







实际问题
在大模型的研发中,通常会有下面一些需求:
- 计划训练一个10B的模型,想知道至少需要多大的数据?
- 收集到了1T的数据,想知道能训练一个多大的模型?
- 老板准备1个月后开发布会,给的资源是100张A100,应该用多少数据训多大的模型效果最好?
- 老板对现在10B的模型不满意,想知道扩大到100B模型的效果能提升到多少?
核心结论
大模型的Scaling Law是OpenAI在2020年提出的概念[1],具体如下:
- 对于Decoder-only的模型,计算量𝐶(Flops), 模型参数量𝑁, 数据大小𝐷(token数),三者满足: 𝐶≈6𝑁𝐷 。(推导见本文最后)
- 模型的最终性能主要与计算量𝐶,模型参数量𝑁和数据大小𝐷三者相关,而与模型的具体结构(层数/深度/宽度)基本无关。
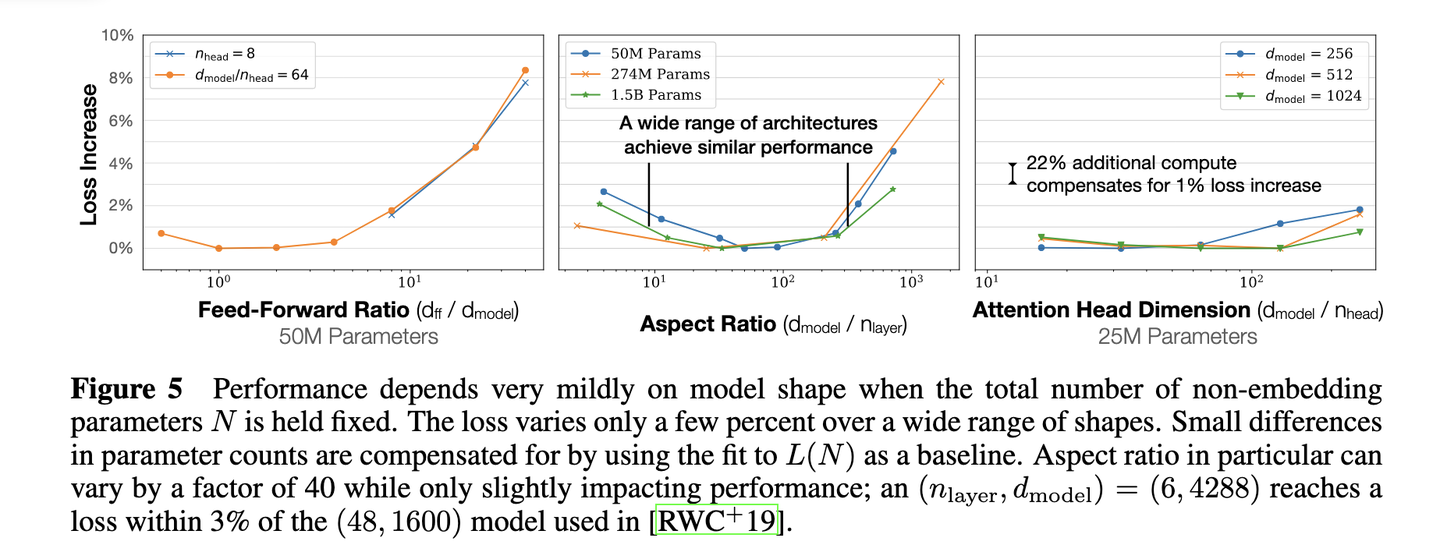
固定模型的总参数量,调整层数/深度/宽度,不同模型的性能差距很小,大部分在2%以内
3. 对于计算量𝐶,模型参数量𝑁和数据大小𝐷,当不受其他两个因素制约时,模型性能与每个因素都呈现幂律关系
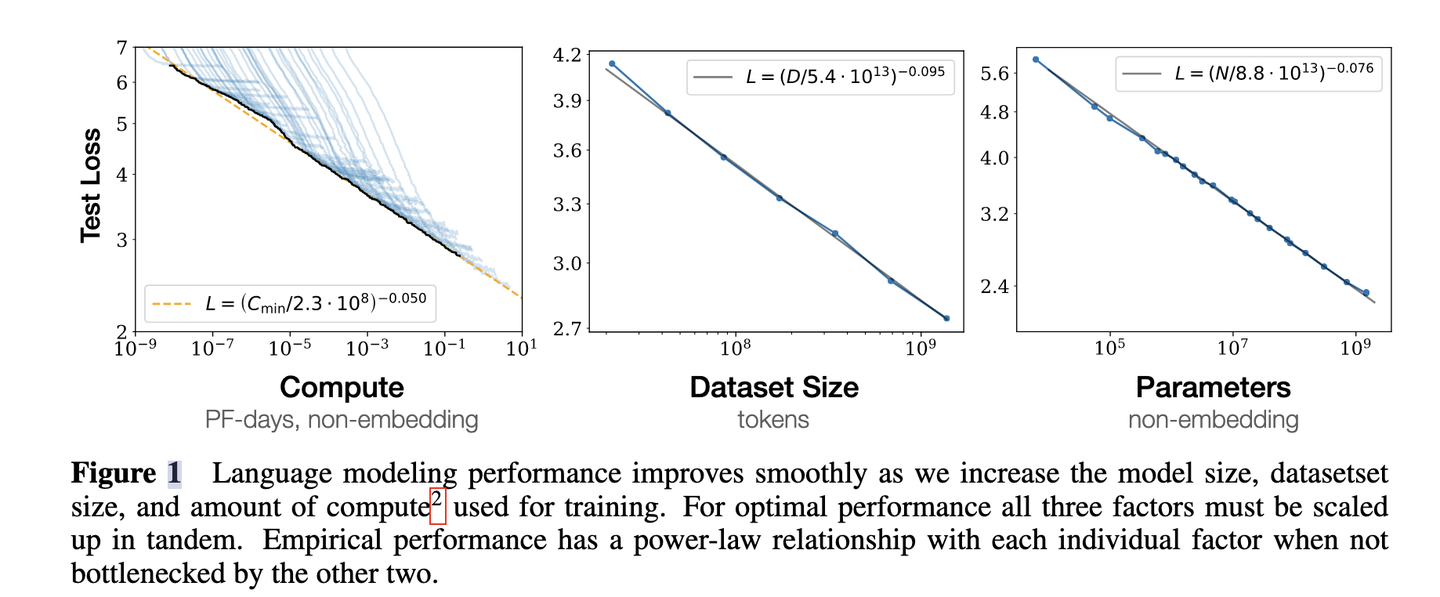
4. 为了提升模型性能,模型参数量𝑁和数据大小𝐷需要同步放大,但模型和数据分别放大的比例还存在争议。
5. Scaling Law不仅适用于语言模型,还适用于其他模态以及跨模态的任务[4]:
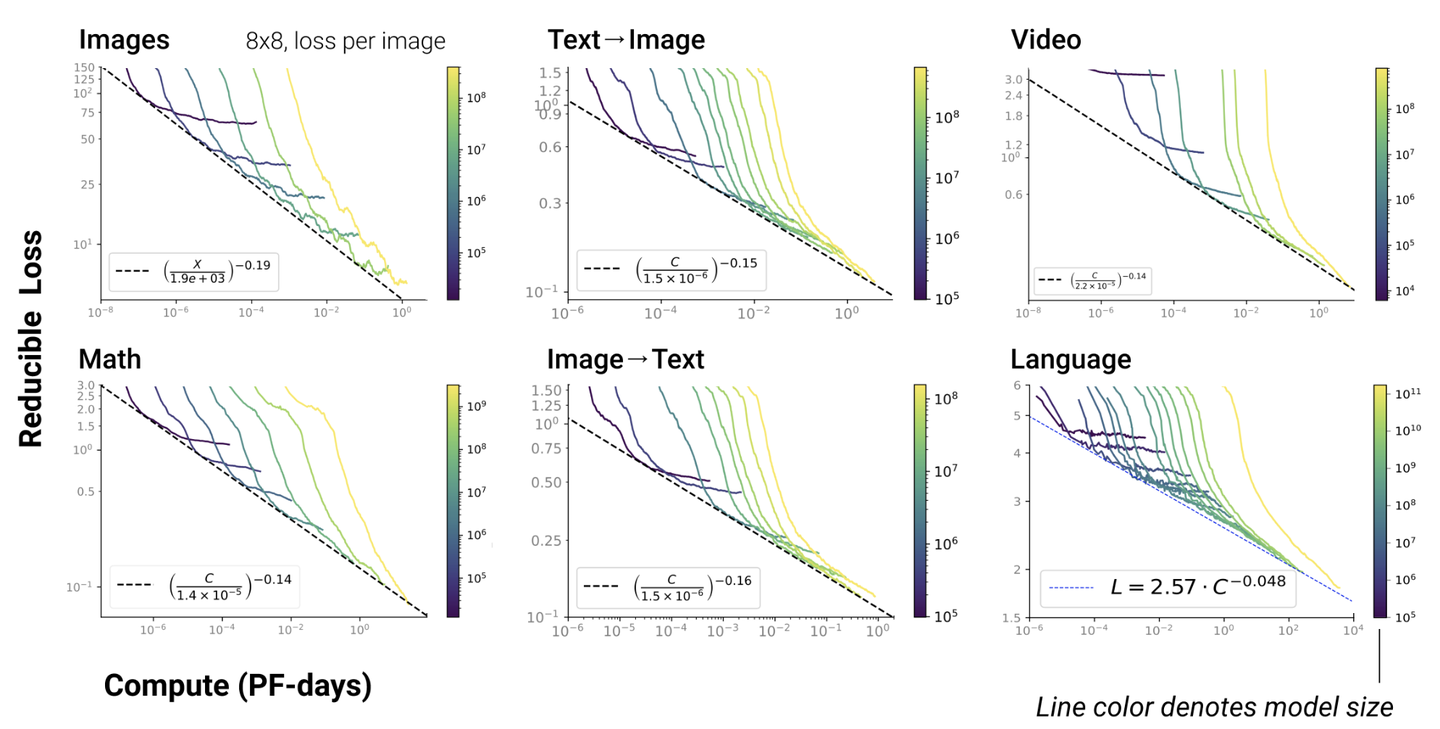
这里横轴单位为PF-days: 如果每秒钟可进行1015次运算,就是1 peta flops,那么一天的运算就是1015×24×3600=8.64×1019,这个算力消耗被称为1个petaflop/s-day。
