










本篇是在imagenet模型上进行微调,可以节省模型训练时间,如果需要重新训练一个模型,请参考上一篇文章:https://blog.csdn.net/lzdjlu/article/details/134669294?spm=1001.2014.3001.5502
1.DenseNet网络结构
论文题目:《Densely Connected Convolutional Networks》
论文地址:https://arxiv.org/abs/1608.06993
DenseNet是CVPR2017的Best Paper,网络的基本思路与ResNet差不多,但是它的不同之处是将前面所有层与后面层的密集连接,目的是实现特征重用。这一特点使DenseNet在参数和计算成本更少的情形下实现比ResNet更优的性能。Densenet由DenseBlock和间隔模块Transition Layer组成。
2.数据集
采用kaggle上的猫狗数据集,总共10000张图片,猫和狗分别有5000张,取4000张图片作为训练集,1000张图片作为验证集
kaggle数据集地址:https://www.kaggle.com/chetankv/dogs-cats-images

每张图片的大小都不同,进行训练的时候需要将所有图片resize到相同的大小(224×224),然后输入到网络进行训练。
3.训练代码
新建DenseNet121_finetune_train.py文件:
# 导入相应的库
from tensorflow.keras.callbacks import ReduceLROnPlateau, ModelCheckpoint
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
import itertools
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
# 设置图片的高和宽,一次训练所选取的样本数,迭代次数
im_height = 224
im_width = 224
batch_size = 256
epochs = 30
INIT_LR = 1e-3
labelList = []
dicClass = {'cat': 0, 'dog': 1}
classnum = 2
# 创建保存模型的文件夹
if not os.path.exists("save_weights"):
os.makedirs("save_weights")
image_path = "dataset1/" # 猫狗数据集路径
train_dir = image_path + "training_set" # 训练集路径
validation_dir = image_path + "test_set" # 验证集路径
# 定义训练集图像生成器,并进行图像增强
train_image_generator = ImageDataGenerator(rescale=1. / 255, # 归一化
rotation_range=40, # 旋转范围
width_shift_range=0.2, # 水平平移范围
height_shift_range=0.2, # 垂直平移范围
shear_range=0.2, # 剪切变换的程度
zoom_range=0.2, # 剪切变换的程度
horizontal_flip=True, # 水平翻转
fill_mode='nearest')
# 使用图像生成器从文件夹train_dir中读取样本,对标签进行one-hot编码
train_data_gen = train_image_generator.flow_from_directory(directory=train_dir, # 从训练集路径读取图片
batch_size=batch_size, # 一次训练所选取的样本数
shuffle=True, # 打乱标签
target_size=(im_height, im_width), # 图片resize到224x224大小
class_mode='categorical') # one-hot编码
# 训练集样本数
total_train = train_data_gen.n
# 定义验证集图像生成器,并对图像进行预处理
validation_image_generator = ImageDataGenerator(rescale=1. / 255) # 归一化
# 使用图像生成器从验证集validation_dir中读取样本
val_data_gen = validation_image_generator.flow_from_directory(directory=validation_dir, # 从验证集路径读取图片
batch_size=batch_size, # 一次训练所选取的样本数
shuffle=False, # 不打乱标签
target_size=(im_height, im_width), # 图片resize到224x224大小
class_mode='categorical') # one-hot编码
# 验证集样本数
total_val = val_data_gen.n
