






 这篇博客介绍了MySQL的基础知识,包括SQL语句的划分(DDL, DML, DCL),MySQL的数据类型,以及数据库范式(1NF, 2NF, 3NF)。同时,讲解了基础SQL操作如库操作、表操作和多表查询,以及如何创建、修改和查询数据。"
88804853,8289851,Maven配置与部署教程,"['Maven', 'Maven配置', 'Eclipse集成', '仓库配置', 'Spring框架']
这篇博客介绍了MySQL的基础知识,包括SQL语句的划分(DDL, DML, DCL),MySQL的数据类型,以及数据库范式(1NF, 2NF, 3NF)。同时,讲解了基础SQL操作如库操作、表操作和多表查询,以及如何创建、修改和查询数据。"
88804853,8289851,Maven配置与部署教程,"['Maven', 'Maven配置', 'Eclipse集成', '仓库配置', 'Spring框架']
MySQL是关系型数据库,和其他的关系型数据库最大的区别在于支持可插拔式的存储引擎,其中InNoDB非常强大;
MySQL设计是C/S客户端服务端模式,应用作为MySQL Client 向MySQL server发送请求,获取响应结果,因此MySQL非常适用于集群环境,方便做主从复制,读写分离操作;
为了提高效率,MySQL Client 和MySQL serve处于不同的主机上,当通过网络socket进行网络通信,如果在同一台主机上,Client和server之前是通过内存进行通信, 效率比socket通信要高;
MySQL serve的服务端模块采用IO复用技术+可伸缩的线程池,实现网络高并发的服务器的经典模型。
基础知识
SQL语句的划分
DDL(Data definition Language):数据定义语言,DDL语言是定义不同的数据库、表、列等数据库对象的定义,常见的语句关键字包括create、drop、alter等
DML(Data Manipulation Language):数据操纵语言,用于添加、删除、修改和查询数据库记录,常用的关键字包括insert、delete、update和select等
DCL(Data Control Language)数据控制语言,用户控制不同数据段直接的许可或访问级别的语句,定义了数据库、表、字段的用户访问权限和安全级别,主要的语句包括grant,remove
MySQL数据类型
数据类型是规定了数据的大小,因此使用时需要选择合适的类型,不仅会降低表占用的磁盘空间,间接减少磁盘IO次数,表的访问效率,和设计的表结构类型也是息息相关的。
MySQL中提供了多种的数据类型,包括整数类型,浮点类型,定点类型,日期和时间类型,字符串和二进制类型
归纳数据类型分为三类:数值类型,日期和时间类型和字符串类型
数值类型:包括定点类型、浮点类型和整数类型

日期/时间类型:

字符串类型 :文本数据类型

char(5) 12 占用是5字节
varchar(5) 12 3个字节(有一个结束符)
二进制类型数据:

选择数据类型时:尽量选择可以保证数据正确存储的最小数据类型,小的数据类型占用空间少,操作起来更快
数据库范式
实体:现实世界中客观存在并可以被区别对待的事务,比如“一个学生”,“一门课”等;
属性:实体上具有的某一特征。比如:性别是人的一个属性,在关系型数据库中,属性又是个物理概念,属性可以看做是“表的一列”;
元组:表中的一行就是一个元组;
分量:元组中某个属性值,在一个关系型数据库中,是一个操作原子,即关系型数据库在做任何操作的时候,属性是不可分的,否则就不是关系型数据库;
码:表中可以唯一确定一个元组的某个属性,如果这个码不止一个,那么都叫候选码,从中挑选的一个就叫做主码;
全码:如果一个码包含所有的属性,这个码称之为全码;
主属性:一个属性只要在一个候选码中出现过,这个属性就是主属性;
非主属性:与主属性相反,没有在任何候选码中出现过,这个属性就是非主属性;
外码:一个属性(或者属性组),他不是码,但是他是别的表的码,他就是外码。
第一范式(1NF):每一列保持原子特性
列都是基本数据项,不能进行分割,否则设计成一对多的实体关系
注意:不符合第一范式不能称之为关系型数据库
eg:用户表(用户id,用户姓名,省份证,用户地址)
地址信息,可以在细分为省、市、区等不可拆分字段
通过分析用户表不具有原子特性
需要拆分:
用户表:(用户id,用户姓名,省份证,省,市,区)
第二范式(2NF):属性完全依赖于主键(针对联合主键)
非主属性完全依赖于主关键字,如果不能依赖主键,应该拆分成新的主体,设计成一对多的关系
示例:选课表(学号,姓名,年龄,课程名称,成绩,学分)
将“学号,课程名称”是联合主键
姓名->联合主键 =>部分依赖(姓名依赖于学号,不依赖于课程名称)
年龄->联合主键 =>部分依赖(年龄依赖于学号,不依赖于课程名称)
成绩->联合主键 =>完全依赖
学分->联合主键 =>部分依赖(学分依赖于课程名称,不依赖于学号)
不满足第二范式,对选课表进行拆分:
学生表(学号,姓名,年龄)
课程学分表(课程名称,学分)
学生成绩表(学号,课程名称,成绩)
第三范式(3NF):属性不依赖于其他非主属性
要求一个数据库中不包含已在其他表中已包含的非主键信息
一般关系型数据库满足第三范式就可以
示例:学生表(学号,姓名,年龄,学院名称,学院地点,学院电话) 主键:学号
姓名,年龄,学院名称是完全依赖于主键
而学院电话、学院地点依赖于所在学院,并不依赖于主键学号
因此该设计不符合第三范式,就应该进行拆分,应该学员专门设计成一张表
拆分成:
学院表(学院名称、学院地址、学院电话)
学生表(学号、姓名、年龄、学院名称)
BC范式:每个表中只有一个候选键
第四范式:消除表中的多值依赖
应用范式越高,表越多,即会带来的问题:
1、查询表时需要连接多个表,增加了查询的复杂度;
1、查询表时需要连接多个表,降低了数据库的查询性能;
并不是范式越高越好,需要根据实际情况而定,第三范式已经很大程度上减少了数据冗余,基本预防了数据插入异常,更新异常,删除异常。
基础SQL
连接和断开数据库:
进行SQL操作之前需要连接MySQL服务器
mysql -u root -pXXXXX

退出数据库:exit;
库操作
创建数据库SQL语句:
create database database_name;

查看数据库SQL语句:
show databases;

删除数据库SQL语句:
drop database database_name;

选择数据库SQL语句:
use database_name;

查看数据库下的数据表的SQL语句:
show tables;
注意:该命令必须先选择一个库,使用use XXX后才能查看表

表操作
1、创建表
create table table_name(
属性名 数据类型 [完整性约束条件],
属性名 数据类型 [完整性约束条件],
...
属性名 数据类型 [完整性约束条件]
);
注意;创建表时需要选取合适的数据类型,而且还可以给字段添加完整性约束条件;
比如:主键,非空主键,唯一键...

示例:
CREATE TABLE `tulun` (
`id` int(11) NOT NULL,
`className` varchar(10) NOT NULL,
`content` varchar(50) DEFAULT '无'
)
2、查看表
①使用desc查看
desc table_name;

用desc命令可以查看表的字段名称,属性类型,是否为空,约束条件,默认值及备注信息;
②使用show命令
show create table table_name;
可以用‘;’或者‘\G’结束,后者打印格式更加清晰;
show命令可以打印出创建表时的SQL语句,并限制该表的存储引擎及字符编码信息;
3、修改表
在使用过程中不满足使用的情况下,使用alter命令修改
修改表名:
alter table old_Name rename new_Name;

修改字段的数据类型:
alter table table_name modify 属性名 数据类型;

修改字段名:
alter table 表名 change 旧属性名 新属性名 新数据类型;

增加字段:
alter table 表名 add 属性名 属性类型[完整性约束] [first | after 属性名2];

删除字段:
alter table 表名 drop 属性名;

修改属性排列位置:
alter table 表名 modify 属性名1 数据类型 first | after 属性名2 ;
修改表的存储引擎:
alter table 表名 engine=InNoDB|MyISAM;


