_ENTRY() 宏为攻击者提供了两个有趣的机会:
1. The ability to create a property directly in the destination object’s memory possibly without having any typing requirements
能够直接在目标对象的内存中创建属性,而不需要任何类型要求
2. The ability to provide properties that have undergone absolutely no validation
提供绝对没有验证的属性的能力
- 如果在无类型管理器中指定 PROP_DATA_ENTRY 宏,则这些属性非常危险。如果使用指定为 VT_EMPTY 的类型构造它们,则随后使用此类属性的代码几乎肯定会包含类型混淆漏洞,因为它无法验证它正在操作的数据类型。例如,考虑一种情况,其中 PROP_DATA_ENTRY 属性旨在成为指向字符串或其他更复杂对象的指针。通过指定整数类型而不是预期对象,将触发类型混淆漏洞,最终结果很可能是任意执行。相反,可能存在这样的情况:属性成员应该是整数,但攻击者指定指针(通过指定字符串或其他内容)。此示例类型混淆漏洞很可能会导致信息泄露,并最终泄露指针的值。当试图绕过当代 Windows 操作系统中的内存保护机制时,这些类型的问题变得越来越有用。
- 此外,值得考虑的是 PROP_DATA_ENTRY 属性是直接设置的,因此可以绕过 IDispatch 接口的 put 属性可以强制执行的任何验证级别。这意味着可能存在直接设置这些属性可能在某种程度上绕过检测过程的情况,因为它可能在 put 属性方法中执行。因此,当在以某种方式对其进行检测的脆弱假设下使用该属性时,攻击者有可能利用该对象绕过检测。
3.2.3.2 VARIANT 类型混淆攻击 II:错误解释类型
- 在处理 VARIANT 数据结构时容易出现潜在问题的一个方面是正确解释 vt 成员。与 NPAPI variant 数据结构相反,回想一下 VARIANT 中的类型参数可以是基本类型,也可以是由表示基本类型和修饰符的位组成的复杂类型(或者两个修饰符,如果其中一个是 VT_BYREF)。当错误地执行位掩码时,可能会发生对 vt 成员的错误解释,从而导致细微的漏洞,其中 VARIANT 的值在实际上是另一种时被用作一种类型。
- 为了说明这一点,请考虑以下代码:
#ifndef VT_TYPEMASK
#define VT_TYPEMASK 0xfff
#endif
WXDLLEXPORT bool wxConvertOleToVariant(const VARIANTARG& oleVariant, wxVariant& variant)
{
switch (oleVariant.vt & VT_TYPEMASK)
{
case VT_BSTR:
{
wxString str(wxConvertStringFromOle(oleVariant.bstrVal));
variant = str;
break;
}
…
-
精明的读者会注意到这段代码有一个非常明显的缺陷:使用掩码执行类型检查以获得 VARIANT 的基本类型。在 BSTR 的情况下,字符串被传递复制它的函数。 这里的问题是如果使用修饰符, VARIANT 将不包含 BSTR 作为其值参数。如果此函数的调用者提供类型为(VT_BYREF | VT_BSTR)的 VARIANT,则会导致指向 BSTR 的指针放在 VARIANT 而不是 BSTR 中。(BSTR 实际上是 WCHAR *,其前面有 32 位长度,因此 BSTR * 是 WCHAR **)因此,在传递给此函数的 VARIANT 上使用任何修饰符都会导致类型混淆漏洞。
-
考虑这个稍微更微妙的例子:
SAFEARRAY*psa;
ULONG *pValue
// Test if object is an array of integers
VARTYPE baseType = pVarSrc->vt & VT_TYPEMASK;
if( (baseType != VT_I4 && baseType != VT_UI4) || ((pVarSrc->vt & VT_ARRAY) == 0) )
return -1;
psa = pVarSrc->parray;
// operate on SAFEARRAY
SafeArrayAccessData(psa, &pValues);
...
-
此代码执行一些检查以确保输入类型是有符号或无符号整数的数组。如果不是,则通过返回值 -1 来发出错误信号。但是,此代码中也存在问题 - 检查变量类型时未考虑该类型可以设置 VT_BYREF 位。由于 VT_ARRAY 修饰符与 VT_BYREF 不相互排斥,因此在处理类型为(VT_BYREF | VT_ARRAY | VT_I4)的 VARIANT 时,上述代码存在类型混淆漏洞。在这种情况下,SAFEARRAY** 将被错误地解释为 SAFEARRAY *,导致超出内存访问。
-
以下代码是从 IE(所有当前版本)获取的真实示例。 此示例是 DOM 的核心编组代码的一部分。有问题的代码负责验证从插入 DOM 的脚本主机接收的 VARIANT 参数是否正确,如有必要,将这些参数转换为预期类型。尽管每个 DOM 函数都使用不同类型的参数,但大多数编组例程在其核心使用相同的函数 VARIANTArgToCVar(),该函数接受单个 VARIANT 并尝试将其转换为期望的类型。易受攻击的代码如下所示:
int VARIANTARGToCVar(VARIANT *pSrcVar, int *res, VARTYPE vt, PVOID outVar, IServiceProvider *pProvider, BOOL bAllocString)
{
VARIANT var;
VariantInit(&var);
if(!(vt & VT_BYREF))
{
// Type mismatch - attempt conversion
if( (pSrcVar->vt & (VT_BYREF|VT_TYPEMASK)) != vt && vt != VT_VARIANT)
{
hr = VariantChangeTypeSpecial(&var, pSrcVar, vt, pProvider, 0);
if(FAILED(hr))
return hr;
... more stuff ...
