







一、提出任务
- 有多科成绩表,比如python.txt、spark.txt、django.txt,计算每个学生三科平均分
- python成绩表 -
python.txt
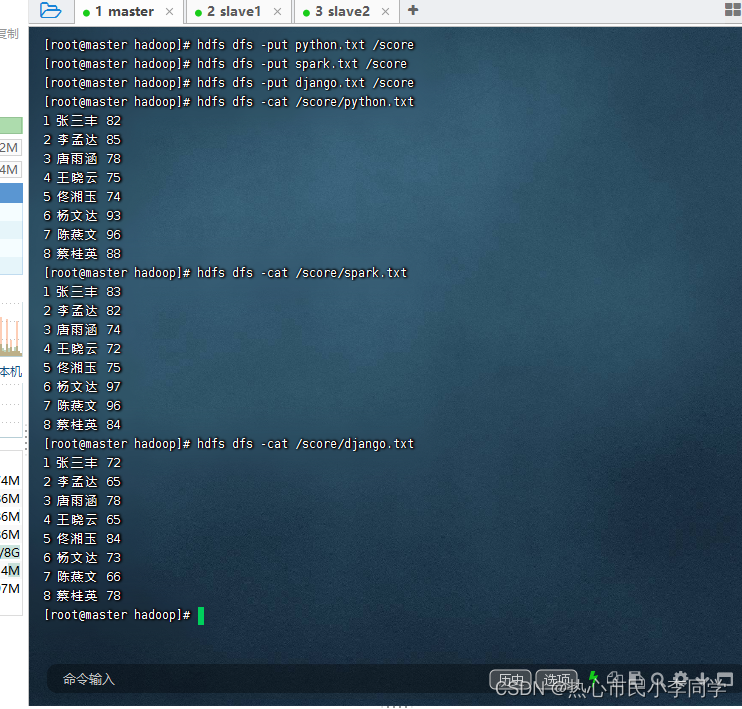
1 张三丰 82
2 李孟达 85
3 唐雨涵 78
4 王晓云 75
5 佟湘玉 74
6 杨文达 93
7 陈燕文 96
8 蔡桂英 88
- spark成绩表 -
spark.txt
1 张三丰 83
2 李孟达 82
3 唐雨涵 74
4 王晓云 72
5 佟湘玉 75
6 杨文达 97
7 陈燕文 96
8 蔡桂英 84
- django成绩表 -
django.txt
1 张三丰 72
2 李孟达 65
3 唐雨涵 78
4 王晓云 65
5 佟湘玉 84
6 杨文达 73
7 陈燕文 66
8 蔡桂英 78
-
在集群上打开
HDFS与Spark
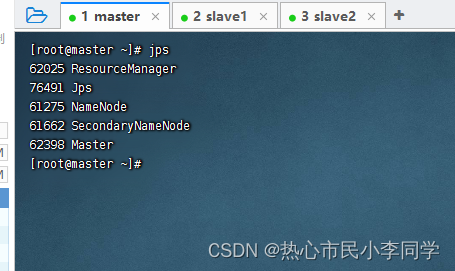
-
在hdfs创建
/score文件夹
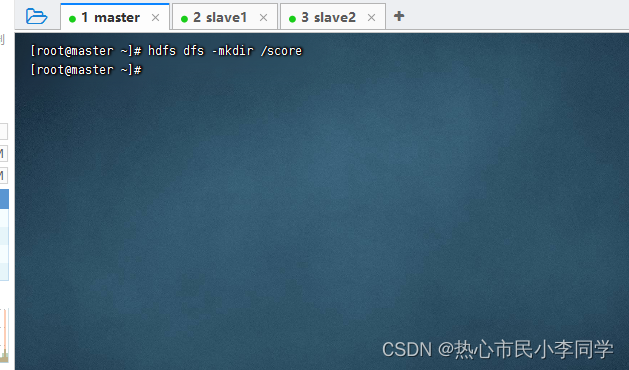
-
在虚拟机上面创建三个成绩文件
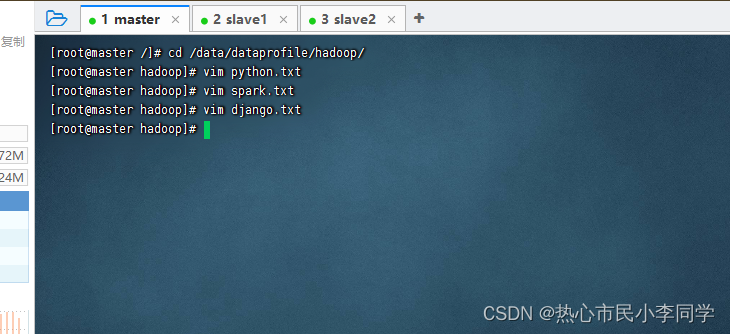
- 上传三个成绩文件到
/score目录,并检查三个成绩内容
二、完成任务
(一)新建Maven项目
-
设置项目信息(项目名、保存位置、组编号、项目编号)
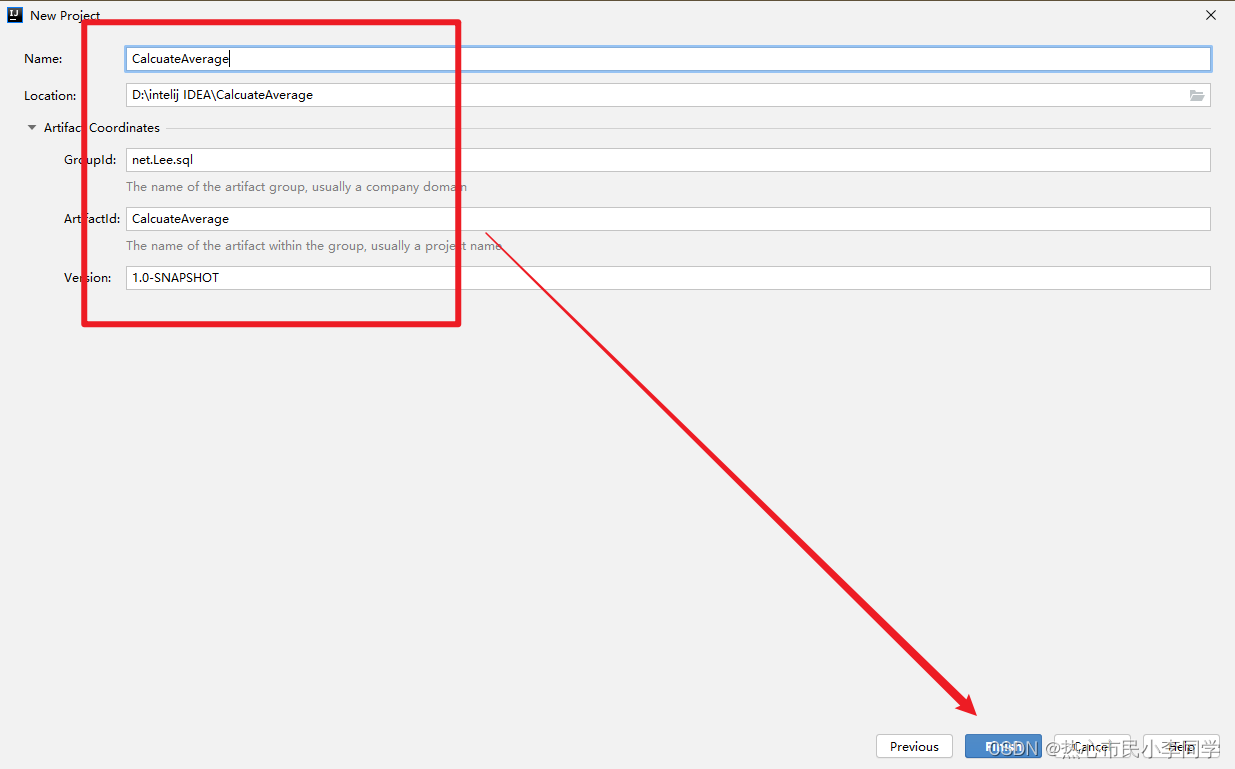
-
