








1. 使用DSL查询文档
1.1 主要的查询类型
类似于SQL语句,在ES中使用DSL语句来定义查询。主要的查询类型包括
- 查询所有数据。
match_all - 全文搜索查询:利用分词器对用户输入进行分词,然后去倒排索引库中匹配。
match_query,multi-match-query - 精确查找,根据词条紧缺查找,一般查询的是keyword,数值,日期,bool查询等。主要由
range,term - 地理位置查询。包括查找距离指定位置指定距离的所有文档
geo_distance, 和查询某一个范围内的所有文档geo_bounding_box - 符合查询,多个条件的组合查询
bool,和基于自定义算分函数查询function_score
1.2 全文检索查询
全文搜索命令分为了match_all, match, mutli_match三种。
全文搜索的基本流程如下:
- 对用户输入的搜索内容进行分词,得到词条。
- 根据词条到倒排索引中取匹配,得到文档ID
- 根据文档ID查找文档,返回给用户
比较常见的场景如:商城的搜索输入框,Google的搜索框等

查询的语法基本一致:
GET /indexName/_search
{
"query": {
"查询类型": {
"查询条件": "条件值"
}
}
}
1.2.1 查询所有文档 (match_all)
- 查询类型为match_all
- 没有查询条件
// 查询所有
GET /indexName/_search
{
"query": {
"match_all": {
}
}
}
其它查询无非就是查询类型、查询条件的变化。
例如查询所有酒店信息
GET /hotel/_search
{
"query": {
"match_all": {}
}
}
注意,ES默认只显示查找结果的前10条文档,后续可以通过指定
from和end设置
1.2.2 单字段查询(match)
match查询语法如下:
GET /indexName/_search
{
"query": {
"match": {
"FIELD": "TEXT"
}
}
}
例如查找外滩的如家
GET /hotel/_search
{
"query": {
"match": {
"name": "外滩如家"
}
}
}
"hits" : [
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "434082",
"_score" : 4.620212,
"_source" : {
"address" : "复兴东路260号",
"brand" : "如家",
"business" : "豫园地区",
"city" : "上海",
"id" : 434082,
"location" : "31.220706, 121.498769",
"name" : "如家酒店·neo(上海外滩城隍庙小南门地铁站店)",
"pic" : "https://m.tuniucdn.com/fb2/t1/G6/M00/52/B6/Cii-U13eXLGIdHFzAAIG-5cEwDEAAGRfQNNIV0AAgcT627_w200_h200_c1_t0.jpg",
"price" : 392,
"score" : 44,
"starName" : "二钻"
}
},
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "60487",
"_score" : 4.42869,
"_source" : {
"address" : "黄浦路199号",
"brand" : "君悦",
"business" : "外滩地区",
"city" : "上海",
"id" : 60487,
"location" : "31.245409, 121.492969",
"name" : "上海外滩茂悦大酒店",
"pic" : "https://m.tuniucdn.com/fb3/s1/2n9c/2Swp2h1fdj9zCUKsk63BQvVgKLTo_w200_h200_c1_t0.jpg",
"price" : 689,
"score" : 44,
"starName" : "五星级"
}
},
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "432335",
"_score" : 2.9392586,
"_source" : {
"address" : "唐山路145号",
"brand" : "7天酒店",
"business" : "北外滩地区",
"city" : "上海",
"id" : 432335,
"location" : "31.252585, 121.498753",
"name" : "7天连锁酒店(上海北外滩国际客运中心地铁站店)",
"pic" : "https://m2.tuniucdn.com/filebroker/cdn/res/c1/ba/c1baf64418437c56617f89840c6411ef_w200_h200_c1_t0.jpg",
"price" : 249,
"score" : 35,
"starName" : "二钻"
}
},
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "339952837",
"_score" : 2.0645075,
"_source" : {
"address" : "良乡西路7号",
"brand" : "如家",
"business" : "房山风景区",
"city" : "北京",
"id" : 339952837,
"location" : "39.73167, 116.132482",
"name" : "如家酒店(北京良乡西路店)",
"pic" : "https://m.tuniucdn.com/fb3/s1/2n9c/3Dpgf5RTTzrxpeN5y3RLnRVtxMEA_w200_h200_c1_t0.jpg",
"price" : 159,
"score" : 46,
"starName" : "二钻"
}
},
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "2359697",
"_score" : 1.9649367,
"_source" : {
"address" : "清河小营安宁庄东路18号20号楼",
"brand" : "如家",
"business" : "上地产业园/西三旗",
"city" : "北京",
"id" : 2359697,
"location" : "40.041322, 116.333316",
"name" : "如家酒店(北京上地安宁庄东路店)",
"pic" : "https://m.tuniucdn.com/fb3/s1/2n9c/2wj2f8mo9WZQCmzm51cwkZ9zvyp8_w200_h200_c1_t0.jpg",
"price" : 420,
"score" : 46,
"starName" : "二钻"
}
},
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "1455383931",
"_score" : 1.9649367,
"_source" : {
"address" : "西乡河西金雅新苑34栋",
"brand" : "如家",
"business" : "宝安商业区",
"city" : "深圳",
"id" : 1455383931,
"location" : "22.590272, 113.881933",
"name" : "如家酒店(深圳宝安客运中心站店)",
"pic" : "https://m.tuniucdn.com/fb3/s1/2n9c/2w9cbbpzjjsyd2wRhFrnUpBMT8b4_w200_h200_c1_t0.jpg",
"price" : 169,
"score" : 45,
"starName" : "二钻"
}
},
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "728180",
"_score" : 1.8745286,
"_source" : {
"address" : "西乡大道298-7号(富通城二期公交站旁)",
"brand" : "如家",
"business" : "宝安体育中心商圈",
"city" : "深圳",
"id" : 728180,
"location" : "22.569693, 113.860186",
"name" : "如家酒店(深圳宝安西乡地铁站店)",
"pic" : "https://m.tuniucdn.com/fb3/s1/2n9c/FHdugqgUgYLPMoC4u4rdTbAPrVF_w200_h200_c1_t0.jpg",
"price" : 184,
"score" : 43,
"starName" : "二钻"
}
},
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "2316304",
"_score" : 1.8745286,
"_source" : {
"address" : "龙岗街道龙岗墟社区龙平东路62号",
"brand" : "如家",
"business" : "龙岗中心区/大运新城",
"city" : "深圳",
"id" : 2316304,
"location" : "22.730828, 114.278337",
"name" : "如家酒店(深圳双龙地铁站店)",
"pic" : "https://m.tuniucdn.com/fb3/s1/2n9c/4AzEoQ44awd1D2g95a6XDtJf3dkw_w200_h200_c1_t0.jpg",
"price" : 135,
"score" : 45,
"starName" : "二钻"
}
},
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "1765008760",
"_score" : 1.8745286,
"_source" : {
"address" : "西直门北大街49号",
"brand" : "如家",
"business" : "西直门/北京展览馆地区",
"city" : "北京",
"id" : 1765008760,
"location" : "39.945106, 116.353827",
"name" : "如家酒店(北京西直门北京北站店)",
"pic" : "https://m.tuniucdn.com/fb3/s1/2n9c/4CLwbCE9346jYn7nFsJTQXuBExTJ_w200_h200_c1_t0.jpg",
"price" : 356,
"score" : 44,
"starName" : "二钻"
}
},
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "416121",
"_score" : 1.7920744,
"_source" : {
"address" : "莲花池东路120-2号6层",
"brand" : "如家",
"business" : "北京西站/丽泽商务区",
"city" : "北京",
"id" : 416121,
"location" : "39.896449, 116.317382",
"name" : "如家酒店(北京西客站北广场店)",
"pic" : "https://m.tuniucdn.com/fb3/s1/2n9c/42DTRnKbiYoiGFVzrV9ZJUxNbvRo_w200_h200_c1_t0.jpg",
"price" : 275,
"score" : 43,
"starName" : "二钻"
}
}
]
从结果中可以看出,ES会根据匹配程度进行排序返回。首先返回包含外滩如家的,如果没有,则继续返回包含外滩的和包含如家的
1.2.3 多字段匹配(mulit_match)
mulit_match语法如下:
GET /indexName/_search
{
"query": {
"multi_match": {
"query": "TEXT",
"fields": ["FIELD1", " FIELD12"]
}
}
}
GET /hotel/_search
{
"query": {
"multi_match": {
"query": "外滩如家",
"fields": ["brand", "business", "name"]
}
}
}
1.2.4 小结
match和multi_match的区别是什么?