return hr;
}
switch(vt)
{
case VT_I2:
*(PSHORT)outVar = pSrcVar->iVal; break;
case VT_I4:
*(PLONG)outVar = pSrcVar->lVal; break;
case VT_DISPATCH:
*(PDISPATCH)outVar = pSrcVar->pdispVal; break;
... more cases ...
}
}
}
- 有问题的代码尝试检索输入参数 pSrcVar 的值,如果接收的 VARIANT 不是 vt 参数中给出的预期类型,则执行类型转换。将接收到的输入 VARIANT 类型与预期类型进行比较时,会出现此代码中的问题。具体来说,在输入类型掩码为(VT_BYREF | VT_TYPEMASK)或 0x4FFF 之后,通过比较期望的类型和输入类型来完成测试。执行此掩码会丢失重要信息,在本例中为 VT_ARRAY(0x2000)和 VT_VECTOR(0x1000)修饰符。为了说明该问题,请考虑此函数期望 VT_DISPATCH 输入类型(0x0009)并且输入 VARIANT 是 VT_DISPATCH 类型(VT_ARRAY | VT_DISPATCH 0x2009)的数组的情况。由于(0x2009 和 0x4FFF)产生结果 0x0009 或 VT_DISPATCH,因此该代码将错误地认为它接收到 IDispatch 对象而不是 IDispatch 对象数组。结果?此函数表示成功并返回指向 SAFEARRAY 的指针,该指针已错误地评估为指向 IDispatch 接口的指针。因此,此代码最终导致类型混淆漏洞。
- 评估者在使用 VARIANT 类型掩码时对漏洞进行审计时必须密切关注如何操纵 VARIANT 的 vt 成员。 具体来说,掩码输入 VARIANT 类型。
- 需要谨慎执行,以确保在执行任何验证步骤时不会忽略信息。
3.2.3.3 VARIANT 类型混淆攻击 III:直接类型操纵
- 另一种可能导致类型混淆漏洞的构造是直接操纵 VARIANT 的 vt 成员,而不是使用 API 函数。虽然理论上这应该是一项相当简单的任务,但是如果没有正确实施数据类型,或者没有正确确保类型转换成功,则可能会引入微妙的漏洞。例如,以下代码取自 Microsoft 的 ATL 内部版本。从持久性流执行 COM 对象的反序列化时,将调用此代码。请注意,在此特定示例中, VARIANT 数据结构包装在 C++ 对象 CComVariant 中。此代码中的类成员 vt 对应于 VARIANT 结构中的 vt 类型变量。
- 上面列举的例子是人为的; 然而,本文的作者已经确定了发生此类错误的真实场景。Microsoft 的内部版本的 ATL 具有特殊代码来处理持久性流中的 variant,类似于以下示例:
inline HRESULT CComVariant::ReadFromStream(IStream* pStream)
{
ATLASSERT(pStream != NULL);
HRESULT hr;
hr = VariantClear(this);
if (FAILED(hr))
return hr;
VARTYPE vtRead;
hr = pStream->Read(&vtRead, sizeof(VARTYPE), NULL);
if (hr == S_FALSE)
hr = E_FAIL;
if (FAILED(hr))
return hr;
vt = vtRead;
//Attempts to read fixed width data types here
CComBSTR bstrRead;
hr = bstrRead.ReadFromStream(pStream);
if (FAILED(hr))
return hr;
vt = VT_BSTR;
bstrVal = bstrRead.Detach();
if (vtRead != VT_BSTR)
{
hr = ChangeType(vtRead);
vt = vtRead;
}
return hr;
}
- 上述代码的问题是在手动设置 variant 类型之前不会检查 ChangeType() 函数的返回值。此错误允许攻击者使程序相信攻击者提供的 BSTR 值是固定宽度数据类型处理程序中未处理的任何类型。在一种情况下,攻击者可以指定他提供的字符串应被视为 VT_DISPATCH 对象的数组。当此函数返回错误时,调用者将尝试使用 VariantClear() 函数释放该字符串。这最终导致程序将攻击者提供的字符串视为一个 vtable 数组,一个明确的类型混淆错误,最终允许任意代码执行。
3.2.3.4 VARIANT 类型混淆攻击 IV:初始化错误
- 尽管是一个相对简单的操作数据结构,但 VARIANT 在某些情况下由于 API 部分的欺骗性而容易被滥用。在研究本文的 VARIANT 用法时,作者发现的一个关键错误是 VarintInit() 和 VariantClear() 调用的不匹配。正如我们在本文前面提到的,VariantInit() 函数用于通过将 vt 成员设置为 VT_EMPTY 来初始化 VARIANT 结构。相反,VariantClear() 将释放与 VARIANT 相关的数据,同时考虑存储在那里的数据类型。随后它将 VARIANT 的类型值设置为 VT_EMPTY。
- 这里需要注意的重要一点是,在 VARIANT 上调用 VariantClear() 时尚未正确初始化的任何代码路径都可能导致潜在的安全问题。为什么?因为 VariantClear() 将读取 VARIANT 的未初始化的 vt 成员,并使用它来决定如何操作未初始化的 VARIANT 值。例如,如果 vt 成员是 VT_DISPATCH (0x0009),VariantClear() 将从 VARIANT 获取数据成员并取消引用它以进行间接调用,因为删除 IDispatch 对象的过程涉及调用 IDispatch::Release() 功能。VariantInit() 函数的省略创建了一个条件,与没有先分配它的释放内存块的内存管理模拟不同,有两个主要区别:
1.Double VariantClear() 与 double free()不同 - 由于 VariantClear() 将 VARIANT 类型设置为 VT_EMPTY,因此对同一 VARIANT 的 VariantClear() 的任何后续调用都将无效
2. 没有 malloc(),VariantInit() 的省略比 free() 更有可能,因为代码在大多数情况下仍然看似正常工作,即使行使了易受攻击的代码
- 这类错误实际上是一个未初始化的变量问题,但是包含在本节中,因为它会导致类型混淆的形式,另外需要注意的是攻击者需要使用有用的数据来填充适当的内存区域,而不是直接指定它。也就是说,这些问题的可利用性非常依赖于分配 VARIANT 的存储器中包含的残留数据。在某些情况下,此数据受攻击者控制,而在其他情况下,攻击者需要一些运气。
- VariantInit() 遗漏漏洞的示例如下所示:
HRESULTMyFunc(IStream* pStream)
{
VARIANT var;
IDispatch* pDisp;
HRESULT hr;
var.vt = VT_DISPATCH;
hr = pStream->Read(pDisp, sizeof(IDispatch *), NULL);
if(FAILED(hr)) {
VariantClear(&var);
return hr;
}
. . .
return hr;
}
- 可以看出,位于堆栈上的 VARIANT 是使用 VT_DISPATCH 类型手动初始化的,并且可能在从源流中成功读取数据后填充了指向 IDispatch 接口的指针。但是,如果 IStream::Read() 操作失败,则清除 VARIANT,导致操作未初始化的堆栈数据,就像它指向 IDispatch 接口一样。
- 尽管这似乎是一个相对不太可能的错误,但有时候易受攻击的代码路径的变化会稍微微妙一些。使用 VariantCopy() 函数在 VARIANT 之间复制数据时会出现一个这样的示例。VariantCopy() 函数在复制任何内容之前清除目标 VARIANT 参数。因此,必须首先清除传递给 VariantCopy() 的目标参数。下面的代码演示了一个易受攻击的情况,其具有与前一个示例相同的可利用性限制:
HRESULTMyFunc(IStream* pStream)
{
VARIANT srcVar;
VARIANT dstVar;
IDispatch* pDisp;
HRESULT hr;
srcVar.vt = VT_DISPATCH;
dstVar.vt = VT_DISPATCH;
hr = pStream->Read(pDisp, sizeof(IDispatch *), NULL);
if(FAILED(hr)) {
//VariantClear(&var);
return hr;
}
else {
srcVar.pdispVal = pDisp;
hr = VariantCopy(&dstVar, &srcVar);
}
return hr;
}
- 其他 VARIANT API 函数中也存在类似问题,最值得注意的是 VariantChangeType() / VariantChangeTypeEx() 函数。这些函数将在一些但不是所有转换情况下使用 VariantClear()。在目标值上调用 VariantClear() 的规则在很大程度上是直观的; 它们发生在:
- 未遇到无效的转换尝试(即,不在两个不兼容的类型之间进行转换),并且当源和目标 VARIANT 相同时,VariantClear() 不会导致问题,例如从 VT_UNKNOWN - > VT_DISPATCH 的转换
- 在审核漏洞方面,应该严格查看目标参数未初始化的任何转换。例如,请考虑以下代码:
BSTR*ExtractStringFromVariant(VARIANT *var)
{
VARIANT dstVar;
HRESULT hr;
BSTR *res;
if(var->vt == VT_BSTR)
return SysAllocString(var->bstrVal);
else {
hr = VariantChangeType(&dstVar, var, 0, VT_BSTR);
if(FAILED(hr))
return NULL;
}
res = SysAllocString(dstVar.bstrVal);
VariantClear(&dstVar);
return res;
}
- 这里我们看到与前面示例类似的构造,除了这次使用 VariantChangeType()。存在以下开发要求:
1.目的地变量未被初始化
2.从常规类型到VT_BSTR的转换将导致目标 VARIANT 上的 VariantClear() (例如 VT_I4 -> VT_BSTR)
- 如前所述,成功利用上述漏洞需要攻击者能够影响堆栈,以便未初始化的目标 VARIANT 中包含有用数据,例如具有 VT_DISPATCH 类型和某种有效指针作为值。
3.2.4 Mozilla 类型混淆漏洞:NPAPI
- 大多数非IE浏览器为插件交互实现 NPAPI,后者又利用 NPRuntime 将脚本化对象暴露给脚本语言。用于向插件传递变量和从插件传递变量的 API 比 COM 和 IE 使用的 API 简单得多,从而减少了攻击面。然而,NPRuntime 仍然为攻击者提供了有趣的机会,因为它会导致滥用,导致类型混乱漏洞类似于我们在 VARIANT 中看到的漏洞。本节探讨如何在 NPRuntime 脚本化对象的上下文中发生类型混淆漏洞。此讨论适用于实现 NPAPI 并将 NPRuntime 功能公开给 Web 内容的所有浏览器。
3.2.4.1 NPAPI 类型混淆攻击 I:类型验证