单击【Finish】按钮
-
将java目录改成scala目录
(二)添加相关依赖和构建插件
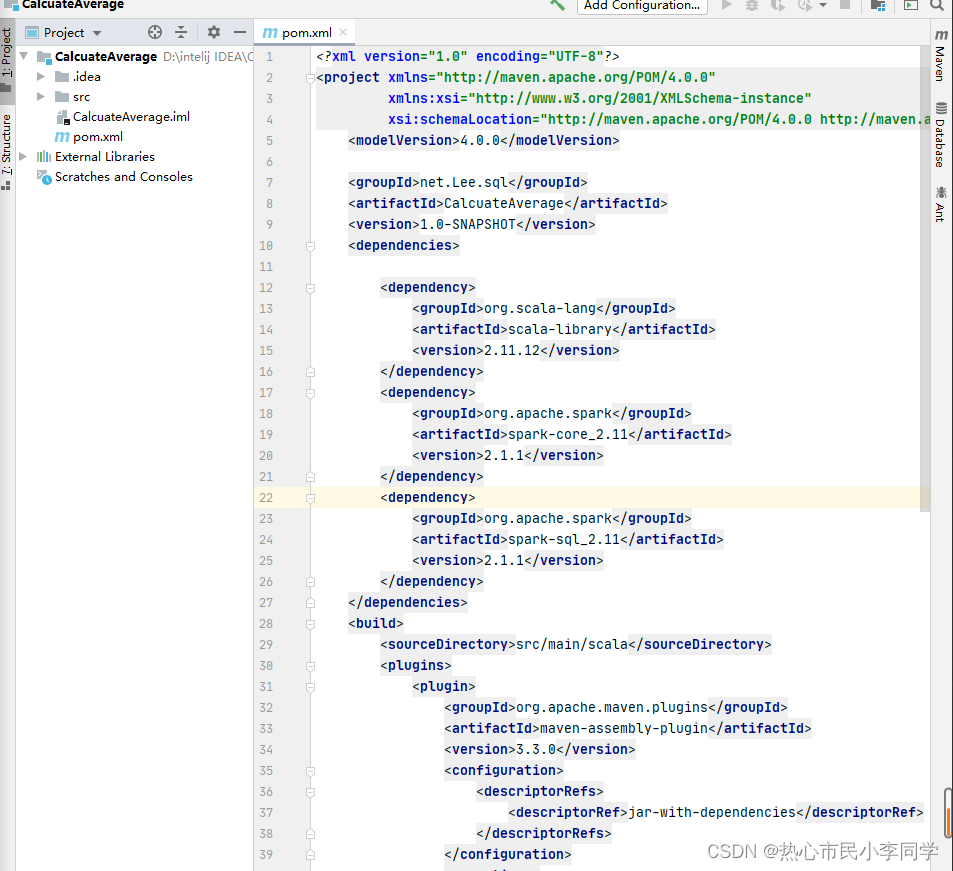
- 在
pom.xml文件里添加依赖与Maven构建插件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>net.Lee.sql</groupId>
<artifactId>CalcuateAverage</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.1</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.3.2</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal>
<goal>compile</goal>
</goals>
</execution>
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
(三)创建日志属性文件
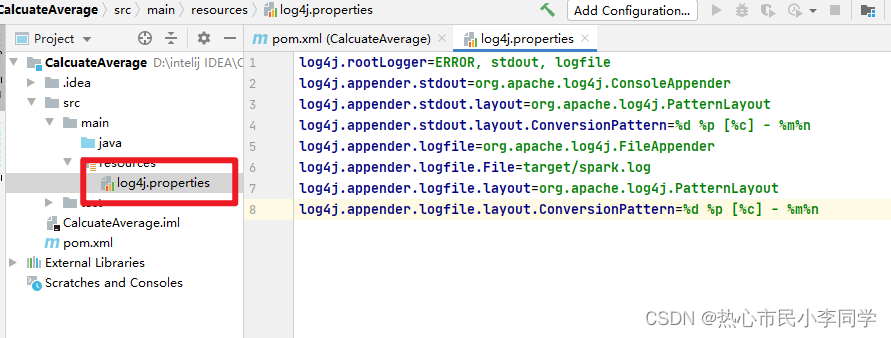
- 在资源文件夹里创建日志属性文件 -
log4j.properties
log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spark.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
(四)创建计算平均分单例对象