- match:根据一个字段查询
- multi_match:根据多个字段查询,参与查询字段越多,查询性能越差,因此我们会将可能同时需要多字段排序的字段都
copy_to到一个联合字段
1.3 精确查找
精确查找一般是查找keyword,数值,日期和bool字段。精确查找不会对字段进行分词,要求查找内容和字段内容完全一致。比较常见的有
term按照词条精确匹配range根据范围匹配,可以数值也可以是日期
1.3.1 term查询
term在查找时不会根据用户输入的内容进行分词,只有和用户输入完全匹配的文档才会被查询出来
语法说明:
// term查询
GET /indexName/_search
{
"query": {
"term": {
"FIELD": {
"value": "VALUE"
}
}
}
}
这里我们来对比一下term和match的区别,我们分别使用match和term来查询上海如家。
# 精确查询term
GET /hotel/_search
{
"query": {
"term": {
"name": {
"value": "上海如家"
}
}
}
}
由于是精确查找,但是没有酒店的名字就叫做上海如家,因此查询结果为0
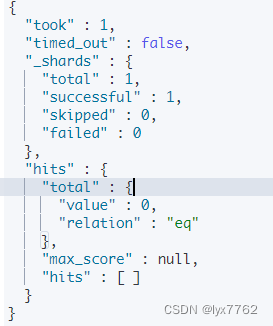
但是如果使用match的话,会将用户输入的词语分解为上海和如家,因此可以查询到大量的内容
# 查询符合条件的酒店信息
GET /hotel/_search
{
"query": {
"match": {
"name": "上海如家"
}
}
}

1.3.2 range查询
范围查询,一般用来进行数值范围过滤
基本语法:
// range查询
GET /indexName/_search
{
"query": {
"range": {
"FIELD": {
"gte": 10, // 这里的gte代表大于等于,gt则代表大于
"lte": 20 // lte代表小于等于,lt则代表小于
}
}
}
}
如查询价格位于(100, 200]区间的酒店
# 范围查找 range
GET /hotel/_search
{
"query": {
"range": {
"price": {
"gt": 100,
"lte": 200
}
}
}
}
1.3.3 小结
精确查询常见的有哪些?
- term查询:根据词条精确匹配,一般搜索keyword类型、数值类型、布尔类型、日期类型字段
- range查询:根据数值范围查询,可以是数值、日期的范围
1.4 地理坐标查询
地理位置查询。包括查找距离指定位置指定距离的所有文档geo_distance, 和查询某一个范围内的所有文档geo_bounding_box
常见的应用场景有:
- 携程:附近的酒店
- 微信:附近的人
- 滴滴:附近的车
1.4.1 矩形范围查找(geo_bounding_box)
查询时,需要指定矩形的左上、右下两个点的坐标,然后画出一个矩形,落在该矩形内的都是符合条件的点。

语法如下:
// geo_bounding_box查询
GET /indexName/_search
{
"query": {
"geo_bounding_box": {
"FIELD": {
"top_left": { // 左上点
"lat": 31.1,
"lon": 121.5
},
"bottom_right": { // 右下点
"lat": 30.9,
"lon": 121.7
}
}
}
}
}
1.4.2 附近查询(geo_distance)
查找距离制位置在指定距离内的所有文档。换句话来说,在地图上找一个点作为圆心,以指定距离为半径,画一个圆,落在圆内的坐标都算符合条件:

语法说明:
// geo_distance 查询
GET /indexName/_search
{
"query": {
"geo_distance": {
"distance": "15km", // 半径
"FIELD": "31.21,121.5" // 圆心
}
}
}
如查找(32.21, 121.5)点周围15km的所有酒店
# 根据距离查询
GET /hotel/_search
{
"query": {
"geo_distance" : {
"distance" : "15km",
"location" : "32.21, 121.5"
}
}
}
1.5 复合查询
所谓符合查询就是将多个简单查询组合起来,从而实现更加复杂的搜索逻辑。主要有以下两种:
- bool query 布尔查询,利用逻辑关键字将多个条件联合起来实现复杂查询
- function socre 自定义算分函数,可以人为的孔夷文档的相关性分数从而控制排名
1.5.1 相关性算分
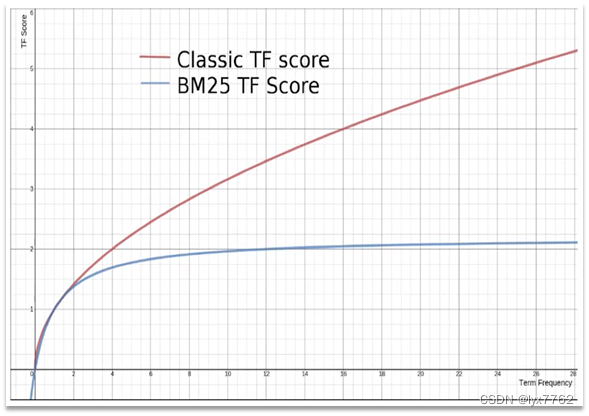
在ES中搜索结果中会根据相关性评分进行排序。在早起的ES版本中,采用的算法是TF_IDF算法

在新版本中,ES采用了BM25算法

TF-IDF算法有一个缺陷,就是词条频率越高,文档得分也会越高,单个词条对文档影响较大。而BM25则会让单个词条的算分有一个上限,曲线更加平滑:
1.5.2 自定义算分函数
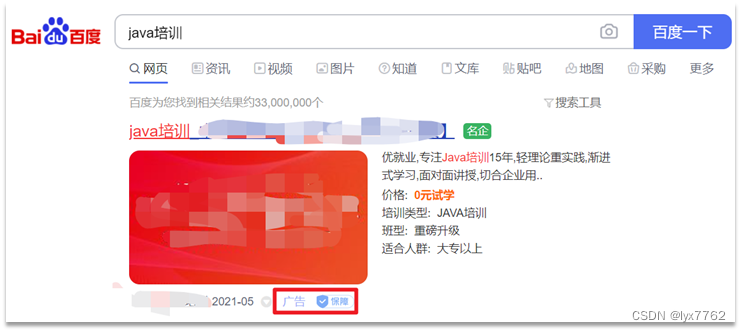
通常情况下,应该根据相关性进行排序,但是在都写情况下,需要修改排序。
以百度为例,你搜索的结果中,并不是相关度越高排名越靠前,而是谁掏的钱多排名就越靠前。如图:
如果想要认为的去修改相关性分数,就需要使用ES中的function score 查询了。
语法说明
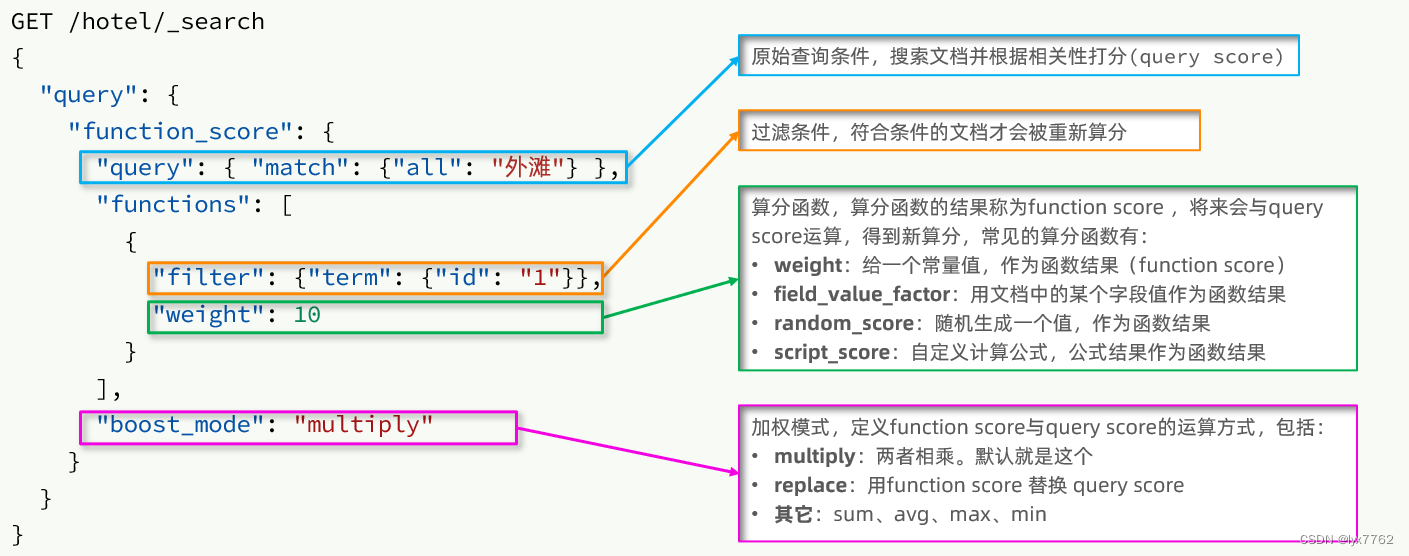
function score包含四部分内容:
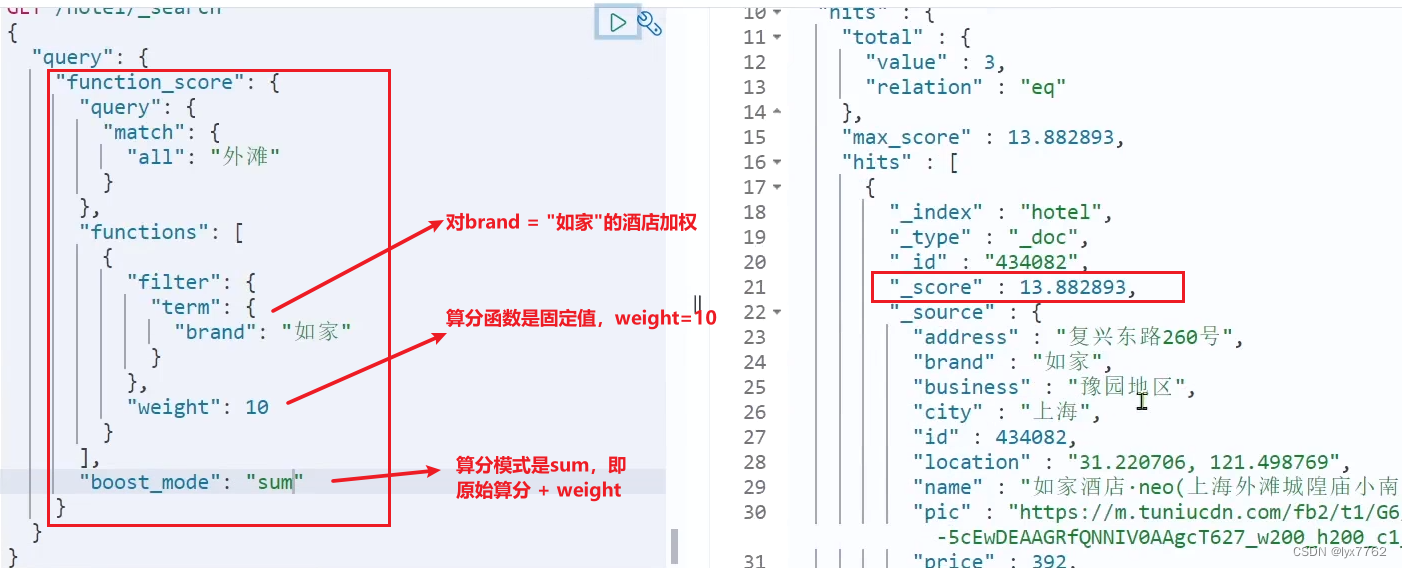
- 原始查询条件:query部分,基于BM25算法打分,查询结果的相关性分数就是原始分数。
- 过滤条件:filter部分,符合该条件的文档才会重新算分。比如给如家重新算分,则这里的过滤条件就是
"filter" : {"term" : {"brand" : "如家"}} - 算分函数:给符合过滤条件的文档使用下面的这个函重新计算相关性分数。常用的函数由四种:
- weight:函数结果是常量
- field_value_factor:以文档中的某个字段值作为函数结果
- random_score:以随机数作为函数结果
- script_score:自定义算分函数算法
- 运算模式:将算分函数的结果和原始结果进行运算后得到最终的得分,常见的有:
- multiply:相乘
- replace:用function score替换query score
- 其它,例如:sum、avg、max、min
function score运行流程
- 根据原始条件查询文档,并计算相关性得分,称为原始得分
- 根据过滤条件,查找到需要重新计算分数的文档
- 基于算分函数,得到函数得分
- 将原始得分和函数得分通过运算模式进行运算,得到最终得分
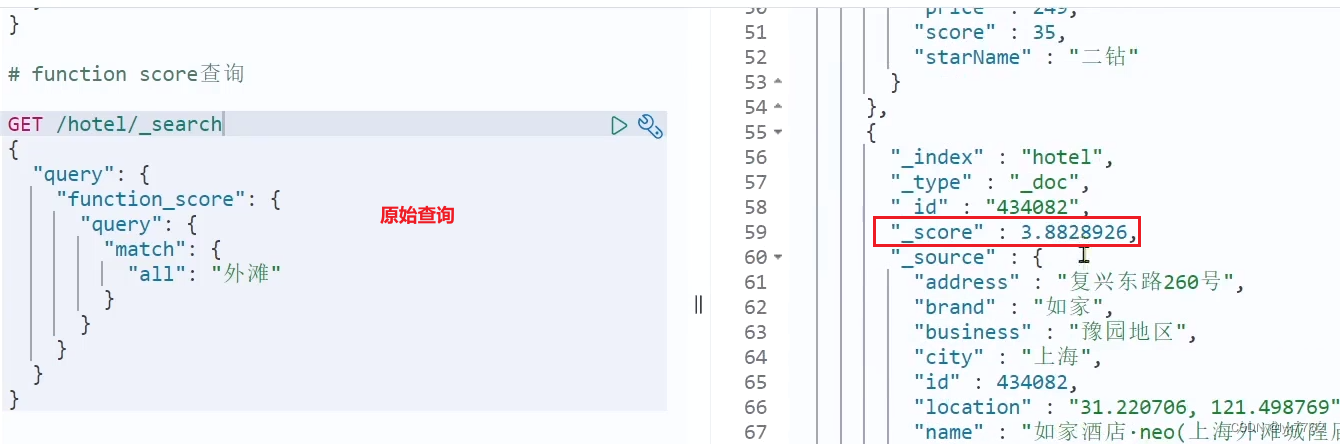
如如家酒店的相关性加20分
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match": {
"all": "外滩"
}
},
"functions": [
{
"filter": {
"term": {
"brand": "如家"
}
},
"weight": 20
}
],
"boost_mode": "sum"
}
}
}
1.5.3 总结
function score query定义的三要素是什么?
- 过滤条件:哪些文档要加分
- 算分函数:如何计算function score
- 加权方式:function score 与 query score如何运算
1.5.4 布尔查询
布尔查询将一个或多个子查询通过一定的逻辑关系组合起来,进而完成复杂查询。逻辑关系词有以下四个:
- must:必须满足的条件
- should:只要满足一个子查询
- must_not:必须不匹配,不参与算分
- filter:必须匹配,不参与算法
如在搜索酒店时,除了关键字搜索外,我们还可能根据品牌、价格、城市等字段做过滤:
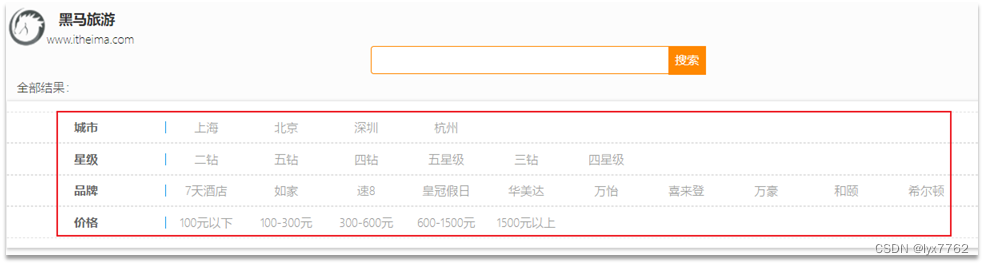
每一个不同的字段,其查询的条件、方式都不一样,必须是多个不同的查询,而要组合这些查询,就必须用bool查询了。
需要注意的是,搜索时,参与打分的字段越多,查询的性能也越差。因此这种多条件查询时,建议这样做:
- 搜索框的关键字搜索,是全文检索查询,使用must查询,参与算分
- 其它过滤条件,采用filter查询。不参与算分
如查询名字包含“如家”,价格不高于400,在坐标31.21,121.5周围10km范围内的酒店。
# bool查询
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"brand": {
"value": "如家"
}
}
}
],
"must_not": [
{
"range": {
"price": {
"gt": 400
}
}
}
],
"filter": [
{
"geo_distance": {
"distance": "10km",
"location": {
"lat": 31.21,
"lon": 121.5
}
}
}
]
}
}
}
还有一种写法,不使用must_not,注意filter里面是如何添加多条件的
# bool查询
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"brand": {
"value": "如家"
}
}
}
],
"filter": [
{
"geo_distance": {
"distance": "10km",
"location": {
"lat": 31.21,
"lon": 121.5
}
}
},
{
"range": {
"price": {
"gte": 10,
"lte": 420
}
}
}
]
}
}
}
1.5.5 小结
bool查询有几种逻辑关系?
- must:必须匹配的条件,可以理解为“与”
- should:选择性匹配的条件,可以理解为“或”
- must_not:必须不匹配的条件,不参与打分
- filter:必须匹配的条件,不参与打分
1.6 查询结果排序
elasticsearch默认是根据相关度算分(_score)来排序,但是也支持自定义方式对搜索结果排序。可以排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。
1.6.1 普通字段排序
语法:
GET /indexName/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"FIELD": "desc" // 排序字段、排序方式ASC、DESC
}
]
}
排序条件是一个数组,也就是可以写多个排序条件。按照声明的顺序,当第一个条件相等时,再按照第二个条件排序,以此类推
如查询所有酒店,根据酒店的评分降序排列,酒店的分数一样的按照价格的升序排列
# 排序
GET /hotel/_search
{
"query": {
"match_all": {}
}
, "sort": [
{
"score": "desc"
},
{
"price": "asc"
}
]
}
1.6.2 按照地理位置排序
地理坐标排序略有不同。
语法说明:
GET /indexName/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance" : {
"FIELD" : "纬度,经度", // 文档中geo_point类型的字段名、目标坐标点
"order" : "asc", // 排序方式
"unit" : "km" // 排序的距离单位
}
}
]
}
这个查询的含义是:
- 指定一个坐标,作为目标点
- 计算每一个文档中,指定字段(必须是geo_point类型)的坐标 到目标点的距离是多少
- 根据距离排序
如查询到(31.03, 121.61)这个点附近的所有酒店,按照距离升序排列
GET /hotel/_search
{
"query": {
"match_all": {
}
},
"sort": [
{
"_geo_distance": {
"location": {
"lat": 31.03,
"lon": 121.61
},
"order": "asc",
"unit": "km"
}
}
]
}
提示:获取你的位置的经纬度的方式:https://lbs.amap.com/demo/jsapi-v2/example/map/click-to-get-lnglat/
1.7 分页
之前已经提到过,ES默认返回的查询结果只有10条。如果要查询更多数据就需要修改分页参数了。elasticsearch中通过修改from、size参数来控制要返回的分页结果:
- from:从第几个文档开始
- size:总共查询几个文档
类似于mysql中的limit ?, ?