- 我们已经看过的 NPRuntime 和 COM VARIANT 传递之间的主要区别之一是 NPRuntime 不对从脚本主机收到的 NPVariant 执行任何类型强制或验证。回想一下我们之前对 NPRuntime 的讨论,插件如何访问 NPVariant; 通过使用 NPVARIANT_TO_XXX() 宏之一。这些宏除了访问 NPVariant 中包含的 union 数据结构的成员之外什么都不做 - 插件开发人员有责任通过使用相应的 NPVARIANT_IS_XXX() 宏来确保 variant 的类型正确。正确处理 NPVariant 参数的插件可能如下所示:
boolSetProperty(NPObject *obj, NPIdentifier name, const NPVariant *variant)
{
if(name == kTestIdent)
{
if(!NPVARIANT_IS_INT32(*variant))
return false;
gTest = NPVARIANT_TO_INT32(*variant);
return true;
}
return false;
}
- 此示例是操作 NPVariants 的预期算法 - 检查正确的类型,然后检查数据。每次函数接收 NPVariant 时,必须在处理其数据之前执行此类型检查。缺少初始检查会使代码容易出现类型混淆问题。为了说明未能执行初始检查的问题,请考虑以下从 Google 的 "Native Client” 插件中获取的代码:
bool Plugin::SetProperty(NPObject* obj, NPIdentifier name, const NPVariant* variant)
{
Plugin* plugin = reinterpret_cast<Plugin*>(obj);
if (kHeightIdent == name) {
plugin->height_ = NPVARIANT_TO_INT32(*variant);
return true;
- 此函数设置有问题对象的 “height” 属性,但无法确保被操作的 NPVariant 是整数。攻击者可能会传递一个字符串或对象 in 作为 height 参数而不是整数,导致指针混淆为整数。此代码很可能导致信息泄露漏洞,当攻击者稍后读回高度属性时,漏洞会泄露指针。显然,相反的情况可能更危险 - 攻击者可以提供一个整数来代替指针。根据指针的操作方式,这种情况可能导致更广泛的信息泄漏或内存损坏漏洞。
- 此攻击的一个稍微微妙的变化是 NPVariant 被验证为 NPObject,并且插件尝试将通用 NPObject 强制转换为特定类型的对象。NPAPI 运行时缺少 API 函数,允许您确定执行此对象转换是否安全,因此此构造几乎总是有助于利用。 返回 Native Client,请考虑以下代码:
static bool GetHandle(struct NaClDesc** v, NPVariant var) {
if (NPVARIANT_IS_OBJECT(var)) {
NPObject* obj = NPVARIANT_TO_OBJECT(var);
UnknownHandle* handle = reinterpret_cast<UnknownHandle*>(obj);
*v = handle->desc();
return true;
} else {
return false;
}
}
- 此代码负责从 JavaScript 接收“句柄”对象。句柄对象是可编写脚本的对象的特定专用,由 Native Client 实现,用于与其后端进行通信。代码使用 NPVARIANT_IS_OBJECT() 宏正确验证收到的 NPVariant 确实是一个 JavaScript 对象。但是,他们随后将收到的 NPObject 指针强制转换为 UnknownHandle 指针。由于攻击者可能在此处提供任意 JavaScript 对象,因此可以执行类型混淆攻击,其中任何随机 NPObject 与 UnknownHandle 对象混淆。这种类型混淆漏洞的最可能结果是任意代码执行。
- 这里值得一提的是,NPObject 函数的输入不一定是提供可能错误类型对象的唯一方法。如技术概述中所述,NPN_GetProperty() 函数用于从 DOM 层次结构中检索对象。由于这些对象受脚本控制,因此操纵 DOM 中可见的对象可以是执行与此处描述的类似攻击的入口点。
3.2.4.2 NPAPI 类型混淆攻击 II:参数计数验证
- NPObject 公开的 Invoke() 和 InvokeDefault() 方法需要根据 NPIdentifier 参数标识的方法的正确数量和类型参数来验证传递给它们的参数的数量和类型。对于这两个函数,只需确保 argc 参数包含正确的值即可验证参数的数量。虽然这是一个不太常见的错误,但插件开发人员需要验证 Invoke() 和 InvokeDefault() 中每个可调用函数的 argc 参数 - 它不会自动验证。无法验证它可能导致无效数组索引用于检索参数参数的情况。一些易受攻击的示例代码如下所示:
boolInvoke(NPObject *obj, NPIdentifier name, const NPVariant *args, uint32_targCount, NPVariant *result)
{
if(name == kTestFuncName)
{
if(argCount != 2 && (!NPVARIANT_IS_INT32(args[0]) || !NPVARIANT_IS_STRING(args[1])))
return false;
unsigned int length = NPVARIANT_TO_INT32(args[0]);
char *buffer = ExtractString(args[1]);
... more code ...
