






本文将动画讲解LLM中的一些重点,内容包括:
Transformer: LLM的核心架构是Transformer,当下最成功的大模型例如,GPT4-o、Claude3、LLama3都是Transformer Decoder架构。
自注意力机制: Transformer中的核心是自注意力机制,自注意力机制能够获取序列的上下文信息,这也是Transformer有别于其它时序模型的关键所在。
MoE: 除了注意力,还有MLP层,MLP层占据了大部分参数,为了提升长序列文本的计算效率,有人提出MoE来替代MLP。
RHLF: 大模型训练过程包括预训练,有监督微调和RHLP,其中RHLP是让大模型向人类价值观对齐的关键步骤。
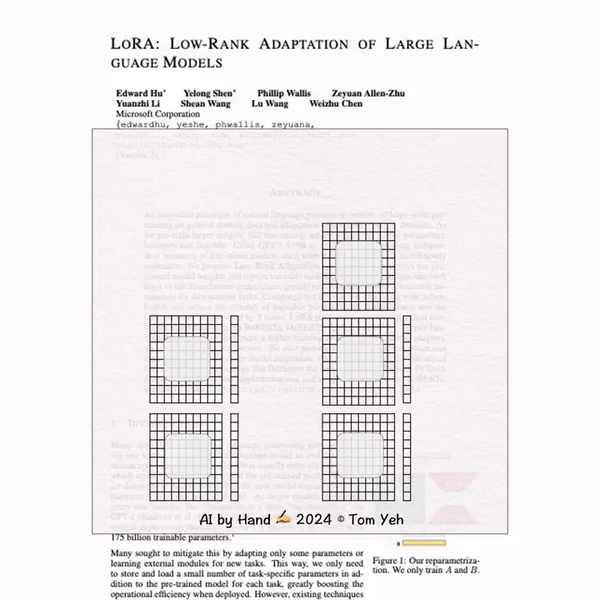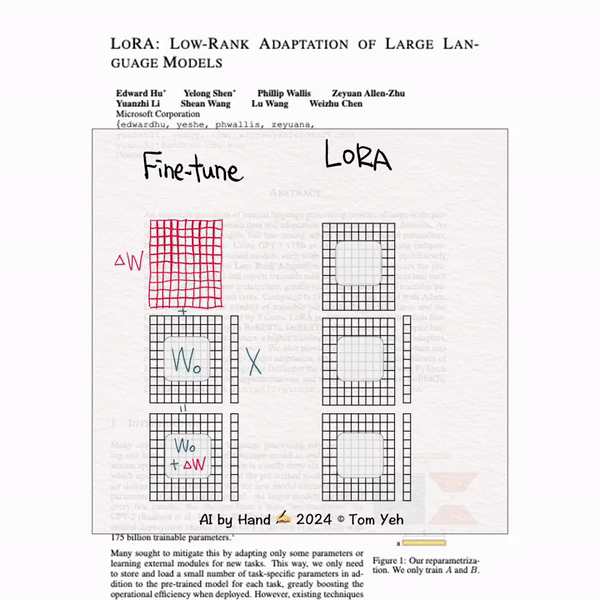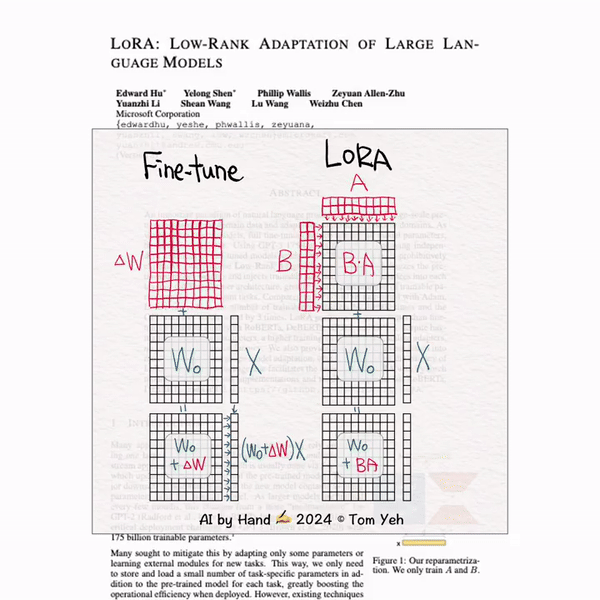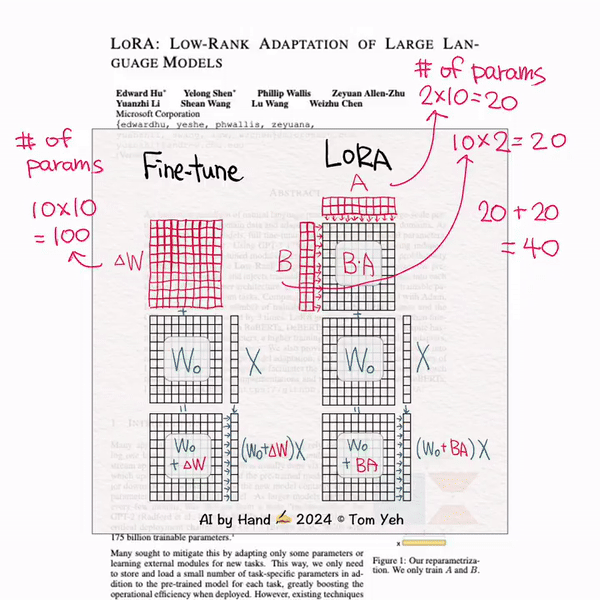
LORA: 微调大模型时,可以全部参数都进行更新,也可以只更新两个小矩阵,这两个小矩阵可以看作一个参数矩阵的低秩分解,由于这两个小矩阵的参数量远小于原参数矩阵,所以可以加速微调过程。
向量数据库: 通过RAG限定LLM的上下文,能让大模型回答的更准确,而RAG的核心就是构造向量数据库。
[自注意力] 手书动画✍️
自注意力使得LLMs能够理解上下文。