1.7.1 简单分页
分页的基本语法如下:
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from": 0, // 分页开始的位置,默认为0
"size": 10, // 期望获取的文档总数
"sort": [
{"price": "asc"}
]
}
1.7.2 ES分页原理
如果我们要查询从990条记录到1000条文档,ES需要先获取前1000条文档,然后排序,最后截取990-1000条记录再返回
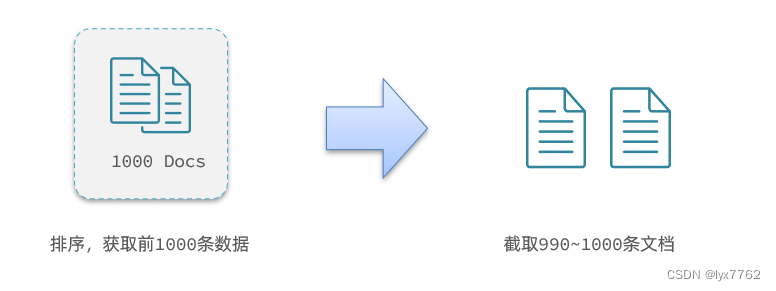
如果在集群模式下,通常数据是分散的存储在不同的节点上的,因此如果有我集群有5个节点,我要查询TOP1000的数据,并不是每个节点查询200条就可以了。因为节点A的TOP200,在另一个节点可能排到10000名以外了。因此要想获取整个集群的TOP1000,必须先查询出每个节点的TOP1000,汇总结果后,重新排名,重新截取TOP1000。
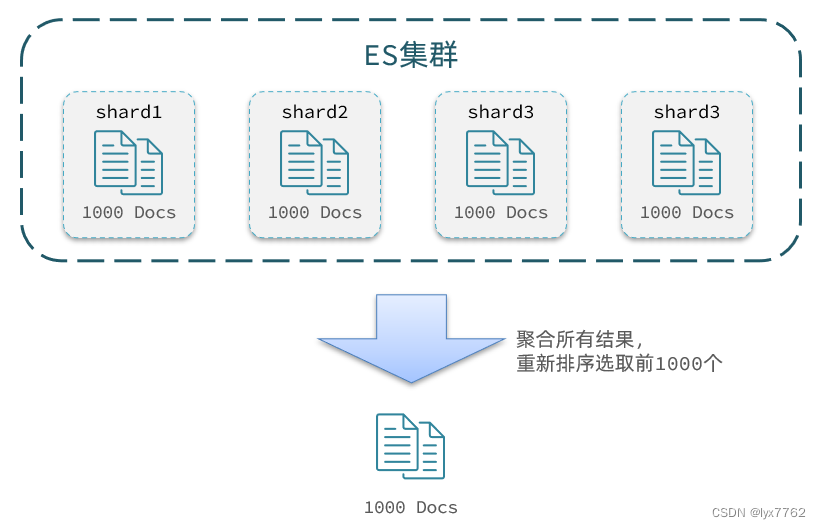
那如果我要查询9900~10000的数据呢?是不是要先查询TOP10000呢?那每个节点都要查询10000条?汇总到内存中?
当查询分页深度较大时,汇总数据过多,对内存和CPU会产生非常大的压力,因此elasticsearch会禁止from+ size 超过10000的请求。
1.7.3 小结
分页查询的常见实现方案以及优缺点:
from + size:- 优点:支持随机翻页
- 缺点:深度分页问题,默认查询上限(from + size)是10000
- 场景:百度、京东、谷歌、淘宝这样的随机翻页搜索
1.8 查询结果高亮
我们在使用搜索引擎搜索的时候,关键字会高亮显示
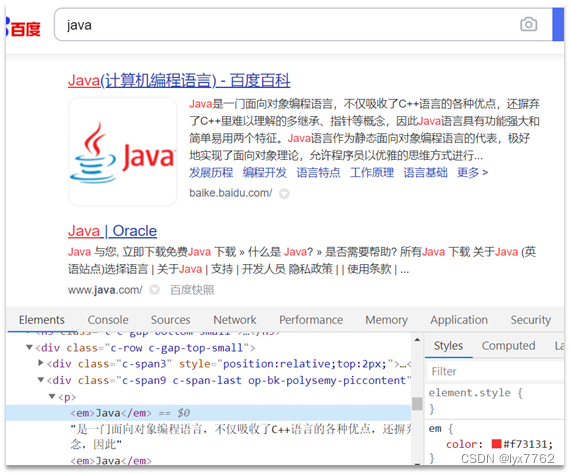
高亮显示的实现分为两步:
- 给文档中的所有关键字都添加一个标签,例如
<em>标签 - 页面给
<em>标签编写CSS样式
高亮显示看似是通过前端标签实现的,实际上是ES查询后,给关键字添加了前端标签。
语法:
GET /hotel/_search
{
"query": {
"match": {
"FIELD": "TEXT" // 查询条件,高亮一定要使用全文检索查询
}
},
"highlight": {
"fields": { // 指定要高亮的字段
"FIELD": {
"pre_tags": "<em>", // 用来标记高亮字段的前置标签
"post_tags": "</em>" // 用来标记高亮字段的后置标签
}
}
}
}
高亮显示是对结果高亮,因此查询条件必须是带有关键字的搜索
默认恩情况下,高亮的字段和搜索的字段应该是一样的
如果要对非搜索字段高亮,则需要添加一个属性:required_field_match=false
如查询所有的如家酒店,并进行高亮处理
# 分页高亮
GET /hotel/_search
{
"query": {
"term": {
"brand": {
"value": "如家"
}
}
},
"from": 0,
"size": 20,
"sort": [
{
"score": "desc"
},
{
"price": "asc"
}
],
"highlight": {
"fields": {
"name": {
"require_field_match": "false"
}
}
}
}
1.9 使用DSL查询文档总结
查询的DSL是一个大的JSON对象,包含下列属性:
- query:查询条件
- from和size:分页条件
- sort:排序条件
- highlight:高亮条件
2. 使用RestClient查询文档
文档的查询同样适用昨天学习的 RestHighLevelClient对象,基本步骤包括:
- 准备Request对象
- 准备请求参数
- 发起请求
- 解析响应
2.1 match_all
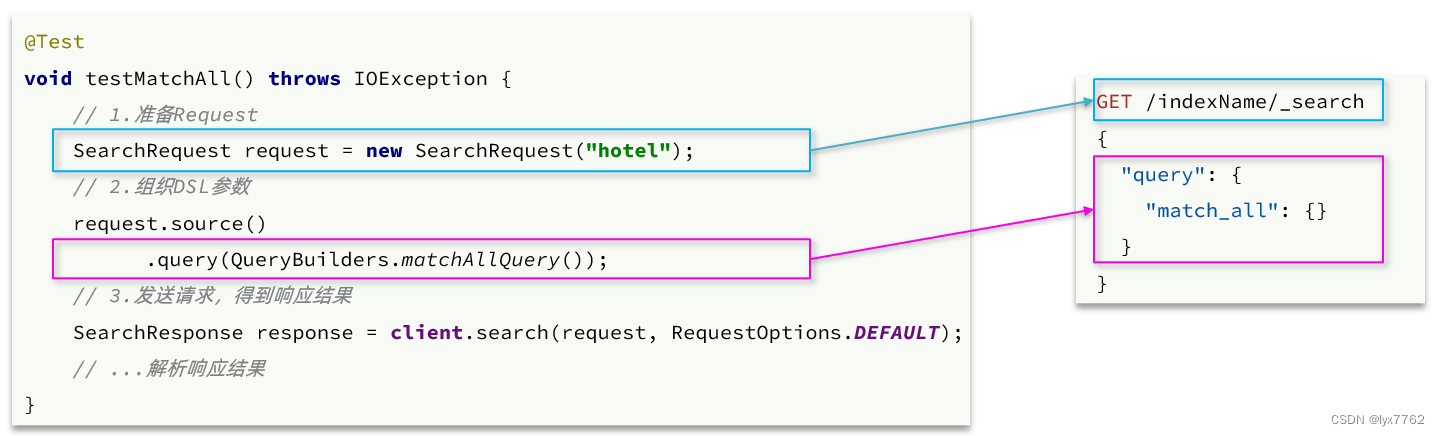
代码解读:
-
第一步,创建
SearchRequest对象,指定索引库名 -
第二步,利用
request.source()构建DSL,DSL中可以包含查询、分页、排序、高亮等query():代表查询条件,利用QueryBuilders.matchAllQuery()构建一个match_all查询的DSL
-
第三步,利用client.search()发送请求,得到响应
这里关键的API有两个,一个是request.source(),其中包含了查询、排序、分页、高亮等所有功能:
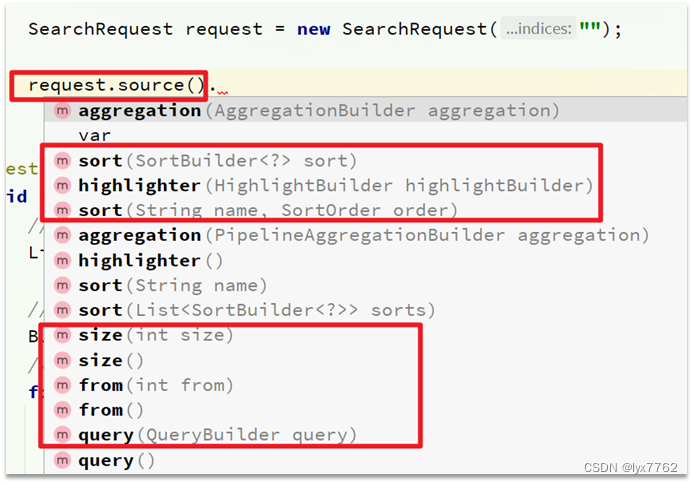
另一个是QueryBuilders,其中包含match、term、function_score、bool等各种查询:

响应结果解析
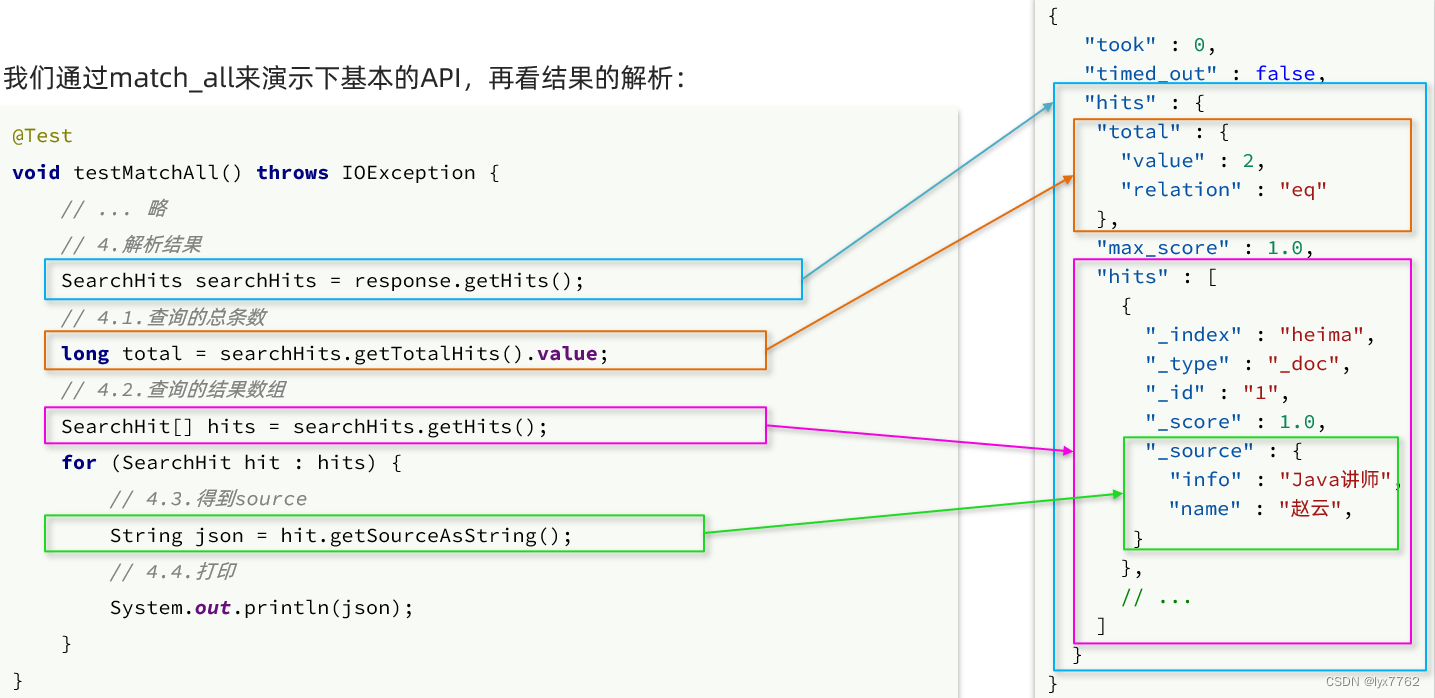
elasticsearch返回的结果是一个JSON字符串,结构包含:
hits:命中的结果total:总条数,其中的value是具体的总条数值max_score:所有结果中得分最高的文档的相关性算分hits:搜索结果的文档数组,其中的每个文档都是一个json对象_source:文档中的原始数据,也是json对象
因此,我们解析响应结果,就是逐层解析JSON字符串,流程如下:
SearchHits:通过response.getHits()获取,就是JSON中的最外层的hits,代表命中的结果SearchHits#getTotalHits().value:获取总条数信息SearchHits#getHits():获取SearchHit数组,也就是文档数组SearchHit#getSourceAsString():获取文档结果中的_source,也就是原始的json文档数据
具体代码如下:
@Test
void testMatchAll() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
request.source()
.query(QueryBuilders.matchAllQuery());
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
private void handleResponse(SearchResponse response) {
// 4.解析响应
SearchHits searchHits = response.getHits();
// 4.1.获取总条数
long total = searchHits.getTotalHits().value;
System.out.println("共搜索到" + total + "条数据");
