




 本文介绍了OpenAI的Q*(Q Star)项目,它是Q-learning的一个高级迭代,可能结合了深度学习。文章通过与A*搜索算法的对比,解释了Q-learning的基本原理,强调了Q*在动态学习、交互式学习和决策优化方面的优势。此外,还探讨了Q*与谷歌的Gemini项目在语言模型和决策策略上的相似性和差异。
本文介绍了OpenAI的Q*(Q Star)项目,它是Q-learning的一个高级迭代,可能结合了深度学习。文章通过与A*搜索算法的对比,解释了Q-learning的基本原理,强调了Q*在动态学习、交互式学习和决策优化方面的优势。此外,还探讨了Q*与谷歌的Gemini项目在语言模型和决策策略上的相似性和差异。

为初学者解释 Open Ai 的 Q*(Q Star)
Q* 的两个可能来源。
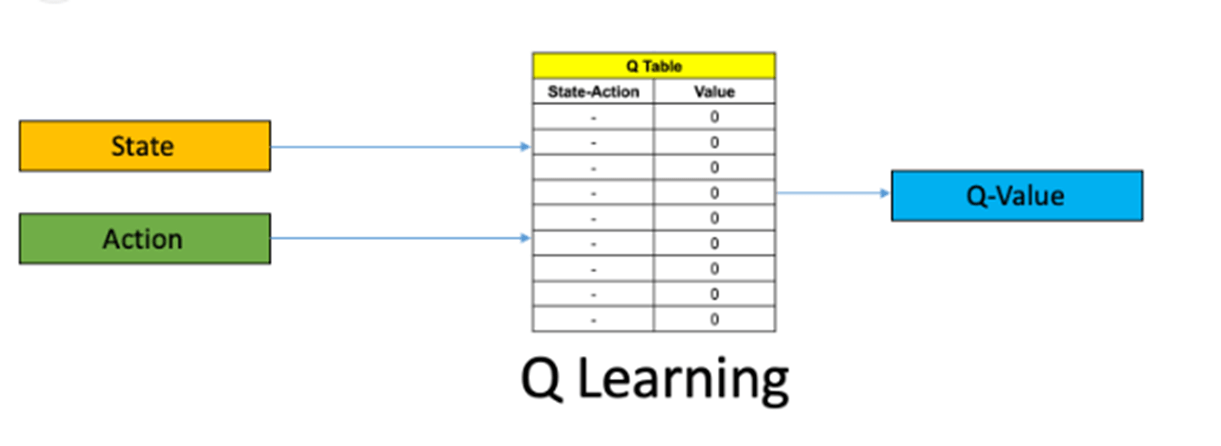
1)Q 可能是指 "Q-learning",这是一种用于强化学习的机器学习算法。
-
Q 名称的由来*:把 "Q*"想象成超级智能机器人的昵称。
-
Q 的意思是这个机器人非常善于做决定。
-
它从经验中学习,就像你从玩电子游戏中学习一样。
-
玩得越多,就越能找出获胜的方法。
2) 来自 A* 搜索
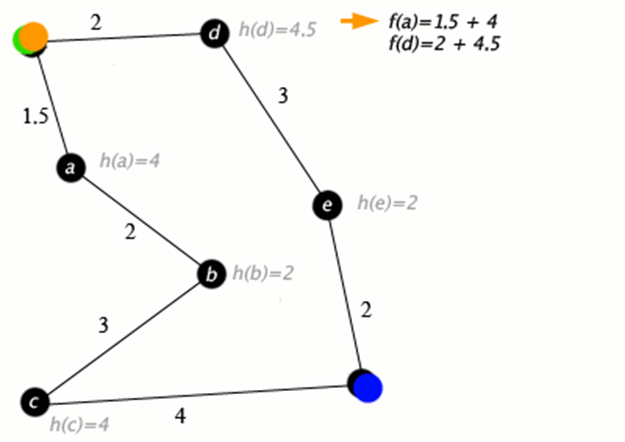
A* 搜索算法是一种寻路和图遍历算法,在计算机科学中被广泛用于解决各种问题,尤其是在游戏和人工智能中用于寻找两点之间的最短路径。
-
想象一下,你身处迷宫之中,需要找到最快的出路。
-
计算机科学中有一种经典方法,有点像一组指令,可以帮助找到迷宫中的最短路径。
-
这就是A*搜索。现在,如果我们将这种方法与深度学习(一种让计算机从经验中学习和改进的方法,就像你在尝试了几次之后,会学到更好的方法)相结合,我们就能得到一个非常智能的系统。
-
这个系统不仅仅能在迷宫中找到最短的路径,它还能通过找到最佳解决方案来解决现实世界中更棘手的问题,就像你如何找出解决难题或游戏的最佳方法一样。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1578
1578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











