






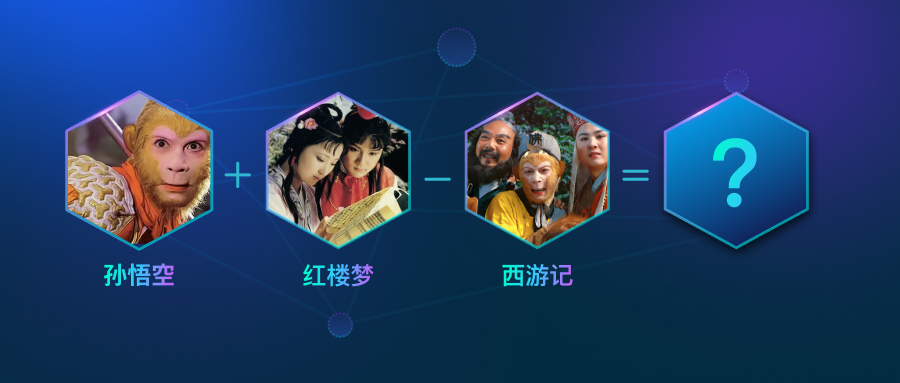
一起来开个脑洞,如果孙悟空穿越到红楼梦的世界,他会成为谁?贾宝玉,林黛玉,还是薛宝钗?这看似一道文学题,但是我们不妨用数学方法来求解:孙悟空 + 红楼梦 - 西游记 = ?
文字也能做运算?当然不行,但是把文字转换成数字之后,就可以用来计算了。而这个过程,叫做 “向量嵌入”。为什么要做向量嵌入?因为具有语义意义的数据,比如文本或者图像,人可以分辨相关程度,但是无法量化,更不能计算。比如,对于一组词“孙悟空、猪八戒、沙僧、西瓜、苹果、香蕉“,我会把“孙悟空、猪八戒、沙僧”分成一组,“西瓜、苹果、香蕉”分成另一组。但是,如果进一步提问,“孙悟空”是和“猪八戒”更相关,还是和“沙僧”更相关呢?这很难回答。
而把这些信息转换成向量后,相关程度就可以通过它们在向量空间中的距离量化。甚至于,我们可以做 孙悟空 + 红楼梦 - 西游记 = ? 这样的脑洞数学题。
01.
文字是怎么变成向量的
怎么把文字变成向量呢?首先出现的是词向量,其中的代表是 word2vec 模型。它先准备一张词汇表,给每个词随机赋予一个向量,然后利用大量语料,通过 CBOW(Continuous Bag-of-Words)和 Skip-Gram 两种方法训练模型,不断优化字词的向量。
CBOW 使用上下文(周围的词)预测目标词[^1],而 Skip-Gram 则相反,通过目标词预测它的上下文。举个例子,对于“我爱吃冰淇淋”这个句子,CBOW方法已知上下文“我爱“和”冰淇淋”,计算出中间词的概率,比如,“吃”的概率是90%,“喝”的概率是7%,“玩”的概率是3%。然后再使用损失函数预测概率与实际概率的差异,最后通过反向传播算法,调整词向量模型的参数,使得损失函数最小化。训练词向量模型的最终目的,是捕捉词汇之间的语义关系,使得相关的词在向量空间中距离更近。
打个比方,最初的词向量模型就像一个刚出生的孩子,对字词的理解是模糊的。父母在各种场景下和孩子说话,时不时考一考孩子,相当于用语料库训练模型。只不过训练模型的过程是不断迭代神经网络的参数,而教孩子说话,则是改变大脑皮层中神经元突触的连接。
比如,父母会在吃饭前跟孩子说:
“肚子饿了就要…”
“要吃饭。”
如果答错了,父母会纠正孩子:
“吃饭之前要…”
“要喝汤。”
“不对,吃饭之前要洗手。”
这就是在调整模型的参数。
好了,纸上谈兵结束,咱们用代码实际操练一番吧。
先安装依赖:
pip install gensim scikit-learn transformers matplotlib
从 gensim.models 模块中导入 KeyedVectors 类,它用于存储和操作词向量。
from gensim.models import KeyedVectors
在_https://github.com/Embedding/Chinese-Word-Vectors/blob/master/README_zh.md_下载中文词向量模型 Literature 文学作品,并且加载该模型。
# 加载中文词向量模型
word_vectors = KeyedVectors.load_word2vec_format('sgns.literature.word', binary=False)
词向量模型其实就像一本字典。在字典里,每个字对应的是一条解释,在词向量模型中,每个词对应的是一个向量。
我们使用的词向量模型是300维的,数量太多,可以只显示前4个维度的数值:
print(f"'孙悟空'的向量的前四个维度:{word_vectors['孙悟空'].tolist()[:4]}")
输出结果为:
'孙悟空'的向量的前四个维度:[-0.09262000024318695, -0.034056998789310455, -0.16306699812412262, -0.05771299824118614]
02.