4、数据插入到表
单条数据插入
insert into 表名(属性1,属性2,...,属性n)
values (值1,值2,...,值n);
批量数据插入
insert into 表名(属性1,属性2,...,属性n)
values
(值1,值2,...,值n),
(值1,值2,...,值n),
...,
(值1,值2,...,值n);
5、查询表
SQL的基本查询结构:
select 属性列表(*) from 表名
[where 条件表达式]
[group by 属性名1[ having 条件表达式2] ]
[order by 属性名2[ASC|DESC] ]
带in的子查询:
where 属性名 [not] in(元素1,元素2,...,元素n);
表示将in后面的元素存在的查询出来/剔除存在的元素
带between and的范围查询:
where 属性名 [not] between 取值1 and 取值2;
带like的通配符匹配查询:
where 属性名 [not] like '字符串'
此处的like后面的字符串可以携带通配符
%:表示0个或者任意长度的字符串
_:只能是表示单个通配符
空值查询:
where 属性名 is [not] null;
带and的多条件查询:
where 条件表达式1 and 条件表达式2[...and 条件表达式n];
带or的多条件查询:
where 条件表达式1 条件表达式2[...or 条件表达式n];
去重查询:
select distinct 属性名;
对结果排序:
order by 属性名 [ASC |DESC]
ASC:升序、默认是升序
DESC:降序
limit分页查询:
limit num; 不指定初始位置的limit记录数 num:记录数,一次最多加载num的数据
limit index, num; 指定起始位置 index初始位置 , num:记录数
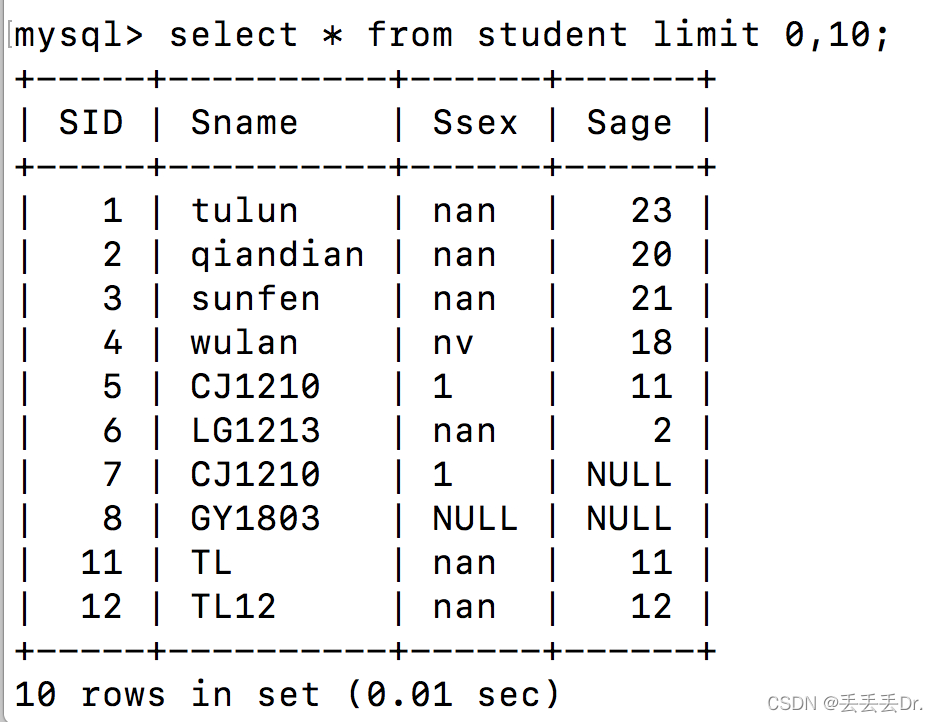
多表查询
SQL强大功能之一在于数据检索查询时执行连接(Join)表,可以很好的将很多表进行连接查询操作
表与表之间关系: 多表连接需要注意决定关系
方向性、主附关系
一对一关系: 在一对一关系中,A表中的一行最多只能匹配B表中的一行,反之亦然,创建的就是一对一关系
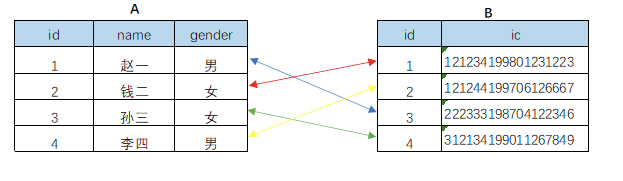
一对多关系: 最普通的一种关系,A表中的一行可以匹配B表中的多行,但B表中的一行只能匹配A表中的一行
例如:存在部门表和人员表之间具有一对多的关系,每个部门有很多的员工,但是每个员工只属于一个部门,
只有当一个相关列是一个主键或者具有唯一性约束时,才能创建一对多的关系
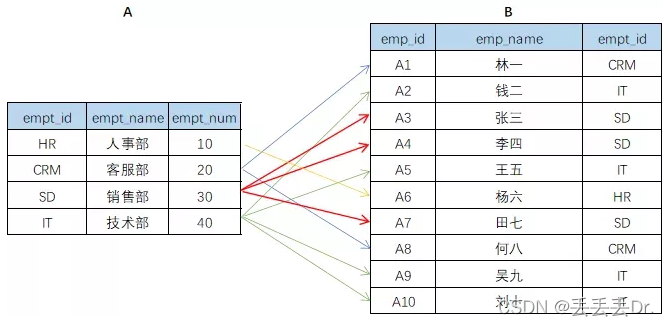
多对多关系: 在多对多关系中,A表中一行可以匹配B表中的多行,反之亦然。要创建这种关系,要创建第三张表,称之为结合表,他的主键由A表和B表的外部件组成
mysql> select * from student;
+------+--------+------+------+
| SID | Sname | Sage | Ssex |
+------+--------+------+------+
| 1 | 赵雷 | 20 | 男 |
| 2 | 钱电 | 20 | 男 |
| 3 | 孙风 | 21 | 男 |
| 4 | 吴兰 | 18 | 女 |
| 5 | 孙兰 | 17 | 女 |
+------+--------+------+------+