}
}
- 上面的代码是出于好意 - 它试图检查参数计数以及每个参数的类型。但是,检查中存在一个问题:逻辑and(&&)运算符用于逻辑 OR(||)应该在的位置。这样,可以通过验证并使用与预期数量不同的多个参数执行处理代码。如果只传递一个参数,则对于args数组的第二个元素的任何操作,将访问越界内存。
- 前面的代码构造导致使用未初始化的变量,并且可以认为它更适当地归类为未初始化的变量问题; 然而,这种错误行为源于 NPVariant 参数与原生变量类型相比的相对模糊性。因此,它包含在本节中,因为它源于类型歧义,并且因为此问题的语义类似于上一节中描述的语义。
3.3 互操作性攻击 III:信任可执行模块
- 互操作性对执行环境提出了独特的要求。首先,应用程序需要确保它实例化的组件符合应用程序的安全要求。确保这一事实很困难,因为为互操作性而编写的组件不需要特定的环境; 因此,他们很大程度上不了解可能需要的任何环境特定的安全标准。实际上,在回顾微软围绕 COM 的安全性时,很容易形成脆弱的安全架构由于复杂性的结果。
- 进一步复杂化该问题的事实是互操作性组件可能需要使用一个或多个子组件。假设应用程序有一种方法可以完全确保互操作性组件在应用程序的上下文中运行是安全的,那么应用程序可能仍然完全不知道经过审查的组件将哪些子组件带入执行环境。应用程序环境或父组件必须负责确保子组件对于执行环境是可信的。
- 可传递信任是我们用来表示组件能够将主机应用程序授予的信任扩展到组件可能依赖的对象的条件的一个术语,由组件自行决定。 在Web浏览器的上下文中,实践中使用的授权模型是平坦的;也就是说,只有父组件经过主机应用程序的显式授权检查。图23描绘了一个示例信任链:
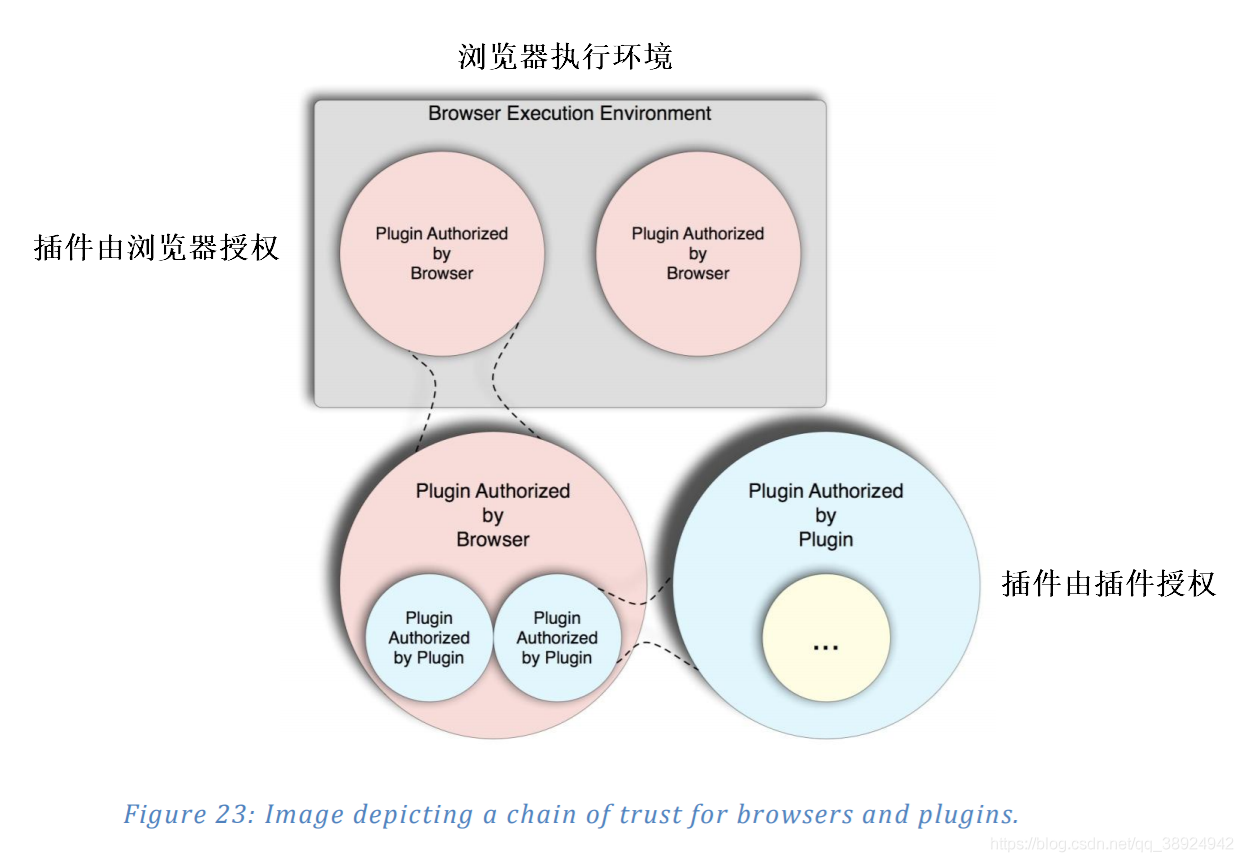
- 如图所示,强制执行安全模型的动力完全放在父组件上。父对象可能依赖于子对象的这种模型创建了一个信任链,其中链中的每个链接都由来自不同代码库的对象验证,使用可能不同的策略,可能拥有他们继承的信任模型的有限概念。因此,他们可能无法以完全保真的方式强制执行该模型。此外,随着时间的推移添加到主机应用程序中的改装安全功能通常会被最初设计为不符合新限制的插件或组件破坏。因此,创造性地利用插件功能的攻击者通常可以方便地绕过新的安全功能。本节将介绍作者发现的一些属于可传递信任类别的攻击 - 利用插件或组件功能来破坏内置于 Web 浏览器的安全功能。
3.3.1 传递信任漏洞 I - 持久化对象
- 本文已经详细讨论了持久 COM 对象的实现和使用,以及它们在安全性方面提出的一些挑战。除了已经讨论过的问题之外,持久对象还为攻击者提供了使对象加载属性值的能力,有时甚至是任意类型的值。以下部分将探讨此功能对传递信任漏洞的影响,最终概述绕过 Internet Explorer 依赖的安全功能以安全传递 Web 内容的方法。
3.3.1.1 传递信任漏洞: 绕过控制授权(Highlander Bit)
- 正如本文第二部分所讨论的,IE 实现了各种控件来限制可以在浏览器的上下文中实例化哪些 ActiveX 对象,以及在控件被授权用于浏览器上下文之前用户呈现的警告类型。正如我们之前所描述的,对于在 Internet Explorer 的执行环境中被认为是安全加载的对象,需要将其标记为安全的脚本和/或安全的初始化,不能设置有问题的对象的 killbit,最后 ,必须批准控件在域中运行。