语义更近,距离更近
前面我们提出了疑问,“孙悟空”是和“猪八戒”更相关,还是和“沙僧”更相关呢?在 [怎么把大白话“变成”古诗词]这篇文章中,我们使用内积 IP 计算两个向量的距离,这里我们使用余弦相似度来计算。
print(f"'孙悟空'和'猪八戒'向量的余弦相似度是:{word_vectors.similarity('孙悟空', '猪八戒'):.2f}")
print(f"'孙悟空'和'沙僧'向量的余弦相似度是:{word_vectors.similarity('孙悟空', '沙僧'):.2f}")
返回:
'孙悟空'和'猪八戒'向量的余弦相似度是:0.60
'孙悟空'和'沙僧'向量的余弦相似度是:0.59
看来,孙悟空还是和猪八戒更相关。但是我们还不满足,我们还想知道,和孙悟空最相关的是谁。
# 查找与“孙悟空”最相关的4个词
similar_words = word_vectors.most_similar("孙悟空", topn=4)
print(f"与'孙悟空'最相关的4个词分别是:")
for word, similarity in similar_words:
print(f"{word}, 余弦相似度为:{similarity:.2f}")
返回:
与'孙悟空'最相关的4个词分别是:
悟空, 余弦相似度为:0.66
唐僧, 余弦相似度为:0.61
美猴王, 余弦相似度为:0.61
猪八戒, 余弦相似度为:0.60
“孙悟空”和“悟空”、“美猴王”相关,这容易理解。为什么它还和“唐僧”、“猪八戒”相关呢?前面提到的词向量模型的训练原理解释,就是因为在训练文本中,“唐僧”、“猪八戒”经常出现在“孙悟空”这个词的上下文中。这不难理解——在《西游记》中,孙悟空经常救唐僧,还喜欢戏耍八戒。
前面提到,训练词向量模型是为了让语义相关的词,在向量空间中距离更近。那么,我们可以测试一下,给出四组语义相近的词,考一考词向量模型,看它能否识别出来。