5 rows in set (0.02 sec)
mysql> select * from sc;
+------+------+-------+
| SID | CID | score |
+------+------+-------+
| 1 | 1 | 80 |
| 1 | 2 | 71 |
| 1 | 3 | 87 |
| 2 | 1 | 88 |
| 2 | 2 | 70 |
| 2 | 3 | 89 |
| 3 | 1 | 68 |
| 3 | 2 | 78 |
| 3 | 3 | 87 |
| 4 | 1 | 67 |
| 4 | 2 | 58 |
| 4 | 3 | 89 |
| 5 | 1 | 56 |
| 5 | 2 | 89 |
| 6 | 3 | 38 |
+------+------+-------+
15 rows in set (0.01 sec)
学生表和成绩表是一对多的关系
笛卡尔积
笛卡尔积的元素是元组,关系A和关系B的笛卡尔积可以记为(AXB),如果A表a条,B表B条,那么A和B的笛卡尔积为(a+b)列数,(a*b)行的元素集合
检索出来的条目是将第一个表中的行数乘以第二个表中的行数
select <字段名称1>[字段名称2,字段名称3,...字段名n] from <表1>,<表2> where <检索条件>
内连接:按照连接条件,返回两张表中的满足条件的记录
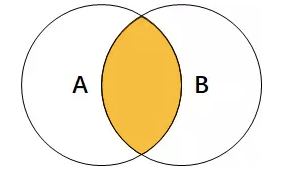
内连接称之为普通连接或自然连接
等值连接:当条件为”=“的连接,称之为等值连接
mysql> select * from student,sc where student.SID = sc.SID;
+------+--------+------+------+------+------+-------+
| SID | Sname | Sage | Ssex | SID | CID | score |
+------+--------+------+------+------+------+-------+
| 1 | 赵雷 | 20 | 男 | 1 | 1 | 80 |
| 1 | 赵雷 | 20 | 男 | 1 | 2 | 71 |
| 1 | 赵雷 | 20 | 男 | 1 | 3 | 87 |
| 2 | 钱电 | 20 | 男 | 2 | 1 | 88 |
| 2 | 钱电 | 20 | 男 | 2 | 2 | 70 |
| 2 | 钱电 | 20 | 男 | 2 | 3 | 89 |
| 3 | 孙风 | 21 | 男 | 3 | 1 | 68 |
| 3 | 孙风 | 21 | 男 | 3 | 2 | 78 |
| 3 | 孙风 | 21 | 男 | 3 | 3 | 87 |
| 4 | 吴兰 | 18 | 女 | 4 | 1 | 67 |
| 4 | 吴兰 | 18 | 女 | 4 | 2 | 58 |
| 4 | 吴兰 | 18 | 女 | 4 | 3 | 89 |
| 5 | 孙兰 | 17 | 女 | 5 | 1 | 56 |
| 5 | 孙兰 | 17 | 女 | 5 | 2 | 89 |
+------+--------+------+------+------+------+-------+
14 rows in set (0.01 sec)
外连接: 外连接不仅包含符合条件的连接的行,而且还包含左表(左外连接)、右表(右外连接)中所有的数据行
左连接:left join
左连接是以左表中的数据为基准,若左表中有数据而右表中没有数据,则显示左表中的数据,右表中的数据显示为空