// 4.2.文档数组
SearchHit[] hits = searchHits.getHits();
// 4.3.遍历
for (SearchHit hit : hits) {
// 获取文档source
String json = hit.getSourceAsString();
// 反序列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println("hotelDoc = " + hotelDoc);
}
}
使用RestClient查询的基本步骤
- 创建
SearchRequest对象 - 准备
Request.source(),也就是DSL
2.1 使用QueryBuilders创建查询条件
2.2 将构建好的条件传入Request.source().query()方法 - 发送请求
- 解析结果
2.2 match查询
架构基本和match_all类似,唯一的区别就是查询条件

@Test
void testMatch() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
request.source()
.query(QueryBuilders.matchQuery("all", "如家"));
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
2.3 term和range查询
只需要修改查询条件

@Test
void testMatch() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
request.source()
.query(QueryBuilders.termQuery("city", "上海").rangeQuery("price").gte(200));
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
2.4 bool query
布尔查询是用must、must_not、filter等方式组合其它查询,代码示例如下:
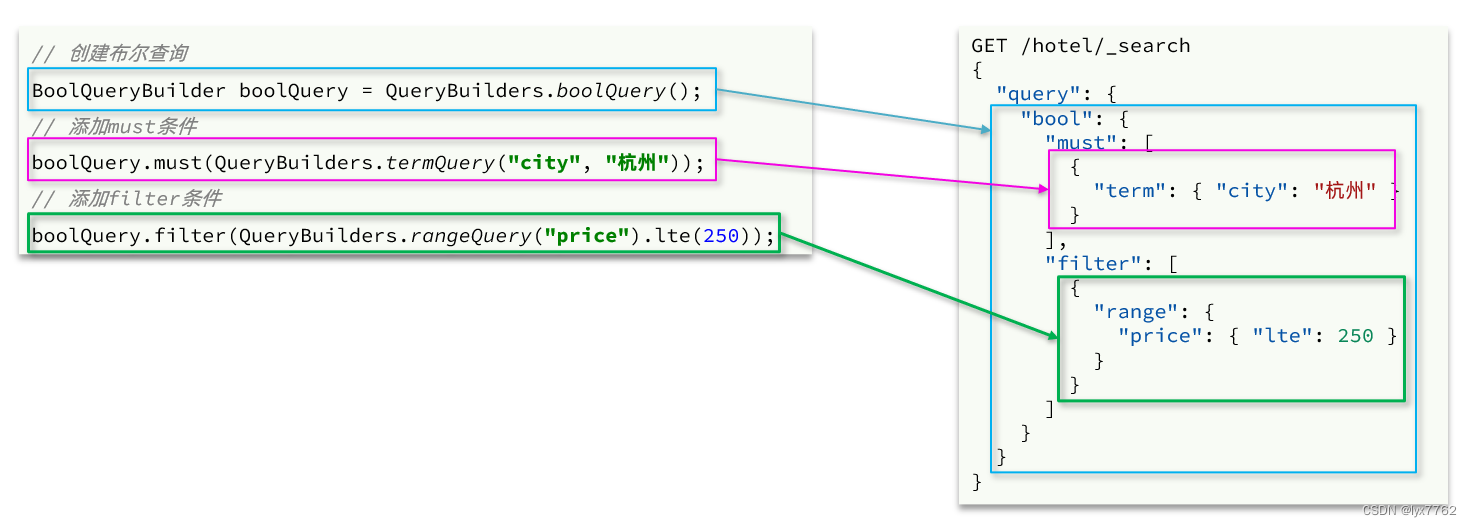
如查询如家小于400元的31.21,121.5这个位置10km内的酒店 bool查询
@Test
void testBool() throws IOException {
// 1.创建查询请求
SearchRequest request = new SearchRequest("hotel");
// 查询如家小于400元的31.21,121.5这个位置10km内的酒店
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.must(QueryBuilders.termQuery("brand", "如家"));
boolQuery.mustNot(QueryBuilders.rangeQuery("price").gt(400));
boolQuery.filter(QueryBuilders.geoDistanceQuery("location").point(31.21, 121.5).distance(10, DistanceUnit.KILOMETERS));
request.source().query(boolQuery);
// 2.发送查询请求
SearchResponse response = this.client.search(request, RequestOptions.DEFAULT);
// 3.解析查询请求
parseResult(response);
}
对应的DSL
# bool查询
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"brand": {
"value": "如家"
}
}
}
],
"must_not": [
{
"range": {
"price": {
"gt": 400
}
}
}
],
"filter": [
{
"geo_distance": {
"distance": "10km",
"location": {
"lat": 31.21,
"lon": 121.5
}
}
}
]
}
}
}
2.5 排序和分页
搜索结果的排序和分页是与query同级的参数,因此同样是使用request.source()来设置。
对应的API如下:

@Test
void testOrderAndPagination() throws IOException {
int pageNo = 1, pageSize = 5;
// 1.创建查询请求
SearchRequest request = new SearchRequest("hotel");
request.source().query(QueryBuilders.matchAllQuery());
request.source().from((pageNo - 1) * pageSize).size(pageSize);
request.source().sort("price", SortOrder.ASC);
// 2.发送查询请求
SearchResponse response = this.client.search(request, RequestOptions.DEFAULT);
// 3.解析查询请求
parseResult(response);
}
2.6 高亮
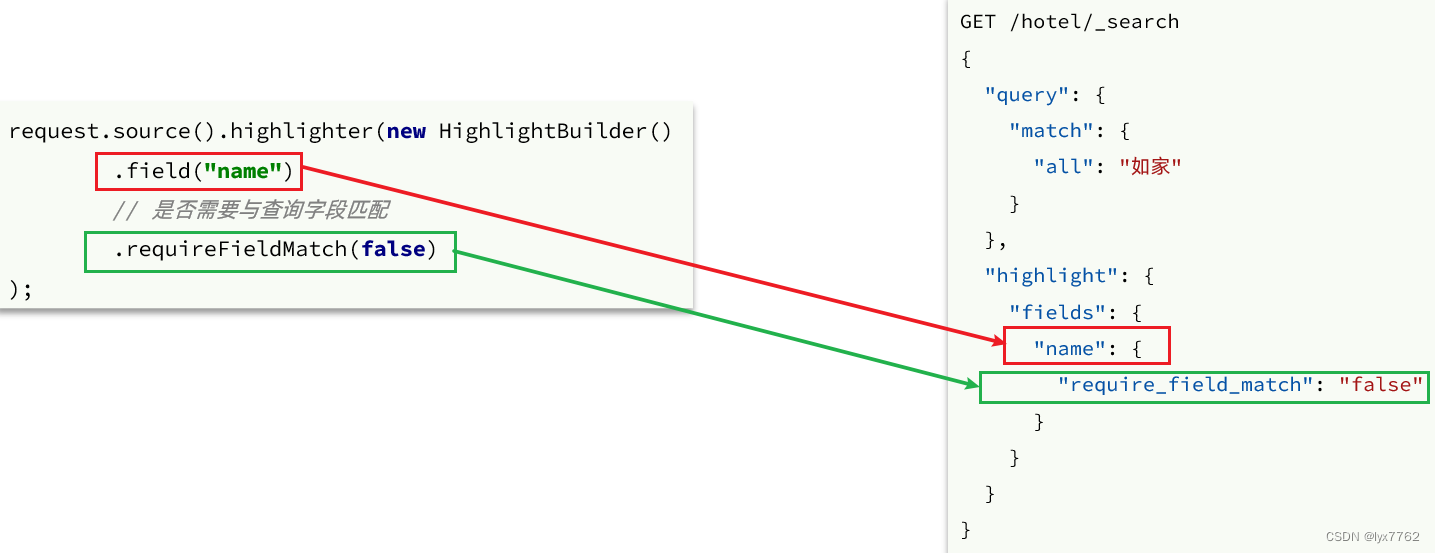
高亮的代码与之前代码差异较大,有两点:
- 查询的DSL:其中除了查询条件,还需要添加高亮条件,同样是与query同级。
- 结果解析:结果除了要解析_source文档数据,还要解析高亮结果
@Test
void testHeightLight() throws IOException {
int pageNo = 1, pageSize = 5;
// 1.创建查询请求
SearchRequest request = new SearchRequest("hotel");
request.source().query(QueryBuilders.matchQuery("name", "如家"));
request.source().from((pageNo - 1) * pageSize).size(pageSize);
request.source().sort("price", SortOrder.ASC);
request.source().highlighter(new HighlightBuilder().field("name"));