# 使用tf.keras.applications中的DenseNet121网络,并且使用官方的预训练模型
covn_base = tf.keras.applications.DenseNet121(weights='imagenet', include_top=False, input_shape=(224, 224, 3), classes=classnum)
covn_base.trainable = True
# 冻结前面的层,训练最后5层
for layers in covn_base.layers[:-5]:
layers.trainable = False
# 构建模型
model = tf.keras.Sequential()
model.add(covn_base)
model.add(tf.keras.layers.GlobalAveragePooling2D()) # 加入全局平均池化层
model.add(tf.keras.layers.Dense(512, activation='relu')) # 添加全连接层
model.add(tf.keras.layers.Dropout(rate=0.5)) # 添加Dropout层,防止过拟合
model.add(tf.keras.layers.Dense(2, activation='softmax')) # 添加输出层(2分类)
model.summary() # 打印每层参数信息
# 编译模型
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.0001), # 使用adam优化器,学习率为0.0001
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=False), # 交叉熵损失函数
metrics=["accuracy"]) # 评价函数
# 训练模型
# 回调函数1:学习率衰减
reduce_lr = ReduceLROnPlateau(
monitor='val_loss', # 需要监视的值
factor=0.1, # 学习率衰减为原来的1/10
patience=2, # 当patience个epoch过去而模型性能不提升时,学习率减少的动作会被触发
mode='min', # 当监测值为val_acc时,模式应为max,当监测值为val_loss时,模式应为min,在auto模式下,评价准则由被监测值的名字自动推断
verbose=1 # 如果为True,则为每次更新输出一条消息,默认值:False
)
# 回调函数2:保存最优模型
checkpoint = ModelCheckpoint(
filepath='./save_weights/weights_bestDogVSCcat_Deset_model.hdf5', # 保存模型的路径
monitor='val_accuracy', # 需要监视的值
verbose=1,
save_best_only=True, # 当设置为True时,监测值有改进时才会保存当前的模型
mode='max', # 当监测值为val_acc时,模式应为max,当监测值为val_loss时,模式应为min,在auto模式下,评价准则由被监测值的名字自动推断
)
# 开始训练
history = model.fit(x=train_data_gen, # 输入训练集
steps_per_epoch=total_train // batch_size, # 一个epoch包含的训练步数
epochs=epochs, # 训练模型迭代次数
validation_data=val_data_gen, # 输入验证集
validation_steps=total_val // batch_size, # 一个epoch包含的训练步数
callbacks=[checkpoint, reduce_lr]) # 执行回调函数
# 保存训练好的模型权重
model.save('./save_weights/dogVScat_Desnet121.h5')
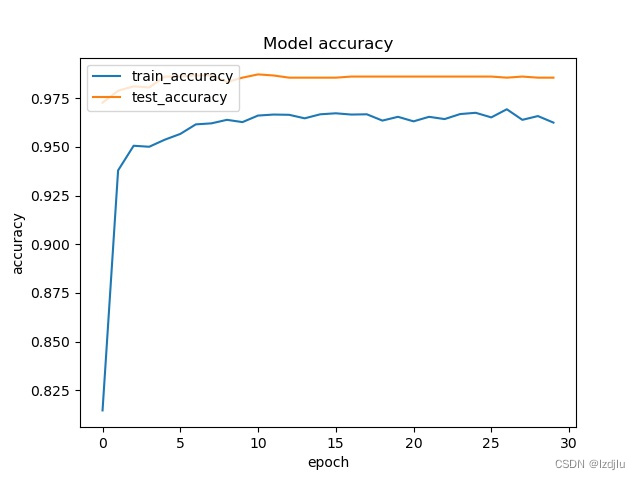
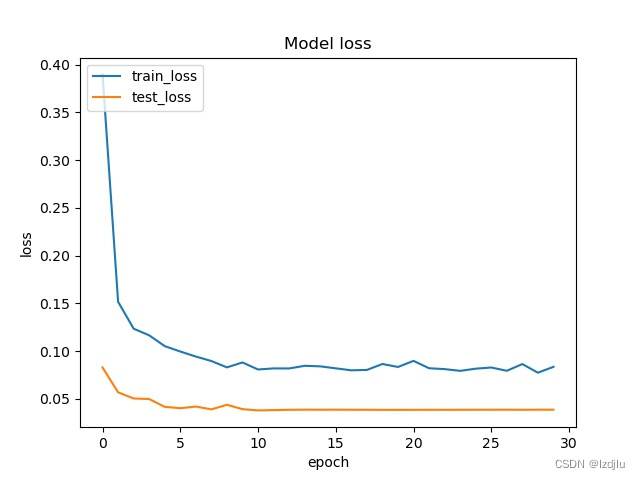
# 记录训练集和验证集的准确率和损失值
history_dict = history.history
train_loss = history_dict["loss"] # 训练集损失值
train_accuracy = history_dict["accuracy"] # 训练集准确率
val_loss = history_dict["val_loss"] # 验证集损失值
val_accuracy = history_dict["val_accuracy"] # 验证集准确率
loss_trend_graph_path = r"WW_loss.jpg"
acc_trend_graph_path = r"WW_acc.jpg"
print("Now,we start drawing the loss and acc trends graph...")