- 首次安装 Internet Explorer 时会填充预先批准的列表,并且此列表的任何其他更改都将来自用户自定义。此列表限制了攻击者在没有 Internet Explorer 通知目标内容可能会破坏浏览器安全性的情况下可以利用的控制数量。此外,Microsoft 一直在分发累积 killbit 设置作为其每月安全捆绑包的一部分,以确保在 IE 的上下文中无法加载大量可利用的控件。实际上,在几个实例中,Microsoft 选择通过添加 killbits 来禁用控件,而不是在发现它们时尝试修复底层漏洞。 很容易看出,从攻击者的角度来看,绕过这些授权是非常可取的,而对象持久性有助于实现这一目标。
- 在典型的Windows机器上有几个可用的控件,可以在不提示用户的情况下进行初始化。由于大多数自动化控件使用 IPersistStream 的默认 ATL 实现来将对象复活到内存中,因此我们将考虑此实现中的 Load() 方法。 恢复对象的大部分工作实际上是由 CComVariant::ReadFromStream() 执行的,其实现部分显示:
HRESULTVariantCopy(VARIANTARG *pvargDest, VARIANTARG *pvargSrc);
HRESULT VariantCopyInd(VARIANTARG *pvargDest, VARIANTARG *pvargSrc);
inline HRESULT CComVariant::ReadFromStream(IStream* pStream)
{
ATLASSERT(pStream != NULL);
if(pStream == NULL)
return E_INVALIDARG;
HRESULT hr;
hr = VariantClear(this);
if (FAILED(hr))
return hr;
VARTYPE vtRead = VT_EMPTY;
ULONG cbRead = 0;
hr = pStream->Read(&vtRead, sizeof(VARTYPE), &cbRead);
if (hr == S_FALSE || (cbRead != sizeof(VARTYPE) && hr == S_OK))
hr = E_FAIL;
if (FAILED(hr))
return hr;
vt = vtRead;
cbRead = 0;
switch (vtRead)
{
case VT_UNKNOWN:
case VT_DISPATCH:
{
punkVal = NULL;
hr = OleLoadFromStream(pStream, (vtRead == VT_UNKNOWN) ? __uuidof(IUnknown) : __uuidof(IDispatch), (void**)&punkVal);
// If IPictureDisp or IFontDisp property is not set,
// OleLoadFromStream() will
// return REGDB_E_CLASSNOTREG.
if (hr == REGDB_E_CLASSNOTREG)
hr = S_OK;
return hr;
}
case VT_UI1:
case VT_I1: cbRead = sizeof(BYTE); break;
... more object types ...
default:
break;
}
... more code ...