大模型中的Scaling Law
GPT4:遵循Scaling Law的大模型
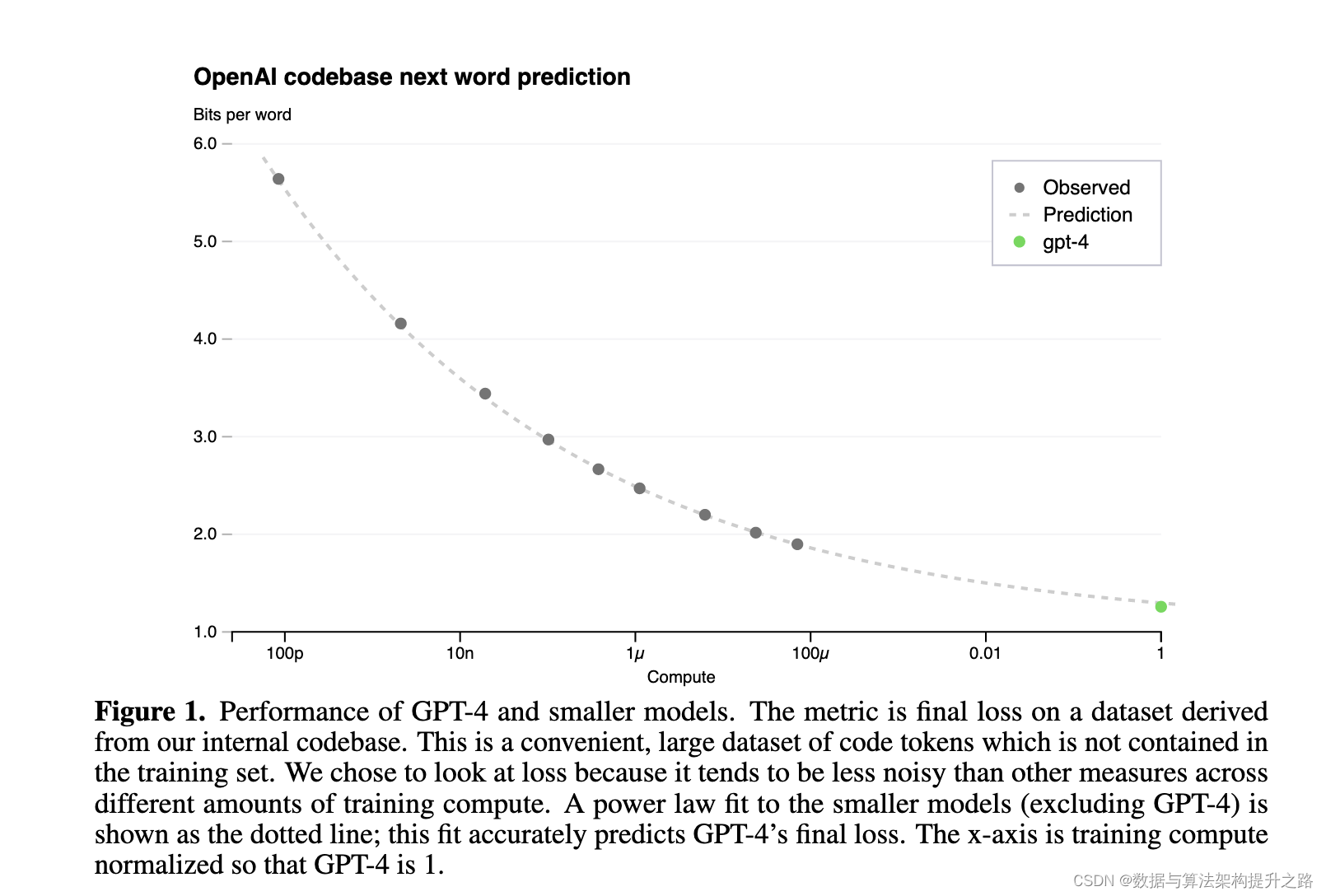
- 符合Scaling Law:GPT-4的实际性能与通过较小模型拟合得到的功率律曲线一致,这表明GPT-4遵循Scaling Law。换句话说,随着计算量的增加,模型的性能改善符合预期。
- 功率律拟合:通过对较小模型的功率律拟合,可以准确预测更大模型的最终性能。这说明在合理范围内,使用较小模型进行实验并拟合曲线,能够有效预测更大规模模型的性能。
LLaMA: "违反"Scaling Law的大模型
缩放法则通常认为模型性能与参数数量和训练数据量呈幂律关系。
LLAMA模型在较小的参数规模下就能达到与更大模型相当的性能,这似乎违反了缩放法则。
LLAMA之所以能做到这一点,主要有以下几个原因:
a) 高质量的训练数据:LLAMA使用了经过careful curation的高质量数据集。
b) 更长的训练时间:LLAMA采用了更长的训练周期。
c) 改进的模型架构:如使用RoPE等新技术。
d) 更好的训练策略:如采用cosine learning rate schedule等。
LLAMA并没有真正违反缩放法则,而是通过优化各个环节,在资源受限的情况下最大化了模型性能。
这种方法对于资源有限的研究团队和公司很有启发意义,说明通过精心设计,小规模模型也可以达到很好的效果。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