# 绘制损失值曲线
# summarize history for loss
fig = plt.figure(2)
plt.plot(history.history["loss"])
plt.plot(history.history["val_loss"])
plt.title("Model loss")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.legend(["train_loss", "test_loss"], loc="upper left")
plt.savefig(loss_trend_graph_path)
plt.close(2)
# 绘制准确率曲线
# summarize history for accuracy
fig = plt.figure(1)
plt.plot(history.history["accuracy"])
plt.plot(history.history["val_accuracy"])
plt.title("Model accuracy")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(["train_accuracy", "test_accuracy"], loc="upper left")
plt.savefig(acc_trend_graph_path)
plt.close(1)
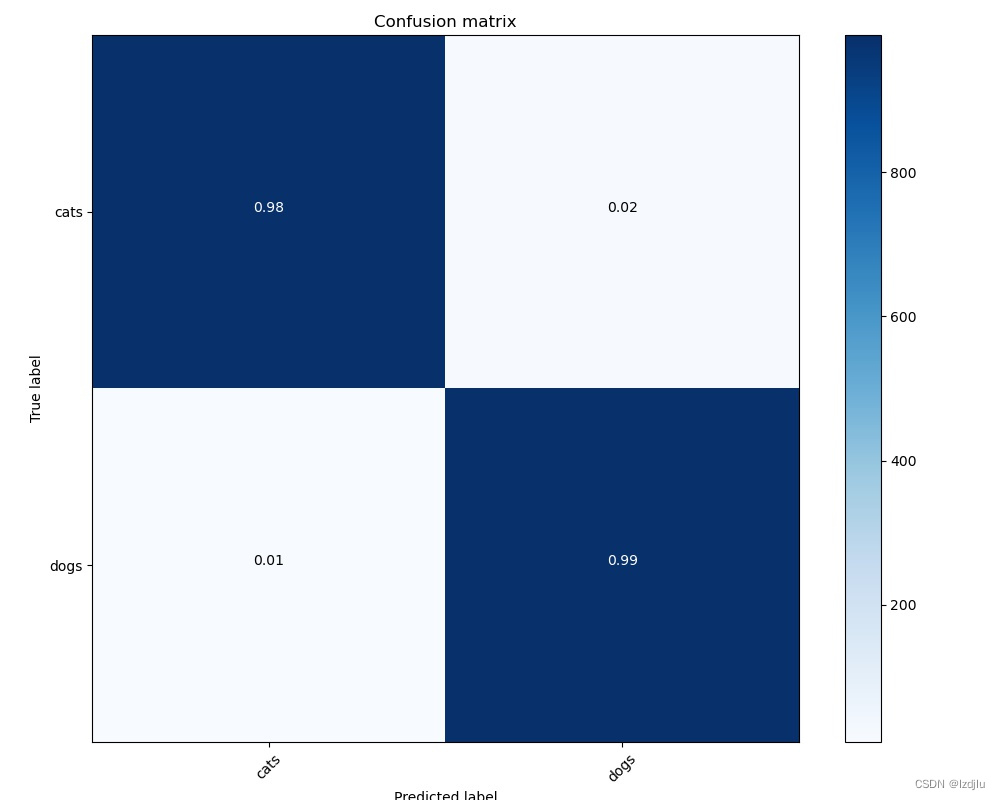
# 绘制混淆矩阵
def plot_confusion_matrix(cm, target_names, title='Confusion matrix', cmap=None, normalize=False, ww_confusion_matrix=None):
fig = plt.figure(3)
accuracy = np.trace(cm) / float(np.sum(cm)) # 计算准确率
misclass = 1 - accuracy # 计算错误率
if cmap is None:
cmap = plt.get_cmap('Blues') # 颜色设置成蓝色
plt.figure(figsize=(12, 10)) # 设置窗口尺寸
plt.imshow(cm, interpolation='nearest', cmap=cmap) # 显示图片
plt.title(title) # 显示标题
plt.colorbar() # 绘制颜色条
if target_names is not None:
tick_marks = np.arange(len(target_names))
plt.xticks(tick_marks, target_names, rotation=45) # x坐标标签旋转45度
plt.yticks(tick_marks, target_names) # y坐标