它是如何工作的?
本练习演示了如何手动计算6维->3维的注意力头。注意,如果我们有两个这样的实例,我们就得到了6维->6维的注意力(即多头注意力,n=2)。
– 𝗚𝗼𝗮𝗹 –
将 [6维特征 🟧] 转换为右下角的 [3维注意力加权特征 🟦]
– 𝗪𝗮𝗹𝗸𝘁𝗵𝗿𝗼𝘂𝗴𝗵 –
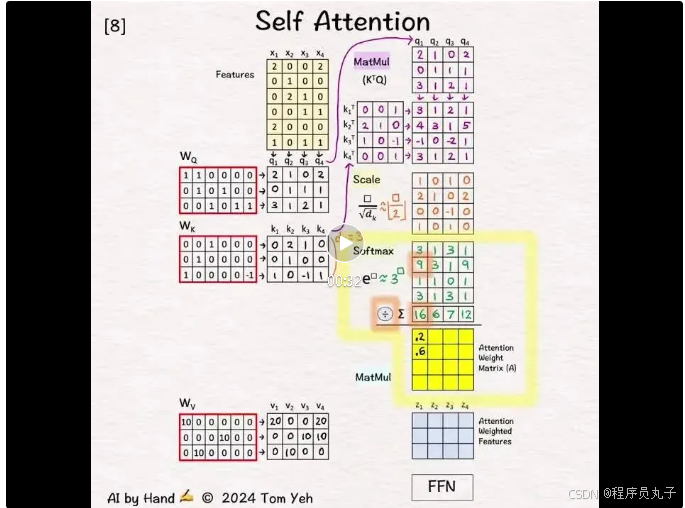
[1] 给定
↳ 一组4个特征向量(6维):x1, x2, x3, x4
[2] 查询、键、值
↳ 将特征x通过线性变换矩阵WQ、WK和WV进行相乘,得到查询向量(q1, q2, q3, q4),键向量(k1, k2, k3, k4),和值向量(v1, v2, v3, v4)。
↳ “自”指输入序列的各个位置之间建立关系,而不依赖于外部的信息源。
[3] 🟪 准备进行矩阵乘法
↳ 复制查询向量
↳ 复制键向量的转置
[4] 🟪 矩阵乘法
↳ 将K^T和Q相乘
↳ 这相当于对每对查询和键向量进行点积运算。
↳ 目的是使用点积作为每对键值匹配得分的估计。
↳ 这种估计是合理的,因为点积是两个向量之间余弦相似度的分子。
[5] 🟨 缩放
↳ 将每个元素除以dk的平方根,即键向量的维度(dk=3)。
↳ 除以dk的平方根,是为了解决softmax 函数会造成梯度消失的问题。
↳ 目的是在即使我们将dk缩放到32、64或128时,也能规范化dk对匹配得分的影响。
↳ 为简化手算,我们用[□/2的向下取整]代替[□/sqrt(3)]。