select <字段名称1>[字段名称2,字段名称3,...字段名n]
from <表名1>
left join<表名2>
on <连接条件>
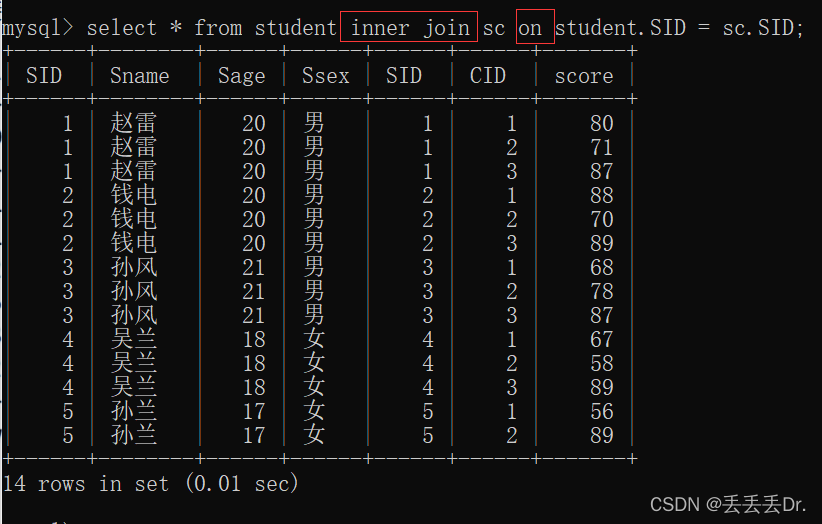
mysql> select * from student left join sc on student.SID = sc.SID;
+------+--------+------+------+------+------+-------+
| SID | Sname | Sage | Ssex | SID | CID | score |
+------+--------+------+------+------+------+-------+
| 1 | 赵雷 | 20 | 男 | 1 | 1 | 80 |
| 1 | 赵雷 | 20 | 男 | 1 | 2 | 71 |
| 1 | 赵雷 | 20 | 男 | 1 | 3 | 87 |
| 2 | 钱电 | 20 | 男 | 2 | 1 | 88 |
| 2 | 钱电 | 20 | 男 | 2 | 2 | 70 |
| 2 | 钱电 | 20 | 男 | 2 | 3 | 89 |
| 3 | 孙风 | 21 | 男 | 3 | 1 | 68 |
| 3 | 孙风 | 21 | 男 | 3 | 2 | 78 |
| 3 | 孙风 | 21 | 男 | 3 | 3 | 87 |
| 4 | 吴兰 | 18 | 女 | 4 | 1 | 67 |
| 4 | 吴兰 | 18 | 女 | 4 | 2 | 58 |
| 4 | 吴兰 | 18 | 女 | 4 | 3 | 89 |
| 5 | 孙兰 | 17 | 女 | 5 | 1 | 56 |
| 5 | 孙兰 | 17 | 女 | 5 | 2 | 89 |
| 11 | 小红 | 23 | 男 | NULL | NULL | NULL |
| 15 | 小徐 | 22 | 男 | NULL | NULL | NULL |
| 17 | 徐志 | 13 | 男 | NULL | NULL | NULL |
+------+--------+------+------+------+------+-------+
17 rows in set (0.00 sec)
右连接
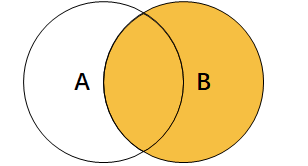
右连接是以右表的数据为基准,若右表有数据且左表没有数据,则显示右表中的数据,左表中的数据则显示为空
mysql> select * from student right join sc on student.SID = sc.SID;
+------+--------+------+------+------+------+-------+
| SID | Sname | Sage | Ssex | SID | CID | score |
+------+--------+------+------+------+------+-------+
| 1 | 赵雷 | 20 | 男 | 1 | 1 | 80 |
| 1 | 赵雷 | 20 | 男 | 1 | 2 | 71 |
| 1 | 赵雷 | 20 | 男 | 1 | 3 | 87 |
| 2 | 钱电 | 20 | 男 | 2 | 1 | 88 |
| 2 | 钱电 | 20 | 男 | 2 | 2 | 70 |
| 2 | 钱电 | 20 | 男 | 2 | 3 | 89 |
| 3 | 孙风 | 21 | 男 | 3 | 1 | 68 |
| 3 | 孙风 | 21 | 男 | 3 | 2 | 78 |
| 3 | 孙风 | 21 | 男 | 3 | 3 | 87 |
| 4 | 吴兰 | 18 | 女 | 4 | 1 | 67 |
| 4 | 吴兰 | 18 | 女 | 4 | 2 | 58 |
| 4 | 吴兰 | 18 | 女 | 4 | 3 | 89 |
| 5 | 孙兰 | 17 | 女 | 5 | 1 | 56 |
| 5 | 孙兰 | 17 | 女 | 5 | 2 | 89 |
| NULL | NULL | NULL | NULL | 6 | 3 | 38 |
+------+--------+------+------+------+------+-------+
15 rows in set (0.00 sec)
设置字符集编码问题:
1、学生表
Student(SID,Sname,Sage,Ssex)
--SID 学生编号,Sname 学生姓名,Sage 年龄,Ssex 学生性别
2.课程表
Course(CID,Cname,TID)
--CID --课程编号,Cname 课程名称,TID 教师编号
3.教师表
Teacher(TID,Tname)
--TID 教师编号,Tname 教师姓名
4.成绩表
SC(SID,CID,score)
--SID 学生编号,CID 课程编号,score 分数
学生表:
编号 姓名 年龄 性别
1 赵雷 20 男
2 钱电 20 男
3 孙风 21 男
4 吴兰 18 女
5 孙兰 17 女
课程表:
课程号 课程名称 教师编号
1 语文 2
2 数学 1
3 英语 3
教师表:
教师编号 教师名
1 张三
2 李四
3 王五
成绩表:
学生编号 课程编号 分数
1 1 80
1 2 71
1 3 87
2 1 88
2 2 70
2 3 89
3 1 68
3 2 78
3 3 87
4 1 67
4 2 58
4 3 89
5 1 56
5 2 89
6 3 38
1、查询"01"课程比"02"课程成绩高的学生的信息及课程分数
select 查询结果 from 表 where 条件表达式
关注查询结果、查询表、查询条件
通过分析:
学生信息-》学生表
课程分数-》成绩表
”01“课程、”02“课程 -》成绩表、课程表(不需要)
表:学生表、成绩表 from
查询结果:学生信息、课程分数
条件表达式:查询"01"课程比"02"课程成绩高的学生-》同一个学生,既有”01“课程分数且有”02“课程分数,
且”01“课程分数比”02“课程分数高 成绩表当做两张表
select s.SID,s.Sname,s.Sage,s.Ssex ,sc1.score '01课程成绩',sc2.score '02 课程成绩' from student as s,sc as sc1,sc as sc2 where s.SID =sc1.SID and s.SID= sc2.SID and sc1.CID=1 and sc2.CID = 2 and sc1.score > sc2.score;
+------+--------+------+------+----------------+----------------+
| SID | Sname | Sage | Ssex | 01课程成绩 | 02课程成绩 |
+------+--------+------+------+----------------+----------------+
| 1 | 赵雷 | 20 | 男 | 80 | 71 |
| 2 | 钱电 | 20 | 男 | 88 | 70 |
| 4 | 吴兰 | 18 | 女 | 67 | 58 |
+------+--------+------+------+----------------+----------------+
3 rows in set (0.00 sec)
2、查询平均成绩大于等于60分的同学的学生编号和学生姓名和平均成绩 avg()
分析:
学生编号:student,SC 学生姓名:student 成绩:SC -》 from student,SC
select SID,Sname, avg(score)
查询平均成绩大于等于60分的同学 ->每一个同学所有课程成绩的平均值大于等于60->
分组 :group by SID having avg(score) >=60;
select s.SID,s.Sname,avg(SC.score) as '平均成绩'from student s,SC where s.SID= SC.SID group by s.SID having avg(SC.score) >= 60;
+------+--------+-------------------+
| SID | Sname | 平均成绩 |
+------+--------+-------------------+
| 1 | 赵雷 | 79.33333333333333 |
| 2 | 钱电 | 82.33333333333333 |
| 3 | 孙风 | 77.66666666666667 |
| 4 | 吴兰 | 71.33333333333333 |
| 5 | 孙兰 | 72.5 |
+------+--------+-------------------+
5 rows in set (0.01 sec)
3、查询在sc表中不存在成绩的学生信息。
分析:
表分析: 学生信息:student 成绩:SC =》表:student,sc
查询条件分析:SID,Sname,Sage,Ssex
where表达式:在sc表中不存在成绩的学生信息-》在学生表中存在的学生但是在SC表中没有成绩=》
not in(不在)=》SID not in
mysql> select * from student where SID not in (select sc.SID from sc);
+------+--------+------+------+
| SID | Sname | Sage | Ssex |
+------+--------+------+------+
| 11 | 小红 | 23 | 男 |
| 15 | 小徐 | 22 | 男 |
| 17 | 徐志 | 13 | 男 |
+------+--------+------+------+
3 rows in set (0.01 sec)
4、查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩
选课总数:count(CID),总成绩:sum(score):
分析表:学生编号:student,SC、学生姓名:student 选课总数:SC,总成绩:SC =>student ,SC
分析查询结果:SID,Sname,count(CID),sum(score)
分析条件:查询所有同学:student表中所有数据