// 2.发送查询请求
SearchResponse response = this.client.search(request, RequestOptions.DEFAULT);
// 3.解析查询请求
parseResult(response);
}
通过高亮后返回的结果可以看出来,经过高亮后的代码并不是直接在source里面返回,而是在highlight里面返回的,因此在解析结果的时候,需要做一些额外的处理
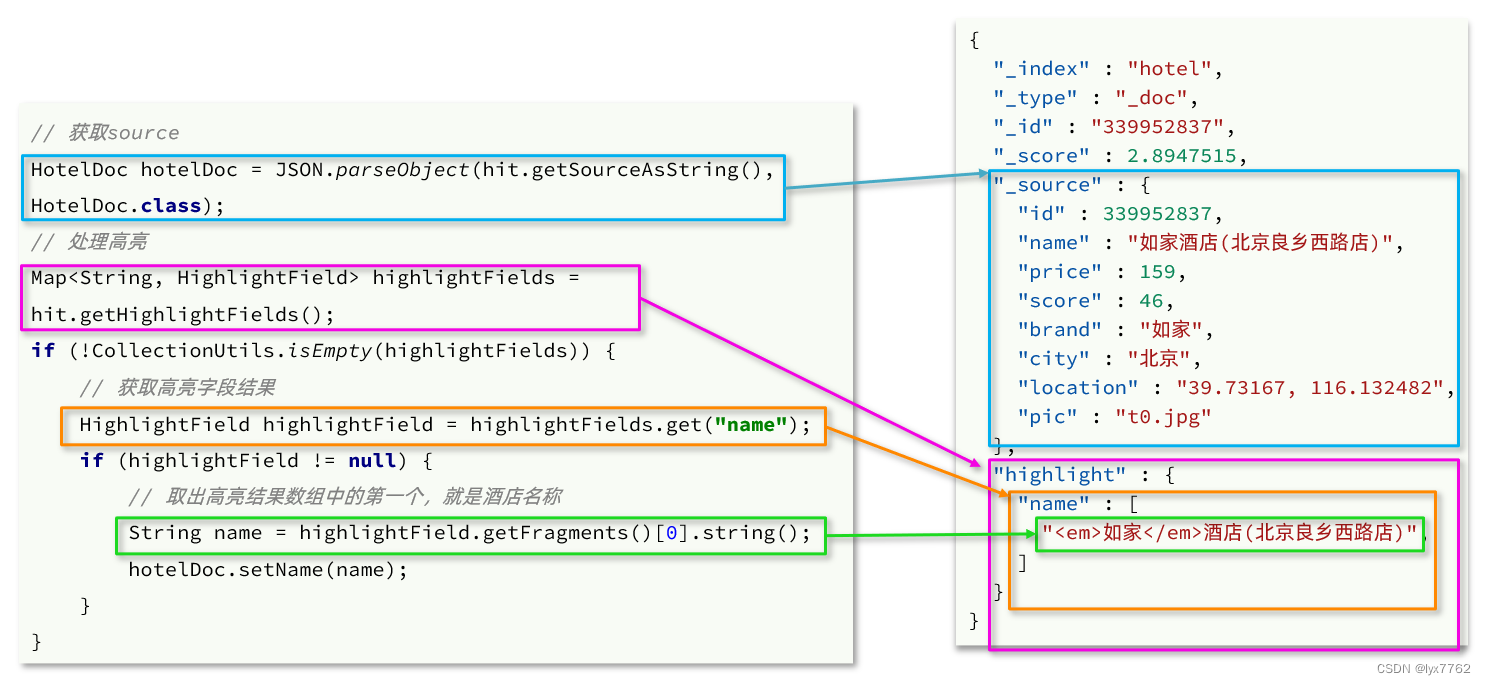
代码解读:
- 第一步:从结果中获取
source。hit.getSourceAsString(),这部分是非高亮结果,json字符串。还需要反序列为HotelDoc对象 - 第二步:获取高亮结果。
hit.getHighlightFields(),返回值是一个Map,key是高亮字段名称,值是HighlightField对象,代表高亮值 - 第三步:从map中根据高亮字段名称,获取高亮字段值对象HighlightField
- 第四步:从HighlightField中获取Fragments,并且转为字符串。这部分就是真正的高亮字符串了
- 第五步:用高亮的结果替换HotelDoc中的非高亮结果
完整的结果解析代码
private static void parseResult(SearchResponse response) {
SearchHits searchHits = response.getHits();
long total = searchHits.getTotalHits().value;
System.out.println("共查询到" + total + "条记录");
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
String json = hit.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
if (!CollectionUtils.isEmpty(highlightFields)) {
// 如果需要高亮显示
HighlightField highlightField = highlightFields.get("name");
if (highlightField != null) {
String name = highlightField.getFragments()[0].toString();
hotelDoc.setName(name);
}
}
System.out.println(hotelDoc);
}
}
3. 黑马旅游案例
下面通过一个案例巩固之前的知识。这个案例主要实现四部分功能:
- 酒店的搜索和分页
- 对结果的过滤
- 周边的酒店
- 酒店的竞价排名
3.1 酒店的搜索和分页
在项目的首页,有一个大大的搜索框,还有分页按钮:
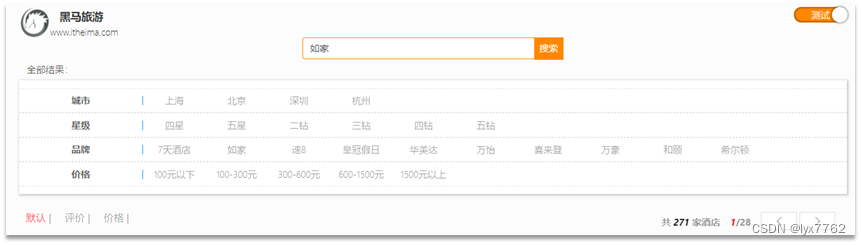
点击搜索按钮,可以看到浏览器控制台发出了请求:
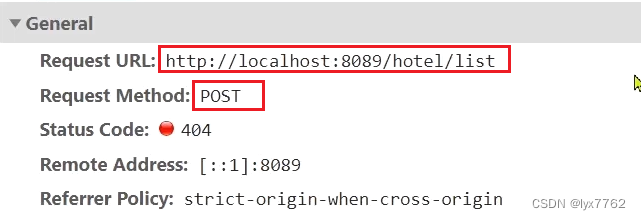

由此可以知道,我们这个请求的信息如下:
- 请求方式:POST
- 请求路径:/hotel/list
- 请求参数:JSON对象,包含4个字段:
- key:搜索关键字
- page:页码
- size:每页大小
- sortBy:排序,目前暂不实现
- 返回值:分页查询,需要返回分页结果PageResult,包含两个属性:
total:总条数List<HotelDoc>:当前页的数据
因此我们的实现步骤如下
- 定义实体类,用来接收前端传递的参数
- 编写controller,接收页面请求
- 使用RestClient实现搜索和分页。
定义实体类
@Data
public class RequestParams {
private String key;
private Integer page;
private Integer size;
private String sortBy;
}
向前端发送数据的时候,需要带上总条数和所有查找到的数据,因此也需要一个结果类封装返回的结果
@Data
@NoArgsConstructor
@AllArgsConstructor
public class PageResult {
private Long total;
private List<HotelDoc> hotels;
}
定义Controller
定义一个HotelController,声明查询接口,满足下列要求:
- 请求方式:Post
- 请求路径:/hotel/list
- 请求参数:对象,类型为RequestParam
- 返回值:PageResult,包含两个属性
Long total:总条数List<HotelDoc> hotels:酒店数据
@RestController
@RequestMapping("/hotel")
public class HotelController {
@Resource
IHotelService hotelService;
@PostMapping("/list")
public PageResult search(@RequestBody SearchParam searchParam) {
return hotelService.search(searchParam);
}
}
业务代码
首先需要将RestClient添加到IOC容器中,因此在启动类中使用注解添加
@Bean
public RestHighLevelClient client(){
return new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.150.101:9200")
));
}
在实现类中实现
@Override
public PageResult search(RequestParams params) {
try {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.query
String key = params.getKey();
if (key == null || "".equals(key)) {
boolQuery.must(QueryBuilders.matchAllQuery());
} else {
boolQuery.must(QueryBuilders.matchQuery("all", key));
}
// 2.2.分页
int page = params.getPage();
int size = params.getSize();