[6] 🟩 Softmax: e^x
↳ 将e提升到每个单元格中数字的幂次
↳ 为简化手算,我们用3□代替e□。
[7] 🟩 Softmax: ∑
↳ 对每一列求和
[8] 🟩 Softmax: 1 / sum
↳ 对每一列,使用列和除以每个元素
↳ 目的是将每一列标准化,使得数字之和为1。换句话说,每一列是注意力的概率分布,总共有四个。
↳ 结果是注意力权重矩阵(A)(黄色)
[9] 🟦 矩阵乘法
↳ 将值向量(Vs)与注意力权重矩阵(A)相乘
↳ 结果是注意力加权特征Zs。
↳ 它们被馈送到下一层中的位置相关前馈网络。
[Transformer] 手书动画 ✍️
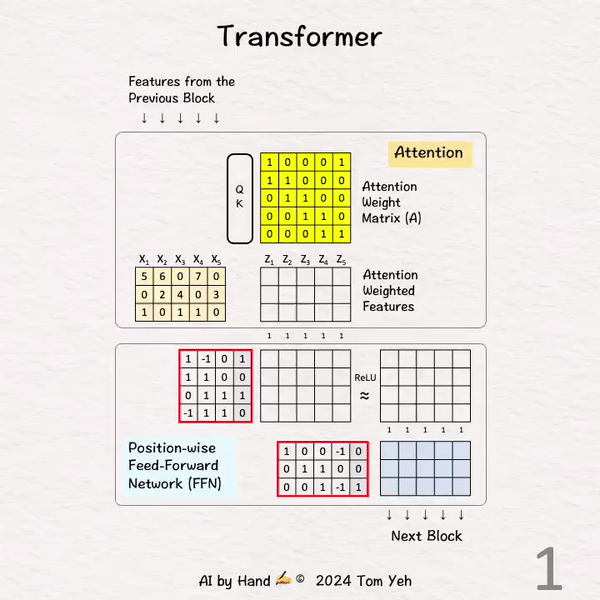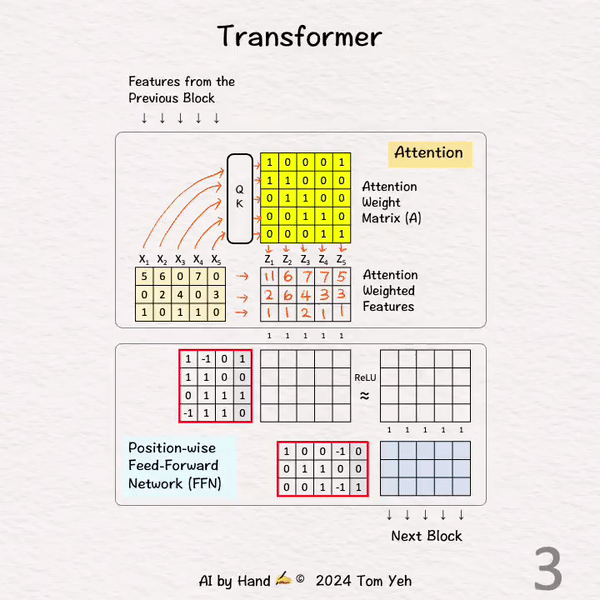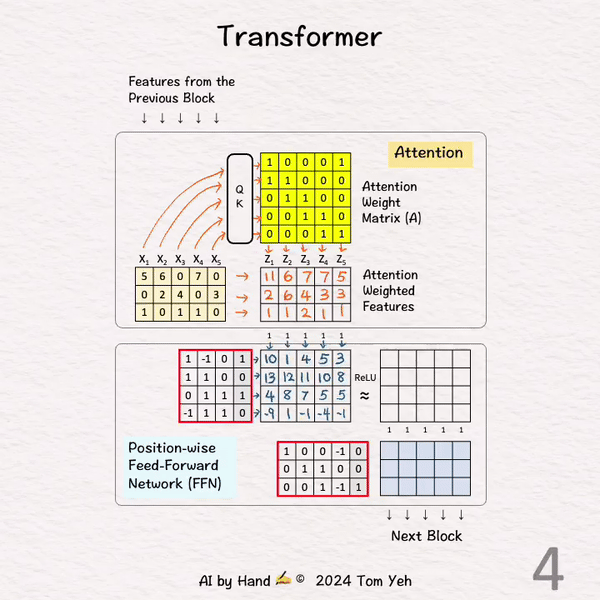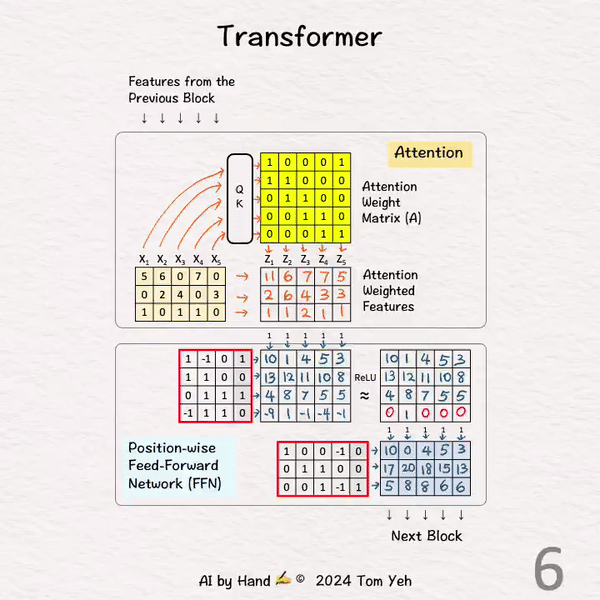
学习 Transformer 架构,就像打开汽车引擎盖,看到各种引擎部件:嵌入、位置编码、前馈网络、注意力加权、自注意力、交叉注意力、多头注意力、层归一化、跳跃连接、softmax、线性、Nx、右移、查询、键、值、掩码。这些术语的列表让人感到不知所措!
Transformer(🚗)真正运行的关键部件是什么?
在我看来,🔑 关键是:[注意力加权] 和 [前馈网络] 的结合。