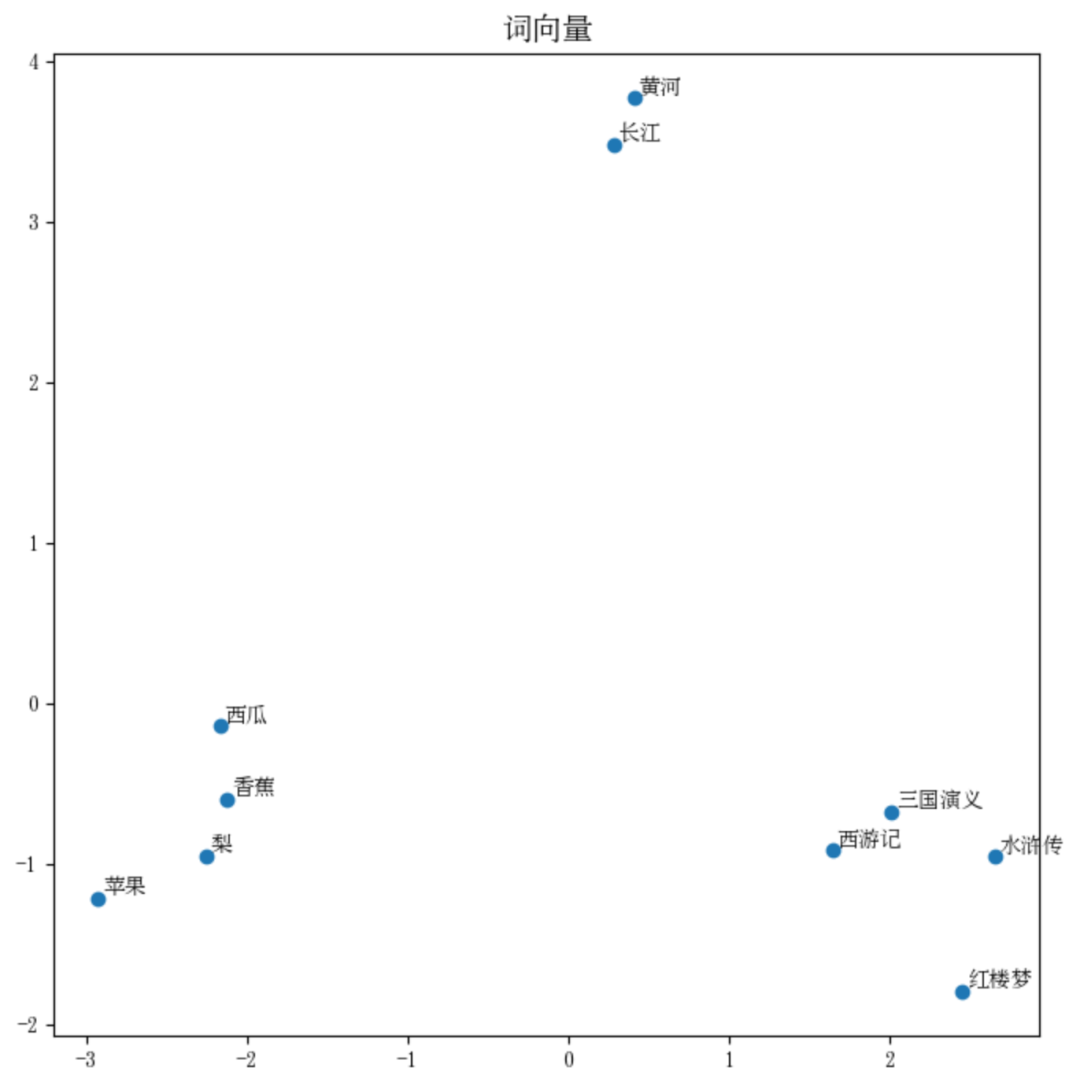
第一组:西游记,三国演义,水浒传,红楼梦
第二组:西瓜,苹果,香蕉,梨
第三组:长江,黄河
首先,获取这四组词的词向量:
# 导入用于数值计算的库
import numpy as np
# 定义要可视化的单词列表
words = ["西游记", "三国演义", "水浒传", "红楼梦",
"西瓜", "苹果", "香蕉", "梨",
"长江", "黄河"]
# 使用列表推导式获取每个单词的向量
vectors = np.array([word_vectors[word] for word in words])
然后,使用 PCA (Principal Component Analysis,组成分分析)把200维的向量降到2维,一个维度作为 x 坐标,另一个维度作为 y 坐标,这样就把高维向量投影到平面了,方便我们在二维图形上显示它们。换句话说,PCA 相当于《三体》中的二向箔,对高维向量实施了降维打击。
# 导入用于降维的PCA类
from sklearn.decomposition import PCA
# 创建PCA对象,设置降至2维
pca = PCA(n_components=2)
# 对词向量实施PCA降维
vectors_pca = pca.fit_transform(vectors)
最后,在二维图形上显示降维后的向量。
# 导入用于绘图的库
import matplotlib.pyplot as plt
# 创建一个5x5英寸的图
fig, axes = plt.subplots(1, 1, figsize=(7, 7))
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimSong']