request.source().from((page - 1) * size).size(size);
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
return handleResponse(response);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
// 结果解析
private PageResult handleResponse(SearchResponse response) {
// 4.解析响应
SearchHits searchHits = response.getHits();
// 4.1.获取总条数
long total = searchHits.getTotalHits().value;
// 4.2.文档数组
SearchHit[] hits = searchHits.getHits();
// 4.3.遍历
List<HotelDoc> hotels = new ArrayList<>();
for (SearchHit hit : hits) {
// 获取文档source
String json = hit.getSourceAsString();
// 反序列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
// 放入集合
hotels.add(hotelDoc);
}
// 4.4.封装返回
return new PageResult(total, hotels);
}
3.2 酒店查询结果的过滤
在页面搜索框下面,会添加品牌、城市、星级、价格等过滤项:
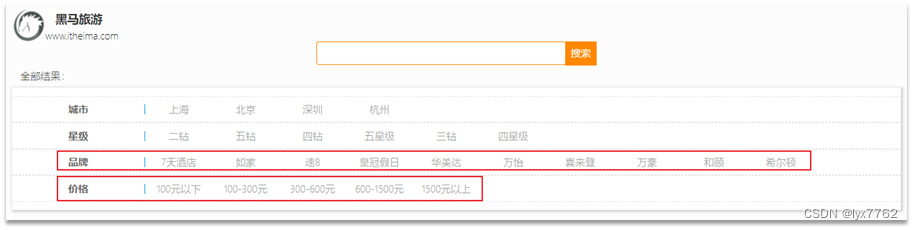
请求参数如下
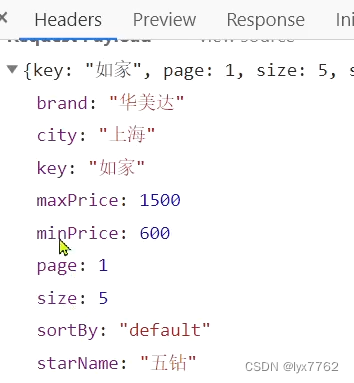
因此我们要修改之前接收前端信息的实体类,然后修改搜索的业务逻辑
修改实体类
@Data
public class RequestParams {
private String key;
private Integer page;
private Integer size;
private String sortBy;
// 下面是新增的过滤条件参数
private String city;
private String brand;
private String starName;
private Integer minPrice;
private Integer maxPrice;
}
修改业务
现在我们需要综合多个子查询的结果来对结果进行过滤,因此我们需要使用boolQuery。
- 品牌过滤:是keyword类型,用term查询
- 星级过滤:是keyword类型,用term查询
- 价格过滤:是数值类型,用range查询
- 城市过滤:是keyword类型,用term查询
多个查询条件组合,肯定是boolean查询来组合:
- 关键字搜索放到must中,参与算分
- 其它过滤条件放到filter中,不参与算分
@Override
public PageResult search(SearchParam searchParam) {
try {
SearchRequest request = new SearchRequest("hotel");
// 查询关键字
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
String key = searchParam.getKey();
if (key == null || "".equals(key)) {
boolQueryBuilder.must(QueryBuilders.matchAllQuery());
} else {
boolQueryBuilder.must(QueryBuilders.matchQuery("all", key));
}
if (searchParam.getCity() != null && !"".equals(searchParam.getCity())) {
boolQueryBuilder.filter(QueryBuilders.termQuery("city", searchParam.getCity()));
}
if (searchParam.getBrand() != null && !"".equals(searchParam.getBrand())) {
boolQueryBuilder.filter(QueryBuilders.termQuery("brand", searchParam.getBrand()));
}
if (searchParam.getStarName() != null && !"".equals(searchParam.getStarName())) {
boolQueryBuilder.filter(QueryBuilders.termQuery("startName", searchParam.getStarName()));
}
if (searchParam.getMaxPrice() != null) {
boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").lt(searchParam.getMaxPrice()));
}
if (searchParam.getMinPrice() != null) {
boolQueryBuilder.filter(QueryBuilders.rangeQuery("price").gt(searchParam.getMinPrice()));
}
// 分页
int page = searchParam.getPage();
int size = searchParam.getSize();
request.source().from((page - 1) * size);
request.source().size(size);
request.source().query(functionScoreQuery);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
return parseResult(response);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
3.3 附近的酒店
在酒店列表页的右侧,有一个小地图,点击地图的定位按钮,地图会找到你所在的位置: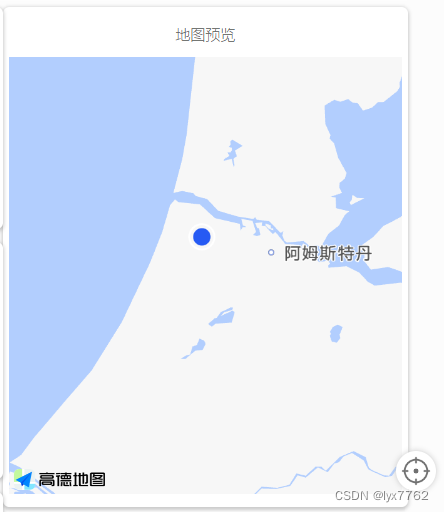