所有其他部分都是为了让 Transformer(🚗)运行得更快、更持久的增强功能,这些增强功能仍然很重要,因为这些增强功能使我们能够开发出“大型”语言模型。🚗 -> 🚚
操作步骤
[1] 给定
↳ 来自上一个模块的输入特征(5 个位置)
[2] 注意力
↳ 将所有 5 个特征输入到查询-键注意力模块(QK)中,获得注意力权重矩阵(A)。我将跳过该模块的详细信息。在后续文章中,我会详细说明这个模块。
[3] 注意力加权
↳ 将输入特征与注意力权重矩阵相乘,得到注意力加权特征(Z)。注意,仍然有 5 个位置。
↳ 其效果是跨位置(水平)组合特征,在这种情况下,X1 := X1 + X2,X2 := X2 + X3…等等。
[4] FFN: 第一层
↳ 将所有 5 个注意力加权特征输入第一层。
↳ 将这些特征与权重和偏置相乘。
↳ 其效果是跨特征维度(垂直)组合特征。
↳ 每个特征的维度从 3 增加到 4。
↳ 注意,每个位置都由相同的权重矩阵处理。这就是“逐位置”一词的含义。
↳ 请注意,FFN 本质上是一个多层感知器。
[5] ReLU
↳ ReLU 将负值设为零。
[6] FFN: 第二层
↳ 将所有 5 个特征(d=3)输入第二层。
↳ 每个特征的维度从 4 减少回 3。
↳ 输出被输入到下一个模块以重复此过程。
↳ 请注意,下一个模块将有一套完全独立的参数。
总体来说,这两个关键部分:注意力和 FFN,在跨位置和跨特征维度上转换特征。这就是让 Transformer(🚗)运行的原因!