# 确保负号能够正确显示
plt.rcParams['axes.unicode_minus'] = False
# 使用PCA降维后的前两个维度作为x和y坐标绘制散点图
axes.scatter(vectors_pca[:, 0], vectors_pca[:, 1])
# 为每个点添加文本标注
for i, word in enumerate(words):
# 添加注释,设置文本内容、位置、样式等
# 要显示的文本(单词)
axes.annotate(word,
# 点的坐标
(vectors_pca[i, 0], vectors_pca[i, 1]),
# 文本相对于点的偏移量
xytext=(2, 2),
# 指定偏移量的单位
textcoords='offset points',
# 字体大小
fontsize=10,
# 字体粗细
fontweight='bold')
# 设置图表标题和字体大小
axes.set_title('词向量', fontsize=14)
# 自动调整子图参数,使之填充整个图像区域
plt.tight_layout()
# 在屏幕上显示图表
plt.show()
从图中可以看出,同一组词的确在图中的距离更近。
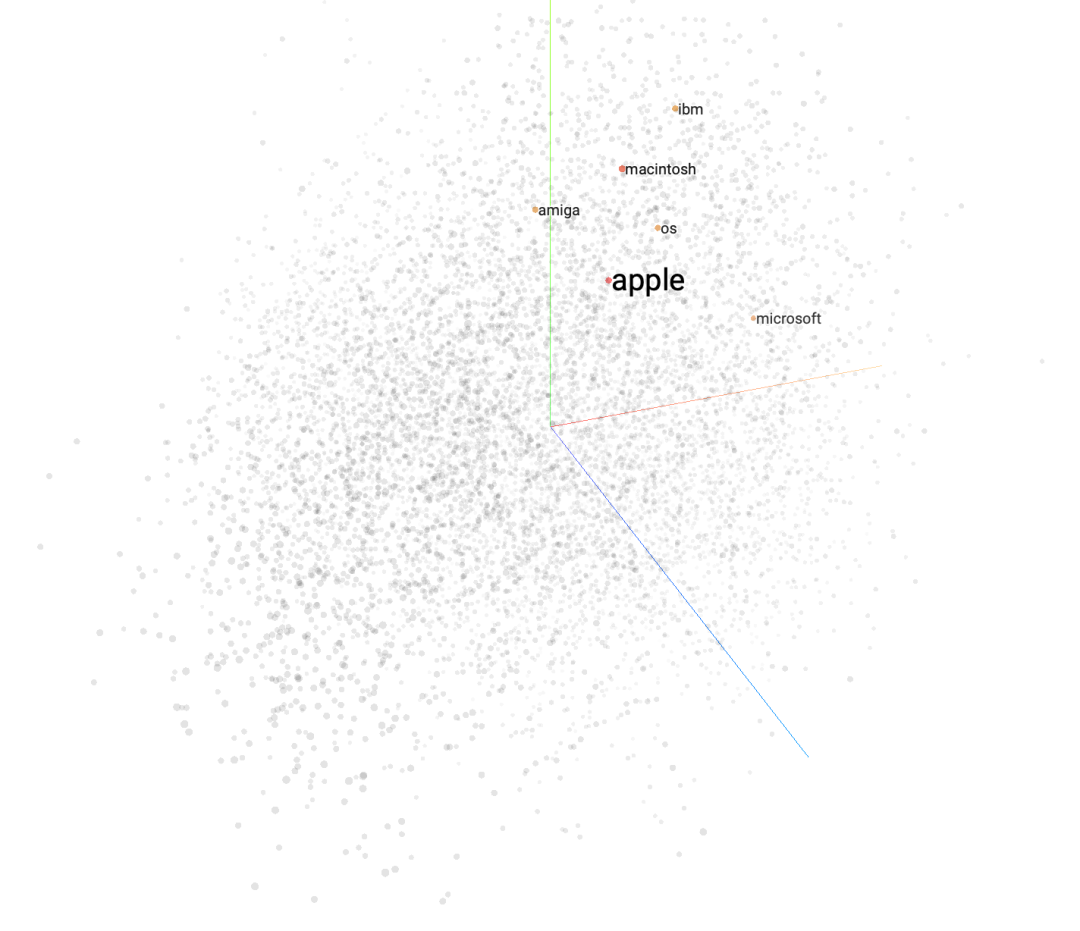
既然可以把高维向量投影到二维,那么是不是也能投影到三维呢?当然可以,那样更酷。你可以在 TensorFlow Embedding Projector (https://projector.tensorflow.org/) 上尝试下,输入单词,搜索与它最近的几个词,看看它们在三维空间上的位置关系。
比如,输入 apple,最接近的5个词分别是 OS、macintosh、amiga、ibm 和 microsoft。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

03.