if normalize:
cm = cm.astype('float32') / cm.sum(axis=1)
cm = np.round(cm, 2) # 对数字保留两位小数
thresh = cm.max() / 1.5 if normalize else cm.max() / 2
for i, j in itertools.product(range(cm.shape[0]),
range(cm.shape[1])): # 将cm.shape[0]、cm.shape[1]中的元素组成元组,遍历元组中每一个数字
if normalize: # 标准化
plt.text(j, i, "{:0.2f}".format(cm[i, j]), # 保留两位小数
horizontalalignment="center", # 数字在方框中间
color="white" if cm[i, j] > thresh else "black") # 设置字体颜色
else: # 非标准化
plt.text(j, i, "{:,}".format(cm[i, j]),
horizontalalignment="center", # 数字在方框中间
color="white" if cm[i, j] > thresh else "black") # 设置字体颜色
plt.tight_layout() # 自动调整子图参数,使之填充整个图像区域
plt.ylabel('True label') # y方向上的标签
plt.xlabel("Predicted label\naccuracy={:0.4f}\n misclass={:0.4f}".format(accuracy, misclass)) # x方向上的标签
# plt.show() # 显示图片
plt.savefig(ww_confusion_matrix)
plt.close(3)
# 猫和狗两种标签,存入到labels中
labels = ['cats', 'dogs']
WW_confusion_matrix = r"WW_confusion_matrix.jpg"
# 预测验证集数据整体准确率
Y_pred = model.predict_generator(val_data_gen, total_val // batch_size + 1)
# 将预测的结果转化为one hit向量
Y_pred_classes = np.argmax(Y_pred, axis=1)
# 计算混淆矩阵
confusion_mtx = confusion_matrix(y_true=val_data_gen.classes, y_pred=Y_pred_classes)
# 绘制混淆矩阵
plot_confusion_matrix(confusion_mtx, normalize=True, target_names=labels, ww_confusion_matrix=WW_confusion_matrix)