[Reinforcement Learning from Human Feedback(RLHF)] 手书动画✍️
昨天,Jan Leike (@janleike) 宣布加入#Anthropic,领导他们的"超级对齐"任务。他是人类反馈强化学习(#RLHF)的共同发明人。RLHF是如何工作的?
[1] 给定
↳ 奖励模型 (RM)
↳ 大型语言模型 (LLM)
↳ 两对 (提示词, 下一词)
训练 RM
目标: 学会给予获胜者更高的奖励
[2] 偏好
↳ 人类审查两对并选择一个"获胜者"
↳ (doc is, him) < (doc is, them) 因为前者存在性别偏见。
[3]-[6] 计算对1(失败者)的奖励
[3] 词嵌入
↳ 查找词嵌入作为RM的输入
[4] 线性层
↳ 将输入向量与RM的权重和偏置相乘(4x4矩阵)
↳ 输出: 特征向量
[5] 平均池化
↳ 将特征与列向量[1/3,1/3,1/3]相乘,实现跨三个位置的特征平均
↳ 输出: 句子嵌入向量
[6] 输出层
↳ 将句子嵌入与权重和偏置相乘(1x5矩阵)
↳ 输出: 奖励 = 3
[7] 对2(获胜者)的奖励
↳ 重复 [3]-[6]
↳ 输出: 奖励 = 5
[8] 获胜者 vs 失败者的奖励
↳ 计算获胜者和失败者奖励之间的差异
↳ RM希望这个差距为正且尽可能大
↳ 5 - 3 = 2
[9] 损失梯度
↳ 将奖励差距映射为概率值作为预测: σ(2) ≈ 0.9
↳ 计算损失梯度: 预测 - 目标: 0.9 - 1 = -0.1
↳ 目标是1,因为我们想最大化奖励差距。
↳ 运行反向传播和梯度下降来更新RM的权重和偏置(紫色边框)
对齐 LLM