如果孙悟空穿越到红楼梦
回到我们开篇的问题,把文本向量化后,就可以做运算了。如果孙悟空穿越到红楼梦,我们用下面的数学公式表示:孙悟空 + 红楼梦 - 西游记
result = word_vectors.most_similar(positive=["孙悟空", "红楼梦"], negative=["西游记"], topn=4)
print(f"孙悟空 + 红楼梦 - 西游记 = {result}")
答案为:
孙悟空 + 红楼梦 - 西游记 = [('唐僧', 0.4163001477718353), ('贾宝玉', 0.41606390476226807), ('妙玉', 0.39432790875434875), ('沙和尚', 0.3922004997730255)]
你是不是有点惊讶,因为答案中的“唐僧”和“沙和尚”根本就不是《红楼梦》中的人物。这是因为虽然词向量可以反映字词之间的语义相关性,但是它终究是在做数学题,不能像人类一样理解“孙悟空 + 红楼梦 - 西游记”背后的含义。答案中出现“唐僧”和“沙和尚”是因为它们和“孙悟空”更相关,而出现“贾宝玉”和“妙玉”则是因为它们和“红楼梦”更相关。
不过,这样的测试还蛮有趣的,你也可以多尝试一下,有的结果还蛮符合直觉的。
result = word_vectors.most_similar(positive=["牛奶", "发酵"], topn=1)
print(f"牛奶 + 发酵 = {result[0][0]}")
result = word_vectors.most_similar(positive=["男人", "泰国"], topn=1)
print(f"男人 + 泰国 = {result[0][0]}")
计算的结果如下:
牛奶 + 发酵 = 变酸
男人 + 泰国 = 女人
04.
一词多义怎么办
前面说过,词向量模型就像一本字典,每个词对应一个向量,而且是唯一一个向量。但是,在语言中一词多义的现象是非常常见的,比如对于 “苹果” 这个词,既可以指一种水果,也可以指一家电子产品公司。词向量模型在训练 “苹果”这个词的向量时,这两种语义都会考虑到,所以它在向量空间中将位于“水果”和 “电子产品公司”之间。这就好像你3月20号过生日,你同事3月30号过生日,你的领导为了给你们两个人一起过庆祝生日,选择了3月25号——不是任何一个人的生日。
为了解决一词多义的问题,BERT(Bidirectional Encoder Representations from Transformers)模型诞生了。它是一种基于深度神经网络的预训练语言模型,使用 Transformer 架构,通过自注意力机制同时考虑一个 token 的前后上下文,并且根据上下文环境更新该 token 的向量。
比如,“苹果”这个目标词的初始向量是从词库中获取的,向量的值是固定的。当注意力模型处理“苹果“这个词时,如果发现上下文中有“手机”一词,会给它分配更多权重,“苹果”的向量会更新,靠近“手机”的方向。如果上下文中有“水果”一词,则会靠近“水果”的方向。
注意力模型分配权重是有策略的。它只会给上下文中与目标词关系紧密的词分配更多权重。所以,BERT 能够理解目标词与上下文之间的语义关系,根据上下文调整目标词的向量。
BERT 的预训练分成两种训练方式。第一种训练方式叫做“掩码语言模型(Masked Language Model,MLM)”,和 word2vec 相似,它会随机选择句子中的一些词遮住,根据上下文信息预测这个词,再根据预测结果与真实结果的差异调整参数。第二种训练方式叫做“下一句预测(Next Sentence Prediction,NSP)”,每次输入两个句子,判断第二个句子是否是第一个句子的下一句,然后同样根据结果差异调整参数。
说了这么多,BERT 模型的效果究竟怎么样?让我们动手试试吧。首先导入 BERT 模型,定义一个获取句子中指定单词的向量的函数。
# 从transformers库中导入BertTokenizer类和BertModel类
from transformers import BertTokenizer, BertModel
# 加载分词器 BertTokenizer
bert_tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