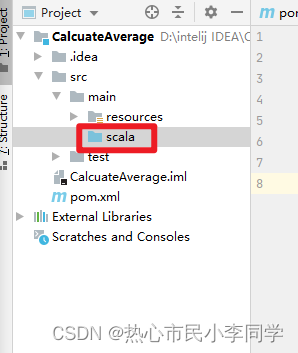
-
将
java目录改成scala目录
-
在
net.Lee.sql包里创建CalculateAverageBySQL单例对象
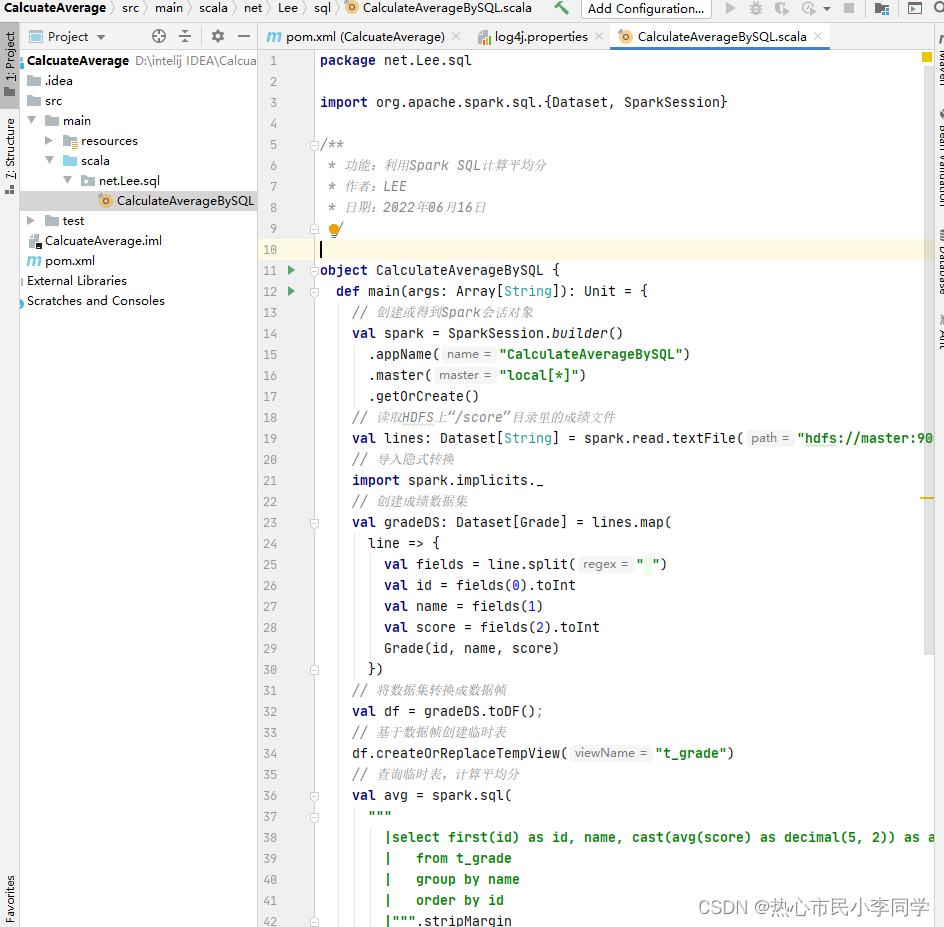
package net.Lee.sql
import org.apache.spark.sql.{Dataset, SparkSession}
/**
* 功能:利用Spark SQL计算平均分
* 作者:LEE
* 日期:2022年06月16日
*/
object CalculateAverageBySQL {
def main(args: Array[String]): Unit = {
// 创建或得到Spark会话对象
val spark = SparkSession.builder()
.appName("CalculateAverageBySQL")
.master("local[*]")
.getOrCreate()
// 读取HDFS上“/score”目录里的成绩文件
val lines: Dataset[String] = spark.read.textFile("hdfs://master:9000/score")
// 导入隐式转换
import spark.implicits._
// 创建成绩数据集
val gradeDS: Dataset[Grade] = lines.map(
line => {
val fields = line.split(" ")
val id = fields(0).toInt