并且,在前端会发起查询请求,将你的坐标发送到服务端:
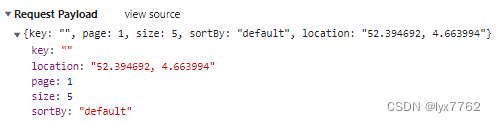
我们需要做的就是基于这个地理位置坐标,按照距离对搜索到的酒店排序。
- 我们需要修改实体类,添加location字段接收位置消息
- 修改search方法业务逻辑,如果location有值,添加根据geo_distance排序的功能
修改实体类
@Data
public class RequestParams {
private String key;
private Integer page;
private Integer size;
private String sortBy;
private String city;
private String brand;
private String starName;
private Integer minPrice;
private Integer maxPrice;
// 我当前的地理坐标
private String location;
}
修改业务代码
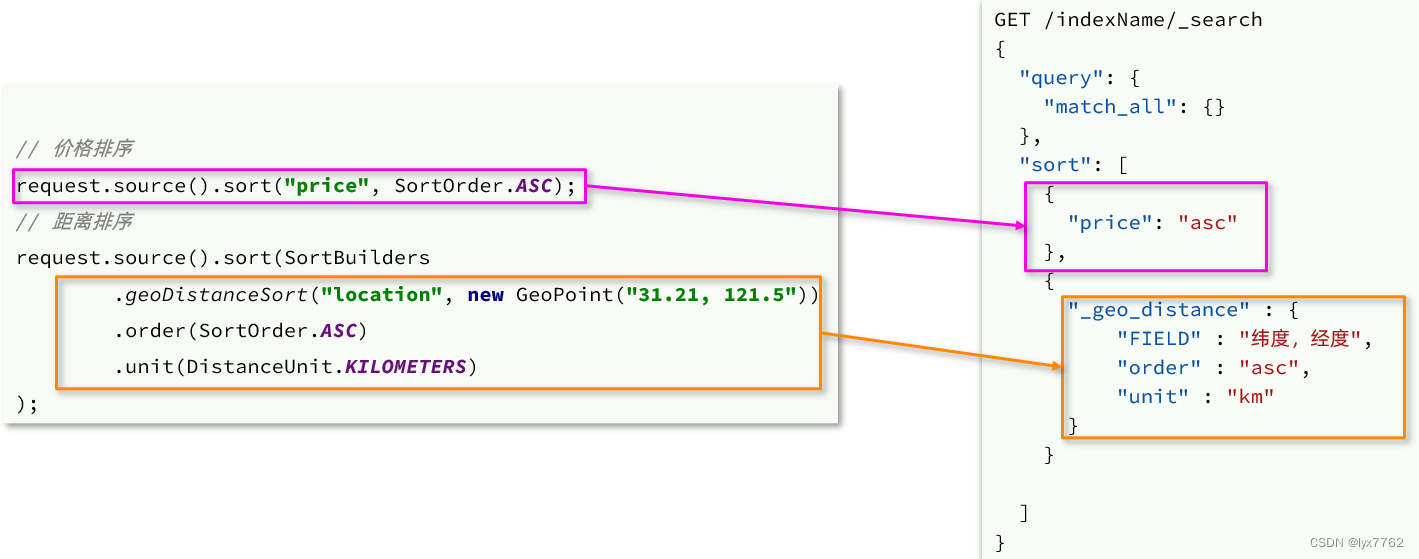
HotelService的search方法中,添加一个下列代码
if (!StringUtils.isEmpty(searchParam.getLocation())) {
// 按照距离排序
request.source().sort(SortBuilders.geoDistanceSort(
"location",
new GeoPoint(searchParam.getLocation())
)
.order(SortOrder.ASC)
.unit(DistanceUnit.KILOMETERS)
);
}
从目前的搜索结果看,我们并不知道酒店距离我们到底有多远,因此还需要完善
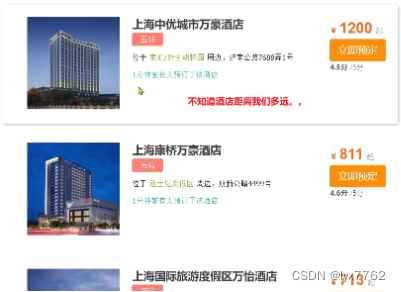
排序完成后,页面还要获取我附近每个酒店的具体距离值,这个值在响应结果中是独立的:
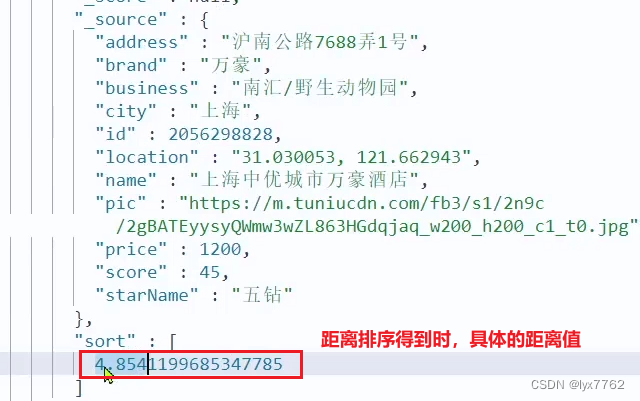
因此,我们在结果解析阶段,除了解析source部分以外,还要得到sort部分,也就是排序的距离,然后放到响应结果中。我们需要完成两件事
- 修改HotelDoc,加入distance字段
- 修改业务,读取response信息中获取到距离,封装到HotelDoc对象
修改HotelDoc
@Data
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
private Object distance;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + ", " + hotel.getLongitude();
this.pic = hotel.getPic();
}
修改业务方法
private PageResult parseResult(SearchResponse response) {
SearchHits searchHits = response.getHits();
long total = searchHits.getTotalHits().value;
SearchHit[] hits = searchHits.getHits();
List<HotelDoc> hotels = new ArrayList<>();
for (SearchHit hit : hits) {
String json = hit.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
// 设置距离字段新增代码-------------------------------
Object[] sortValues = hit.getSortValues();
if (sortValues.length != 0) {
hotelDoc.setDistance(sortValues[0]);
}
//---------------
hotels.add(hotelDoc);
}
return new PageResult(total, hotels);
}
3.4 酒店竞价排名
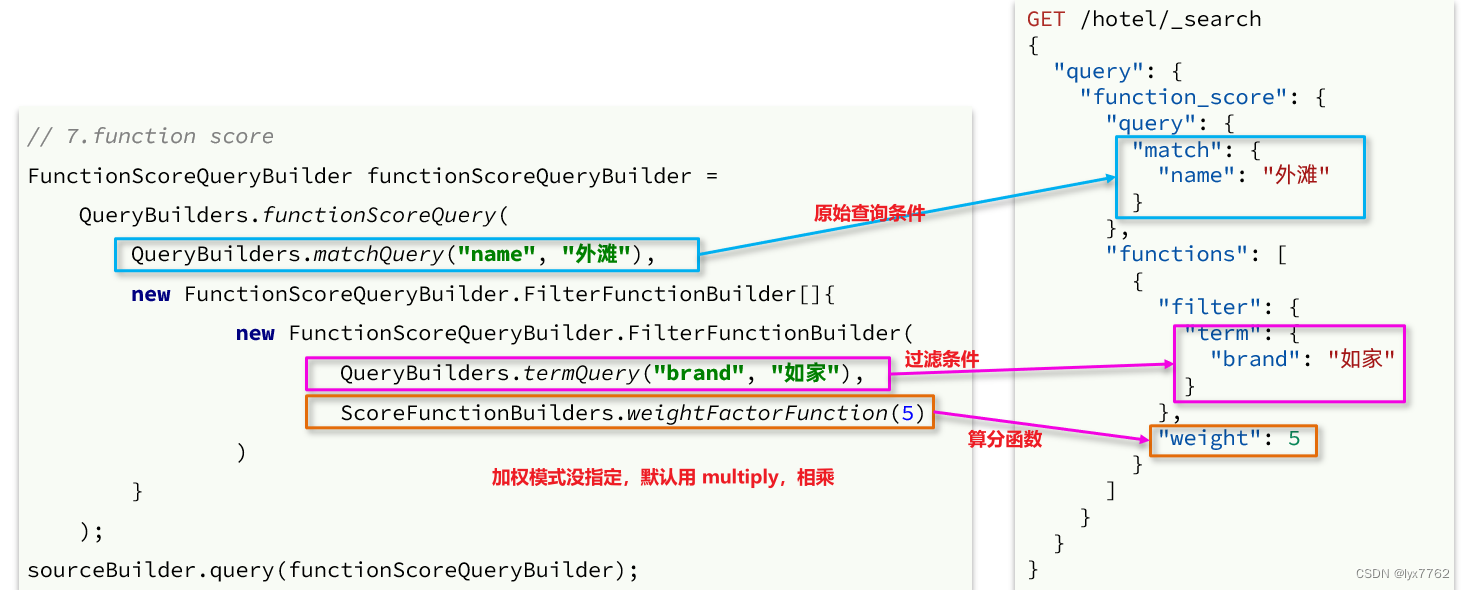
要让指定酒店在搜索结果中排名置顶。那么就需要自定义排序函数function_score了。function_score包含3个要素:
- 过滤条件:指定哪些文档需要重新计算相关得分
- 算分函数:计算函数得分
- 加权方式:函数得分和原始得分如何运算得到最终得分
在这个例子中,我们使用一个标记isAD来判断文档是否需要加分。我们给酒店添加一个字段isAD,Boolean类型
- true:是广告
- false:不是广告
那么例中的function_score的三要素如下
- 过滤条件 isAD为true
- 算分函数 直接使用权重
- 加权方式 默认相乘
给HotelDoc添加isAD字段
@Data
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
private Object distance;
private Boolean isAD;
}
随机选择1个酒店添加广告
POST /hotel/_update/2056126831
{
"doc": {
"isAD": true
}
}
我们可以将之前写的boolean查询作为原始查询条件放到query中,接下来就是添加过滤条件、算分函数、加权模式了。所以原来的代码依然可以沿用。
在HotelService类中的buildBasicQuery方法中添加相关代码:
// 原始查询,相关性算分的查询
boolQuery,
// function score的数组
new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{
// 其中的一个function score 元素
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
// 过滤条件
QueryBuilders.termQuery("isAD", true),
// 算分函数
ScoreFunctionBuilders.weightFactorFunction(10)
)
});
request.source().query(functionScoreQuery);















 608
608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