# 加载嵌入模型 BertModel
bert_model = BertModel.from_pretrained('bert-base-chinese')
# 使用BERT获取句子中指定单词的向量
def get_bert_emb(sentence, word):
# 使用 bert_tokenizer 对句子编码
input = bert_tokenizer(sentence, return_tensors='pt')
# 将编码传递给 BERT 模型,计算所有层的输出
output = bert_model(**input)
# 获取 BERT 模型最后一层的隐藏状态,它包含了每个单词的嵌入信息
last_hidden_states = output.last_hidden_state
# 将输入的句子拆分成单词,并生成一个列表
word_tokens = bert_tokenizer.tokenize(sentence)
# 获取目标单词在列表中的索引位置
word_index = word_tokens.index(word)
# 从最后一层隐藏状态中提取目标单词的嵌入表示
word_emb = last_hidden_states[0, word_index + 1, :]
# 返回目标单词的嵌入表示
return word_emb
然后通过 BERT 和词向量模型分别获取两个句子中指定单词的向量。
sentence1 = "我今天很开心。"
sentence2 = "我打开了房门。"
word = "开"
# 使用 BERT 模型获取句子中指定单词的向量
bert_emb1 = get_bert_emb(sentence1, word).detach().numpy()
bert_emb2 = get_bert_emb(sentence2, word).detach().numpy()
# 使用词向量模型获取指定单词的向量
word_emb = word_vectors[word]
最后,查看这三个向量的区别。
print(f"在句子 '{sentence1}' 中,'{word}'的向量的前四个维度:{bert_emb1[: 4]}")
print(f"在句子 '{sentence2}' 中,'{word}'的向量的前四个维度:{bert_emb2[: 4]}")
print(f"在词向量模型中, '{word}' 的向量的前四个维度:{word_emb[: 4]}")
结果为:
在句子 '我今天很开心。' 中,'开'的向量的前四个维度:[1.4325644 0.05137304 1.6045816 0.01002912]
在句子 '我打开了房门。' 中,'开'的向量的前四个维度:[ 0.9039772 -0.5877741 0.6639165 0.45880783]
在词向量模型中, '开' 的向量的前四个维度:[ 0.260962 0.040874 0.434256 -0.305888]
BERT 模型果然能够根据上下文调整单词的向量。不妨再比较下余弦相似度:
# 导入用于计算余弦相似度的函数
from sklearn.metrics.pairwise import cosine_similarity
# 计算两个BERT嵌入向量的余弦相似度
bert_similarity = cosine_similarity([bert_emb1], [bert_emb2])[0][0]
print(f"在 '{sentence1}' 和 '{sentence2}' 这两个句子中,两个 '{word}' 的余弦相似度是: {bert_similarity:.2f}")
# 计算词向量模型的两个向量之间的余弦相似度
word_similarity = cosine_similarity([word_emb], [word_emb])[0][0]
print(f"在词向量中, '{word}' 和 '{word}' 的余弦相似度是: {word_similarity:.2f}")
观察结果发现,不同句子中的“开”语义果然不同:
在 '我今天很开心。' 和 '我打开了房门。' 这两个句子中,两个 '开' 的余弦相似度是: 0.69
在词向量中, '开' 和 '开' 的余弦相似度是: 1.00
05.
