






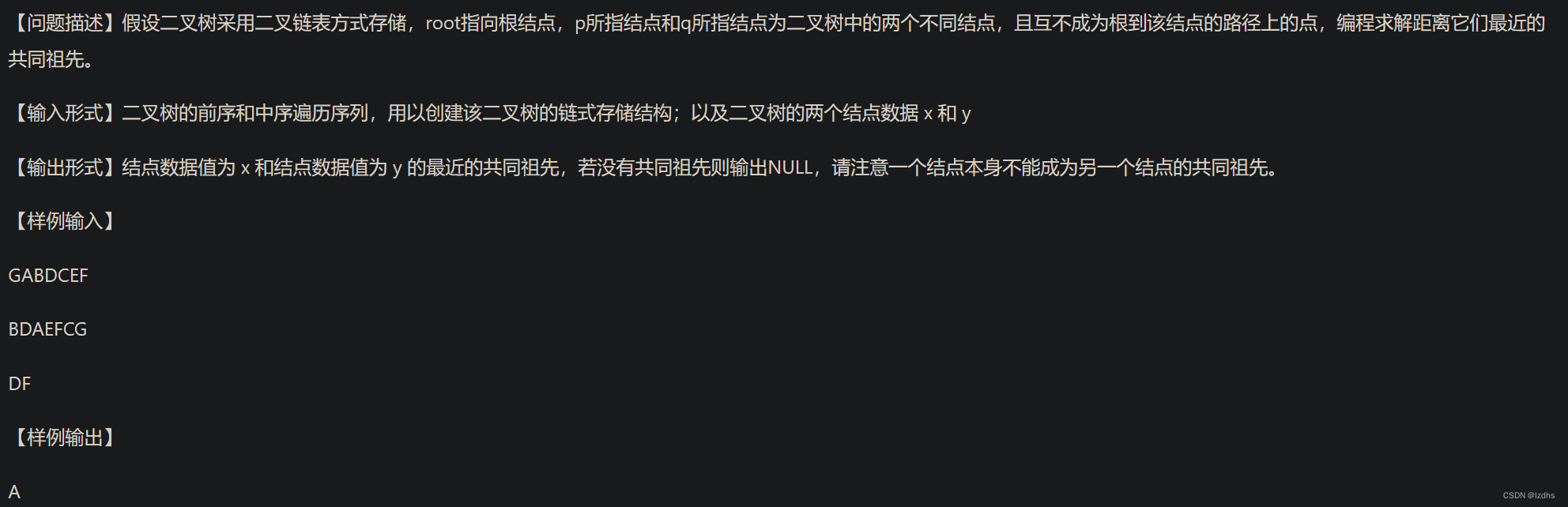
一道关于二叉树共同祖先的题目,不过这次我想分享的并不是这道题的思路,而是其中的一个算法。题目是这样的
这道题输入形式是一个二叉树前序和中序的遍历序列,我想分享一下通过前序和中序的遍历序列来构建二叉树的过程,这次我们不先上代码。
二叉树节点定义:
`typedef struct tnode
{
char data;
struct tnode *lchild;
struct tnode *rchild;
}tnode,*tree;```
s1是先序遍历的字符串,s2是中序遍历的字符串。
在写这个算法前,请各位读者拿起笔和纸,在纸上根据这个序列先画出这个二叉树,会有助于理解。
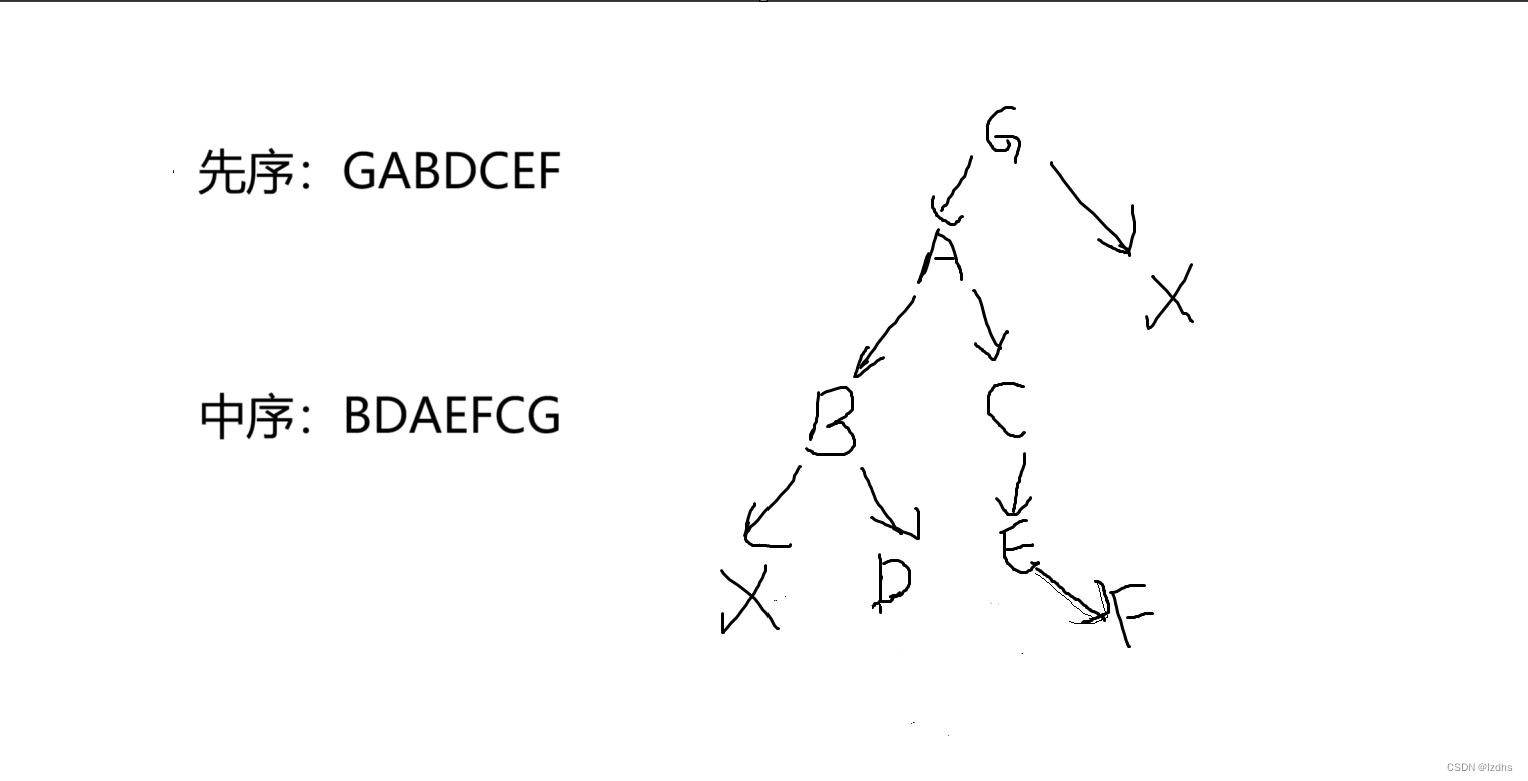
理解算法前,必须先把二叉树是如何建立的搞清楚。
要找到根节点,需要通过先序序列找到,显而易见,先序序列的第一个字母就是整个二叉树的根节点,所以我们在函数的最开始为它分配空间,同时赋好值。以本题为例,G为根节点。
既然我们知道了根节点,那么我们就可以通过中序序列来分开左右子树了,显然,在根节点左边的为左子树,右边的为右子树。那么我们就不难发现这道题没有右子树。
接下来我们看左子树,根据先序序列可以得到A为左子树的根节点,然后再次根据根节点在中序序列里的位置来判断左右子树,所以BD是左子树,AEFC是右子树。再次反复执行上述过程,不难把树画出来。
接下来就可以写代码了
{
*root=(tnode*)malloc(sizeof(tnode));
(*root)->lchild=(*root)->rchild=NULL;
(*root)->data=s1[0];
tree temp=*root;
tree newroot;
int i=0,j=0,rootpos;//in s2
stack s;
s.top=-1;
push(&s,temp);
rootpos=findpos(s1[0],s2);
while(s1[i]!='\0')
{
i++;
if(findpos(s1[i],s2)<rootpos)
{
newroot=(tnode*)malloc(sizeof(tnode));
newroot->lchild=newroot->rchild=NULL;
temp->lchild=newroot;