}
- 通过查看上面的代码可以看出,当读取 VT_DISPATCH 或 VT_UNKNOWN 对象时,IStream 将传递给 OleLoadFromStream() 以将下级对象读入内存。从 ole32.dll 导出的 OleLoadFromStream() 的伪代码如下所示:
HRESULT __stdcallOleLoadFromStream(LPSTREAM pStm, const IID *const iidInterface, LPVOID *ppvObj)
{
IPersistStream *pIPersistStream;
IUnknown *pIUnknown;
CLSID clsidControl;
HRESULT hrValue;
*ppbObj = NULL;
hrValue = ReadClassStm(pStm, &clsidControl);
if(hrValue != ERROR_SUCCESS)
return(hrValue);
hrValue = CoCreateInstance(&clsidControl, NULL, CLSCTX_INPROC_SERVER | CLSCTX_LOCAL_SERVER | CLSCTX_REMOTE_SERVER | CLSCTX_NO_CODE_DOWNLOAD, iidInterface, &pIUnknown);
if(hrValue != ERROR_SUCCESS)
return(hrValue);
hrValue = pIUnknown->QueryInterface(CLSID_IPersistStream, &pIPersistStream);
if(hrValue != ERROR_SUCCESS)
goto CleanupIUnknown;
hrValue = pIPersistStream->Load(pStm);
pIPersistStream->Release();
if(hrValue != ERROR_SUCCESS)
goto CleanupIUnknown;
hrValue = pIUnknown->QueryInterface(iidInterface, ppvObj);
CleanupIUnknown:
pIUnknown->Release();
return(hrValue);
}
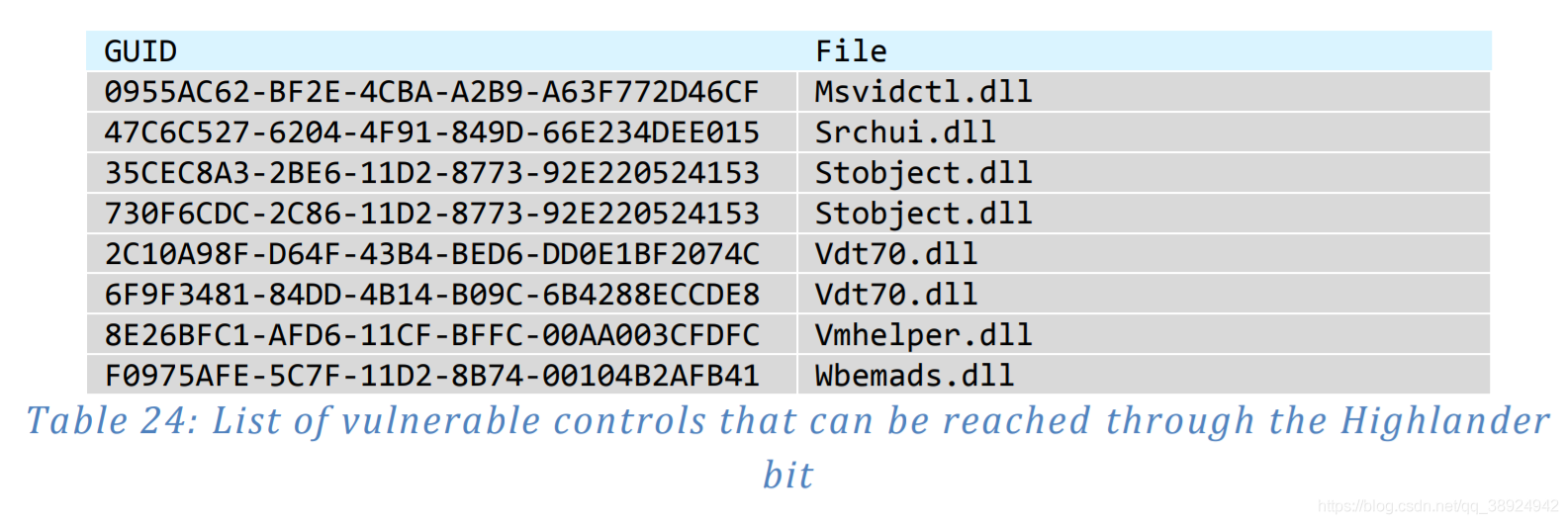
- 如上所示,OleLoadFromStream() 函数将使用 IStream 中提供的 CLSID 调用 CoCreateInstance(),然后使用持久性数据初始化控件。如果攻击者能够提供此持久性数据,那么他们可以使用此代码加载任意 COM 对象并为该对象提供持久性数据。最重要的是,没有功能可以确定从属控件是否满足主机应用程序的安全要求 - 包括控件的 killbit 状态,以及可能请求用户批准的任何逻辑。应该注意的是,在撰写本文时,使用此方法似乎只提供对从持久性数据加载的控件的 IPersistStream 接口中的 Load() 方法的访问。但是,此功能完全足以提供一个不受安全限制影响的向量,允许访问持久性例程中存在的漏洞以及许多以前公开的漏洞。表24列出了一小部分控件,这些控件可以到达并且已报告仅在对象实例化时触发漏洞,或者通过处理持久性数据。
- 从随 Visual Studio 97 一起发布的 ATL 第2版(包括 ATL 8.0 版)开始,与 Visual Studio 2005 一起分发,没有任何机制可以对从任何宏的流中读取的属性类型进行粒度控制。不同于 PROP_DATA_ENTRY ;因此,从流中读取的控件的大多数属性可以读作 VT_DISPATCH 或 VT_UNKNOWN variant 。在与 Visual Studio 2008 一起分发的 ATL 9.0 版中,未声明类型的属性条目宏被声明为不推荐使用,CComVariant::ReadFromStream() 要求从流中读取的类型等同于宏中指定的类型,除非类型指定等于 VT_EMPTY。但是,若干第三方控件(最值得注意的是 Macromedia 的 Flash 控件)具有指定 VT_DISPATCH 类型的属性条目,并且仍将允许此向量。此外,实现自定义 Load() 方法的几个 Microsoft 控件也为攻击者提供了加载任意对象的能力。以下示例代码是 Microsoft 的 ComponentTypes 控件的 IPersistStream 实现的一部分。
HRESULT __stdcall CComponentTypes::Load(struct IStream *pStm)
{
HRESULT hrVal;
ULONG ulRead;
long lCntComponents;
long lIndexComponent;
hrVal = pStm->Read(&lCntComponents, sizeof(lCntComponents), &ulRead);
if(hrVal < ERROR_SUCCESS)
return(hrVal);
if(ulRead != sizeof(lCntComponents))
return(E_UNEXPECTED);