怎么获得句子的向量
我们虽然可以通过 BERT 模型获取单词的向量,但是怎么获得句子的向量呢?最简单的方法就是让 BERT 输出句子中每个单词的向量,然后计算向量的平均值。但是,这种不分重点一刀切的效果肯定是不好的,就好像我和千万富豪站在一起,计算我们的平均资产,然后得出结论,这两个人都是千万富翁,这显然不能反映真实情况。
所以,想要反映句子的语义,必须使用专门的句子嵌入模型。BGE_M3 模型就是这样一个嵌入模型,它直接生成句子级别的嵌入表示,能够更好地捕捉句子中的上下文信息,从而生成更准确的句子向量,而且支持中文。
真的这么好用?是骡子是马,拉出来遛遛,我们比较一下这两种生成句子嵌入的方法。
首先,定义一个使用 BERT 模型获取句子向量的函数。
# 导入 PyTorch 库
import torch
# 使用 BERT 模型获取句子的向量
def get_bert_sentence_emb(sentence):
# 使用 bert_tokenizer 对句子进行编码,得到 PyTorch 张量格式的输入
input = bert_tokenizer(sentence, return_tensors='pt')
# print(f"input: {input}")
# 将编码后的输入传递给 BERT 模型,计算所有层的输出
output = bert_model(**input)
# print(f"output: {output}")
# 获取 BERT 模型最后一层的隐藏状态,它包含了每个单词的嵌入信息
last_hidden_states = output.last_hidden_state
# 将所有词的向量求平均值,得到句子的表示
sentence_emb = torch.mean(last_hidden_states, dim=1).flatten().tolist()
# 返回句子的嵌入表示
return sentence_emb
然后,安装 pymilvus.model库。
pip install pymilvus "pymilvus[model]"
定义一个用 bge_m3模型获取句子向量的函数。
# 导入 bge_m3 模型
from pymilvus.model.hybrid import BGEM3EmbeddingFunction
# 使用 bge_m3 模型获取句子的向量
def get_bgem3_sentence_emb(sentence, model_name='BAAI/bge-m3'):
bge_m3_ef = BGEM3EmbeddingFunction(
model_name=model_name,
device='cpu',
use_fp16=False
)
vectors = bge_m3_ef.encode_documents([sentence])
return vectors['dense'][0].tolist()
接下来,先计算下 BERT 模型生成的句子向量之间的余弦相似度。
sentence1 = "我喜欢这部电影!"
sentence2 = "这部电影太棒了!"
sentence3 = "我讨厌这部电影。"
# 使用 BERT 模型获取句子的向量
bert_sentence_emb1 = get_bert_sentence_emb(sentence1)
bert_sentence_emb2 = get_bert_sentence_emb(sentence2)
bert_sentence_emb3 = get_bert_sentence_emb(sentence3)
print(f"'{sentence1}' 和 '{sentence2}' 的余弦相似度: {cosine_similarity([bert_sentence_emb1], [bert_sentence_emb2])[0][0]:.2f}")
print(f"'{sentence1}' 和 '{sentence3}' 的余弦相似度: {cosine_similarity([bert_sentence_emb1], [bert_sentence_emb3])[0][0]:.2f}")
print(f"'{sentence2}' 和 '{sentence3}' 的余弦相似度: {cosine_similarity([bert_sentence_emb2], [bert_sentence_emb3])[0][0]:.2f}")
结果是:
'我喜欢这部电影!' 和 '这部电影太棒了!' 的余弦相似度: 0.93
'我喜欢这部电影!' 和 '我讨厌这部电影。' 的余弦相似度: 0.94
'这部电影太棒了!' 和 '我讨厌这部电影。' 的余弦相似度: 0.89
很明显,前两个句子语义相近,并且与第三个句子语义相反。但是使用 BERT 模型的结果却是三个句子语义相近。
最后看看 bge_m3模型的效果如何:
# 使用 bge_m3 模型获取句子的向量
bgem3_sentence_emb1 = get_bgem3_sentence_emb(sentence1)
bgem3_sentence_emb2 = get_bgem3_sentence_emb(sentence2)
bgem3_sentence_emb3 = get_bgem3_sentence_emb(sentence3)
print(f"'{sentence1}' 和 '{sentence2}' 的余弦相似度: {cosine_similarity([bgem3_sentence_emb1], [bgem3_sentence_emb2])[0][0]:.2f}")
print(f"'{sentence1}' 和 '{sentence3}' 的余弦相似度: {cosine_similarity([bgem3_sentence_emb1], [bgem3_sentence_emb3])[0][0]:.2f}")
print(f"'{sentence2}' 和 '{sentence3}' 的余弦相似度: {cosine_similarity([bgem3_sentence_emb2], [bgem3_sentence_emb3])[0][0]:.2f}")
结果是:
'我喜欢这部电影!' 和 '这部电影太棒了!' 的余弦相似度: 0.86
'我喜欢这部电影!' 和 '我讨厌这部电影。' 的余弦相似度: 0.65
'这部电影太棒了!' 和 '我讨厌这部电影。' 的余弦相似度: 0.57
从余弦相似度可以看出,前两个句子语义相近,和第三个句子语义较远。看来 bge_m3 模型确实可以捕捉句子中的上下文信息。
06.