训练过程:
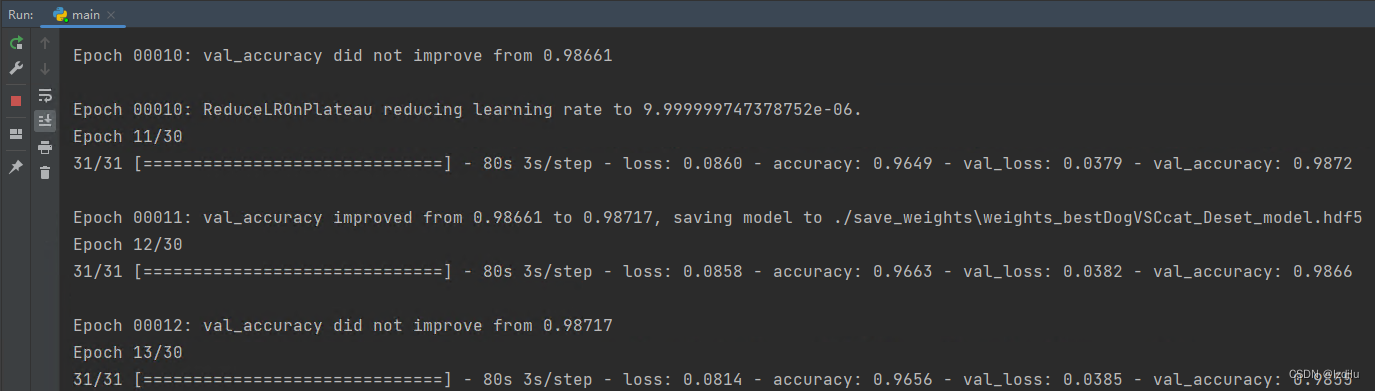
4.测试代码
新建DenseNet_test.py文件对模型进行测试:
# 导入相应的库
import time
from PIL import Image
from tensorflow.keras.callbacks import ReduceLROnPlateau, ModelCheckpoint
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
import itertools
import os
from tensorflow.keras.models import load_model
os.environ['CUDA_VISIBLE_DEVICES'] = '0' # 指定GPU:0
# 设置图片的高和宽,一次训练所选取的样本数,迭代次数
im_height = 224
im_width = 224
batch_size = 256
epochs = 10
INIT_LR = 1e-3
labelList = []
dicClass = {'cat': 0, 'dog': 1}
classnum = 2
# 创建保存模型的文件夹
if not os.path.exists("save_weights"):
os.makedirs("save_weights")
image_path = "dataset1/" # 猫狗数据集路径
train_dir = image_path + "training_set" # 训练集路径
validation_dir = image_path + "test_set" # 验证集路径
# 定义训练集图像生成器,并进行图像增强
train_image_generator = ImageDataGenerator(rescale=1. / 255, # 归一化
rotation_range=40, # 旋转范围
width_shift_range=0.2, # 水平平移范围
height_shift_range=0.2, # 垂直平移范围
shear_range=0.2, # 剪切变换的程度
zoom_range=0.2, # 剪切变换的程度
horizontal_flip=True, # 水平翻转
fill_mode='nearest')
# 使用图像生成器从文件夹train_dir中读取样本,对标签进行one-hot编码
train_data_gen = train_image_generator.flow_from_directory(directory=train_dir, # 从训练集路径读取图片
batch_size=batch_size, # 一次训练所选取的样本数
shuffle=True, # 打乱标签