目标: 更新权重以最大化奖励
[10] 提示词 -> 嵌入
↳ 这个提示词从未直接收到人类反馈
↳ [S] 是特殊的开始符号
[11] Transformer
↳ 注意力机制 (黄色)
↳ 前馈 (4x2 权重和偏置矩阵)
↳ 输出: 3个"转换后"的特征向量,每个位置一个
↳ 更多细节见我之前的帖子 8. Transformer []
[12] 输出概率
↳ 应用线性层将每个转换后的特征向量映射到词汇表上的概率分布。
[13] 采样
↳ 应用贪婪方法,选择得分最高的词
↳ 对于输出1和2,模型准确预测了下一个词
↳ 对于第3个输出位置,模型预测"him"
[14] 奖励模型
↳ 新对 (CEO is, him) 被输入到奖励模型
↳ 过程与 [3]-[6] 相同
↳ 输出: 奖励 = 3
[15] 损失梯度
↳ 我们将损失设为奖励的负值。
↳ 损失梯度简单地是常数 -1。
↳ 运行反向传播和梯度下降来更新LLM的权重和偏置(红色边框)
[LORA] 手书动画✍️
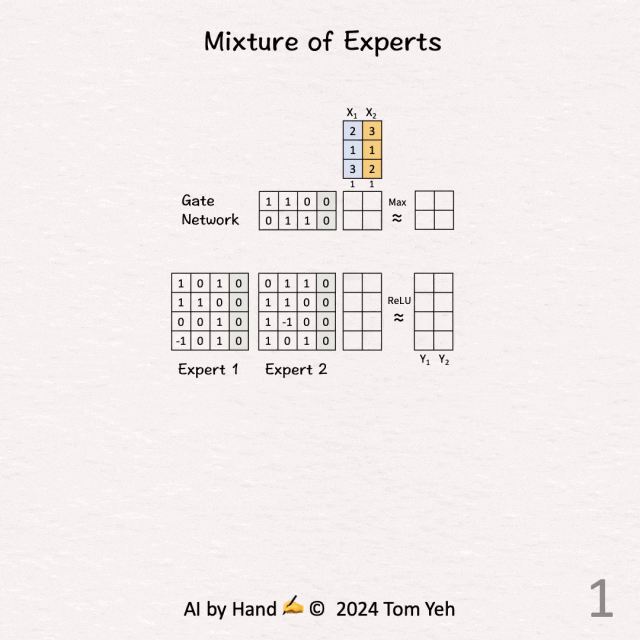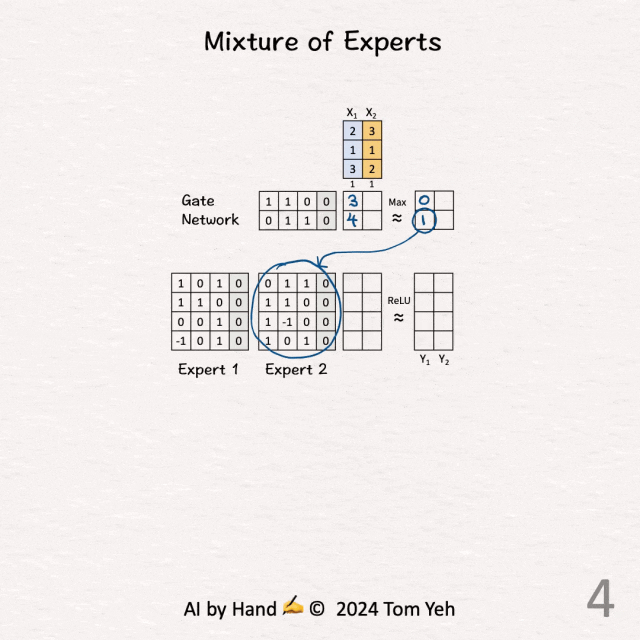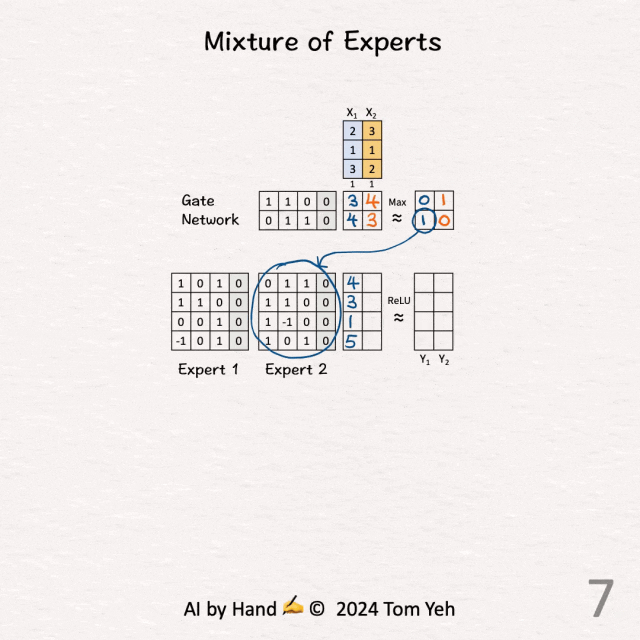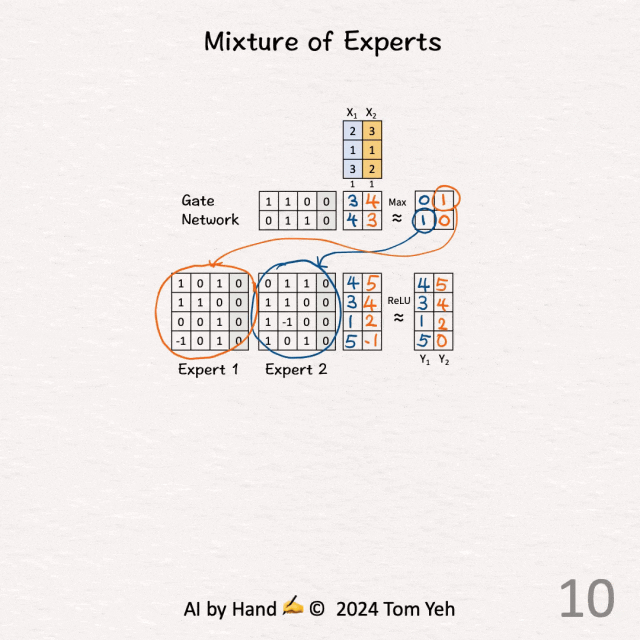
[Mixture of Experts (MoE)] 手书动画✍️
[Vector Database]手书动画✍️