藏宝图
本文主要通过执行代码直观展示向量嵌入的原理和模型,如果你想进一步了解技术细节,这里有一些资料供你参考。
词向量模型
word2vect 模型论文:
-
Efficient Estimation of Word Representations in Vector Space (https://arxiv.org/abs/1301.3781)
-
Distributed Representations of Words and Phrases and their Compositionality (https://arxiv.org/abs/1310.4546)
中文词向量模型
-
Chinese-Word-Vectors (https://github.com/Embedding/Chinese-Word-Vectors) 项目提供了上百种预训练的中文词向量,这些词向量是基于不同的表征、上下文特征和语料库训练的,可以用于各种中文自然语言处理任务。
-
腾讯 AI Lab 中英文词和短语的嵌入语料库
-
word2vec-Chinese (https://github.com/lzhenboy/word2vec-Chinese) 介绍了如何训练中文 Word2Vec 词向量模型。
BERT 模型
BERT 模型论文:
-
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (https://arxiv.org/abs/1810.04805)
-
ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT (https://arxiv.org/abs/2004.12832)
BERT 模型的 GitHub:https://github.com/google-research/bert
介绍 ColBERT 模型的博客:Exploring ColBERT: A Token-Level Embedding and Ranking Model for Efficient Similarity Search (https://zilliz.com/learn/explore-colbert-token-level-embedding-and-ranking-model-for-similarity-search)
bge_m3 模型
介绍 bge_m3模型的博客:Exploring BGE-M3 and Splade: Two Machine Learning Models for Generating Sparse Embeddings (https://zilliz.com/learn/bge-m3-and-splade-two-machine-learning-models-for-generating-sparse-embeddings#BERT-The-Foundation-Model-for-BGE-M3-and-Splade)
注意力模型
注意力模型论文:Attention Is All You Need (https://arxiv.org/abs/1706.03762)
模型库
-
gensim (https://radimrehurek.com/gensim/) 包含了 word2vec 模型和 GloVe(Global Vectors for Word Representation)模型。
-
Transformers (https://huggingface.co/transformers/) 是 Hugging Face 开发的一个开源库,专门用于自然语言处理(NLP)任务,它提供了大量预训练的 Transformer 模型,如 BERT、GPT、T5 等,并且支持多种语言和任务。
-
Chinese-BERT-wwm (https://github.com/ymcui/Chinese-BERT-wwm) 是哈工大讯飞联合实验室(HFL)发布的中文 BERT 模型。
-
pymilvus.model (https://milvus.io/docs/embeddings.md) 是 PyMilvus 客户端库的一个子包,提供多种嵌入模型的封装,用于生成向量嵌入,简化了文本转换过程。
[^1]: 严格来说,“目标词”不是单词而是“token”。token 是组成句子的基本单元。对于英文来说,token可以简单理解为单词,还可能是子词(subword)或者标点符号,比如“unhappiness” 可能会被分割成“un”和“happiness“。对于汉字来说,则是字、词或者短语,汉字不会像英文单词那样被分割。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}