newroot->data=s1[i];
temp=newroot;
rootpos=findpos(s1[i],s2);
push(&s,temp);
}
else
{
temp=pop(&s);
rootpos=findpos(s1[i],s2);
if(findpos(gettop(&s),s2)>rootpos)
{
newroot=(tnode*)malloc(sizeof(tnode));
newroot->lchild=newroot->rchild=NULL;
temp->rchild=newroot;
newroot->data=s1[i];
temp=newroot;
push(&s,temp);
}
else
{
temp=pop(&s);
newroot=(tnode*)malloc(sizeof(tnode));
newroot->lchild=newroot->rchild=NULL;
temp->rchild=newroot;
newroot->data=s1[i];
temp=newroot;
push(&s,temp);
}
}
}
}```
```int findpos(char ch,char s[])
{
int i=0;
for(i=0;s[i]!='\0';i++)
{
if(s[i]==ch)
return i;
}
return 0;
}```
每次当我们申请了一个新的节点,必须先把它的左右孩子节点置空。
当下一个根节点在前一个根节点的左边(即中序序列中下一个节点的字符位置小于当前根节点位置,那么就建立左子树),分配内存,赋值等一系列操作进行完毕后,当前根节点位置需要更新,然后我们把它压入栈中。(因为后续我们啃还要对右子树进行赋值操作,所以先留着)
如果在右边,我们就建立它的右子树,此时把之前压在栈中的节点取出,为它右子树赋值,操作同上。
但是为什么要在右子树建立过程中判断栈顶元素和当前节点位置关系呢?因为我们根据先序序列进行的建树,进入右子树,首先要把根节点赋值,然后继续建立它的左子树,此时需判断一下。
理解建树的过程,代码自然不难理解,本文到此结束,欢迎大家在评论区交流,共同学习,共同进步!















 3895
3895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









