







之前一直觉得正则表达式很神秘,工作中有时候也会用到正则,但是对它的用法不是很了解,只是单纯的从网上找人家写好的粘贴复制,能用就行,但是现在感觉还是必须要了解一下基础语法, 这样自己也可以尝试着写一些正则表达式,最近在网上搜索基础教程,在此做一下笔记,方便以后查看。
相信用过正则表达式的人都知道,正则表达式的主要目的是按照某种规则去匹配符合条件的字符串,然后简化代码操作。
| 代码 | 说明 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线或汉字 |
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \b | 匹配单词的开始或结束 |
| ^ | 匹配行的开始 |
| $ | 匹配行的结束 |
| 代码 | 说明 |
|---|---|
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
拿一些简单的例子来说
例1、一个判断邮箱的正则表达式,我们可以这么写:
^([a-zA-Z0-9_-])+@([a-zA-Z0-9_-])+((\.[a-zA-Z0-9_-]{2,3}){1,2})$
我们先来分析一下语法格式:
^代表开头,
()代表分组,
[]代表取里面的任意字符,
\.代表转义,转义为. 因为.在正则表达式代表任意字符,
{}代表范围,例如{3}取3个,{2,3}取2到3个,
$代表结尾例子2 This is a good dog,在这里面我们直想替换 is,不替换This中的is,就需要用到元字符/b
匹配is
\bis\b \b是单词边界\b是正则表达式规定的一个元字符,代表着单词的开头或结尾,就是单词的分界处。
js正则表达式方法
1、test方法的返回值是boolean型,用于测试字符串中是否存在匹配正则表达式的字符串,存在返回true,否则返回false
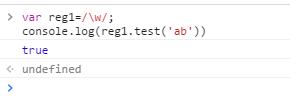
上述正则表达式没有加上全局标识g,只是单纯的判断字符串中是否含有单词字符;
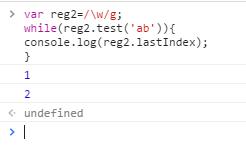
但是加上全局标识后,每次执行test之后会把结果作用到正则表达式本身上,每次匹配不是从头开始的,每次执行之后把结果记住,继续往后面走,如果lastIndex取不到值时,会吧lastIndex重置为0从头开始(lastIndex当前匹配结果的最后一个字符的下一个字符的位置)
2、exec方法:RegExp.prototype.exec(str)
Exec方法:通过对指定你的字符串进行一次匹配检测,获取字符串中的第一个与正则表达式的内容,并将更新全局RegExp对象的属性以反应结果,如果没有匹配的文本返回null,否则将匹配的内容和子匹配的结果存放在返回数组中
数组有两个额外的属性:
Index 声明匹配文本的第一个字符的位置:
不加g标识进行非全局匹配,返回数组:
第一个元素是与正则表达式匹配的文本
第二个元素是与RegExpObject的第一个子表达式相匹配的文本(如果存在的话)
第三个元素是与RegExp对象的第二个子表达式想匹配的文本(如果有的话),以此类推
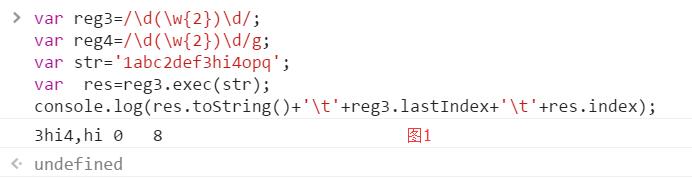
图1中只有一个分组,即只有一个子表达式,因此数组中的第一个元素是3hi4,第二个元素是hi

图2中有两个分组,即有两个个子表达式,因此数组中的第一个元素是3hi4,第二个元素是h,第三个元素是i
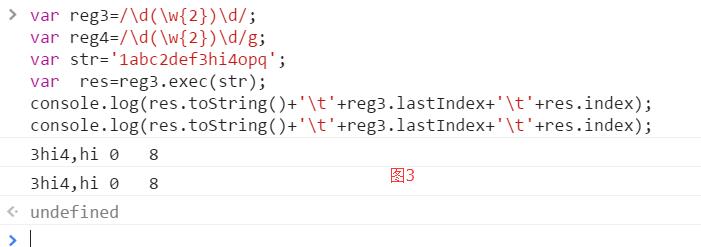
而图三中执行两次lastIndex一直为0,是因为忽略了lastIndex,正则表达式的lastIndex每次都是0















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









