










一、查询结果乱码:
使用mysql执行select命令后查到的结果如果含有汉字时会出现乱码,执行show variables like 'character%',获取字符集配置为:
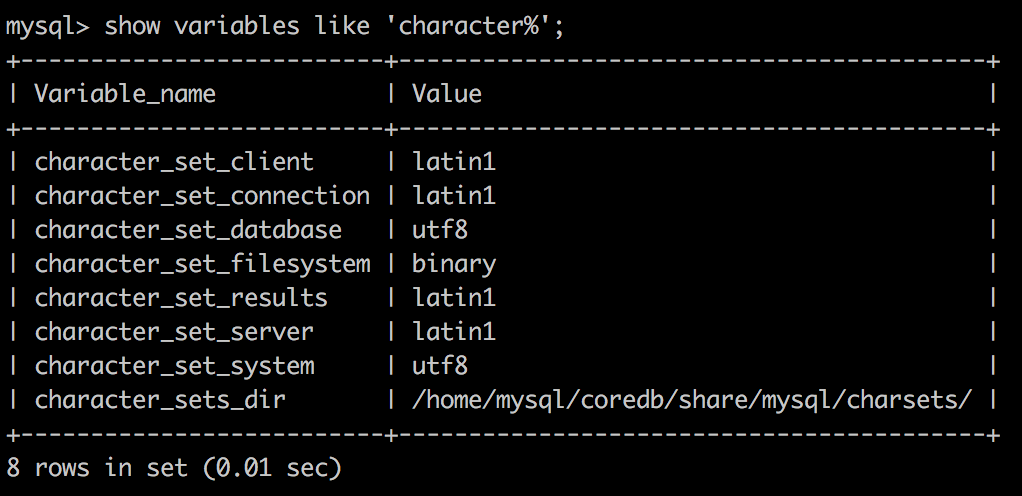
latin1其实就是我们通常所说的ISO-8859-1字符集,是不支持汉字的。需要改成utf8,执行set names utf8,重新执行select语句就不乱码了。可以查看此时字符集配置为:
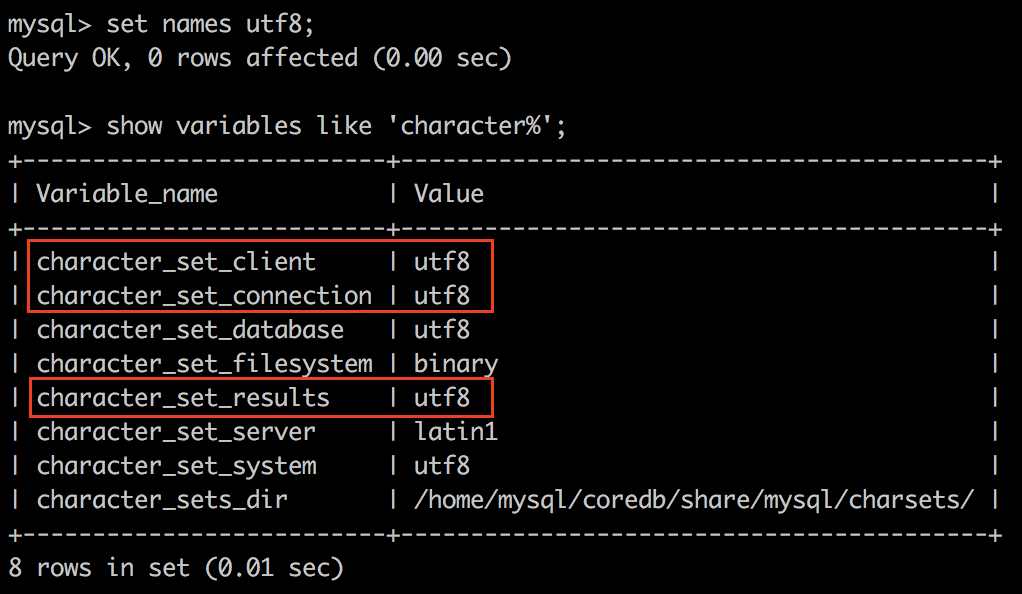
其中:character_set_client、character_set_connection和character_set_results变成了utf8,可以看出set names就是设置这三个参数的值。一个select执行的过程应该是:client——>connection——>server/database——>results——>connection——>client,任何一个环节的字符集不兼容都会出现乱码。其中,select语句最终是针对server下的某个database,所以跟server的字符集关系不太大。
当会话关闭后,重新进入后又恢复成原来的字符集,所以这种方案只是临时方式。如果想每次登录都默认设置成utf8,有两种方式:
1)在my.cnf配置文件中的mysqld中增加如下配置,重启mysql;
#设置字符集为utf8
character-set-server = utf8
#忽略客户端的字符集
skip-character-set-client-handshake2)在my.cnf配置文件中中mysqld中增加如下配置,重启mysql;
#客户端每次连接服务器时首先执行set names utf8
init_connect=set names utf8二、utf8mb4字符集:
utf8编码可能2个字节、3个字节、4个字节的字符,但mysql的utf8编码最多支持3字节的数据,而移动端的emoji表情数据是4个字节,无法存储,utf8mb4字符集可以解决这个问题。
mysql在5.5.3版本之后增加了这个utf8mb4的编码,mb4就是most bytes,4就是专门用来兼容四字节的unicode。其实,utf8mb4是utf8的超集,理论上原来使用utf8,然后将字符集修改为utf8mb4,也不会对已有的utf8编码读取产生任何问题。当然,为了节省空间,一般情况下使用utf8也就够了。
修改数据库字符集和排序集:
ALTER DATABASE database_name CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;修改表的字符集和排序集:
ALTER TABLE table_name CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;修改某列的字符集和排序集:
ALTER TABLE table_name CHANGE old_col_name new_col_name col_type CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;或者:
ALTER TABLE table_name MODIFY COLUMN col_name col_type CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;三、char(n)、varchar(n)以及int(n):
mysql5.0版本以下,char(n)和varchar(n)中n指的是可存储的最大字节数;
mysql5.0版本及以上,char(n)和varchar(n)中n指的是可存储的最大字符数;
char(n)中n的值最大为255,varchar(n)中n的值最大为65535;
int(n)中n指的是显示位数,详见:《mysql的整型》
四、计算内容的字节数和字符数:
length()计算字节数;
char_length()计算字符数;















 5618
5618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