for( lIndexComponent = 0; lIndexComponent < lCntComponents; lIndexComponent++)
{
GUID2 ReadGuid;
hrVal = pStm->Read(&ReadGuid, sizeof(ReadGuid), &ulRead);
if(hrVal < ERROR_SUCCESS)
return(hrVal);
CComQIPtr <IPropertyBag, &__s_GUID const_GUID_55272a00_42cb_11ce_8135_00aa004bb851> myControl;
hrVal = CoCreateInstance(&ReadGuid, NULL, CLSCTX_INPROC_SERVER| CLSCTX_INPROC_HANDLER, IID_IPersistStreamInit, &myControl);
if(hrVal < ERROR_SUCCESS)
return(hrVal);
hrVal = myControl.Load(pStm);
if(hrVal < ERROR_SUCCESS)
return(hrVal);
...
- 代码读取一个整数,指定流中的控件数。 接下来,它将读入类ID并尝试从持久流加载控件。它将重复最后一步,直到遇到错误,或者它已经读取了许多等于流中第一个整数值的控件。 同样,攻击者可以指定此控件从中读取的流,并且控件在使用攻击者提供的持久性数据加载之前不会对此控件执行任何授权检查。
第四节:结论
-
互操作性为应用程序提供了利用可插拔组件提供更高灵活性的优势。然而,从安全角度来看,这种灵活性的成本在很大程度上经常被忽视。我们提出了针对互操作性功能本身的攻击 - 从跨模块边界的数据对象的编组和管理到利用对插件或核心组件的信任扩展。此外,我们已经证明,这些区域更容易受到影响,过去已经收到适度或没有真正关注的独特错误类。希望针对使用互操作性在不相关组件之间进行通信的应用程序的攻击者可以使用此类技术来发现数据操作代码中的细微缺陷,或者通过利用宽松的信任边界来破坏旨在阻止安全漏洞的反措施。对互操作性的进一步研究可能会产生进一步独特的开发方案,特别是在传递信任领域。这是由于安全障碍以及不断添加到 Web 应用程序等丰富应用程序的新组件。
-
Sun, Java and JavaScript is a trademark of Sun Microsystems, Inc. in the United States and other countries.
-
Adobe, Flash, and ActionScript are trademarks of Adobe Systems Incorporated in the United States and/or other countries.
-
Macromedia is a trademark of Marcomedia, Inc in the United States and/or other countries.
-
Microsoft, Windows, Windows Vista, ActiveX, Silverlight, Microsoft Media Player, Visual Studio, VBScript, and Internet Explorer are trademarks of the Microsoft Corporation in the United States and other countries.
-
Mozilla and Firefox are trademarks of the Mozilla Foundation in the United States and other countries.
-
Google and Google Chrome are trademarks of Google, Inc in the United States and other countries.
-
CERT is a trademark of Carnegie Mellon University in the United States and other countries.
-
Apple and Safari are trademarks of Apple, Inc. in the United States and other countries.
-
Opera is a trademark of Opera Software ASA in the United States and other countries.
-
Netscape is a trademark of AOL, Inc. in the United States and other countries.
- 本文的翻译到此结束,鉴于本文信息量庞大,所以难免翻译会出现错误,如有错误,欢迎指正
- 由于本研究报告种类为计算机类型,所以有一些专业术语可能会难以理解,日后会加以修改并逐渐完善














 250
250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