target_size=(im_height, im_width), # 图片resize到224x224大小
class_mode='categorical') # one-hot编码
# 获取数据集的类别编码
class_indices = train_data_gen.class_indices
# 将编码和对应的类别存入字典
inverse_dict = dict((val, key) for key, val in class_indices.items())
emotion_classifier = load_model("save_weights/weights_bestDogVSCcat_Deset_model.hdf5")
# emotion_classifier = load_model("save_weights/dogVScat_Desnet121.h5")
img = Image.open("test/test1.jpg") # 加载测试图片
img = img.resize((im_width, im_height)) # 将图片resize到224x224大小
img1 = np.array(img) / 255. # 归一化
img1 = (np.expand_dims(img1, 0)) # 将图片增加一个维度,目的是匹配网络模型
t1 = time.time()
# 将预测结果转化为概率值
result = np.squeeze(emotion_classifier.predict(img1))
predict_class = np.argmax(result)
t2 = time.time()
t3 = t2-t1
print("time=", t3)
print("result:", result)
print("predict_class:", predict_class)
print("inverse_dict:", inverse_dict)
# print(inverse_dict[int(predict_class)],result[predict_class])
# 将预测的结果打印在图片上面
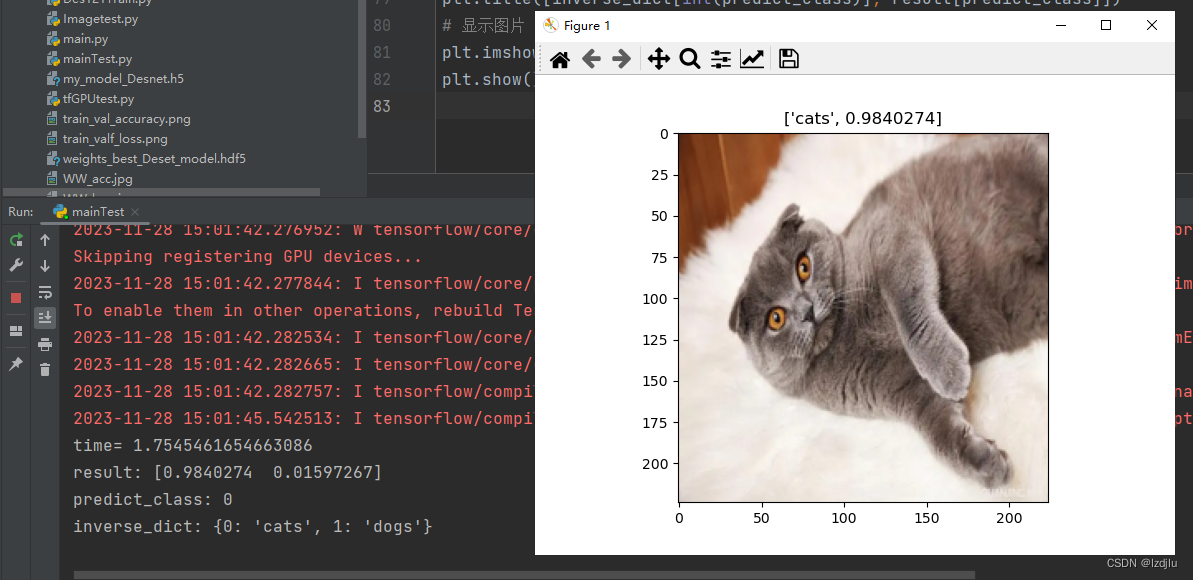
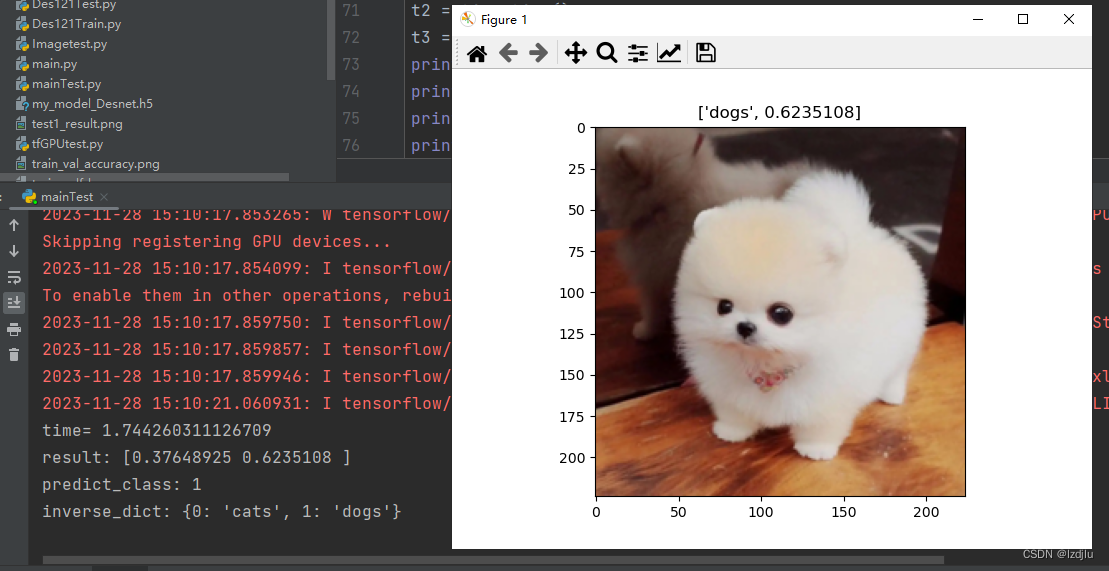
plt.title([inverse_dict[int(predict_class)], result[predict_class]])
# 显示图片
plt.imshow(img)
plt.show()
测试结果如下:
有问题请添加qq:498609554和下面微信交流!

















 3035
3035











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