mysql> select s.SID,s.Sname,count(sc.CID) '选课总数',sum(sc.score) '总成绩'
-> from student s left join SC sc on s.SID=sc.SID
-> group by s.SID;
+------+--------+--------------+-----------+
| SID | Sname | 选课总数 | 总成绩 |
+------+--------+--------------+-----------+
| 1 | 赵雷 | 3 | 238 |
| 2 | 钱电 | 3 | 247 |
| 3 | 孙风 | 3 | 233 |
| 4 | 吴兰 | 3 | 214 |
| 5 | 孙兰 | 2 | 145 |
| 11 | 小红 | 0 | NULL |
| 15 | 小徐 | 0 | NULL |
| 17 | 徐志 | 0 | NULL |
+------+--------+--------------+-----------+
8 rows in set (0.00 sec)
5、查询"李"姓老师的数量
mysql> select count(TID) from teacher where Tname like '李%';
+------------+
| count(TID) |
+------------+
| 1 |
+------------+
1 row in set (0.00 sec)
6、查询学过"张三"老师授课的同学的信息
分析表:"张三"老师:Teacher 同学的信息:student => Course、SC、student、Teacher
分析查询结果:student.*
分析查询条件:学过"张三"老师授课=》
mysql> select * from student where SID in(
-> select SID from SC where CID in(
-> select CID from Course where TID in(
-> select TID from Teacher where Tname='张三')));
+------+--------+------+------+
| SID | Sname | Sage | Ssex |
+------+--------+------+------+
| 1 | 赵雷 | 20 | 男 |
| 2 | 钱电 | 20 | 男 |
| 3 | 孙风 | 21 | 男 |
| 4 | 吴兰 | 18 | 女 |
| 5 | 孙兰 | 17 | 女 |
+------+--------+------+------+
5 rows in set (0.00 sec)
7、查询学过编号为"01"并且也学过编号为"02"的课程的同学的信息
分析表:同学的信息:student 编号为"01"并且也学过编号为"02":SC =》student、SC
分析查询结果:同学的信息:student.*
分析查询条件:from SC sc1,SC sc2 where sc1.SID=sc2.SID and sc1.CID=1 and sc2.CID=2;
mysql> select s.*
-> from student s,SC sc1,SC sc2
-> where s.SID=sc1.SID and sc1.SID=sc2.SID and sc1.CID=1 and sc2.CID=2;
+------+--------+------+------+
| SID | Sname | Sage | Ssex |
+------+--------+------+------+
| 1 | 赵雷 | 20 | 男 |
| 2 | 钱电 | 20 | 男 |
| 3 | 孙风 | 21 | 男 |
| 4 | 吴兰 | 18 | 女 |
| 5 | 孙兰 | 17 | 女 |
+------+--------+------+------+
5 rows in set (0.00 sec)
8、查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
平均成绩:avg()
分析表:学号:SC,student 姓名:student 成绩:sc =>student ,sc
分析查询结果:SID,Sname,avg(score)
分析查询条件:查询两门及其以上不及格课程的同学的学号=》 查询小于等于60分的所有数据, 按照学号进行分组,判断同一个学号计数数量大于等于2=》
where score < 60 group by SID having count(CID) >=2
mysql> select s.*
-> from student s,SC sc
-> where s.SID=sc.SID and sc.score < 60 group by(sc.SID) having count(sc.CID) >= 2;
Empty set (0.00 sec)

















 2915
2915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