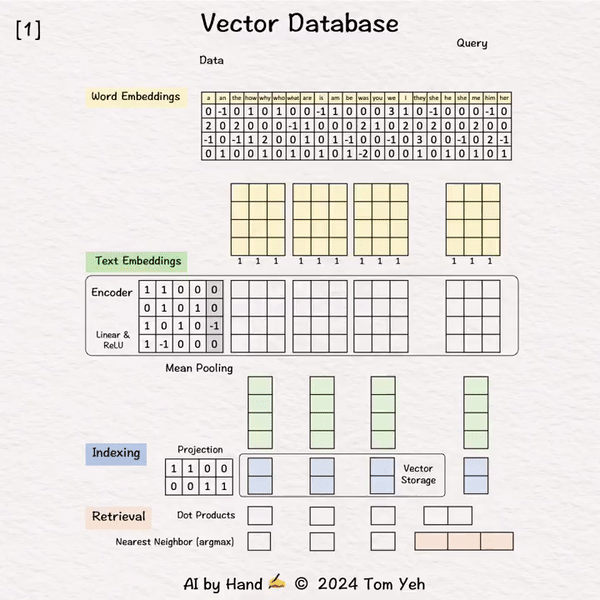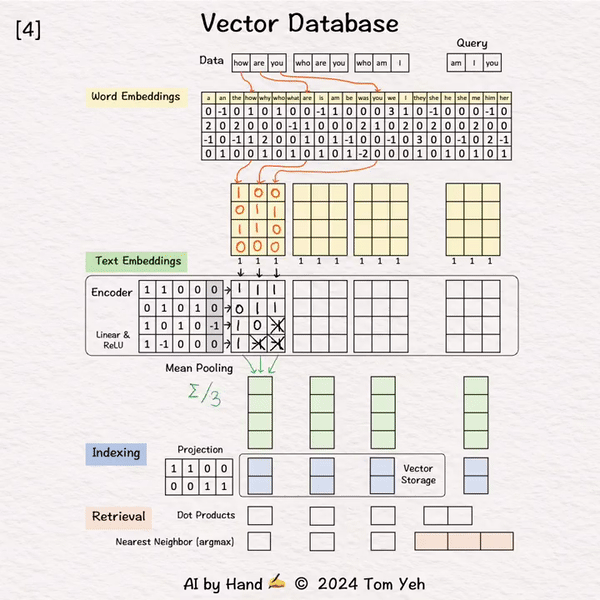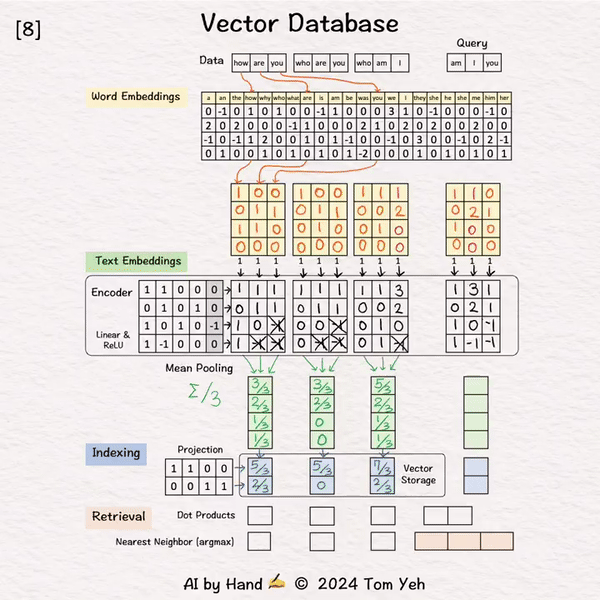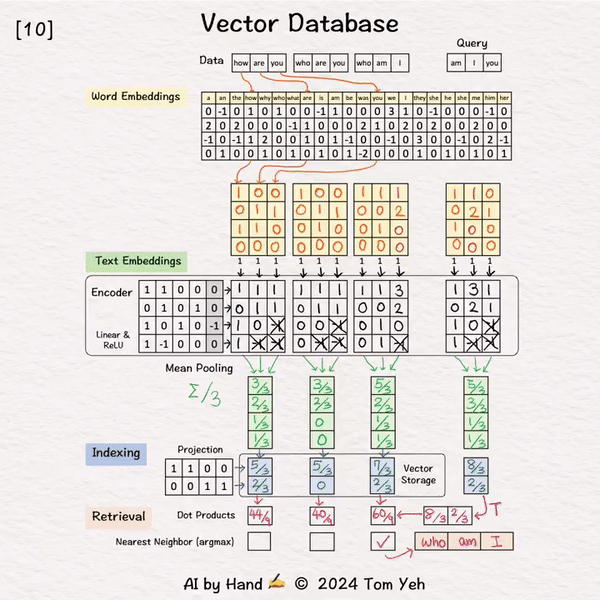
向量数据库正在革新我们搜索和分析复杂数据的方式。它们已成为检索增强生成(#RAG)的骨干。向量数据库是如何工作的?
[1] 给定
↳ 一个包含三个句子的数据集,每个句子有3个单词(或标记)
↳ 在实践中,一个数据集可能包含数百万或数十亿个句子。最大标记数可能是数万(例如,mistral-7b的32,768)。
处理 “how are you”
[2] 词嵌入
↳ 对于每个单词,从22个向量的表中查找相应的词嵌入向量,其中22是词汇量大小。
↳ 在实践中,词汇量可能有数万。词嵌入维度在千位数(例如,1024,4096)
[3] 编码
↳ 将词嵌入序列输入编码器,得到每个单词对应的特征向量序列。
↳ 这里,编码器是一个简单的单层感知器(线性层 + ReLU)
↳ 在实践中,编码器是transformer或其众多变体之一。
[4] 平均池化
↳ 使用"平均池化"将特征向量序列合并为单个向量,即在列上取平均值。
↳ 结果是一个单一向量。我们通常称之为"文本嵌入"或"句子嵌入"。
↳ 其他池化技术也可能,如CLS。但平均池化是最常见的。
[5] 索引
↳ 通过投影矩阵减少文本嵌入向量的维度。降维率为50%(4->2)。
↳ 在实践中,这个投影矩阵中的值要随机得多。
↳ 目的类似于哈希,即获得一个短表示以允许更快的比较和检索。
↳ 结果得到的降维索引向量保存在向量存储中。
[6] 处理 “who are you”
↳ 重复 [2]-[5]
[7] 处理 “who am I”
↳ 重复 [2]-[5]
现在我们已经在向量数据库中索引了我们的数据集。
[8] 查询: “am I you”
↳ 重复 [2]-[5]
↳ 结果是一个2维查询向量。
[9] 点积
↳ 计算查询向量与数据库向量之间的点积。它们都是2维的。
↳ 目的是使用点积来估计相似度。
↳ 通过转置查询向量,这一步变成了矩阵乘法。
[10] 最近邻
↳ 通过线性扫描找到最大点积。
↳ 点积最高的句子是 “who am I”
↳ 在实践中,因为扫描数十亿向量很慢,我们使用近似最近邻(ANN)算法,如分层可导航小世界(HNSW)。
在大模型时代,我们如何有效的去学习大模型?
现如今大模型岗位需求越来越大,但是相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也_想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把都打包整理好,希望能够真正帮助到大家_。
一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,下面是我整理好的一套完整的学习路线,希望能够帮助到你们学习AI大模型。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF书籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型各大场景实战案例

结语
【一一AGI大模型学习 所有资源获取处(无偿领取)一一】
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}