val name = fields(1)
val score = fields(2).toInt
Grade(id, name, score)
})
// 将数据集转换成数据帧
val df = gradeDS.toDF();
// 基于数据帧创建临时表
df.createOrReplaceTempView("t_grade")
// 查询临时表,计算平均分
val avg = spark.sql(
"""
|select first(id) as id, name, cast(avg(score) as decimal(5, 2)) as average
| from t_grade
| group by name
| order by id
|""".stripMargin
)
// 按照指定格式输出平均成绩
println()
avg.collect.foreach(row => println(row(0) + " " + row(1) + " " + row(2)))
// 关闭Spark会话
spark.close()
}
// 定义成绩样例类
case class Grade(id: Int, name: String, score: Int)
}
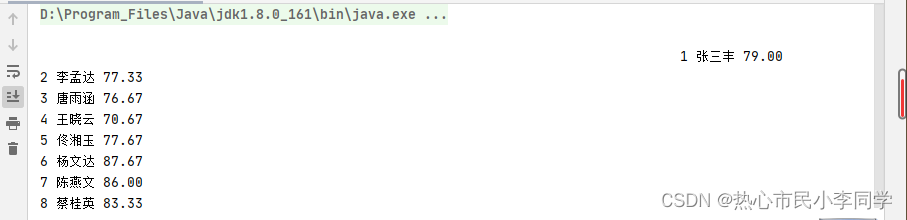
(五)本地运行程序,查看结果
- 在控制台查看输出结果















 444
444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











