






#此篇为学习笔记,资料、图片来源 图灵程序设计丛书 《精通特征工程》阿曼达 .卡萨丽、爱丽丝.郑 著
1.数据
我们所说的数据是对现实世界的现象观测。
每份数据都是管中窥豹,只能反映一小部分现实,把这些观测综合起来才能得到一个完整的描述。但这个描述非常散乱,因为它由成千上万个小片段组成,而且综述存在测量噪声何缺失值。
2.任务
从数据中得到答案,不被杂乱的工具与系统所迷惑,就能发现这个过程包括两个机器学习基础的数学实体:模型和特征
数据处理工作流往往是多阶段的迭代过程。
引用书上的例子“股票价格是在交易所中观测到的,然后由像汤森路透这样的中间机构进行汇集并保存到数据库中,之后被某个公司买去,转换为一个Hadoop集群上的Hive仓库,再被某个脚本从仓库中读出,进行二次抽样和各种处理,接着通过另一个脚本进行清洗,导出到一个文件,转换为某种格式,然后你使用R、Python或Scala中你最喜欢的建模程序进行试验。接着,预测结果被导出为一个CSV文件,再用一个估值程序进行解析。模型会被迭代多次,由产品团队用C++或Java重写,并在全部数据上运行,然后最终的预测结果会输出到另一个数据库中保存起来”。
3.模型
通过数据来理解世界就像是玩拼图,但这副拼图是杂乱且不完整的,而且带有多余的部分。这时数学模型——特别是统计模型——就派上用场了。
统计语言中有很多概念,可以描述常见的数据特征,比如错误数据、冗余数据和缺失数据。
数据的数学模型描述了数据不同部分之间的关系。
4.特征
特征是原始数据的数值表示。
特征工程就是在给定数据、模型和任务的情况下设计出最适合的特征的过程。
特征的数量也很重要。如果没有足够的有信息量的特征,模型将不能完成最终任务。如果特征过多,或者多数特征不合适,那么模型将很难训练而且训练成本高昂。
5.模型评价
特征和模型位于原始数据和我们想得到的知识之间。在机器学习流程中,我们不仅要选择模型,还有特征。模型与特征相辅相成,好的特征可以使随后的建模步骤更加容易,最后得出的模型也更能完成任务。坏的特征想要达到同等的性能,则需要复杂得多的模型。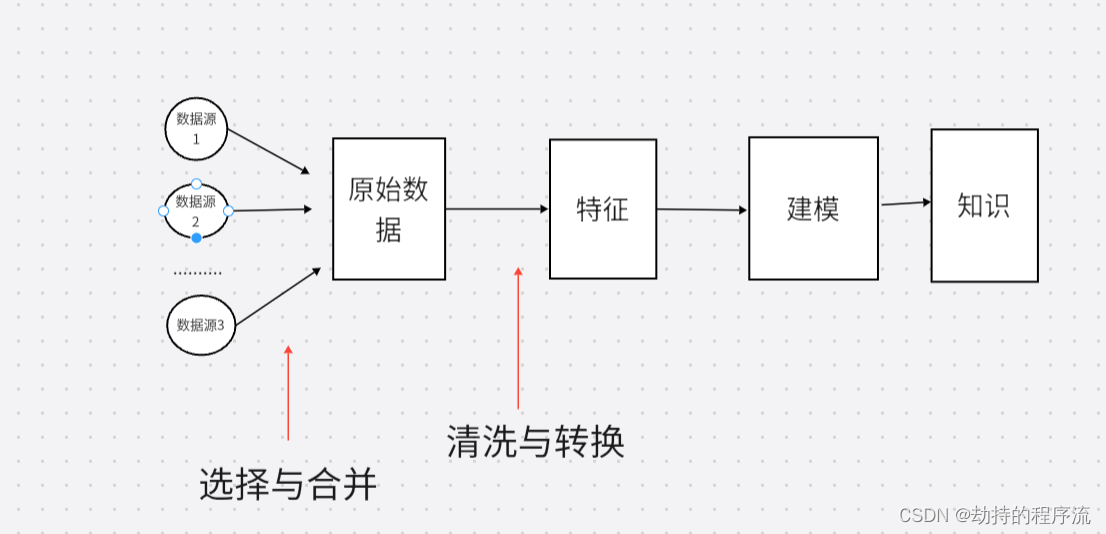















 710
710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









